Diffusion Models专栏文章汇总:入门与实战
前言:在微调扩散模型的时候经常会遇到微调数据集和训练数据集之间的差距过大,导致训练效果很差。在图像生成任务中并不明显,但是在视频生成任务中这个问题非常突出。这篇博客深入解读如何解决微调扩散模型时微调数据集和训练数据集之间的差距过大问题?
目录
图片生成中的微调数据集和训练数据集之间的差距过大问题
视频扩散模型
解决方案一
解决方案二
图片生成中的微调数据集和训练数据集之间的差距过大问题
其实在微调图片生成模型中这个问题并不明显,例如微调一个古风模型,在写实风格的基模上同样可以取得不错的成果,数据怼进去训也不会有太多资源上的压力。
视频扩散模型

视频扩散模型这个问题特别明显:
1、继续大力出奇迹资源成本高。
2、破坏原有的运动先验。
解决方案一
最简单的解决方案:将原有训练基模的数据集和微调数据集混合训练,可以1:1混合,也可以让微调数据集适当多一些。
但是这样的训练成本比较高。
解决方案二
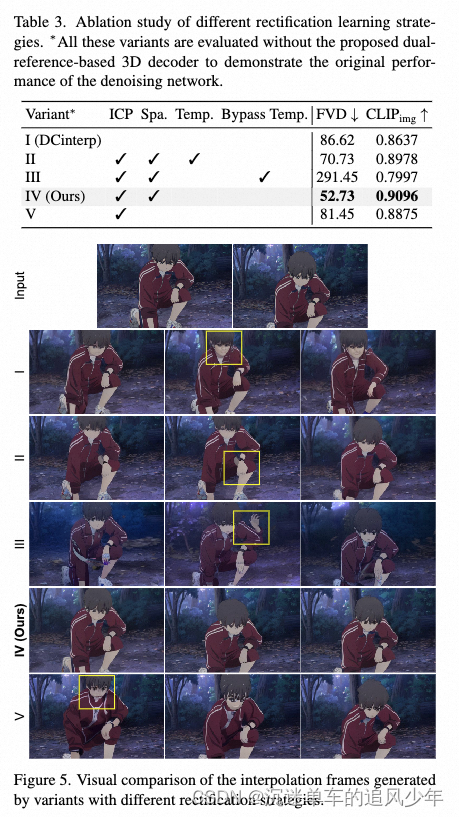
在论文《ToonCrafter: Generative Cartoon Interpolation》中提出了一种方案,名为“Toon Rectification Learning”。
其实就是通过实验证明,在微调过程中对image-context projector和空间层微调,并将其他层(时间层)冻结最有效。
下面是实验结果: