本指南演示了如何从 Python 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后你将在 Kibana 中查看日志事件发生的实时可视化。虽然此示例使用的是 Python,但这种监控日志输出的方法适用于多种客户端类型。查看可用的 ECS 日志记录插件列表。

在今天的展示中,我将使用 Elastic Stack 8.14.1 来进行展示。
前提
要完成这些步骤,你需要在系统上安装 Python 以及 Python 日志库的 Elastic Common Schema (ECS) 记录器。
要安装 ecs-logging-python,请运行:
python -m pip install ecs-logging准备
Elasticsearch 及 Kibana 安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
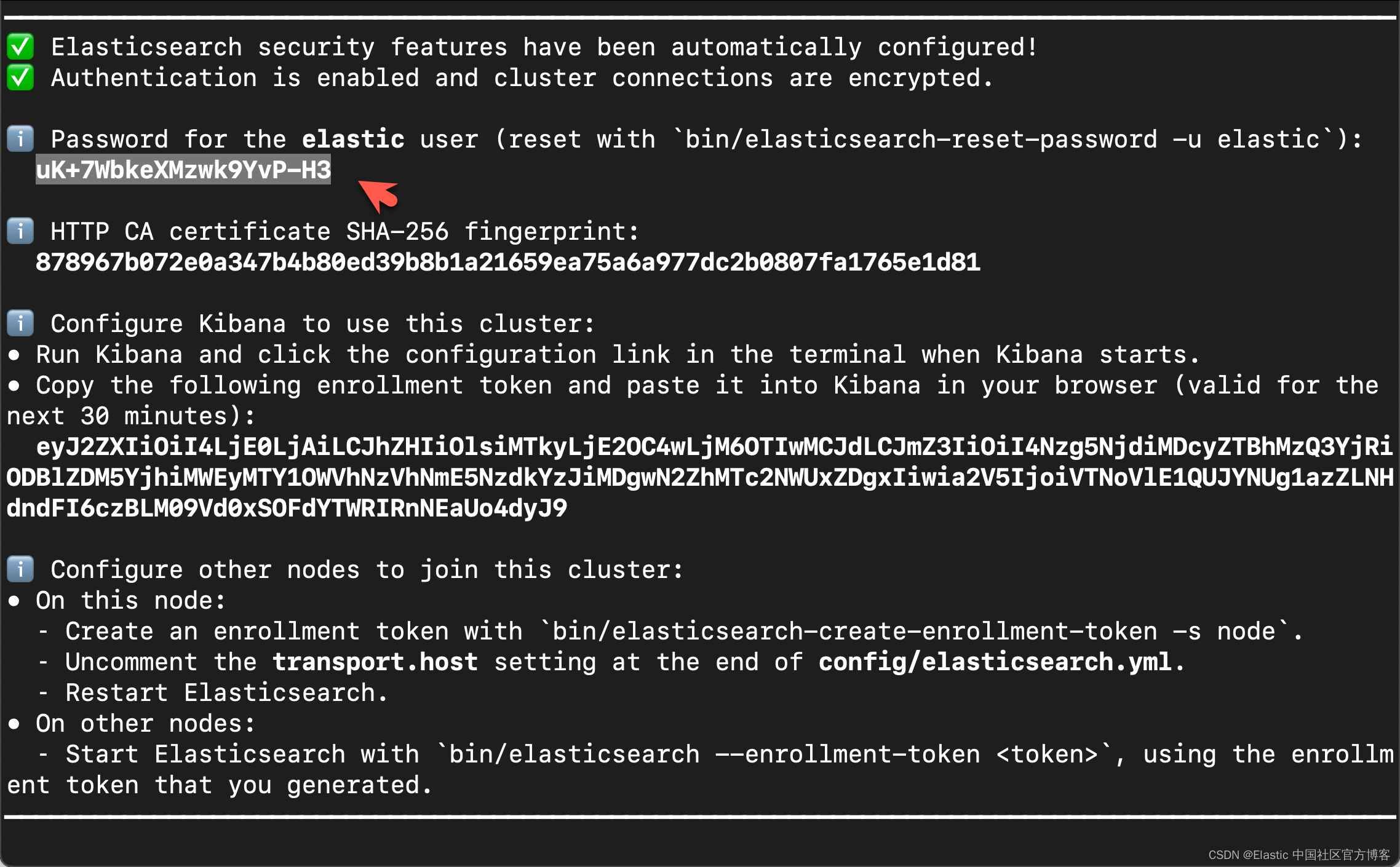
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
生成 API key
在今天的配置中,我们将使用 API key 来配置 Filebeat。我们来在 Kibana 中申请一个 key:
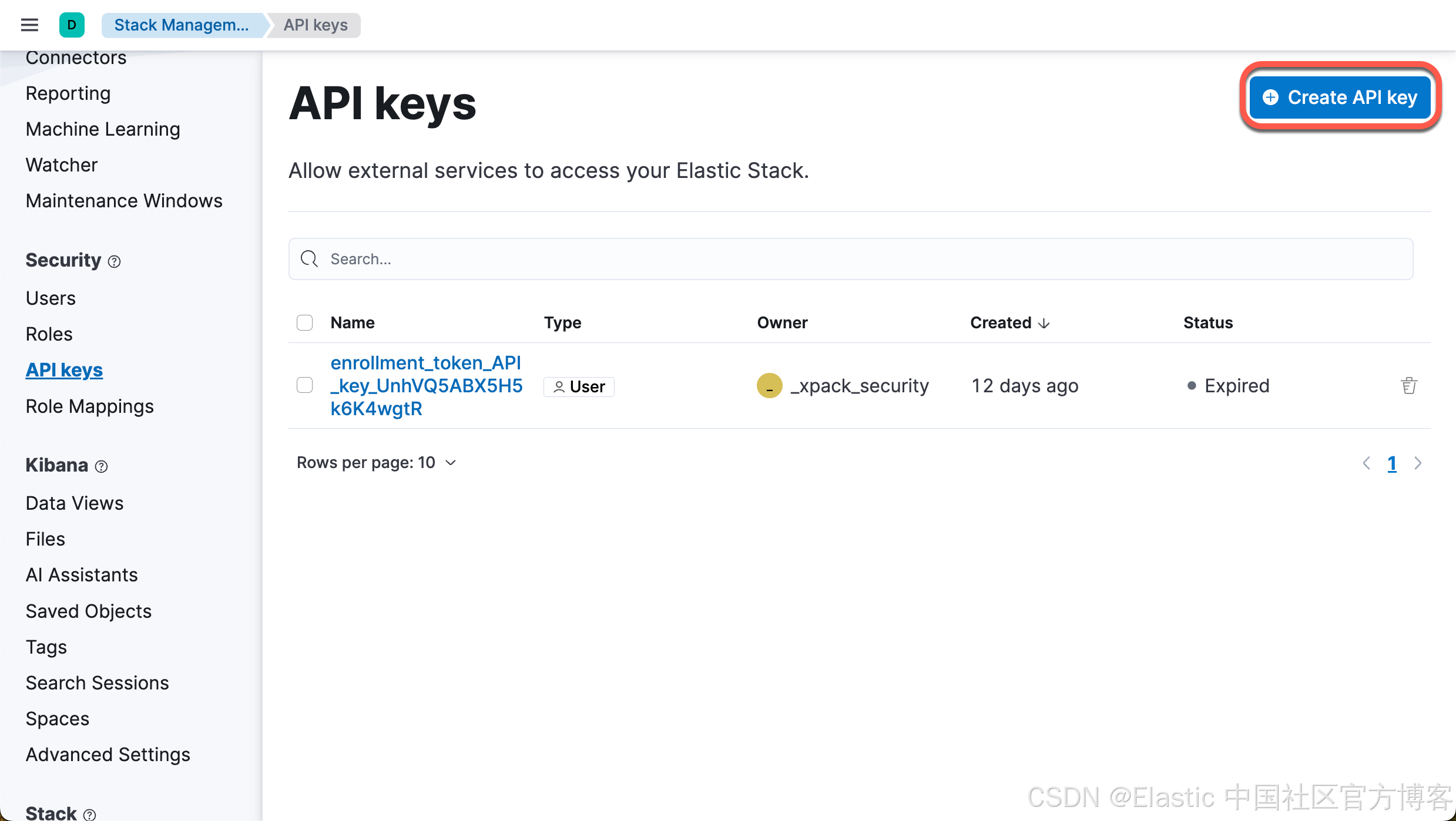
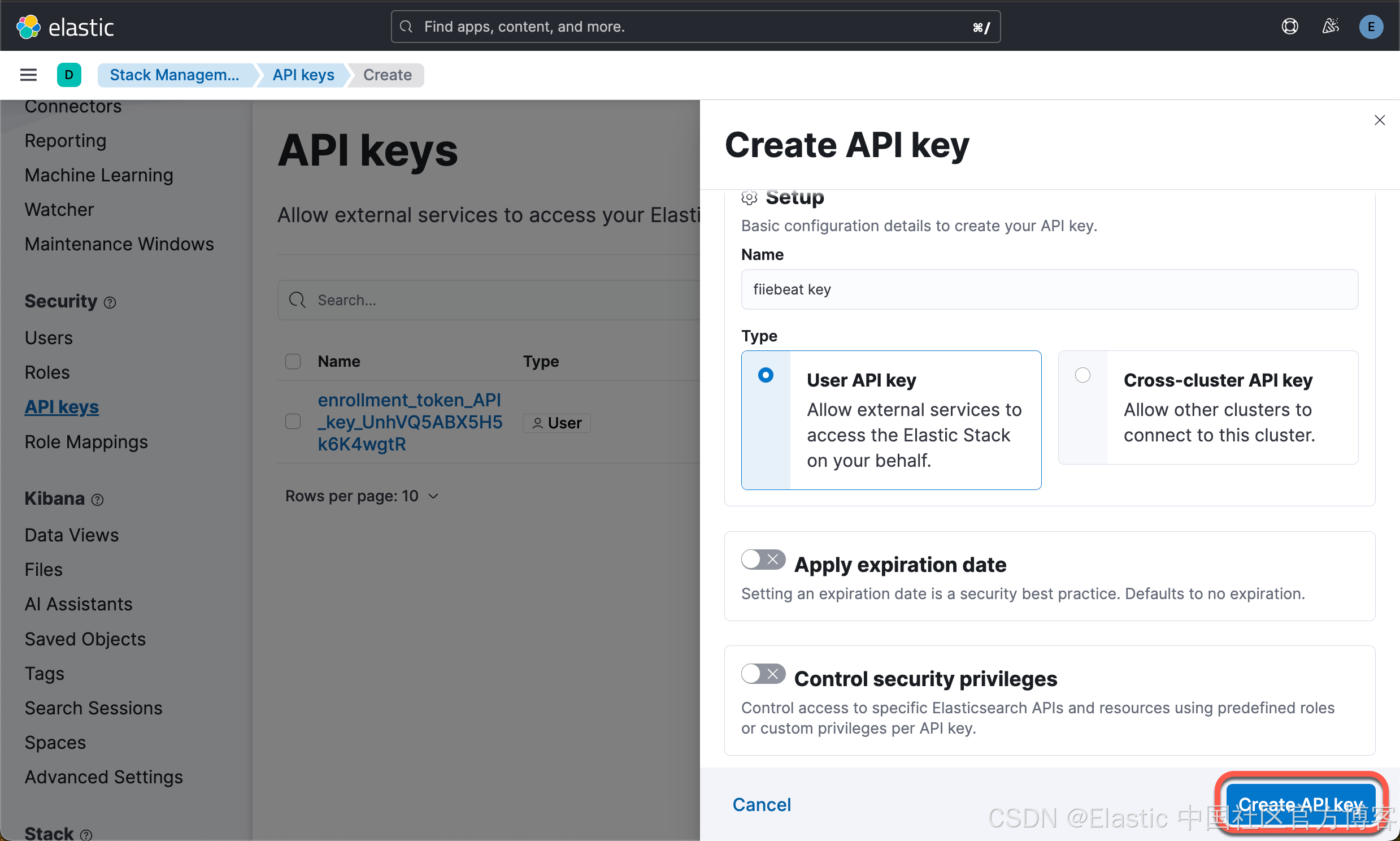
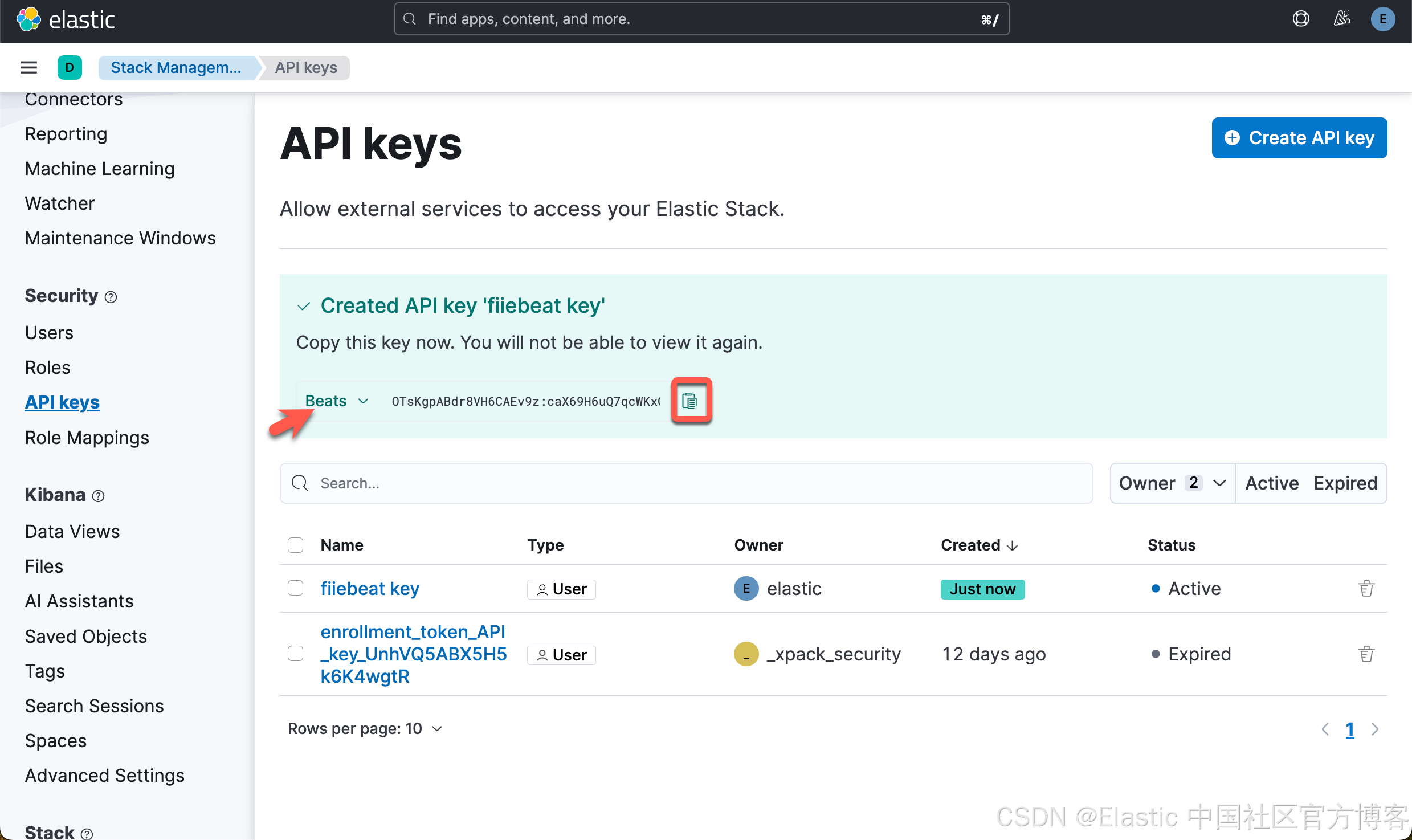
我们点击上面的 copy 按钮来拷贝 API key:OTsKgpABdr8VH6CAEv9z:caX69H6uQ7qcWKxQxeopuQ
我们也可以使用如下的命令来活动 API key:
POST /_security/api_key
