XGBoost(eXtreme Gradient Boosting,其正确拼写应该是 "Extreme Gradient Boosting",而XGBoost 的作者在命名时故意使用了不规范的拼写,将“eXtreme”中的“X”大写,以突出其极限性能和效率)是一个用于回归和分类问题的高效且灵活的增强树(Boosting Tree)工具。它是梯度提升(Gradient Boosting)算法的一种改进版本,具有更高的效率、灵活性和准确性。XGBoost在处理大规模数据集时表现尤为出色,常用于机器学习竞赛和实际应用中。它的主要特点包括正则化、并行计算、自动处理缺失值和自定义目标函数。
XGBoost的数学原理
XGBoost的目标是最小化以下目标函数:
其中,包括树的复杂度:
是树节点的数目惩罚系数,是权重的L2正则化项。
在每一轮迭代中,XGBoost通过添加新树来改进模型,新树的构建基于前一轮模型的残差和梯度信息。
Python实例
以下是一个使用XGBoost进行回归任务的可视化示例。我们将使用波士顿房价数据集,展示模型训练过程中的特征重要性和误差随迭代次数的变化。
安装XGBoost
首先,需要安装XGBoost库:
pip install xgboost
示例代码
我们使用XGBoost对加利福尼亚房价数据集进行回归分析。
加利福尼亚房价数据集包含以下特征,分别对应f1-f8:
-
MedInc - Median income in block group: 每个街区的中位收入
-
HouseAge - Median house age in block group: 每个街区的中位房龄
-
AveRooms - Average number of rooms per household: 每个家庭的平均房间数
-
AveBedrms - Average number of bedrooms per household: 每个家庭的平均卧室数
-
Population - Block group population: 每个街区的人口数量
-
AveOccup - Average number of household members: 每个家庭的平均成员数
-
Latitude - Block group latitude: 街区的纬度
-
Longitude - Block group longitude: 街区的经度
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressor, plot_importance
from sklearn.metrics import mean_squared_error# 加载加利福尼亚房价数据集
california = fetch_california_housing()
X = california.data
y = california.target# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建XGBoost回归器
xgb = XGBRegressor(n_estimators=200, learning_rate=0.1, max_depth=3, random_state=42)# 训练模型
xgb.fit(X_train, y_train, eval_set=[(X_train, y_train), (X_test, y_test)], eval_metric='rmse', verbose=False)# 预测训练集和测试集
y_train_pred = xgb.predict(X_train)
y_test_pred = xgb.predict(X_test)# 计算训练误差和测试误差
train_mse = mean_squared_error(y_train, y_train_pred)
test_mse = mean_squared_error(y_test, y_test_pred)
print(f"Train Mean Squared Error: {train_mse}")
print(f"Test Mean Squared Error: {test_mse}")# 绘制特征重要性图
plot_importance(xgb)
plt.title('Feature Importance')
plt.show()# 绘制训练过程中树的数量与均方误差的关系
results = xgb.evals_result()
epochs = len(results['validation_0']['rmse'])
x_axis = range(0, epochs)fig, ax = plt.subplots()
ax.plot(x_axis, results['validation_0']['rmse'], label='Train')
ax.plot(x_axis, results['validation_1']['rmse'], label='Test')
ax.legend()
plt.xlabel('Number of Trees')
plt.ylabel('Root Mean Squared Error')
plt.title('XGBoost RMSE vs. Number of Trees')
plt.show()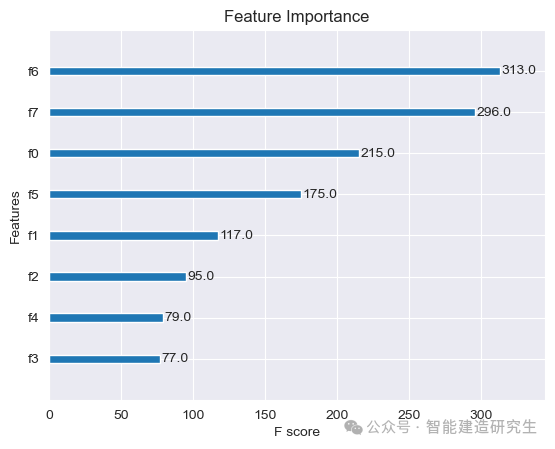
在XGBoost特征重要性图中,F score(或称为Feature score)是一个用于衡量每个特征对模型贡献的指标。具体来说,F score 表示特征在所有树的分裂节点中被使用的次数。分数越高,表示该特征在模型中更为重要。
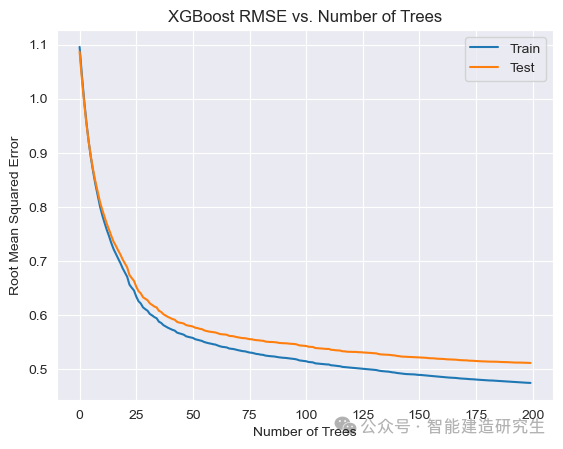
训练误差曲线:不断下降,因为模型通过增加更多的决策树来逐步拟合训练数据。到达一定程度后,模型会几乎完全拟合训练数据,导致训练误差接近于零。
测试误差曲线:在初始阶段,测试误差会随着树的数量增加而减少,表明模型在逐步学习数据中的模式。然而,当树的数量超过某个临界点后,测试误差可能开始上升,这表明模型开始过拟合训练数据,导致在测试集上的性能下降,这种情况并未在本实例中出现。
说明
-
数据加载和预处理:
-
使用
fetch_california_housing函数加载加利福尼亚房价数据集。 -
将数据分为训练集和测试集。
-
-
创建和训练XGBoost模型:
-
使用
XGBRegressor创建XGBoost回归器。 -
在训练模型时,通过
eval_set指定评估数据集,并通过eval_metric指定评估指标(RMSE)。
-
-
计算和打印误差:
-
计算并打印训练集和测试集上的均方误差(MSE)。
-
-
绘制特征重要性图:
-
使用
plot_importance函数绘制特征重要性图,展示每个特征对模型的贡献。
-
-
绘制训练过程的误差变化:
-
使用
evals_result方法获取模型在训练过程中的误差变化。 -
绘制树的数量与均方误差(RMSE)之间的关系图。
-
通过这样的可视化分析,可以更好地理解XGBoost模型的训练过程和特征重要性,从而进行模型优化和改进。
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!