什么是协程和协程调度?
基本概念
协程
协程是一种比线程更轻量级的并发编程结构,它允许在函数执行过程中暂停和恢复执行状态,从而实现非阻塞式编程。协程又被称为用户级线程,这是由于协程包括上下文切换在内的全部执行逻辑都是由程序员显式指定的,操作系统并不知道协程的存在。
协程类的实现:
/*
Fiber类的声明
主要作用:1. 提供了一些基础功能来管理和调度协程的执行
*/
class Fiber : public std::enable_shared_from_this<Fiber> { // std::enable_shared_from_this<T> C++标准库模板类,用于启用从类的成员函数生成共享指针的功能
public:typedef std::shared_ptr<Fiber> ptr; // 指向Fiber类对象的共享指针// Fiber状态机enum State {READY, // 就绪态,刚创建或者从'yield'中恢复,准备运行RUNNING, // 运行态,协程正在运行TERM, // 结束态,协程的回调函数执行完毕,已经结束};private:// 私有的默认构造函数,用来在GetThis中调用以初始化主协程,不能显式调用Fiber();public:// 含参构造函数,用于构造子协程,指定协程的回调函数和栈大小Fiber(std::function<void()> cb, size_t stackSz = 0, bool run_in_scheduler = true); ~Fiber();void reset(std::function<void()> cb); // 重置协程状态,复用栈空间。(给协程重新绑定一个回调函数,在同一个空间但是功能改变了)void resume(); // 切换协程到运行态void yield(); // 让出协程执行权uint64_t getId() const { return id_; } // 获得协程IDState getState() const { return state_; } // 活动协程状态// 静态成员函数static void SetThis(Fiber *f); // 设置当前正在运行的协程static Fiber::ptr GetThis(); // 获取当前线程中的执行协程,如果当前线程没有创建协程,则创建一个且作为主协程static uint64_t TotalFiberNum(); // 获得协程总数static void MainFunc(); // 协程执行函数static uint64_t GetCurFiberID(); // 获得当前协程IDprivate:uint64_t id_ = 0; // 协程IDuint32_t stackSize_ = 0; // 协程栈大小State state_ = READY; // 协程状态ucontext_t ctx_; // 协程的上下文void *stack_ptr = nullptr; // 协程栈地址std::function<void()> cb_; // 协程回调函数bool isRunInscheduler_; // 本协程是否参与调度器调度
};
上述协程的封装提供了一些基础功能,使得协程可以被创建、调度和切换。协程共有三种状态:
READY:就绪态,协程刚创建或从yield中恢复,准备运行。RUNNING:运行态,协程正在运行。TERM:结束态,协程的回调函数执行完毕,已经结束。
简单来说,
协程可以看作是对要执行函数(cb_)的一个封装,但是加入了状态、上下文信息等内容,能够在多线程中实现异步执行。
协程的优势:
协程不是操作系统的底层特性,系统感知不到它的存在。它运行在线程里面,通过分时复用线程的方式运行,不会增加线程的数量。协程也有上下文切换,但是不会切换到内核态去,比线程切换的开销要小很多。每个协程的体积比线程要小得多,一个线程可以容纳数量相当可观的协程。
在IO密集型的任务中有着大量的阻塞等待过程,协程采用协作式调度,在IO阻塞的时候让出CPU,当IO就绪后再主动占用CPU(通过回调函数),牺牲任务执行的公平性换取吞吐量。
事物都有两面性,协程也存在几个弊端:
- 线程可以在多核CPU上并行,无法将一个线程的多个协程分摊到多核上。
- 协程执行中不能有阻塞操作,否则整个线程被阻塞。(不阻塞,而是让出执行权)
- 协程的控制权由用户态决定,可能执行恶意的代码。
协程调度
协程调度是一种用于管理协程执行的机制,负责在多个协程之间分配执行时间,使得它们能够高效地并发运行。

与线程不同,协程的调度是需要由程序员显式的实现。一般来说,任务队列中有很多任务(协程),用户手动调用协程不够灵活,因此利用调度器将任务队列中的各个任务协程,分配给各个线程中进行执行,这就是协程调度。
于是,需要先创建一个**协程调度器**,然后把这些要调度的协程传递给调度器,由调度器负责把这些协程一个一个消耗掉。在单线程模式下,调度器会非常简单,只需要实现加入任务,逐个提取出任务执行即可:
/*** @file simple_fiber_scheduler.cc* @brief 一个简单的协程调度器实现* @version 0.1* @date 2021-07-10*/#include "sylar/sylar.h"/*** @brief 简单协程调度类,支持添加调度任务以及运行调度任务*/
class Scheduler {
public:/*** @brief 添加协程调度任务*/void schedule(sylar::Fiber::ptr task) {m_tasks.push_back(task);}/*** @brief 执行调度任务*/void run() {sylar::Fiber::ptr task;auto it = m_tasks.begin();while(it != m_tasks.end()) { // 挨个把协程拿出来执行task = *it;m_tasks.erase(it++);task->resume();}}
private:/// 任务队列std::list<sylar::Fiber::ptr> m_tasks;
};void test_fiber(int i) {std::cout << "hello world " << i << std::endl;
}int main() {/// 初始化当前线程的主协程sylar::Fiber::GetThis();/// 创建调度器Scheduler sc;/// 添加调度任务for(auto i = 0; i < 10; i++) {sylar::Fiber::ptr fiber(new sylar::Fiber(std::bind(test_fiber, i)));sc.schedule(fiber);}/// 执行调度任务sc.run();return 0;
}
这是由于一个线程同一时刻只能运行一个协程,所以挨个执行即可。然而在实际使用中,势必要用到多线程来提高调度的效率。
- 读取任务:在多线程的情况下,可以简单地认为,调度器创建后,内部首先会创建一个调度线程池,调度开始后,所有调度线程从任务队列里取任务执行,调度线程数越多,能够同时调度的任务也就越多,当所有任务都调度完后,调度线程就停下来等新的任务进来。
- 添加任务:添加调度任务的本质就是往调度器的任务队列里塞任务,但是,只添加调度任务是不够的,还应该有一种方式用于通知调度线程有新的任务加进来了,因为调度线程并不一定知道有新任务进来了。当然调度线程也可以不停地轮询有没有新任务,但是这样CPU占用率会很高。
- 调度器的停止:调度器应该支持停止调度的功能,以便回收调度线程的资源,只有当所有的调度线程都结束后,调度器才算真正停止。
调度器概念的简单总结
调度器内部维护一个任务队列和一个调度线程池。开始调度后,线程池从任务队列里按顺序取任务执行。调度线程可以包含caller线程。当全部任务都执行完了,线程池停止调度,等新的任务进来。添加新任务后,通知线程池有新的任务进来了,线程池重新开始运行调度。停止调度时,各调度线程退出,调度器停止工作。
任务和任务队列 SchedulerTask
任务可以是一个协程也可以是一个函数,可以将他们封装到一个类SchedulerTask中,如下:
/*
SchedulerTask:调度任务类
主要作用:表示一个调度任务,这个任务可以是一个协程对象或者一个函数对象
*/
class SchedulerTask {
public:friend class Scheduler;SchedulerTask() { thread_ = -1; // 初始化为-1}SchedulerTask(Fiber::ptr f, int t) { // 含参构造函数,调度任务为协程对象fiber_ = f;thread_ = t;}SchedulerTask(std::function<void()> f, int t) { // 含参构造函数,调度任务为函数对象cb_ = f;thread_ = t;}// 清空任务void reset() {fiber_ = nullptr;cb_ = nullptr;thread_ = -1;}private:Fiber::ptr fiber_; // 指向协程对象的指针std::function<void()> cb_; // 回调函数int thread_; // 执行该任务的线程ID,-1表示不指定线程
};
任务队列则是用来存放多个任务,具体实现为将任务存储到链表中std::list<SchedulerTask> tasks_ ,每次取任务时从链表头部开始遍历寻找可以运行的任务,每次添加任务的时候,将任务添加到链表尾部。(所以调度策略是先来先服务)
多线程下的协程调度器 Scheduler
调度器的作用就是从任务队列中取出一个任务,然后交给线程中的任务协程处理。实现中,Scheduler类的声明如下:
/*
Scheduler:N-M协程调度器,管理多线程和协程