{"name": "filebeat-api-key","role_descriptors": {"logstash_read_write": {"cluster": ["manage_index_templates", "monitor"],"index": [{"names": ["filebeat-*"],"privileges": ["create_index", "write", "read", "manage"]}]}}
}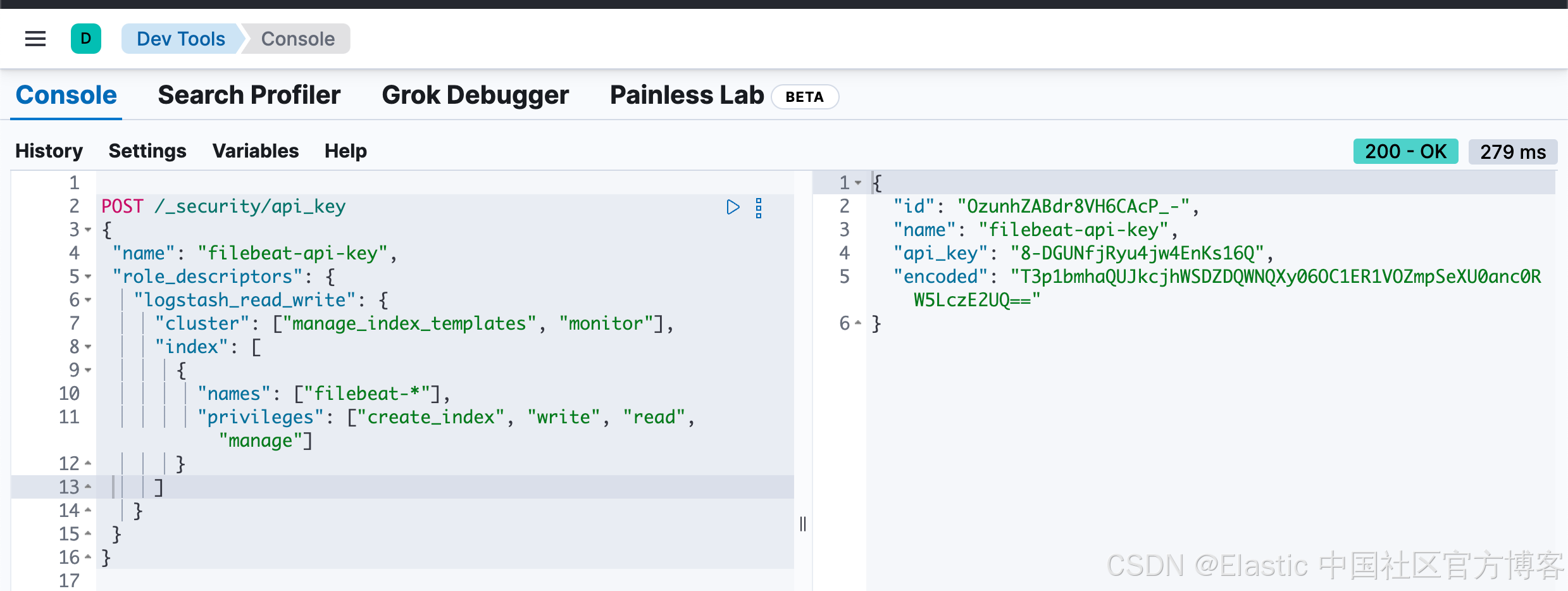
上面的命令将会得到如下所示的回复:
{"id": "OzunhZABdr8VH6CAcP_-","name": "filebeat-api-key","api_key": "8-DGUNfjRyu4jw4EnKs16Q","encoded": "T3p1bmhaQUJkcjhWSDZDQWNQXy06OC1ER1VOZmpSeXU0anc0RW5LczE2UQ=="
}安装 Filebeat
我们可以到地址下载 Filebeat,并加压缩来进行安装:
$ pwd
/Users/liuxg/elastic
$ ls
elasticsearch-8.14.1 kibana-8.14.1-darwin-aarch64.tar.gz
elasticsearch-8.14.1-darwin-aarch64.tar.gz logstash-8.14.1-darwin-aarch64.tar.gz
filebeat-8.14.1-darwin-aarch64.tar.gz metricbeat-8.14.1-darwin-aarch64.tar.gz
kibana-8.14.1
$ tar xzf filebeat-8.14.1-darwin-aarch64.tar.gz
