#创作灵感#
最近在一个系统招标正文中看到了一些国家标准,想要把文章下载下来,方便查阅,但是“国家标准全文公开系统”网站只提供了在线预览功能,没有提供下载功能,但是公司又需要文件,在网上找了一些办法,都没有成功。经过一些实践,发现通过tampermonkey插件写脚本可以获取,记录下来,分享给更多的人。
一、哪里可以免费获取“国家标准”文件?
(1)全国标准信息公共服务平台网址:https://std.samr.gov.cn/
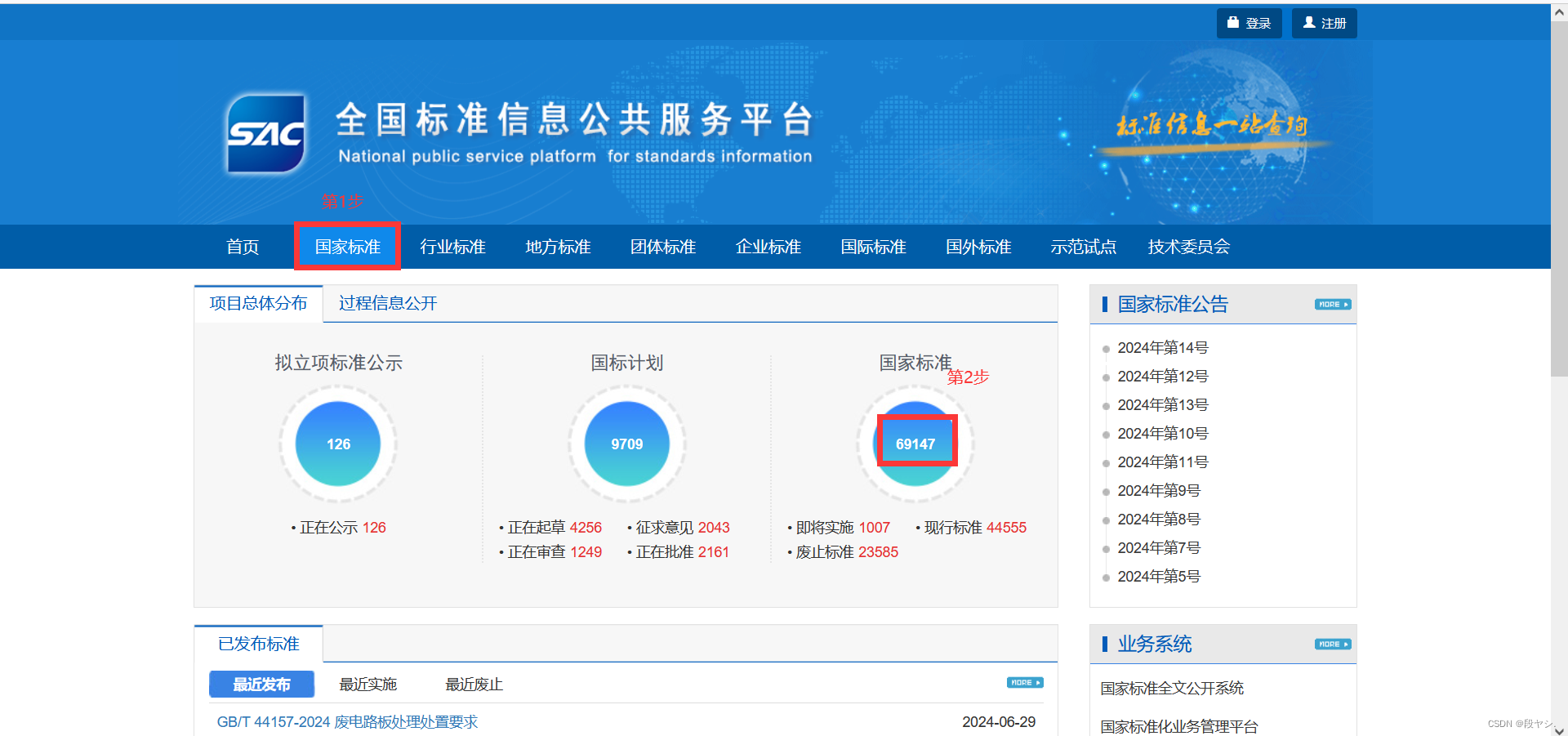
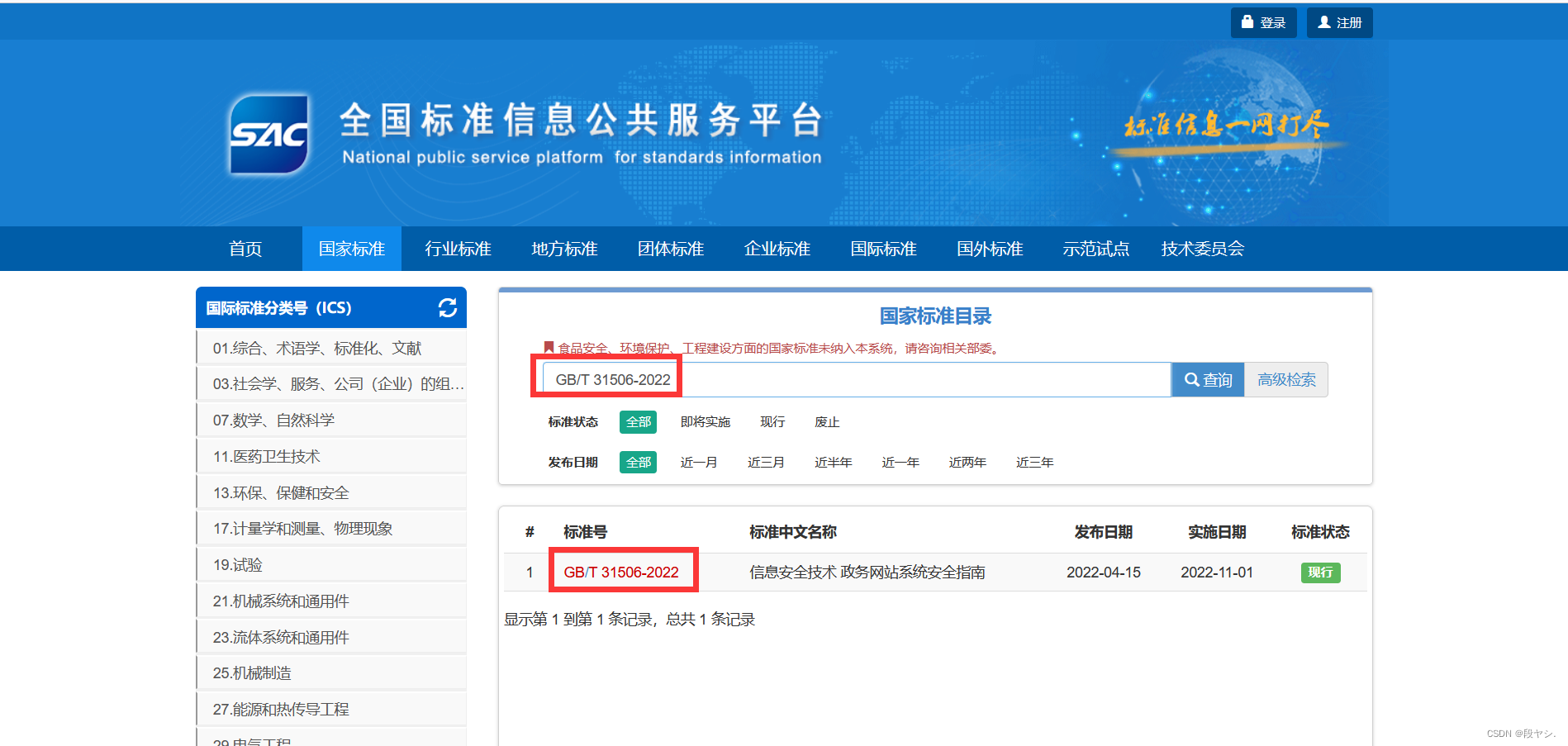
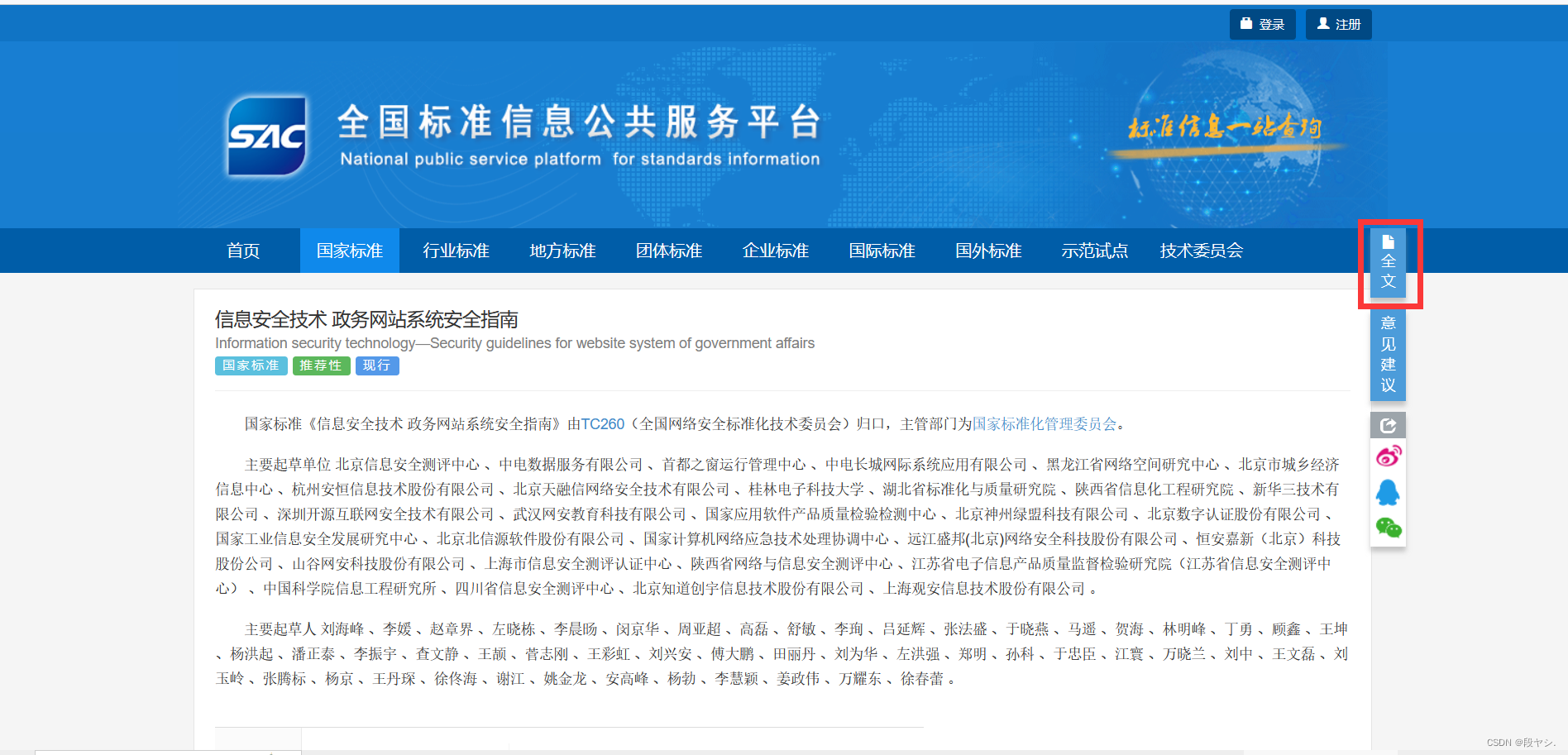

(2)国家标准全文公开系统:https://openstd.samr.gov.cn/bzgk/gb/index
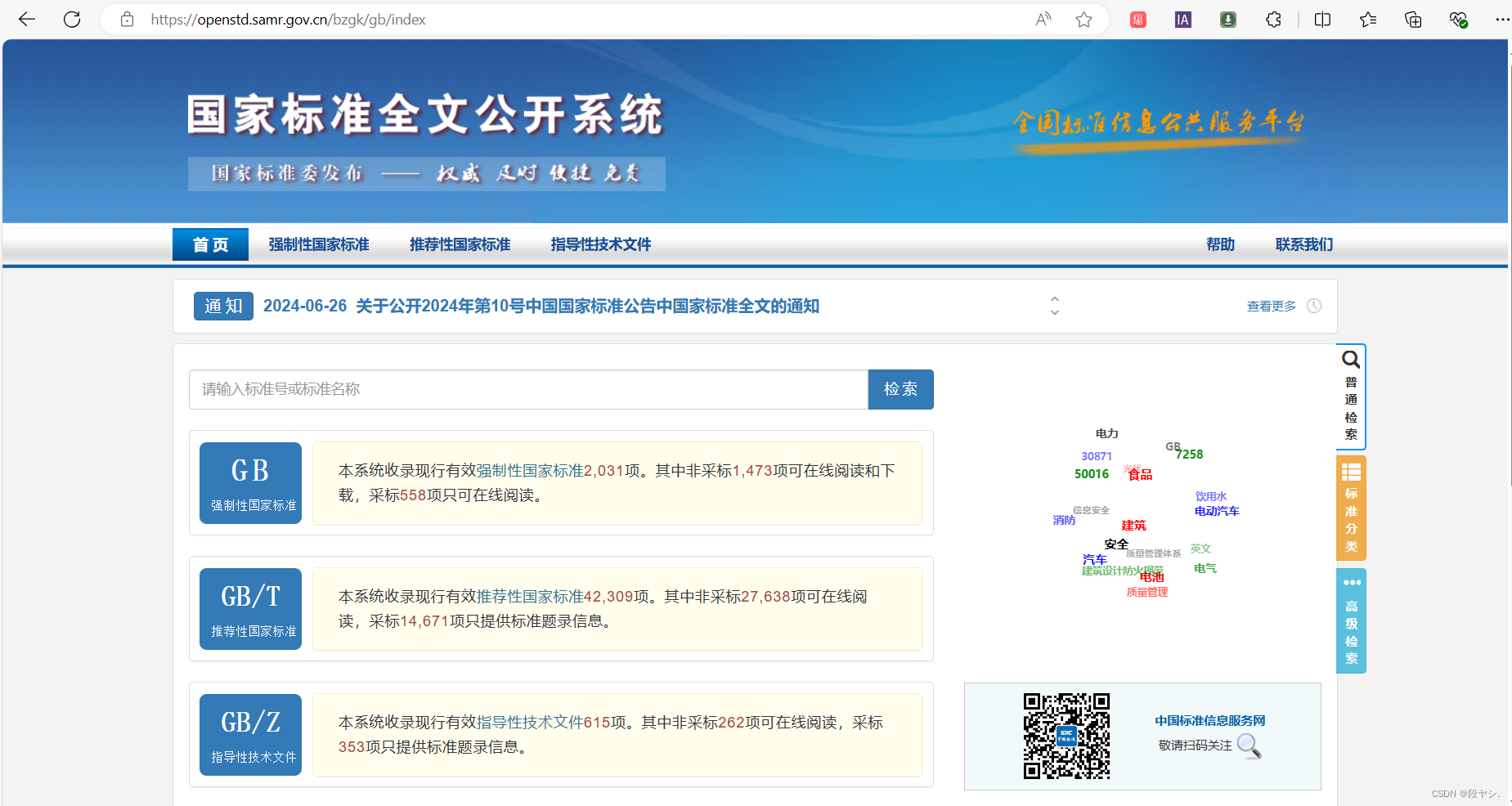
二、如何下载在线预览的国标(以Edge浏览器为例)?
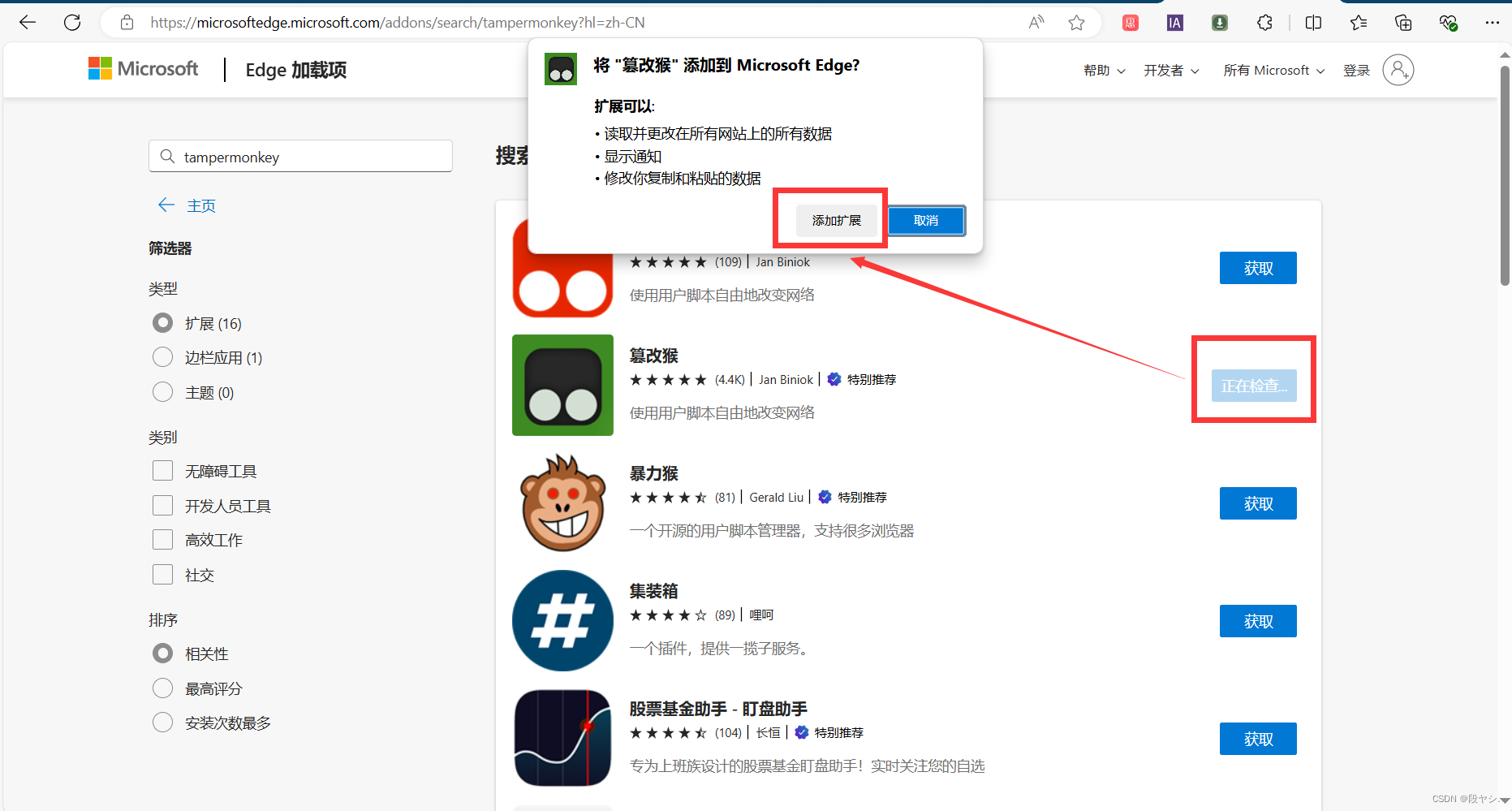
第一步:点击“扩展-获取Microsoft Edge扩展”;

第二步:搜索tampermonkey插件;

第三步:获取并添加tampermonkey(篡改猴,又称“油猴”);
第四步:添加成功页面,在扩展处可看到安装的tampermonkey;
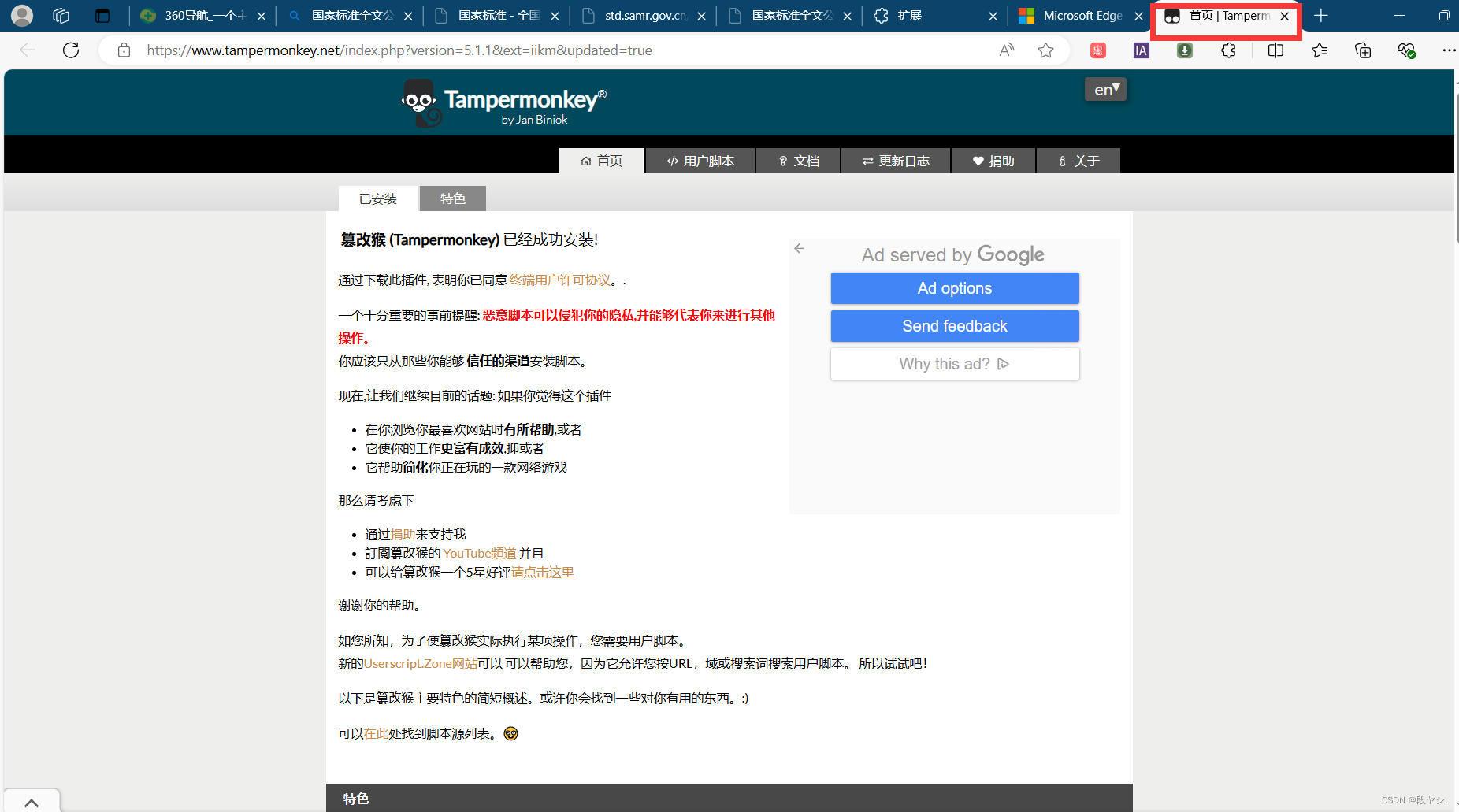
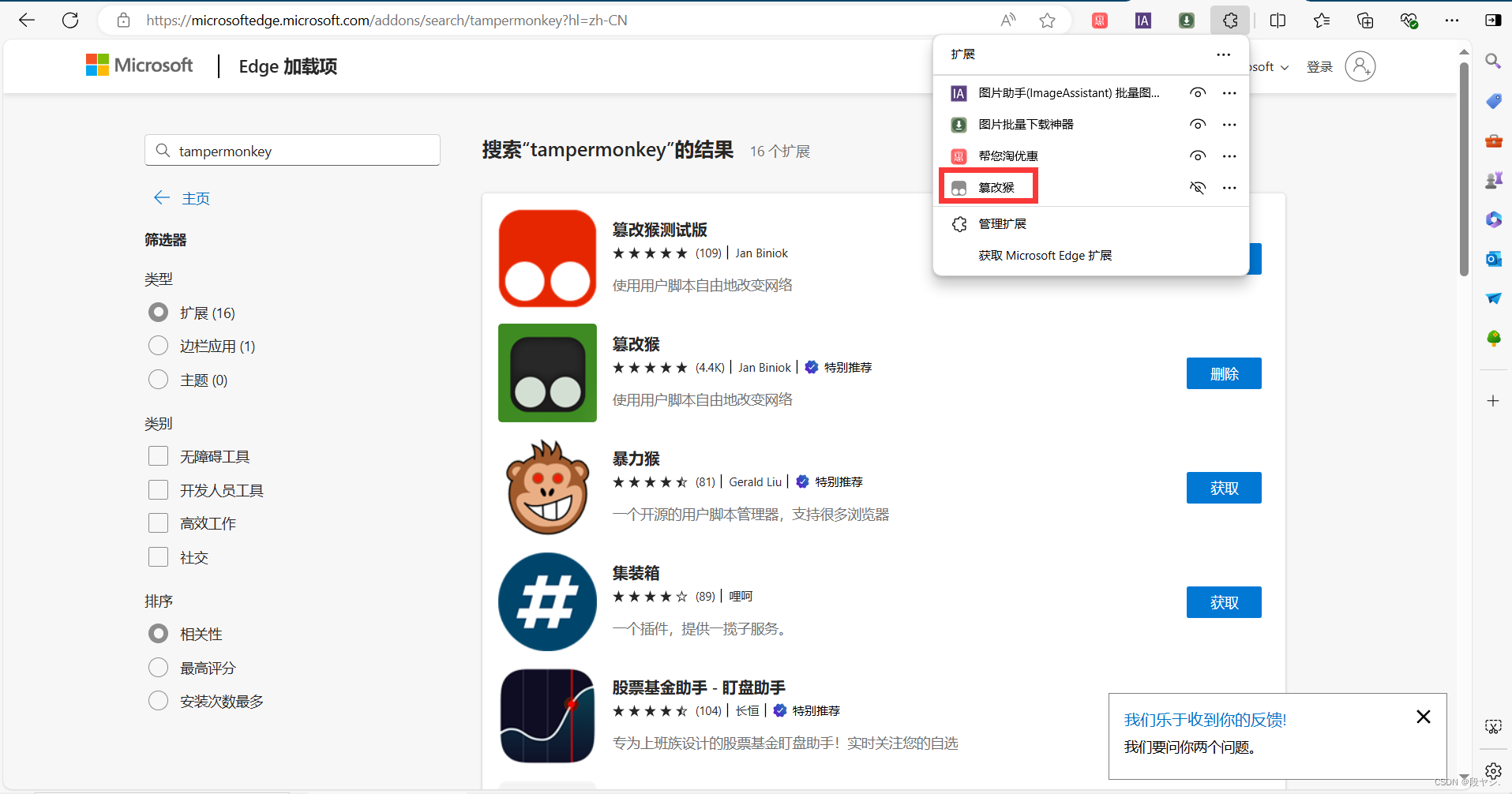
第五步:点击tampermonkey,选择“添加新脚本”;
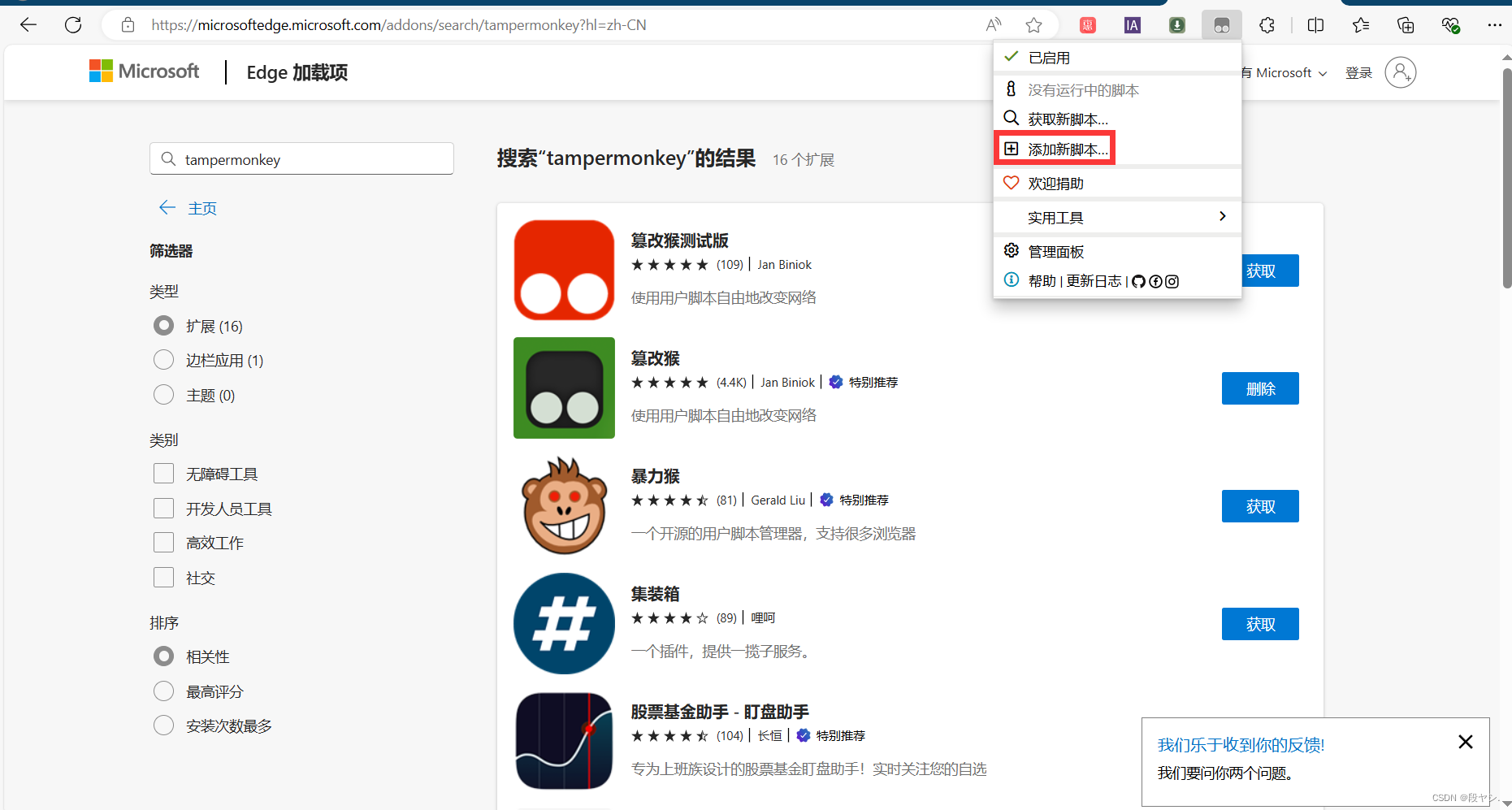
