香橙派 AIpro 根据心情生成专属音乐
- 一、OrangePi AI pro 开发版参数介绍
- 1.1 接口简介
- 1.2 OrangePi AI pro 的Linux系统功能适配情况
- 1.3 开发板开机
- 1.4 远程连接到 OrangePi AIpro
- 二、开发环境搭建
- 2.1 创建环境、代码部署文件夹
- 2.2 安装 miniconda
- 2.3 为 miniconda 更新国内源
- 2.4 创建一个 python 3.9 版本的开发环境
- 三、基于MindNLP + MusicGen生成自己的个性化音乐
- 3.1 模型介绍
- 3.2 下载模型
- 3.3 生成音乐
- 3.4 无提示生成
- 3.5 文本提示生成
- 3.6 音频提示生成
- 四、总结
这篇博客 用 OrangePi AIpro 实现了根据文字、音频、生成音乐
一、OrangePi AI pro 开发版参数介绍
首先必须要提的一点是 OrangePi AI pro 是 业界首款基于昇腾深度研发的AI开发板,采用昇腾AI技术路线,集成图形处理器,拥有16GB LPDDR4X,最大可支持外接 256GB eMMC 模块,支持双 4K 高清输出,8/20 TOPS AI算力。
1.1 接口简介
Orange Pi AIpro 有着强大的可拓展性。包括两个HDMI输出、GPIO接口、Type-C电源接口、支持SATA/NVMe SSD 2280的M.2插槽、TF插槽、千兆网口、两个USB3.0、一个USB Type-C 3.0、一个Micro USB、两个MIPI摄像头、一个MIPI屏等,一个预留电池接口。
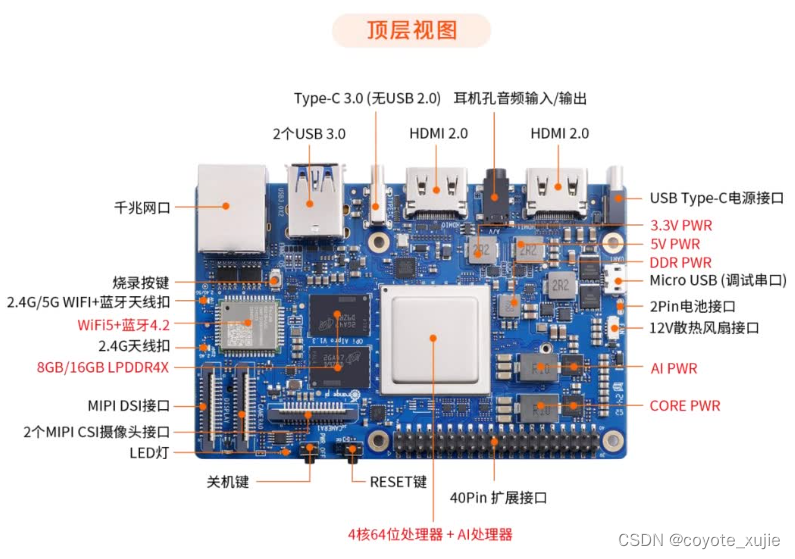
1.2 OrangePi AI pro 的Linux系统功能适配情况
| 功能 | 是否能测试 | Linux 内核驱动 |
|---|---|---|
| HDMI0 1080p 显示 | OK | OK |
| HDMI0 4K 显示 | NO | NO |
| HDMI0 音频 | OK | NO |
| HDMI1 显示 | OK | NO |
| HDMI1 音频 | OK | NO |
| 耳机播放 | OK | NO |
| 耳机 MIC 录音 | OK | NO |
| Type-C USB3.0(无 USB2.0) | OK | OK |
| USB3.0 Host x 2 | OK | OK |
| 千兆网口 | OK | OK |
| 千兆网口灯 | OK | OK |
| WIFI | OK | OK |
| 蓝牙 | OK | OK |
| Micro USB 调试串口 | OK | OK |
| 复位按键 | OK | OK |
| 关机按键(无开机功能) | OK | OK |
| 烧录按键 | OK | OK |
| MIPI 摄像头 0 | OK | NO |
| MIPI 摄像头 1 | OK | NO |
| MIPI LCD 显示 | OK | NO |
| 电源指示灯 | OK | OK |
| 软件可控的 LED 灯 | OK | OK |
| 风扇接口 | OK | OK |
| 电池接口 | OK | OK |
| TF 卡启动 | OK | OK |
| TF 卡启动识别 eMMC | OK | OK |
| TF 卡启动识别 NVMe SSD | OK | OK |
| TF 卡启动识别 SATA SSD | OK | OK |
| eMMC 启动 | OK | OK |
| SATA SSD 启动 | OK | OK |
| NVMe SSD 启动 | OK | OK |
| 2 个拨码开关 | OK | OK |
| 40 pin-GPIO | OK | OK |
| 40 pin-UART | OK | OK |
| 40 pin-SPI | OK | OK |
| 40 pin-I2C | OK | OK |
| 40 pin-PWM | OK | NO |
1.3 开发板开机
这里之所以要拿出来单独说一下,就是因为我本人开了两三次没打开,以为是板子坏了,自己还满心愤懑,后来发现是自己操作不对(确实没看说明书)为了避免大家有同样的错误!!!这里重点介绍!