$ cd filebeat-8.14.1-darwin-aarch64
$ ls
LICENSE.txt fields.yml filebeat.yml modules.d
NOTICE.txt filebeat kibana
README.md filebeat.reference.yml module安装命令如上所示,我们可以看到一个关于 Filebeat 的配置文件 filebeat.yml 文件。在下面的步骤中,我们将对它进行配置。
创建 Python 脚本来生成日志
在此步骤中,你将使用 Python 的标准日志模块创建一个以 JSON 格式生成日志的 Python 脚本。
1)在本地目录中,创建一个新文件 elvis.py 并保存以下内容:
$ pwd
/Users/liuxg/python
$ cd python-logs
$ ls
$ code elvis.py我们把如下的内容粘贴到 elvis.py 文件中去:
elvis.py
#!/usr/bin/pythonimport logging
import ecs_logging
import time
from random import randint#logger = logging.getLogger(__name__)
logger = logging.getLogger("app")
logger.setLevel(logging.DEBUG)
handler = logging.FileHandler('elvis.json')
handler.setFormatter(ecs_logging.StdlibFormatter())
logger.addHandler(handler)print("Generating log entries...")messages = ["Elvis has left the building.",#"Elvis has left the oven on.","Elvis has two left feet.","Elvis was left out in the cold.","Elvis was left holding the baby.","Elvis left the cake out in the rain.","Elvis came out of left field.","Elvis exited stage left.","Elvis took a left turn.","Elvis left no stone unturned.","Elvis picked up where he left off.","Elvis's train has left the station."]while True:random1 = randint(0,15)random2 = randint(1,10)if random1 > 11:random1 = 0if(random1<=4):logger.info(messages[random1], extra={"http.request.body.content": messages[random1]})elif(random1>=5 and random1<=8):logger.warning(messages[random1], extra={"http.request.body.content": messages[random1]})elif(random1>=9 and random1<=10):logger.error(messages[random1], extra={"http.request.body.content": messages[random1]})else:logger.critical(messages[random1], extra={"http.request.body.content": messages[random1]})time.sleep(random2)此 