第六步:将下面这段代码复制到脚本编辑页面,Ctrl+S保存;
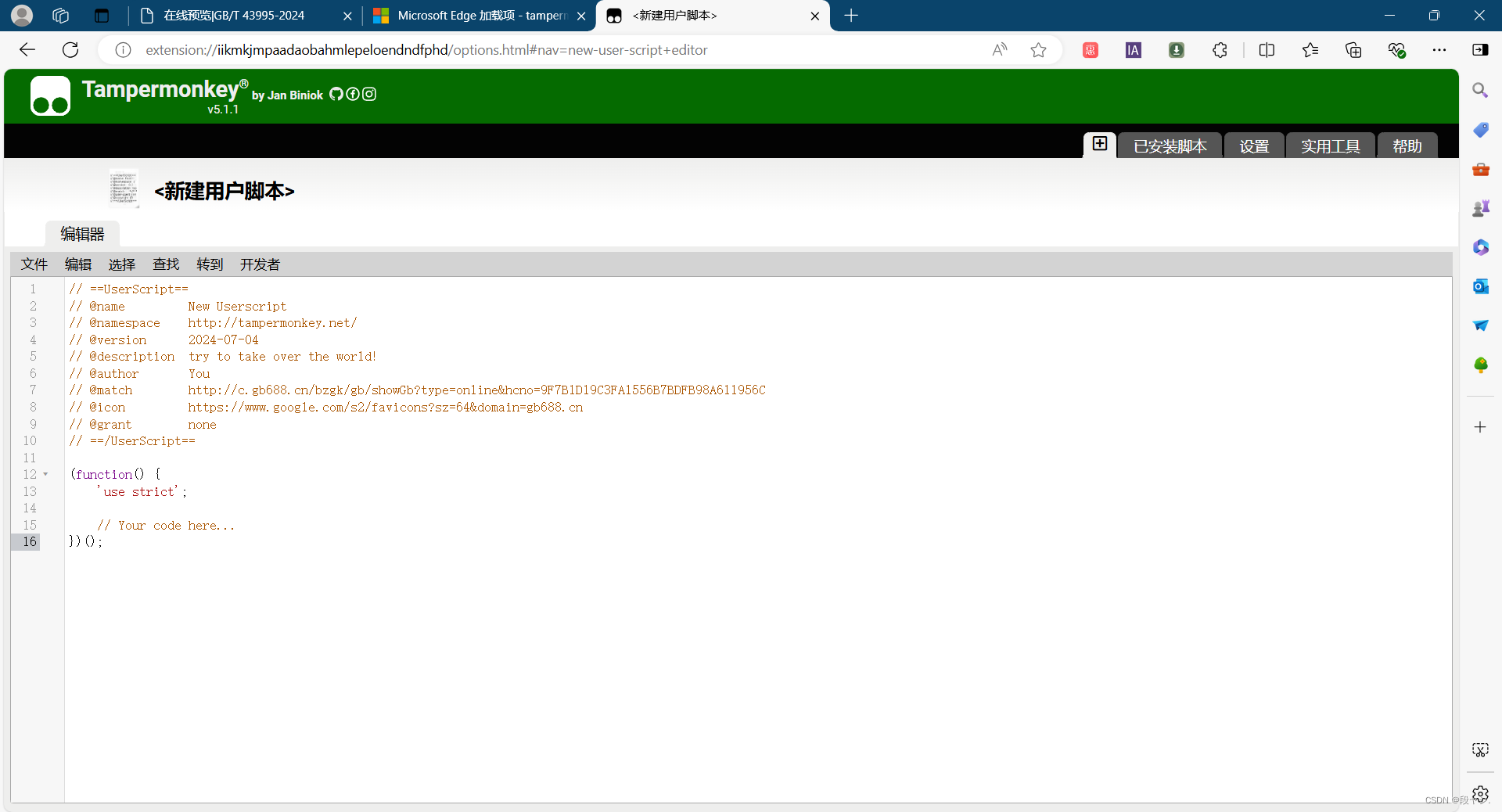
脚本:
// ==UserScript==
// @name 国标下载
// @namespace http://tampermonkey.net/
// @version 0.1
// @description try to take over the world!
// @author wcd
// @match http://c.gb688.cn/*
// @icon https://www.google.com/s2/favicons?sz=64&domain=gb688.cn
// @grant none
// @require https://code.jquery.com/jquery-3.6.0.min.js
//https://openstd.samr.gov.cn/bzgk/gb/index 国家标准全文公开系统
// ==/UserScript==
(function() {
'use strict';
$(function(){
$("head").append('<script src="https://cdnjs.cloudflare.com/ajax/libs/jspdf/2.5.1/jspdf.umd.min.js"></script>');
let my_script=`<script>
function px2Num(px) {
return Number(px.split("px")[0].toString());
}
function getPages(){
if( $("canvas[id^=canvas_]").length > 0 ) {
