1、创建scrapy项目
首先在自己的跟目录文件下执行命令:
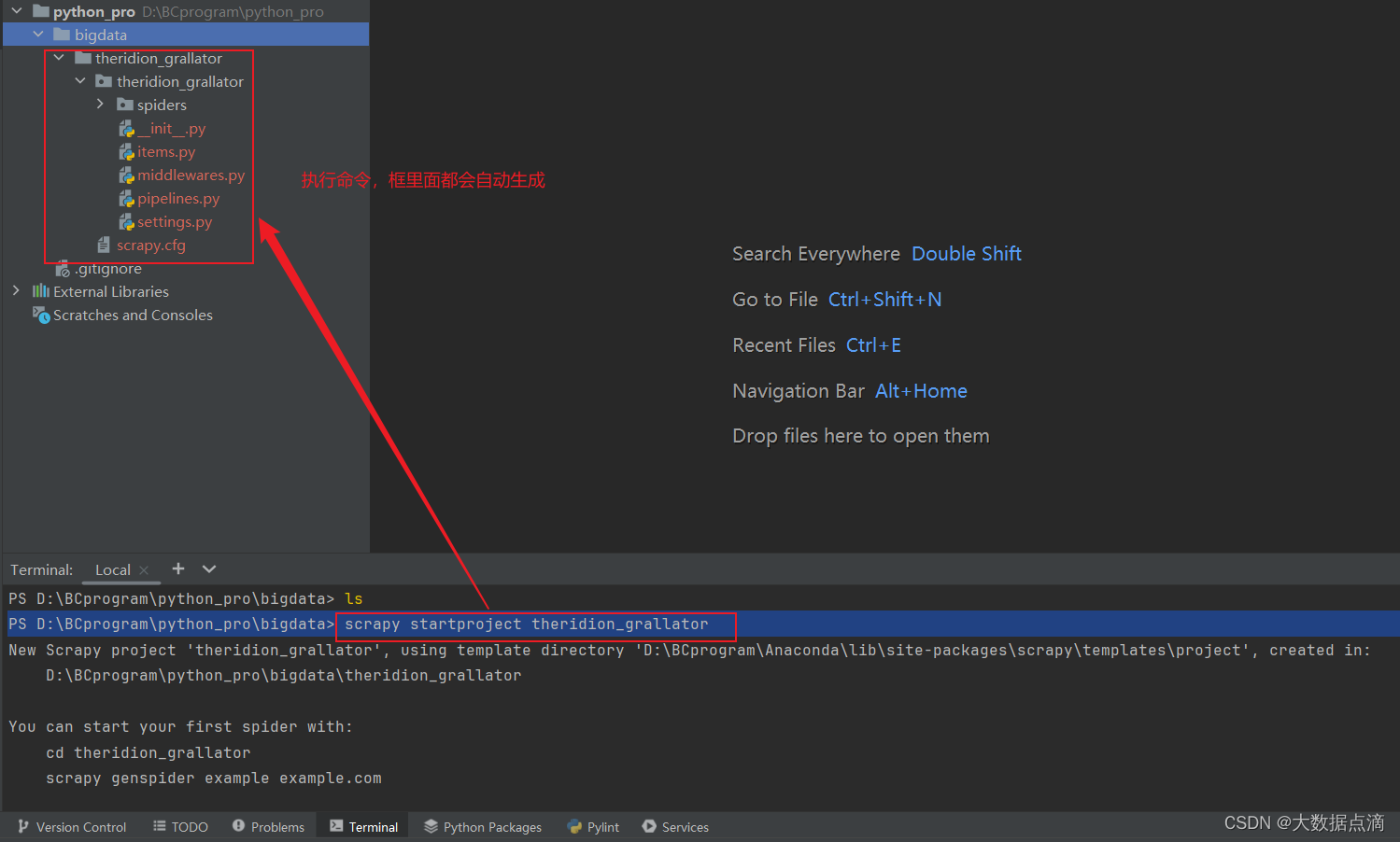
PS D:\BCprogram\python_pro\bigdata> scrapy startproject theridion_grallatorscrapy + startproject + 项目名 具体执行操作如下:1、创建项目目录:Scrapy会在当前工作目录下创建一个名为 theridion_grallator 的新目录。这个目录将成为你的Scrapy项目的根目录。
2、生成基本文件结构:在 theridion_grallator 目录下,Scrapy会自动生成一套标准的文件和子目录结构,包括但不限于:theridion_grallator/: 项目根目录。theridion_grallator/theridion_grallator/: 包含项目的设置文件 (settings.py)、爬虫模块(spiders/)、中间件 (middlewares.py)、管道 (pipelines.py) 等核心组件。theridion_grallator/items.py: 定义爬虫项目中数据模型的地方。theridion_grallator/pipelines.py: 数据处理的管道定义,用于清洗或存储爬取的数据。theridion_grallator/settings.py: 项目的配置文件,可以设置如用户代理、下载延迟等参数。theridion_grallator/spiders/: 存放所有爬虫脚本的目录,初始时可能为空或包含一个示例爬虫。scrapy.cfg: 项目的配置文件,位于根目录,用于指定项目的设置模块和其他元数据
2、创建一个爬虫程序
首先进入项目文件夹下,然后输入命令:
scrapy genspider 爬虫程序的名称 要爬取网站的域名
D:\BCprogram\python_pro\bigdata\theridion_grallator> scrapy genspider game_4399 4399.com
当你运行 scrapy genspider game_4399 4399.com 命令时,Scrapy将执行以下操作:
1、创建爬虫文件:Scrapy会在 theridion_grallator/spiders/ 目录下创建一个名为 game_4399.py 的新文件。这个文件将包含你新建的爬虫的代码。
2、生成爬虫模板:打开 game_4399.py 文件,你会看到Scrapy已经为你生成了一个基本的爬虫模板,包括爬虫类 Game_4399 和一些默认方法,如 start_requests()、parse() 等。
3、配置爬虫域:Scrapy在爬虫类中设置了 allowed_domains 属性,将其值设为 ['4399.com'],这意味着爬虫将只对4399.com域名下的URL进行爬取。