Python 脚本会随机生成十二条日志消息中的一条,连续生成,间隔为 1 到 10 秒。日志消息会写入文件 elvis.json,每条消息都带有时间戳、日志级别(信息、警告、错误或严重)和其他数据。为了给日志数据添加一些变化,Info 消息 "Elvis has left the building" 被设置为最可能的日志事件。在代码中,如果 random1 > 11,那么 random1 就被设置为 0。从这里我们可以看出来。
为简单起见,只有一个日志文件,它会写入 elvis.py 所在的本地目录。在生产环境中,你可能有多个日志文件,与不同的模块和记录器相关联,并且可能存储在 /var/log 或类似目录中。要了解有关在 Python 中配置日志的更多信息,请查看 Python 的日志记录工具。
使用带有 ECS 字段的 JSON 格式编写日志可以轻松解析和分析,并与其他应用程序实现标准化。随着日志中捕获的数据量和类型随时间推移而扩大,标准、易于解析的格式变得越来越重要。
除了每个日志条目所包含的标准字段外,还有一个额外的 http.request.body.content 字段。这个额外的字段只是为了给你提供一些额外的、有趣的数据,同时也是为了演示如何向日志数据添加可选字段。查看 ECS 字段参考以获取可用字段的完整列表。
2)让我们测试一下 Python 脚本。在保存 elvis.py 的位置打开一个终端实例并运行以下命令:
python elvis.py$ pwd
/Users/liuxg/python/python-logs
$ python elvis.py
Generating log entries...
