自媒体视频制作的一些小经验,分享给大家。
一、音频部分:
1、文字转语音阐述:
微软语音识别:云希-青年男, 0.5-0.8变速 。注:云泽-中年男(不支持长音频录制), 适合郑重场合,关键知识点阐述。
测试工具:
a、小蜗软件,测试效果也可以,综合了各种文字字幕转换工具。ui比较专业,用的微软语音tts内核。输出时长软件设计者也不确定。
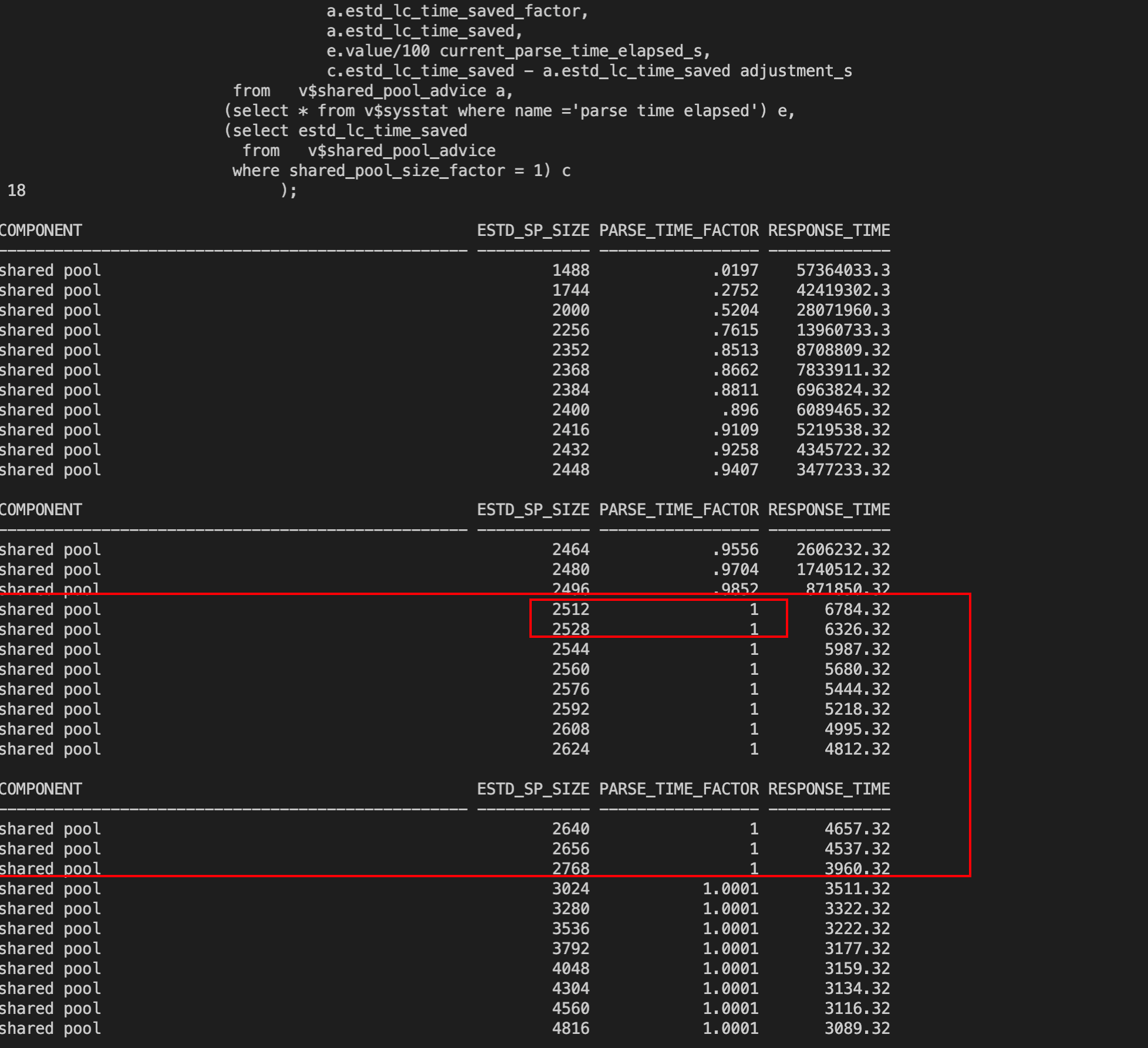
b、edge-tts-record0.1.1 同属于微软语音tts内核(测试后推荐,相对比较稳定)。 也可自己录制后转其他音色。局限为30分钟录制限制。实时同步录音,消耗的时间比较长。录音期间,电脑要关闭下载等其他会发生的程序,以免夹杂。比如:网盘程序等。
注:保存音频路径必须为英文或拼音。此工具录制时,属于实时朗读录音。如下图:
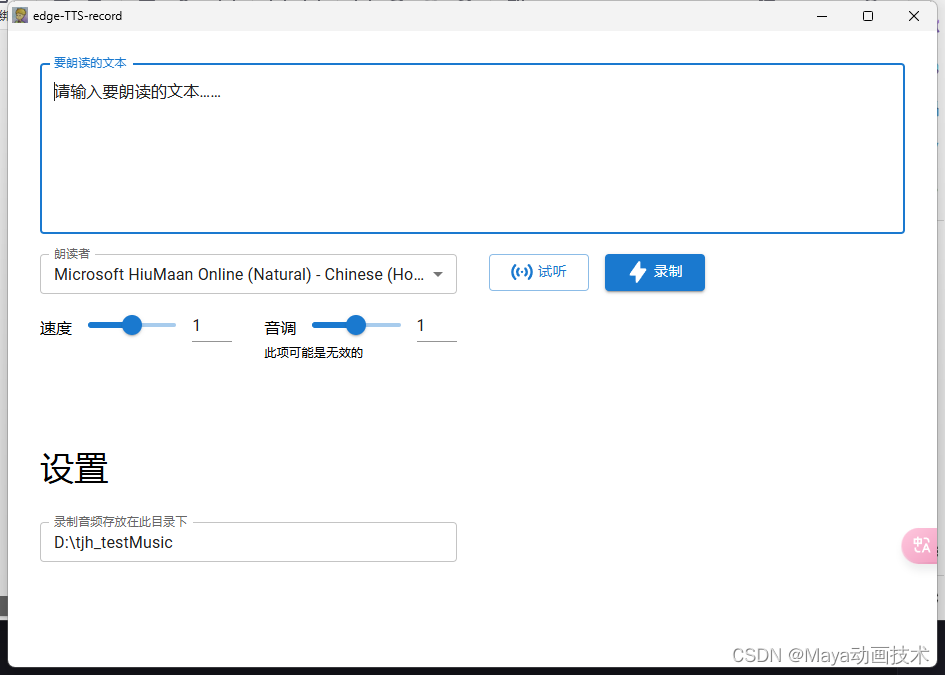