$("canvas[id^=canvas_]").delete();
}
var baseurl = "http://c.gb688.cn/bzgk/gb/";
var pagecount = $("div.page").length;
var pages = new Array(pagecount);
var pagebg = new Array(pagecount);
var title = $("title").text().split("|")[1].toString().trim();
var pheight = $("#0").css("height");
var pwidth = $("#0").css("width");
$(".page").each(function(i, elem) {
if (elem.hasAttribute("bg")) {
pagebg[i] = elem.getAttribute("bg");
} else {
pagebg[i] = $(elem).children("span").first().css("background-image").split('"')[
1].split(/\\//).slice(-1)[0];
}
});
//拼合图片
$(".page").each(function(i, elem) {
var canvasclone = $("canvas#canvas").clone();
canvasclone.attr("id","canvas_"+i).css("background-color","#FFFFFFFF");
$("#newimg").append(canvasclone);
var canvas = document.getElementById('canvas_'+i);
var ctx = canvas.getContext('2d');
ctx.fillStyle="white";
ctx.fillRect(0,0,px2Num(pwidth), px2Num(pheight));
$("#imgContainer").append("<img id=img_" + i + " src='" + baseurl+pagebg[i] + "' />")
var image = document.getElementById('img_'+i);
image.addEventListener('load', e => {
$(elem).children("span").each(function(j,s){
ctx.drawImage(image, -px2Num($(s).css("background-position-x")), -px2Num($(s).css("background-position-y")), 119, 168,
$(s).attr("class").split('-')[1]*119, $(s).attr("class").split('-')[2]*168, 119, 168);
});
});
});
}
function isimgComplete(imgs){
//$("img[id^=img_]")
flag = true;
for(i=0;i<imgs.length;i++){
flag=flag && imgs[i].complete;
}
return flag;
}
function downloadPDF(){
if( $("canvas[id^=canvas_]").length == 0 ) {