脚本运行约 15 秒后,输入 CTRL + C 停止它。查看新生成的 elvis.json。它应该包含一个或多个类似这样的条目:

3)确认 elvis.py 按预期运行后,可以删除 elvis.json。
配置 Filebeat
在 <localpath>/filebeat-<version>/(其中 <localpath> 是 Filebeat 安装的目录,<version> 是 Filebeat 版本号)中打开 filebeat.yml 配置文件进行编辑。我们可以参考文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单” 中描述的配置 Metricbeat 来配置 Filebeat。
配置 Filebeat inputs
Filebeat 有多种收集日志的方法。在本例中,你将手动配置日志收集。
在 filebeat.yml 的 filebeat.inputs 部分中,将 enabled: 设置为 true,并将 paths: 设置为日志文件的位置。在本例中,设置你保存 elvis.py 的同一目录:
filebeat.yml

你可以指定通配符 (*) 来表示应读取指定目录中的所有日志文件。你还可以使用通配符从多个目录读取日志。例如 /var/log/*/*.log。
在上面,你需要根据自己的配置进行相应的修改。
添加 JSON 输入选项
Filebeat 的输入配置选项包括几个用于解码 JSON 消息的设置。日志文件是逐行解码的,因此每行包含一个 JSON 对象非常重要。
对于此示例,Filebeat 使用以下四个解码选项。
json.keys_under_root: truejson.overwrite_keys: truejson.add_error_key: truejson.expand_keys: true要了解有关这些设置的更多信息,请查看 Filebeat 参考中的 JSON 输入配置选项和解码 JSON 字段。
将四个 JSON 解码选项附加到 filebeat.yml 的 Filebeat 输入部分,以便该部分现在如下所示:
filebeat.yml

配置 Elasticsearch
我们需要为 Filebeat 的 output 进行配置。我们的配置如下:
filebeat.yml

