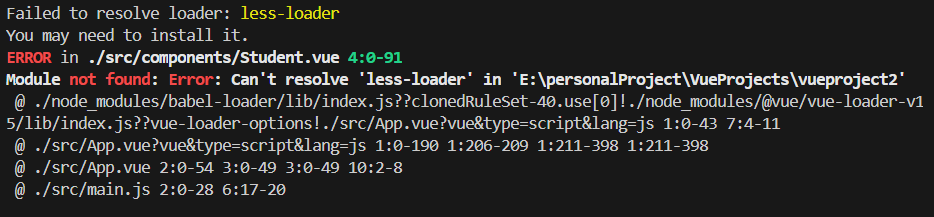
操作文件
使用loadtxt读取文本、csv文件
loadtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False, ndmin=0,encoding='bytes')
参数:
- fname:指定文件名称或字符串。支持压缩文件,包括gz、bz格式。
- dtype:数据类型。 默认float。object均可接收。
- comments:字符串或字符串组成的列表。表示**注释字符集开始的标志,默认为#。**加了#则不会读取
- delimiter:字符串。分隔符。数据之间用什么分割。
- converters:给一个字典。将特定列的数据转换为字典中对应的函数的浮点型数据。例如将空值转换为0,默认为空。
- skiprows:跳过特定行数据。例如跳过前1行(可能是标题或注释,注释也算行数)。默认为0。
- usecols:元组。用来指定要读取数据的列,第一列为0。例如(1, 3, 5),默认为空。
- unpack:布尔型。指定是否转置数组,如果为真则转置,默认为False。
- ndmin:整数型。指定返回的数组至少包含特定维度的数组。值域为0、1、2,默认为0。
- encoding:编码, 确认文件是gbk还是utf-8 格式
返回:从文件中读取的数组。
数据:
姓名,年龄,性别,身高
小王,22,男,170
小张,25,女,165
小花,19,女,167
小谭,20,男,169
小胡,21,女,161
小余,19,女,159
小陈,27,男,177
分析:由于每一列的数据类型都不一样,需要自定义数据类型。
datatype = np.dtype([('name',np.str_),('age','i1'),('gender','U1'),('height','i2')])
#计算平均年龄方法一
data = np.loadtxt('has_title.csv',dtype =datatype,delimiter=',',skiprows=1)
#读取绝对路径时: r'D:/XXX/has_title.csv'或单斜杠转化为双斜杠
print(data['age'].mean())#计算女生的平均身高
isgirl = data['gender']=='女'
print(isgirl)
data['height'][isgirl]
data['height'][isgirl].mean()
"""
[False True True False True True False]
array([165, 167, 161, 159], dtype=int16)
163.0
"""#计算平均年龄方法二
data = np.loadtxt('has_title.csv',dtype =int,usecols=(1,3),delimiter=',',skiprows=1)
print(data.mean(axis=0)[0])#读取指定的列
user_info = np.dtype([('age','i1'),('height','i2')])
print(user_info)
#使用自定义的数据类型,读取数据
data = np.loadtxt('has_title.csv',dtype = user_info,delimiter = ',',skiprows=1,usecols = (1,3))
print(data)
对于空数据的处理方法

如上图中小谭的年龄没有数据,空的数据转换成浮点数会报错
使用参数converters
converters = {列索引:处理的函数,key:value}
# 1. 定义数据类型
def parse_age(age):try:return int(age)except:return 0data =np.loadtxt('has_empty_data.csv',delimiter=',',skiprows=1,usecols=1,converters={1:parse_age})
data
converters={1:parse_age} 的含义是为 CSV 文件中的第二列(索引为 1)应用一个自定义的转换函数 parse_age。np.loadtxt 函数通过 converters 参数允许您指定一个字典,其中键是列的索引,值是用于转换该列数据的函数。