alert("请先点击获取页面!");
return;
}
var images = $("img[id^=img_]");
//alert(isimgComplete(images));
if(!isimgComplete(images)){
alert("页面尚未提取完,稍后再试");
return;
}
var pheight = $("#0").css("height");
var pwidth = $("#0").css("width");
const { jsPDF } = window.jspdf;
const pdf = new jsPDF('p','px',[px2Num(pwidth), px2Num(pheight)]);
var title = $("title").text().split("|")[1].toString().trim();
let [imgX, imgY] = [595.28, 841.89];
let imgHeight = imgX / (px2Num(pwidth) / px2Num(pheight));
$("canvas[id^=canvas_]").each(function(i,e){
pdf.addImage(document.getElementById('canvas_'+i).toDataURL('image/jpeg'), 'jpeg', 0, 0, px2Num(pwidth), px2Num(pheight), '', 'MEDDIUM');
//pdf.addImage(document.getElementById('canvas_'+i).toDataURL('image/png'), 'jpeg', 0, 0, imgX, imgHeight, '', 'SLOW');
pdf.addPage();
});
let targetPage = pdf.internal.getNumberOfPages();
pdf.deletePage(targetPage); // 删除最后一页
pdf.save(title + ".pdf");
}
function downloadPDF0(){
while($("canvas[id^=canvas_]").length < $(".page").length){
setTimeout(function(){
},1000);
}
}
</script>`;
let source_img = `
<div id="canvas_container">
<input type="button" value="获取页面" οnclick="getPages()"/>
<input type="button" value="下载pdf" οnclick="downloadPDF()"/>
</div>
<div id="imgContainer" style="display:none;"><img id="source" src=""></div>
<div id="newimg" width="1190px"></div>
<canvas id="canvas" width="1190px" height="1680px" style="display:none;"></canvas>`;
//let btn = `<input type="button" value="获取页面" οnclick="getPages()"/>
//<input type="button" value="下载pdf" οnclick="downloadPDF()"/>`;