4、设置起始URL:在 start_requests() 方法中,Scrapy通常会生成一个请求(Request 对象)到指定的域名(这里为 4399.com),作为爬虫开始爬取的起点。
5、定义解析函数:parse() 方法是默认的回调函数,当Scrapy收到响应后会调用它来解析网页内容。你需要根据4399.com网站的HTML结构来定制这个方法,以提取所需的数据。
3、编写爬虫程序
在game_4399.py文件中编写爬虫代码,代码如下
import scrapyclass Game4399Spider(scrapy.Spider):name = "game_4399" # 爬虫程序的名称allowed_domains = ["4399.com"] # 允许爬取的域名# 默认情况下是:https://4399.com# 但是我们不从首页开始爬取,所以改一下URLstart_urls = ["https://4399.com/flash/"] # 一开始爬取的URLdef parse(self, response): # 该方法用于对response对象进行数据解析# print(response) # <200 http://www.4399.com/flash/># print(response.text) # 打印页面源代码# response.xpath() # 通过xpath解析数据# response.css() # 通过css解析数据# 获取4399小游戏的游戏名称# txt = response.xpath('//ul[@class="n-game cf"]/li/a/b/text()')# txt 列表中的每一项是一个Selector:# <Selector query='//ul[@class="n-game cf"]/li/a/b/text()' data='逃离克莱蒙特城堡'>]# 要通过extract()方法拿到data中的内容# print(txt)# txt = response.xpath('//ul[@class="n-game cf"]/li/a/b/text()').extract()# print(txt) # 此时列表中的元素才是游戏的名字# 也可以先拿到每个li,然后再提取名字lis = response.xpath('//ul[@class="n-game cf"]/li')for li in lis:# name = li.xpath('./a/b/text()').extract()# # name 是一个列表# print(name) # ['王城霸业']# 一般我们都会这么写:li.xpath('./a/b/text()').extract()[0]# 但是这样如果列表为空就会报错,所以换另一种写法# extract_first方法取列表中的第一个,如果列表为空,返回Nonename = li.xpath('./a/b/text()').extract_first()print(name) # 