主要作用:用于管理多个线程和协程
*/
class Scheduler {
public:typedef std::shared_ptr<Scheduler> ptr; // Scheduler::ptr 是Scheduler类对象的共享指针类型的别名Scheduler(size_t threads = 1, bool user_caller = true, const std::string &name = "Scheduler"); virtual ~Scheduler(); // 析构函数定义为虚函数const std::string &getName() const { return name_; }// 静态成员函数static Scheduler *GetThis(); // 获得当前线程的协程调度器static Fiber *GetMainFiber(); // 获得当前线程的主协程// 添加任务到调度器中template <class TaskType>void scheduler(TaskType task, int thread = -1) {bool isNeedTickle = false; // 是否需要唤醒空闲的协程{Mutex::Lock lock(mutex_); // 初始化局部互斥锁lock,此时会自动加锁(ScopedLockImpl类中的定义)// 因此这里已经加了锁,下面添加调度任务就不需要在加锁了isNeedTickle = schedulerNoLock(task, thread); // 添加调度任务}if (isNeedTickle) {tickle();}}void start(); // 启动调度器void stop(); // 停止调度器,等待所有任务结束protected:virtual void tickle(); // 通知调度器任务到达void run(); // 协程调度函数virtual void idle(); // 无任务时,执行idle协程virtual bool stopping(); // 返回是否可以停止void setThis(); // 设置当前线程调度器bool isHasIdleThreads() { // 有没有空闲进程return idleTreadCnt_ > 0;}private:// 满足无锁条件时(确保task_没被其他线程加锁占用),添加调度任务// TODO:加入使用clang的锁检查template <class TaskType>bool schedulerNoLock(TaskType t, int thread) {bool isNeedTickle = tasks_.empty(); // 任务队列是空,可以唤醒空闲的协程SchedulerTask task(t, thread);if (task.fiber_ || task.cb_) { // 要么是协程,要么是函数对象tasks.push_back(task); // 任务有效,加入到任务队列中}return isNeedTickle;}std::string name_; // 调度器名称Mutex mutex_; // 互斥锁std::vector<Thread::ptr> threadPool_; // 调度线程池std::list<SchedulerTask> tasks_; // 任务队列std::vector<int> threadIds_; // 线程池ID数组size_t threadCnt_ = 0; // 工作线程数量(不包含主线程)std::atomic<size_t> activeThreadCnt_ = {0}; // 活跃线程数目std::atomic<size_t> idleTreadCnt_ = {0}; // IDL线程(在线程池中处于空闲的线程)数目Fiber::ptr rootFiber_; // 指向本线程的调度协程(主协程)bool isUseCaller_; // 是否使用use_caller模式bool isStopped_; // 线程池或调度器是否已经停止// 以下变量仅在use_caller模式中有用Fiber::ptr fiber_; // 存储调度器协程所在线程(主线程)的协程(因为use_caller模式,主线程也会执行除管理线程池或调度器以外的任务)int rootThread_ = 0; // 存储调度器协程所在的线程(主线程)ID};
初始化:
具体实现中,协程调度器在初始化时支持传入线程数和一个布尔型的use_caller参数,表示是否使用caller线程。在使用caller线程的情况下,线程数自动减一,并且调度器内部会初始化一个属于caller线程的调度协程并保存起来(比如,在main函数中创建的调度器,如果use_caller为true,那调度器会初始化一个属于main函数线程的调度协程)。
调度器创建好后,即可调用调度器的schedule方法向调度器添加调度任务,但此时调度器并不会立刻执行这些任务,而是将它们保存到内部的一个任务队列中。
开始调度:
调用start方法启动调度后,调度器会创建调度线程池,线程数量由初始化时的线程数和use_caller确定。调度线程一旦创建,就会立刻从任务队列里取任务执行。所有的调度线程都绑定了run方法,负责从调度器的任务队列中取任务执行**(即调度线程的主协程,也是调度协程)。从任务队列中取出的任务就是任务协程(子协程)**,每个子协程执行完后都必须返回调度协程,由调度协程重新从任务队列中取新的协程并执行。如果任务队列空了,那么调度协程会切换到一个idle协程,这个idle协程什么也不做,等有新任务进来时,idle协程才会退出并回到调度协程,重新开始下一轮调度。
添加调度任务:
添加调度任务,对应schedule方法,这个方法支持传入协程或函数,并且支持一个线程号参数,表示是否将这个协程或函数绑定到一个具体的线程上执行。如果任务队列为空,那么在添加任务之后,要调用一次tickle方法以通知各调度线程的调度协程有新任务来了。在执行调度任务时,还可以通过调度器的GetThis()方法获取到当前调度器,再通过schedule方法继续添加新的任务,这就变相实现了在子协程中创建并运行新的子协程的功能。(在调度线程的任务协程中也可以添加任务)
调度器的停止:
调度器的停止行为要分两种情况讨论:
use_caller模式
caller线程为调度器所在的线程(主线程),如果use_caller=true,则表示将调度器所在的线程也用于任务调度,这样在实现相同调度能力的情况下(指能够同时调度的协程数量),线程数越少,线程切换的开销也就越小,效率更高一些。(使用caller线程进行调度就会少开一个线程),是否使用caller线程,对应的处理方式也不同,这里也是比较难理解的地方。
线程创建、线程内创建协程的理解
caller线程就相当于直接运行main函数得到的线程(主线程),非caller线程是通过new Thread的方式创建线程的。对于caller线程,创建协程时直接调用GetThis()方法即可。
// caller线程
if (use_caller) { // use_caller模式,当前线程也作为被调度的线程std::cout << LOG_HEAD << "current thread as called thread" << std::endl;--threads; // 工作线程总数-1(工作线程不包括主线程,但主线程占了一个位置)// 初始化caller线程的主协程Fiber::GetThis(); // 然后,Fiber::cur_thread_fiber即可获取初始化后的主协程std::cout << LOG_HEAD << "init caller thread's main fiber success" << std::endl;
对于非caller线程,也就是线程池里的线程,需要先创建线程(绑定run方法),然后在run方法中创建主协程
// 非caller线程的创建和协程初始化
for (size_t i = 0; i < threadCnt_; ++i) {threadPool_[i].reset(new Thread(std::bind(&Scheduler::run, this), name_ + "_" + std::to_string(i))); // 创建非caller线程并执行threadIds_.push_back(threadPool_[i]->getId());
}void Scheduler::run() {std::cout << LOG_HEAD << "begin run" << std::endl;set_hook_enable(true); // TODOsetThis(); if (GetThreadId() != rootThread_) { // 当前线程不是caller线程(因为caller线程的主协程(调度协程)已经初始化过了)// 初始化主协程cur_scheduler_fiber = Fiber::GetThis().get();}... ...... ...
}
任务协程、调度协程、主协程的概念
任务协程:就是我们要运行的任务,可以理解为任务队列中的单个任务。
调度协程(cur_scheduler_fiber):在每一个线程中,都会有一个调度协程,调度协程负责从任务队列中取任务,然后调度协程让出执行权,运行任务协程,运行结束后再回到调度协程,如下图所示:

主协程(cur_thread_fiber):在之前的协程模块中,我们已经知道,对于每一个线程都有一个主协程,主协程用于和任务协程(子协程)进行切换,因为实现的是非对称协程,只能通过主协程和任务协程(子协程)进行切换(是否使用caller协程对应主协程任务也不同)。
疑问一:调度协程和主协程不是一个东西吗?为什么非要再声明一个调度协程?直接用主协程不就行了吗?