let style = `
<style>
#canvas_container {
position: fixed;
height: 30px;
width: 150px;
top: 50px;
left: 10px;
border: 1px;
/*background-color: #00ff0099;*/
border-radius: 3px;
}
</style>
`;
$("head").append(style);
$("body").append(source_img);
$("body").append(my_script);
//$("body").append(btn);
//alert($("title").text());
});
})();
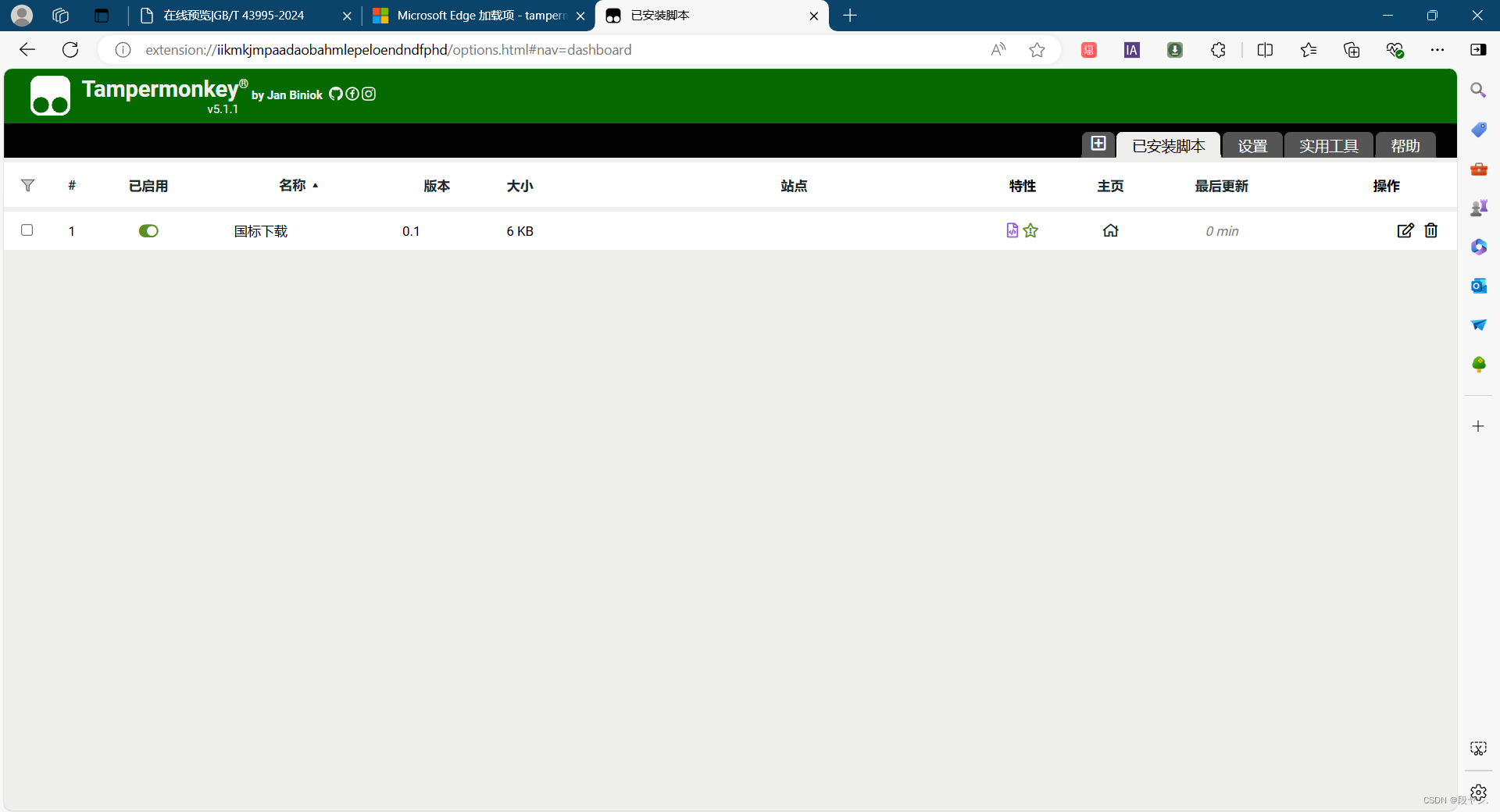
最后,点击在线预览的国标,会在左上角看到“获取页面”和“下载pdf”按钮;
点击“获取页面”,再点击“下载pdf”,就可以把文件下载到本地了。


三、避坑!!!这些方法不要再用了,没用。
方法1:直接Ctrl+S保存当前页面,
再次访问还是需要网络,大部分情况下,一直处于加载中,无法浏览;
方法2:使用开发者工具,选择“网络-XHR”,就可以看到pdf文件。
但如果深扒的话,你会发现,国标一个页面由很多不完整的内容组成,是看不到文件的;

方法3:使用开发者工具,打开控制台(console),输入PDFViewerApplication.save() 或者
PDFViewerApplication.download()就能下载。
开发者应该都知道,我们并没有创建PDFViewerApplication启动器,又怎么可以下载呢?