我们需要根据自己的配置修改上面的值。为了验证修改的正确性,我们可以使用如下的命令进行验证:
$ pwd
/Users/liuxg/elastic/filebeat-8.14.1-darwin-aarch64
$ ./filebeat test config
Config OK
上面表明,我们的配置(yml 文件的格式)都是没有任何问题的。
我们使用如下的命令来测试和 Elasticsearch 的链接是否有问题:
$ pwd
/Users/liuxg/elastic/filebeat-8.14.1-darwin-aarch64
$ ./filebeat test output
elasticsearch: https://localhost:9200...parse url... OKconnection...parse host... OKdns lookup... OKaddresses: 127.0.0.1dial up... OKTLS...security: server's certificate chain verification is enabledhandshake... OKTLS version: TLSv1.3dial up... OKtalk to server... OKversion: 8.14.1
上面显示,我们的链接是成功的。
注意:如果你是使用 API 命令获得的,你也可以使用如下的格式来修改上面的 API key 配置格式。将你的 API 密钥信息添加到 filebeat.yml 的 Elasticsearch 输出部分,就在 output.elasticsearch: 下方。使用格式 <id>:<api_key>。如果你的结果如本例所示,请输入 OzunhZABdr8VH6CAcP_-:8-DGUNfjRyu4jw4EnKs16Q。

完成 Filebeat 的设置
Filebeat 附带预定义资产,用于解析、索引和可视化数据。要加载这些资产,请从 Filebeat 安装目录运行以下命令:
截止此时,我们已经配置了我们所需要的一切。在下面,我们可以开始我们的展示了。
./filebeat setup -e
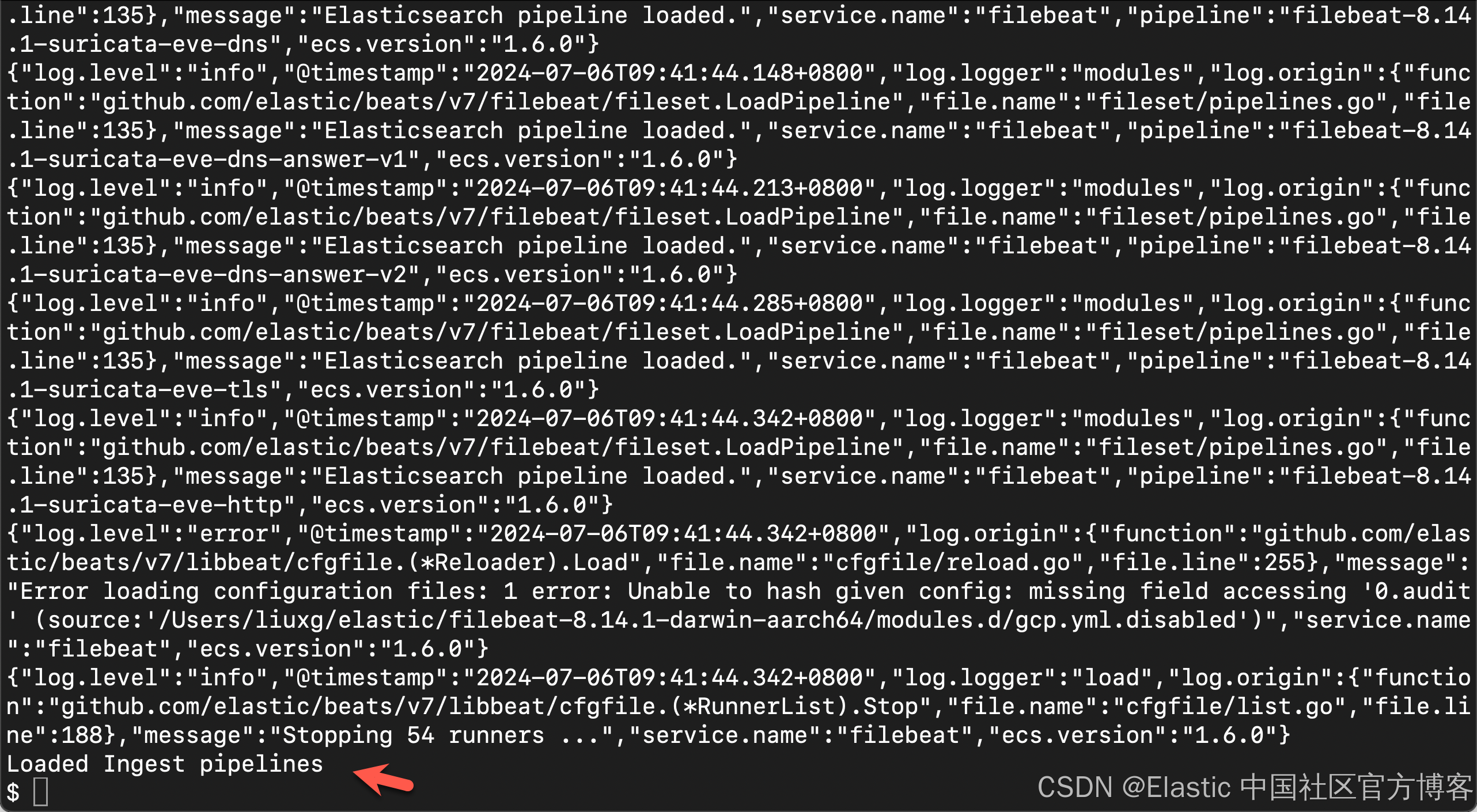