疑问二:调度协程要和任务协程(子协程)切换,另外只能通过主协程和任务协程(子协程)进行切换,所以调度协程就是主协程?
由于调度协程负责从任务队列中取任务,这就意味着我必然要给调度协程设置一个执行函数。
在协程类设计时,主协程创建时,并没有给主协程分配栈,也没有给主协程设置执行函数(具体可见Fiber()构造函数),只用于协程之间的切换,所以就导致主协程不能当作调度协程,因为调度协程需要绑定执行run方法,不断从任务队列中取任务,而主协程又不能设置执行函数。所以概念上调度协程和主协程不是一个东西(概念上)。
idle协程(空闲协程)
假设当线程A没有任务可以做,且整个协程调度还没结束(就是说虽然线程A没任务了,但是其他的线程还有任务正在执行,调度还没结束),此时会让线程A执行idle协程(也是一个子协程),idle协程内部循环判断协程调度是否停止。
-
如果未停止,则将idle协程置为HOLD状态,让出执行权,继续运行run方法内的while循环,从任务队列取任务。(属于忙等状态,CPU占用率爆炸)
-
如果已经停止,则idle协程执行完毕,将idle协程状态置为TERM,协程调度结束。
caller线程和非caller线程的实现区别
caller线程:创建调度器的线程,我们在main函数创建了调度器,该caller线程的执行函数就是main函数,如果想使用caller线程进行协程调度,那就需要创建一个调度协程rootFiber_且绑定执行run方法,才能参与协程调度。
// 创建调度协程rootFiber_,其任务为执行Scheduler的run方法rootFiber_.reset(new Fiber(std::bind(&Scheduler::run, this), 0, false)); // reset为shared_ptr的方法,替换指针托管的对象std::cout << LOG_HEAD << "init caller thread's caller fiber success" << std::endl;
非caller线程:在创建完调度器,调用start方法时会创建线程池,线程池里的线程就是非caller线程,每个非caller线程指定执行函数为run。注意这里run方法绑定到了线程上了,也就是主协程,在线程上执行run方法不断从任务队列取任务,所以就不用再创建一个调度协程绑定执行run方法了
/*
start:启动调度器,提供给外部的接口
主要功能:启动调度器,创建并初始化线程池,使调度器能够开始执行调度任务
*/