方法4:使用开发者工具,直接在控制台中写脚本,不可行,直接手写代码,不能复制粘贴;
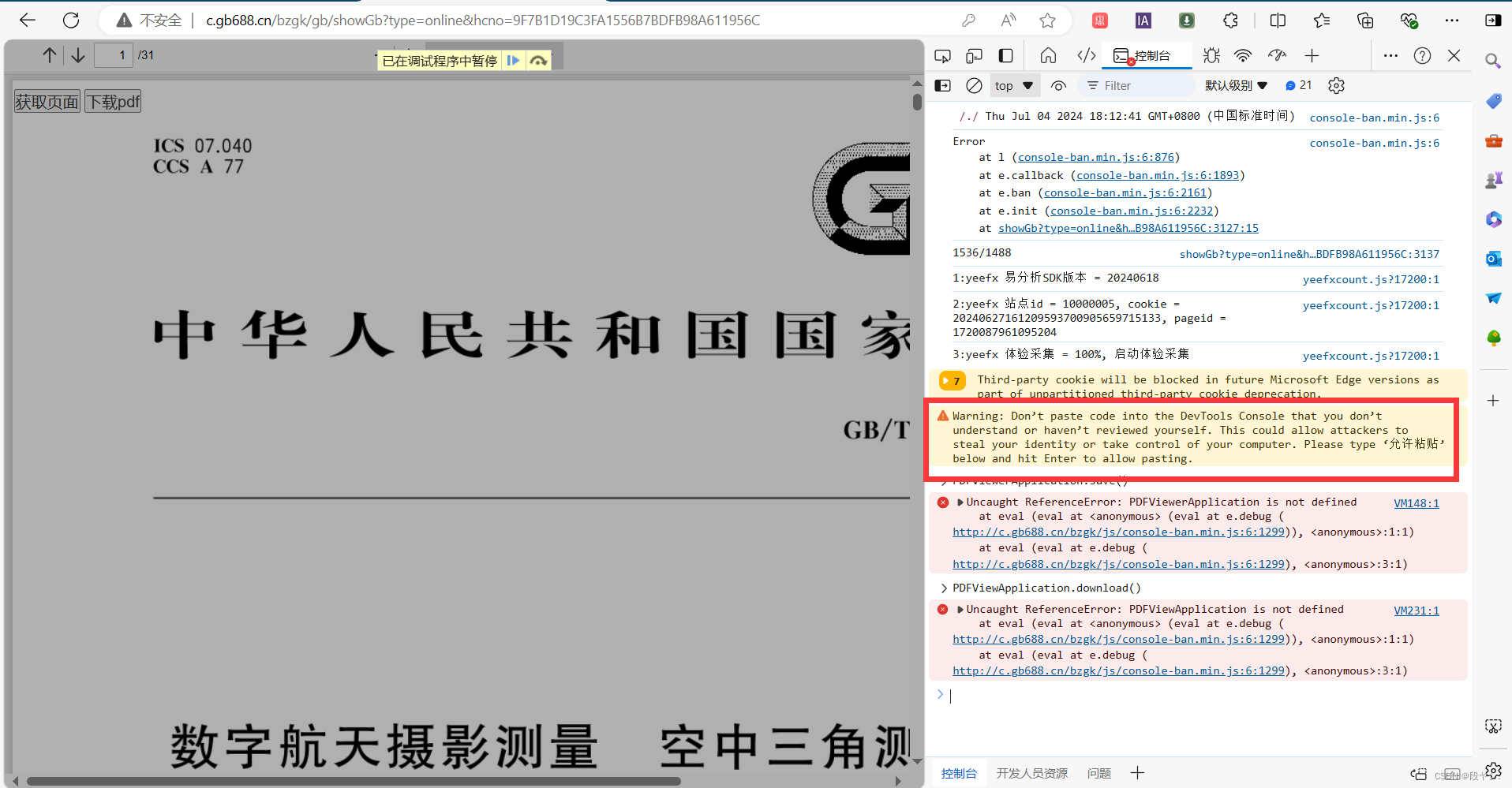
方法5:安装tampermonkey后,使用下面这段代码,我试过,不可行,具体原因没有深究;
// ==UserScript==
// @name gb688下载
// @namespace https://github.com/lzghzr/TampermonkeyJS
// @version 1.0.7
// @author lzghzr, chorar
// @description 下载gb688.cn上的国标文件
// @supportURL https://github.com/lzghzr/TampermonkeyJS/issues
// @match *://*.gb688.cn/bzgk/gb/showGb*
// @match *://*.samr.gov.cn/bzgk/gb/showGb*
// @connect c.gb688.cn
// @license MIT
// @grant none
// ==/UserScript==
(function() {
'use strict';
const online = document.getElementById("toolbarViewerRight");
if (online === null) {
throw '获取页面元素失败!';
}
const download = document.querySelector('button.toolbarButton.download');
if (download !== null) {
download.remove();
}
const GBdownload = document.createElement('button');
GBdownload.title = '下载';
GBdownload.className = 'toolbarButton download';
GBdownload.innerHTML = '<span>下载</span>';
online.insertAdjacentElement('afterbegin', GBdownload);
GBdownload.onclick = async () => {
PDFViewerApplication.pdfDocument.saveDocument(PDFViewerApplication.pdfDocument.annotationStorage).then(res =>{
const blob = new Blob([res], { type: "application/pdf" });
const blobUrl = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = blobUrl;
a.target = "_parent";
a.download = document.title.substr(document.title.indexOf('|')+1).replace("/", '_')+".pdf";
(document.body || document.documentElement).appendChild(a);
a.click();
}).catch(err =>{
console.log(err)
});
};
})();
![Spring学习03-[Spring容器核心技术IOC学习进阶]](https://i-blog.csdnimg.cn/direct/10957890f11d4a2bbfd5161063c717e2.png)