首先 将烧好系统的 TF 卡查到对应位置上,将两个启动方式拨码开关都向右拨(图示为两个启动方式拨码开关都拨向左)

之后将电源插入电源插口

1.4 远程连接到 OrangePi AIpro
默认的用户名:root
默认的密码:Mind@123
二、开发环境搭建
2.1 创建环境、代码部署文件夹
# 创建环境目录
mkdir ~/env# 创建代码目录
mkdir ~/workshop
2.2 安装 miniconda
下载 miniconda 到 ~/env 目录,这里需要注意的是 OrangePi AIpro 是 arm 架构的
bash ~/env/Miniconda3-py312_24.3.0-0-Linux-aarch64.sh
conda 安装完成如如图所示:
2.3 为 miniconda 更新国内源
更新 miniconda 的源,如果有梯子的话这一步可以不做,但是如果梯子的网速感人的话,还是建议将源更新为清华源
# 修改 .condarc 文件
vi ~/.condarc
将 .condarc 文件修改如下
channels:- defaults
show_channel_urls: true
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/clouddeepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/
清理之前预留的缓存
conda clean -i
2.4 创建一个 python 3.9 版本的开发环境
通过 conda 创建一个 python 3.9 的开发环境,并安装 mindspore 框架,以及一些其他必要的库函数
# 创建一个 python 3.9 的环境
conda create -n py39 python=3.9# 激活环境
conda activate py39
安装 mindspore 框架,版本必须选择 2.3.0rc2
conda install mindspore=2.3.0rc2 -c mindspore -c conda-forge# 安装 mindnlp 包
pip install -i https://pypi.mirrors.ustc.edu.cn/simple mindnlp==0.2.4 jieba
三、基于MindNLP + MusicGen生成自己的个性化音乐
3.1 模型介绍
这里简单介绍一下 MusicGen 模型。MusicGen 是基于单个语言模型(LM)的音乐生成模型,能够根据文本描述或音频提示生成高质量的音乐样本,相关研究成果参考论文《Simple and Controllable Music Generation》。
MusicGen 模型基于Transformer结构,可以分解为三个不同的阶段:
- 用户输入的文本描述作为输入传递给一个固定的文本编码器模型,以获得一系列隐形状态表示。
- 训练 MusicGen 解码器来预测离散的隐形状态音频 token。
- 对这些音频 token 使用音频压缩模型(如 EnCodec)进行解码,以恢复音频波形。
MusicGen 直接使用谷歌的 t5-base 及其权重作为文本编码器模型,并使用EnCodec 32kHz及其权重作为音频压缩模型。MusicGen 解码器是一个语言模型架构,针对音乐生成任务从零开始进行训练。
MusicGen取消了多层级的多个模型结构,例如分层或上采样,这使得MusicGen 能够生成单声道和立体声的高质量音乐样本,同时提供更好的生成输出控制。因此,MusicGen 不仅能够生成符合文本描述的音乐,还能够通过旋律条件控制生成的音调结构。
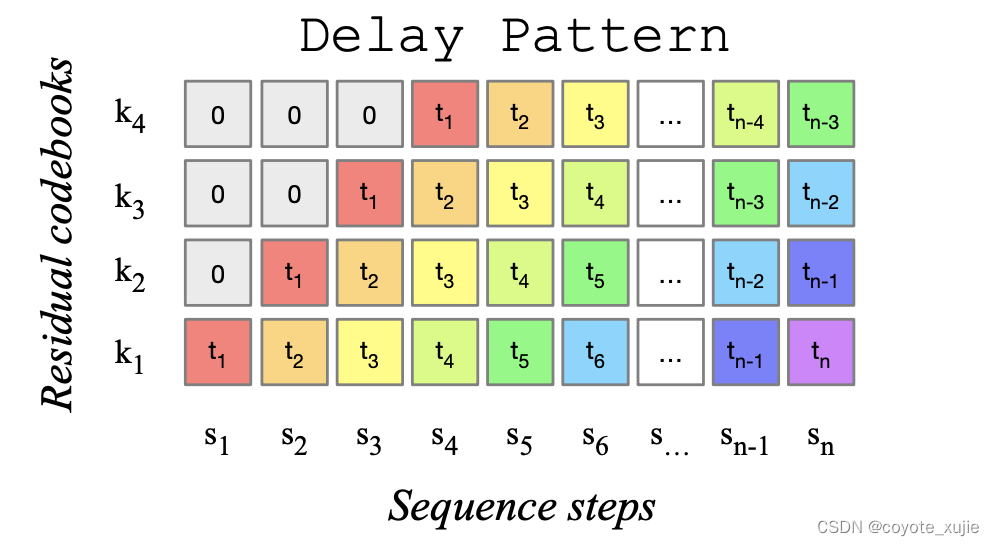
Figure 1: MusicGen使用的码本延迟模式,来源于 MusicGen paper.