void Scheduler::start() {std::cout << LOG_HEAD << "scheduler start" << std::endl;// 添加局部互斥锁,保护共享资源Mutex::Lock lock(mutex_);// 检查调度器是否已经停止,如果停止则直接返回if (isStopped_) {std::cout << "scheduler is stopped" << std::endl;return;}// 确保线程池应该是空的CondPanic(threadPool_.empty(), "thread pool should be empty");threadPool_.resize(threadCnt_); // 根据线程数量确定线程池的大小// 创建线程,加入到线程池for (size_t i = 0; i < threadCnt_; ++i) {threadPool_[i].reset(new Thread(std::bind(&Scheduler::run, this), name_ + "_" + std::to_string(i))); // 创建线程并执行threadIds_.push_back(threadPool_[i]->getId());}
}
总结就是:
-
对于
caller线程,run方法绑定到了一个子协程上(就是调度协程),而主协程没有执行函数和栈空间用于协程切换,主协程 ≠ 调度协程。 -
对于
非caller线程,run方法绑定到了线程上,不断从任务队列寻找任务的事情交给了线程本身(即主协程),所以就不需要调度协程。在具体实现中,为了复用代码,调度协程指针cur_scheduler_fiber指向了主协程(也就是主协程 = 调度协程)。
协程调度的整体流程
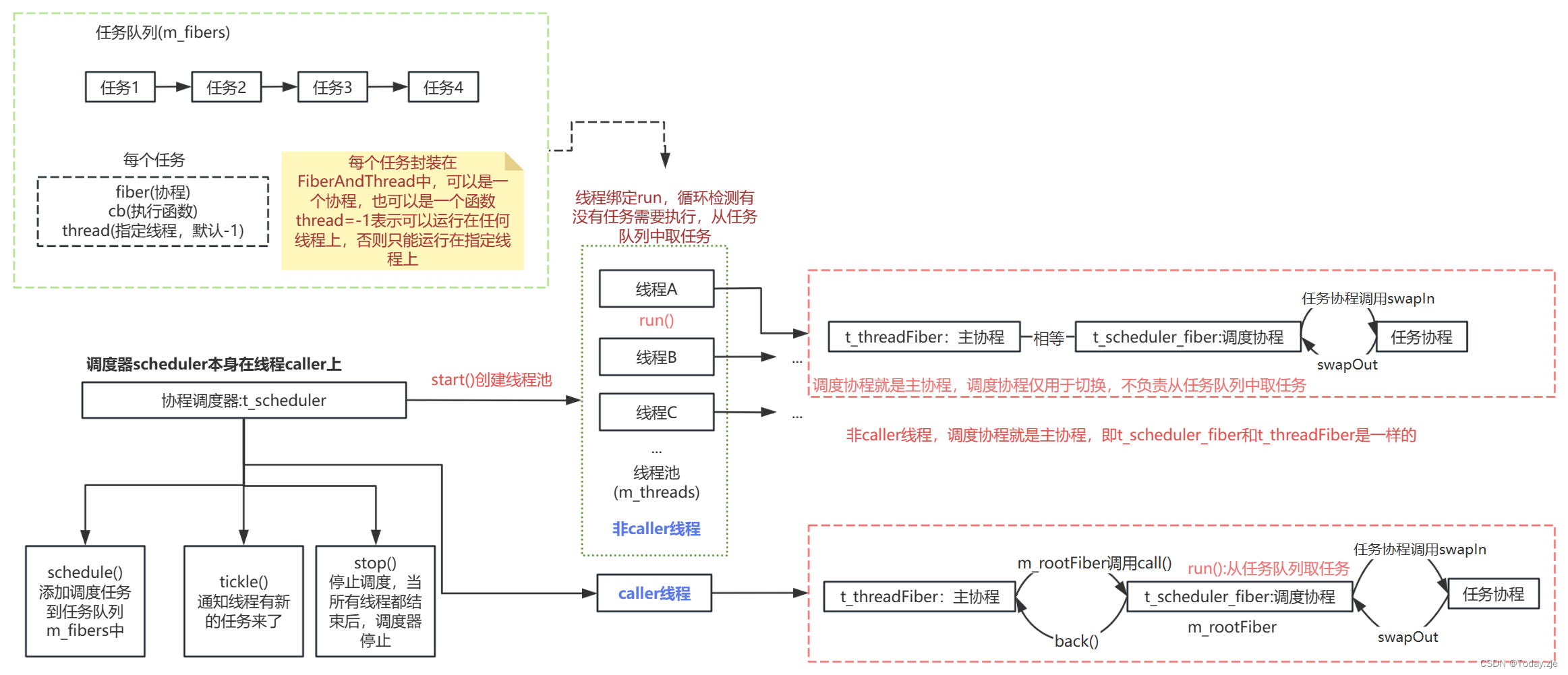
注意:非caller线程中没有调度协程(主协程就是调度协程),线程(主协程)本身绑定了run函数,负责取任务。
协程的切换问题
无论是caller线程还是非caller线程。分两种典型情况来讨论一下调度协程的切换情况,其他情况可以看成以下两种情况的组合,原理是一样的。
-
线程数为1,且use_caller为true,则为caller线程,对应只使用main函数线程进行协程调度的情况。
-
线程数为1,且use_caller为false,对应额外创建一个线程(因为主线程不参与调度)进行协程调度、main函数线程不参与调度的情况。
情况2比较好理解,因为有单独的线程用于协程调度,那只需要让新线程的入口函数作为调度协程,从任务队列里取任务执行(就行了,main函数与调度协程完全不相关,main函数只需要向调度器添加任务,然后在适当的时机停止调度器即可。当调度器停止时,main函数要等待调度线程结束后再退出,参考下面的图示:

情况1则比较复杂,因为没有额外的线程进行协程调度,那只能用main函数所在的线程来进行调度,而梳理一下main函数线程要运行的协程,会发现有以下三类协程:
- main函数对应的主协程
- 调度协程
- 待调度的任务协程

也就是说:main函数先攒下一波协程(添加调度任务),然后切到调度协程里去执行,等把这些协程都消耗完后,再从调度协程切回来。此时,线程需要保存三个协程的上下文(主协程、调度协程、子协程),否则会出现线程主协程跑飞的情况(切换不回主协程)。