重要:根据安装位置、环境和本地权限等变量,你可能需要更改 filebeat.yml 的所有权。你还可以尝试以 root 身份运行该命令:sudo ./filebeat setup -e,或者你可以通过运行带有 --strict.perms=false 选项的命令来禁用严格权限检查。
设置过程需要几分钟。如果一切顺利,你将收到一条确认消息:
Loaded Ingest pipelinesFilebeat data view(以前称为 index pattern)现在可在 Elasticsearch 中使用。我们可以在 Kibana 中进行查看:
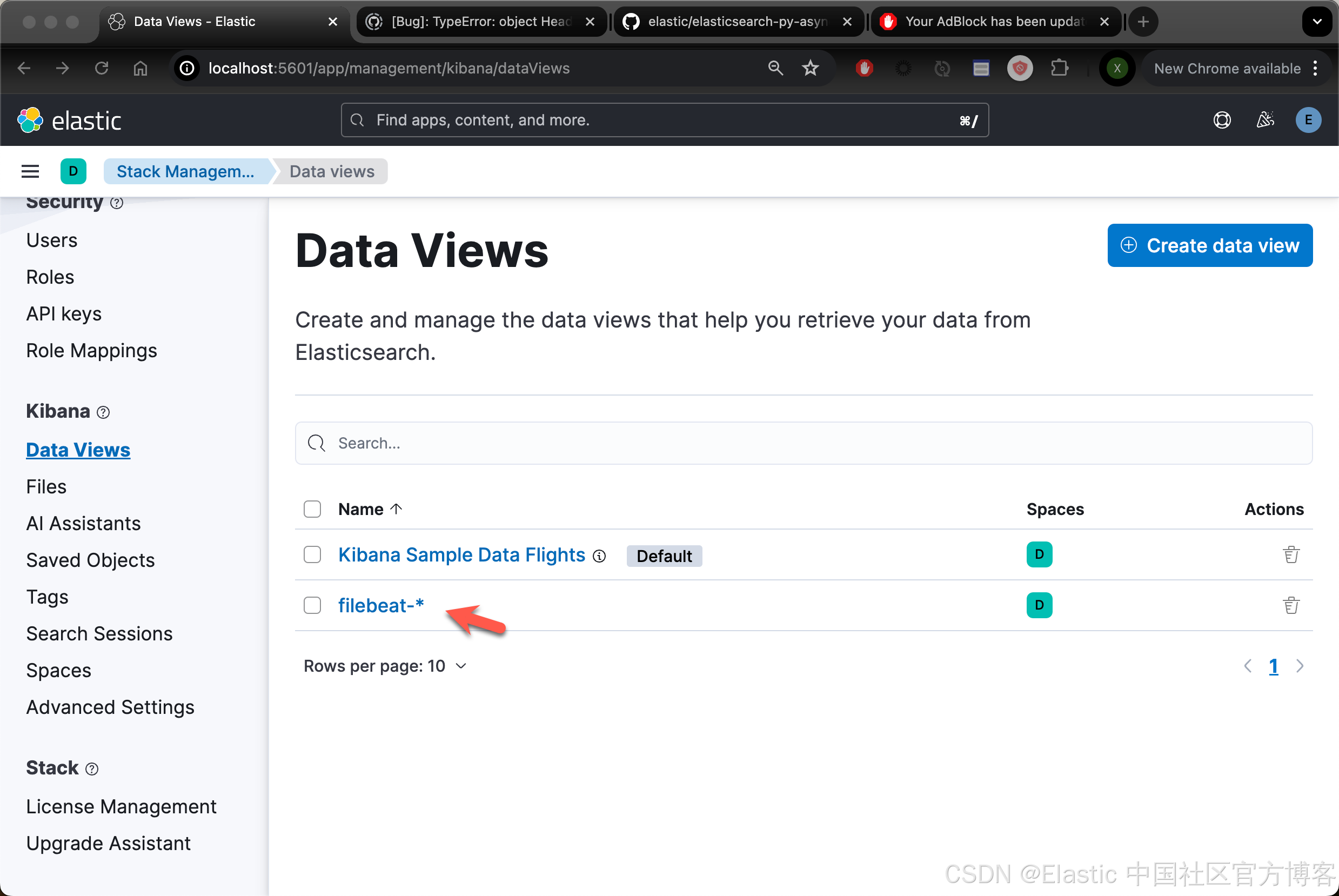
开始演示
启动 Python 应用
我们在 Python 应用的根目录下打入如下的命令:
python elvis.py$ pwd
/Users/liuxg/python/python-logs
$ python elvis.py
Generating log entries...在当前目录下,我们可以查看到新生成的 elvis.json 文件:
$ pwd
/Users/liuxg/python/python-logs
$ ls
elvis.json elvis.py启动 Filebeat
我们使用如下的命令来启动 Filebeat:
./filebeat -e -c filebeat.yml
在上面的命令中:
- -e 标志将输出发送到标准错误而不是配置的日志输出。
- -c 标志指定 Filebeat 配置文件的路径。
为了验证我们已经收到数据,我们可以做如下的检查:
我们可以看到所有的字段。
我们可以在 Kibana DevTools 中查看收集到的数据:

我们可以看到日志数量的编辑已经日志的一些相关信息。
可视化数据
在这里,我们可以针对数据来做一下简单的可视化:






这样我们就生成了第一个可视化图。我们选择保存:

在上面,我们点击 “Create visualization” 按钮:






这样,我们就生成了我们的第二个可视化图。我们按照同样的方法来做第三个可视化图:





最终的可视化图如上所示。
在本篇文章中,我们从零开始从一个 Python 应用使用 Filebeat 来采集数据,并对它进行可视化。希望对大家有所帮助。