3.2 下载模型
MusicGen提供了small、medium和big三种规格的 预训练权重文件,本次指南默认使用 small 规格的权重,生成的音频质量较低,但是生成的速度是最快的(我的板子内存只有 8G大家可以选择 16G 的板子):
from mindnlp.transformers import MusicgenForConditionalGeneration# 下载并导入模型
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
3.3 生成音乐
MusicGen 支持两种生成模式:贪心(greedy)和采样(sampling)。在实际执行过程中,采样模式得到的结果要显著优于贪心模式。因此我们默认启用采样模式,并且可以在调用 MusicgenForConditionalGeneration.generate 时设置 do_sample=True 来显式指定使用采样模式。
3.4 无提示生成
我们可以通过方法 MusicgenForConditionalGeneration.get_unconditional_inputs 获得网络的随机输入,然后使用 .generate 方法进行自回归生成,指定 do_sample=True 来启用采样模式:
unconditional_inputs = model.get_unconditional_inputs(num_samples=1)audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
音频输出是格式是: a Torch tensor of shape (batch_size,num_channels,sequence_length)。
使用第三方库scipy 将输出的音频保存为 musicgen_out.wav 文件。
import scipysampling_rate = model.config.audio_encoder.sampling_rate
scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())
3.5 文本提示生成
首先基于文本提示,通过 AutoProcessor 对输入进行预处理。然后将预处理后的输入传递给 .generate 方法以生成文本条件音频样本。同样,我们通过设置 do_sample=True 来启用采样模式。
其中,guidance_scale 用于无分类器指导(CFG),设置条件对数之间的权重(从文本提示中预测)和无条件对数(从无条件或空文本中预测)。guidance_scale 越高表示生成的模型与输入的文本更加紧密。通过设置guidance_scale > 1 来启用 CFG。为获得最佳效果,使用guidance_scale=3(默认值)生成文本提示音频。
from mindnlp.transformers import AutoProcessorprocessor = AutoProcessor.from_pretrained("facebook/musicgen-small")inputs = processor(text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],padding=True,return_tensors="ms",
)audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)scipy.io.wavfile.write("musicgen_out_text.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())# from IPython.display import Audio
# # 要收听生成的音频样本,可以使用 Audio 进行播放
# Audio(audio_values[0].asnumpy(), rate=sampling_rate)
3.6 音频提示生成
AutoProcessor同样可以对用于音频预测的音频提示进行预处理。在以下示例中,我们首先加载音频文件,然后进行预处理,并将输入给到网络模型来进行音频生成。最后,我们将生成出来的音频文件保存为musicgen_out_audio.wav
from datasets import load_datasetdataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset))["audio"]# take the first half of the audio sample
sample["array"] = sample["array"][: len(sample["array"]) // 2]# 使用音视频提示生成,耗时较久processor = AutoProcessor.from_pretrained("facebook/musicgen-small")inputs = processor(audio=sample["array"],sampling_rate=sample["sampling_rate"],text=["80s blues track with groovy saxophone"],padding=True,return_tensors="ms",
)audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)scipy.io.wavfile.write("musicgen_out_audio.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())# from IPython.display import Audio
# # 要收听生成的音频样本,可以使用 Audio 进行播放
# Audio(audio_values[0].asnumpy(), rate=sampling_rate)
四、总结
总体使用下来我将从 用户友好程度、开发文档支持程度、性能三个方面 对 Orange Pi AI Pro 进行总结:
- 用户友好程度:烧录好的系统和日常经常使用 Unbutu 系统体验上并无任何不同,更为绚丽的界面、精简的系统、完整的开发资料都极大的有助于新手快速玩转开发板。我做的是一个音频生成的模型,模型参数超过了 2G,在 c 上可以顺利的运行、并生成相应风格的音乐。此外,OrangePi AIpro 系统的烧录和启动都很为新手着想(我就是新手),可以选择TF卡、eMMC 或 SSD 作为启动介质,每种方式都有详细的官方指南,系统玩出问题了,恢复起来也很简单。
- 开发文档支持:作为新手,其实我们最担心的问题就是文档全不全、教程多不多、教程详细不详细!很幸运,OrangePi AIpro 有着详尽的教程;用户手册内容详实,从硬件参数到软件配置,乃至进阶功能均有详细解说(收集到的一些教程我也会附在后面,方便大家查阅)。每个模块都有单独的说明,比较丰富的应用示例,一站式找到所有文档的服务极大的降低了新手在开发中走弯路的可能。
- 性能:Orange Pi AI Pro 主打一个性价比!搭载的华为昇腾AI处理器,以 8TOPS 的INT8 算力和 4 TFLOPS FP16 的浮点运算能力,为复杂AI模型提供了强大的计算支撑。我在 8G 版本的 Orange Pi AI Pro 上 成功的运行了 MusicGen模型,其模型参数大小为 2.2G 这对于 8G 版本的 Orange Pi AI Pro 来说,无疑是一个极大的挑战。板子在运行时内存使用超 90%,但是散热真的很好,风扇噪音较小,整块处理器的问题摸起来并不烫手,即使在满载的情况下运行半小时左右,处理器的温度略高于手指温度。