拓展:
- 多线程,且use_caller为true,主线程(caller线程)参与调度,同时还会创建额外的线程进行协程调度。即为**【协程调度的整体流程】图中**展示的情况。
- 多线程,且use_caller为false,主线程(caller线程)不参与调度,会创建多个线程进行协程调度,caller线程负责启动和管理这些调度线程,但不参与实际的协程执行。同时,也会创建专门的调度线程承担从任务队列中取出任务的工作(也就是新建立的这个调度线程承担了在use_caller模式中caller线程执行任务的职责)。
一些问题
1. 调度器的退出问题
调度器内部有一个协程任务队列,调度器调度的实质就是内部的线程池从这个任务队列拿任务并执行,那么,停止调度时,如果任务队列还有任务剩余,要怎么处理?这里可以简化处理,强制规定只有所有的任务都完成调度时,调度器才可以退出,如果有一个任务没有执行完,那调度器就不能退出。
2. 任务协程执行过程中主动调用yield让出了执行权,调度器要怎么处理?
半路yield的协程显然并没有执行完,一种处理方法是调度器来帮协程擦屁股,在检测到协程从resume返回时,如果状态仍为READY,那么就把协程重新扔回任务列,使其可以再次被调度,这样保证一个协程可以执行结束。但这种策略是画蛇添足的,从生活经验的角度来看,一个成熟的协程肯定要学会自我管理,既然你自己yield了,那么你就应该自己管理好自己,而不是让别人来帮你,这样才算是一个成熟的协程。对于主动yield的协程,我们的策略是,调度器直接认为这个任务已经调度完了,不再将其加入任务队列。如果协程想完整地运行,那么在yield之前,协程必须先把自己再扔回当前调度器的任务队列里,然后再执行yield,这样才能确保后面还会再来调度这个协程。
这里规定了一点,协程在主动执行yield前,必须先将自己重新添加到调度器的任务队列中。如果协程不顾后果地执行yield,最后的后果就是协程将永远无法再被执行,也就是所说的逃逸状态。(sylar的处理方法比较折衷一些,sylar定义了两种yield操作,一种是yield to ready,这种yield调度器会再次将协程加入任务队列并等待调度,另一种是yield to hold,这种yield调度器不会再将协程加入任务队列,协程在yield之前必须自己先将自己加入到协程的调度队列中,否则协程就处于逃逸状态。再说一点,sylar定义的yield to ready,在整个sylar框架内一次都没用到,看来sylar也同意,一个成熟的协程要学会自我管理。)
3. 只使用调度器所在的线程进行调度的场景
这种场景下,可以认为是main函数先攒下一波协程,然后切到调度协程,把这些协程消耗完后再从调度协程切回main函数协程。每个协程在运行时也可以继续创建新的协程并加入调度。
4. idle如何处理,也就是当调度器没有协程可调度时,调度协程该怎么办?
