每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

近年来,图像生成模型(T2I)如Stable Diffusion和Imagen在根据文本描述生成高分辨率图像方面取得了显著进展。然而,许多生成的图像仍然存在诸如伪影(如物体变形、文本和身体部位失真)、与文本描述不一致以及美学质量低下等问题。例如,某个输入提示为“熊猫骑摩托车”,但生成的图像却显示了两只熊猫,并伴有其他不需要的伪影,如熊猫的鼻子和车轮辐条变形。
受人类反馈强化学习(RLHF)在大型语言模型(LLMs)中的成功启发,研究者们探索了从人类反馈中学习(LHF)是否能帮助改善图像生成模型。在应用于LLMs时,人类反馈可以包括简单的偏好评分(如“点赞或踩”、“A或B”),也可以是更详细的回应,如重写有问题的答案。然而,目前LHF在T2I中的应用主要集中在简单的响应上,如偏好评分,因为修复有问题的图像通常需要高级技能(如编辑),这既困难又耗时。
在“富人类反馈的文本到图像生成”中,研究人员设计了一种获取具体且易于获取的富人类反馈的方法。他们展示了LHF在T2I中的可行性和优势。主要贡献有三点:
- 研究者们策划并发布了RichHF-18K,这是一个覆盖18K张由Stable Diffusion变体生成图像的人类反馈数据集。
- 他们训练了一个多模态变压器模型——Rich Automatic Human Feedback(RAHF),用于预测各种类型的人类反馈,如不可信评分、伪影位置热图以及丢失或未对齐的文本/关键词。
- 他们展示了预测的丰富人类反馈可以用来改善图像生成,这种改进还可以推广到其他模型(如Muse)。
这是第一个用于最先进的文本到图像生成的丰富反馈数据集和模型。
富人类反馈的收集
从Pick-a-Pic训练数据集中根据PaLI自动创建的属性选择图像,以确保类别和类型的良好多样性,最终得到17K张图像。研究人员将这17K张样本随机分为训练集(16K样本)和验证集(1K样本)。此外,他们在Pick-a-Pic测试集中收集了丰富的人类反馈,作为测试集。最终,RichHF-18K数据集包含16K训练样本、1K验证样本和1K测试样本。
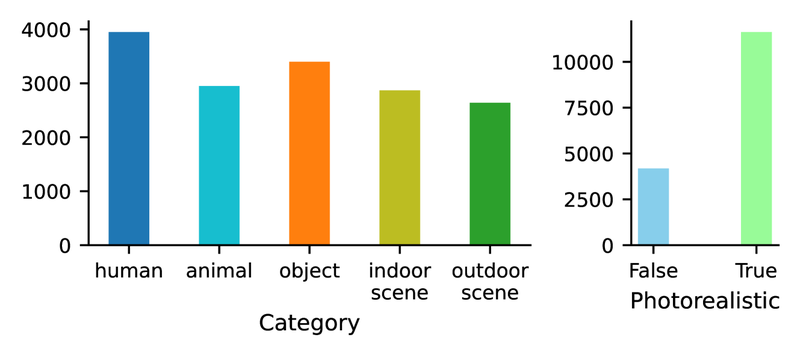
对于每张生成的图像,注释者首先检查图像并阅读文本提示,然后在图像上标记任何不可信、伪影或与文本提示不一致的位置。最后,注释者对未对齐的关键词以及可信度、图像-文本对齐、美学和整体质量的四种评分进行打分,分别使用5分Likert量表。

富人类反馈的预测
RAHF模型的架构基于ViT和T5X模型,受先前大型视觉语言模型(PaLI和Spotlight)的启发。文本信息通过自注意力机制传播到图像标记以预测文本未对齐评分和热图(伪影或未对齐的区域),而视觉信息传播到文本标记以进行更好的视觉感知文本编码,从而解码文本未对齐序列。最好的模型使用单头预测每种类型的反馈,如热图、评分和未对齐序列。研究人员为每个任务在提示中添加了任务字符串(如“不可信热图”)以提示模型特定任务。
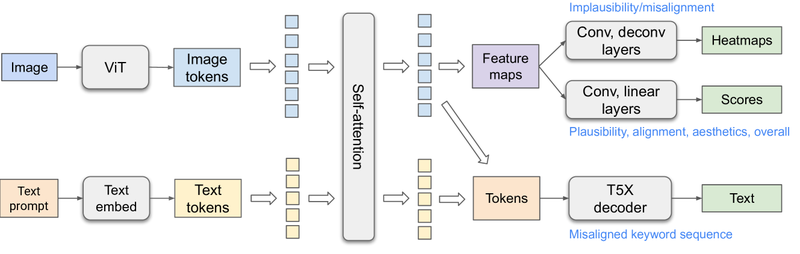


从丰富的人类反馈中学习
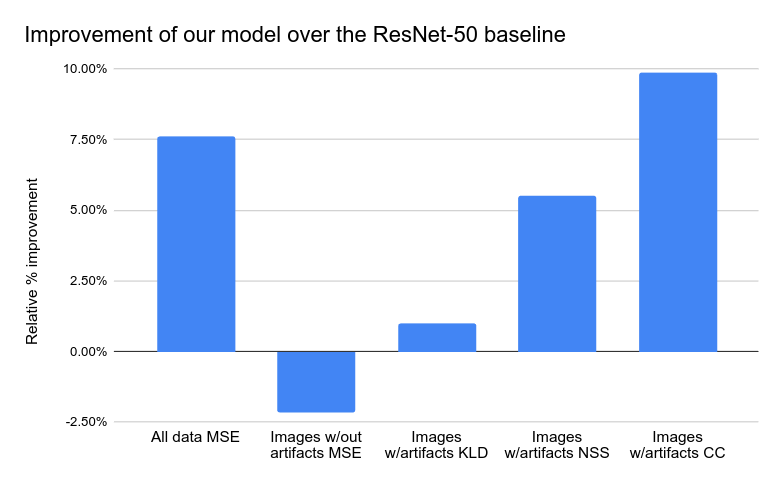
预测的丰富人类反馈(如评分和热图)可以用来改善图像生成。例如,通过用预测的评分来微调生成模型。研究人员首先通过RAHF预测的评分筛选Muse模型的结果,创建一个高质量的数据集,然后使用该数据集通过LoRA微调方法微调Muse模型。对比评估显示,使用RAHF可信度评分微调的Muse生成的图像比原始Muse具有显著更少的伪影。

此外,研究人员展示了使用RAHF美学评分作为分类器指导来改进Latent Diffusion模型的示例,这表明每种细化的评分都可以改善生成模型的不同方面。

总之,研究人员发布了RichHF-18K,这是第一个用于文本到图像生成的丰富人类反馈数据集。他们设计并训练了一个多模态变压器来预测丰富的人类反馈,并展示了使用这些反馈改进图像生成的一些实例。未来的工作包括改进数据集以提高注释质量(尤其是在未对齐热图上),并收集更多生成模型(如Imagen和DALL-E)的丰富人类反馈,同时探索更多使用丰富人类反馈的方法。他们希望RichHF-18K和初始模型能够激发进一步在图像生成领域学习人类反馈的研究方向。
下载 https://github.com/google-research/google-research/tree/master/richhf_18k