王城霸业category = li.xpath('./em/a/text()').extract_first() # 游戏类别date = li.xpath('./em/text()').extract_first() # 日期print(category, date)# 通过yield向管道传输数据dic = {'name': name,'category': category,'date': date}# 可以认为这里是把数据返回给了管道pipeline,# 但是实际上是先给引擎,然后引擎再给管道,只是这个过程不用我们关心,scrapy会自动完成# 这里的数据会在管道程序中接收到yield dic4、运行scrapy爬虫程序
在终端输入命令,就可以看到爬虫程序运行结果。
scrapy crawl 爬虫程序名称
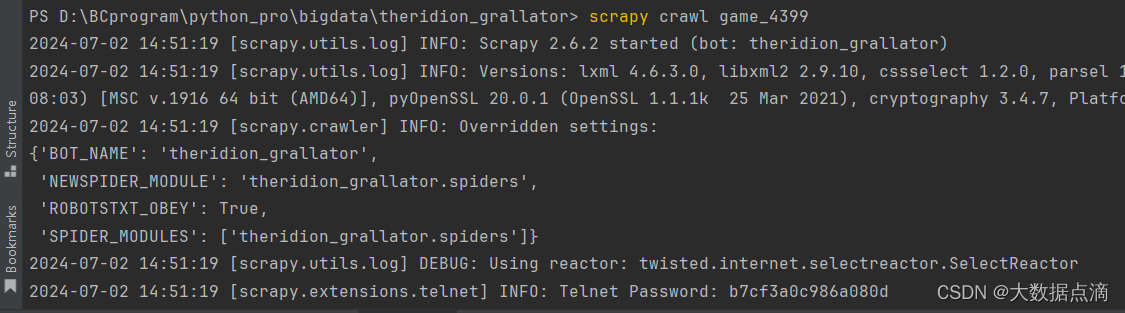
D:\BCprogram\python_pro\bigdata\theridion_grallator> scrapy crawl game_4399
当你运行 scrapy crawl 爬虫程序名称 命令时,Scrapy执行以下操作来启动指定的爬虫:
1、加载项目设置:Scrapy首先读取项目根目录下的 settings.py 文件,加载项目配置。
2、初始化引擎:Scrapy初始化爬虫引擎,准备开始爬取流程。
3、启动爬虫:根据提供的爬虫名称,Scrapy会找到对应的爬虫类(通常在 spiders 目录下的Python文件中),并实例化这个爬虫。
4、执行start_requests:Scrapy调用爬虫类中的 start_requests 方法,这个方法返回一个或多个 Request 对象,表示要发起的HTTP请求。
5、调度请求:每个 Request 对象被添加到调度器(Scheduler)中,等待被发送到下载器(Downloader)。
6、下载网页:下载器接收到调度器的请求,下载网页内容,并生成一个 Response 对象。
7、解析响应:下载完成后的 Response 对象被传递给爬虫的解析函数(通常是 parse 或其他自定义的回调函数),在这里,爬虫解析HTML,提取数据,可能还会生成新的 Request 对象,形成新的爬取循环。
8、处理数据:提取到的数据通常会经过中间件的处理,然后传递给管道(Pipelines),在那里进行进一步的清洗、验证和持久化存储。
9、错误处理:如果在爬取过程中遇到错误,比如网络问题或服务器返回错误状态码,Scrapy会使用中间件和爬虫的错误处理逻辑来处理这些问题。
10、监控和控制:Scrapy提供了一套日志系统,可以记录爬取过程中的信息,还可以通过信号和扩展来实现更复杂的控制逻辑。
11、爬虫结束:当没有更多的请求待处理,或者达到预设的停止条件(如最大深度、最大请求数等),爬虫会停止运行。