直觉上来看这里应该有一些同步手段,比如,没有调度任务时,调度协程阻塞住,比如阻塞在一个idle协程上,等待新任务加入后退出idle协程,恢复调度。然而这种方案是无法实现的,因为每个线程同一时间只能有一个协程在执行,如果调度线程阻塞在idle协程上,那么除非idle协程自行让出执行权,否则其他的协程都得不到执行,这里就造成了一个先有鸡还是先有蛋的问题:只有创建新任务idle协程才会退出,只有idle协程退出才能创建新任务。
为了解决这个问题,sylar采取了一个简单粗暴的办法,如果任务队列空了,调度协程会不停地检测任务队列,看有没有新任务,俗称忙等待,CPU使用率爆表。这点可以从sylar的源码上发现,一是Scheduler的tickle函数什么也不做,因为根本不需要通知调度线程是否有新任务,二是idle协程在协程调度器未停止的情况下只会yield to hold,而调度协程又会将idle协程重新swapIn,相当于idle啥也不做直接返回。这个问题在sylar框架内无解,只有一种方法可以规避掉,那就是设置autostop标志,这个标志会使得调度器在调度完所有任务后自动退出。在后续的IOManager中,上面的问题会得到一定的改善,并且tickle和idle可以实现得更加巧妙一些,以应对IO事件。
5. 有main函数线程参与调度时的调度执行时机
前面说过,当只有main函数线程参与调度时,可以认为是主线程先攒下一波协程,然后切到调度协程开始调度这些协程,等所有的协程都调度完了,调度协程进idle状态,这个状态下调度器只能执行忙等待,啥也做不了。这也就是说,主线程main函数一旦开启了协程调度,就无法回头了,位于开始调度点之后的代码都执行不到。对于这个问题,sylar把调度器的开始点放在了stop方法中,也就是,调度开始即结束,干完活就下班。IOManager也是类似,除了可以调用stop方法外,IOManager类的析构函数也有一个stop方法,可以保证所有的任务都会被调度到。
也就是:如果只使用caller线程进行调度,那所有的任务协程都在stop之后排队调度。
6. 额外创建了调度线程时的调度执行时机
如果不额外创建线程,也就是线程数为1并且use caller,那所有的调度任务都在stop()时才会进行调度。但如果额外创建了线程,那么,在添加完调度任务之后任务马上就可以在另一个线程中调度执行。归纳起来,如果只使用caller线程进行调度,那所有的任务协程都在stop之后排队调度,如果有额外线程,那任务协程在刚添加到任务队列时就可以得到调度。
7. 协程中的异常要怎么处理,子协程抛出了异常该怎么办?
这点其实非常好办,类比一下线程即可,你会在线程外面处理线程抛出的异常吗?答案是不会,所以协程抛出的异常我们也不处理,直接让程序按默认的处理方式来处理即可。一个成熟的协程应该自己处理掉自己的异常,而不是让调度器来帮忙。顺便说一下,sylar的协程调度器处理了协程抛出的异常,并且给异常结束的协程设置了一个EXCEPT状态,这看似贴心,但从长远的角度来看,其实是非常不利于协程的健康成长的。
8. 关于协程调度器的优雅停止。sylar停止调度器的策略如下:
- 设置m_stopping标志,该标志表示正在停止
- 检测是否使用了caller线程进行调度,如果使用了caller线程进行调度,那要保证stop方法是由caller线程发起的
- 通知其他调度线程的调度协程退出调度
- 通知当前线程的调度协程退出调度
- 如果使用了caller线程进行调度,那执行一次caller线程的调度协程(只使用caller线程时的协程调度全仰仗这个操作)
- 等caller线程的调度协程返回
- 等所有调度线程结束
参考文献
上述内容与图像多来自网络和下列博客,若侵权,告知删除。
协程调度模块 - 类库与框架 - 程序员的自我修养 (midlane.top)
彻底理解协程 - 编码专家 - 博客园 (cnblogs.com)
![[linux]sed命令基础入门详解](https://i-blog.csdnimg.cn/direct/eb773c12c6fa44a6b6c814f5924676a6.png)