edge-tts-record官方网址:https://github.com/LuckyHookin/edge-TTS-record
c、微软的clipchamp在线视频编辑软件,内置了文字转语音功能,而且是可以使用最新多语音模型的免费工具,时长限制10分钟以内,输出快速,几乎几秒钟,但由于国内访问较慢,所以,启动时需要有些耐心,如果是windows系统,可以直接在系统微软应用商店Microsoft store中 ,查找并安装本地版clipchamp,便于快速使用。如下图:
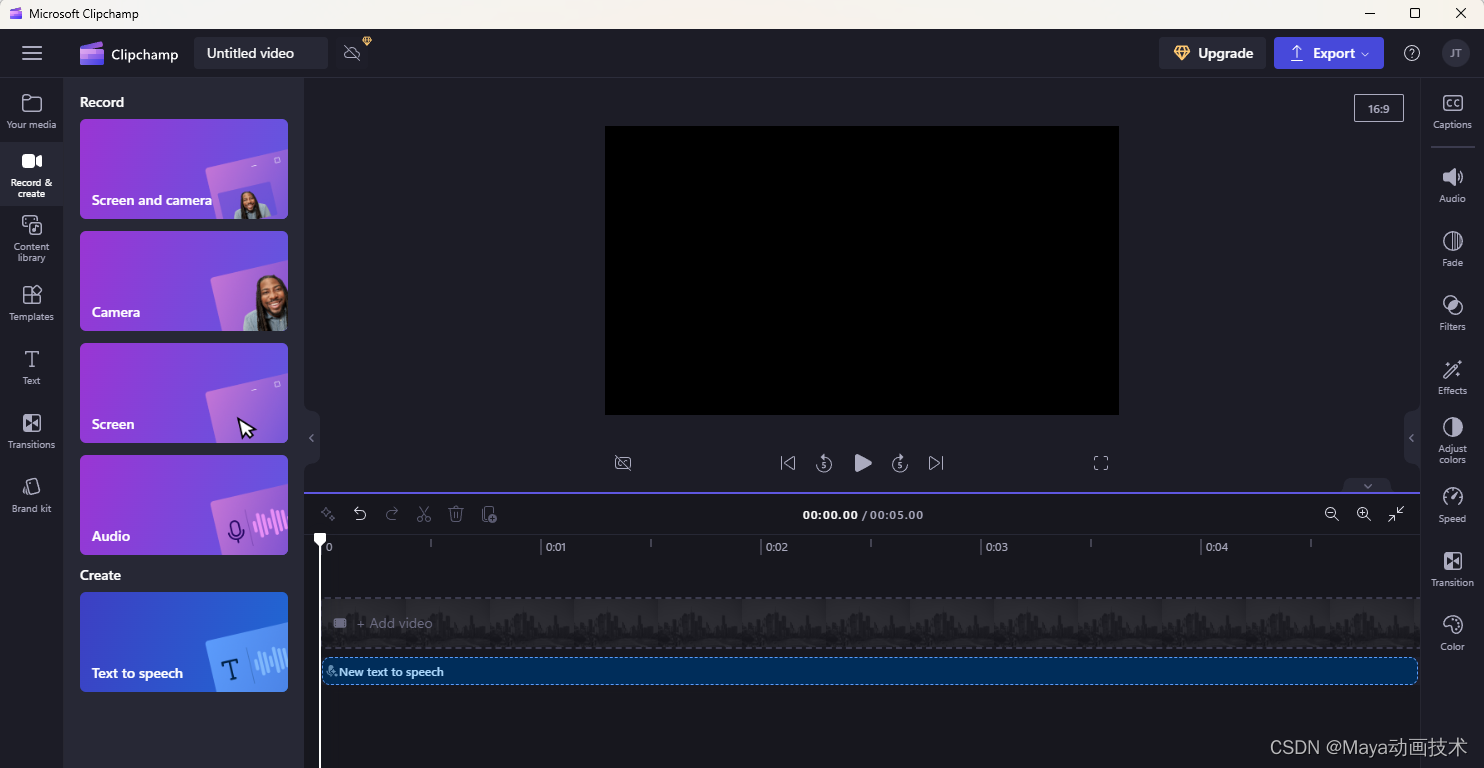
clipchamp网址:https://clipchamp.com/zh-hans/video-editor/
d、 tts-vue1.9.15 软件:有ssml 标记语法输入词语拼音,并局部音频剪辑替换。但现在此功能好像已经作废了。
如下图:
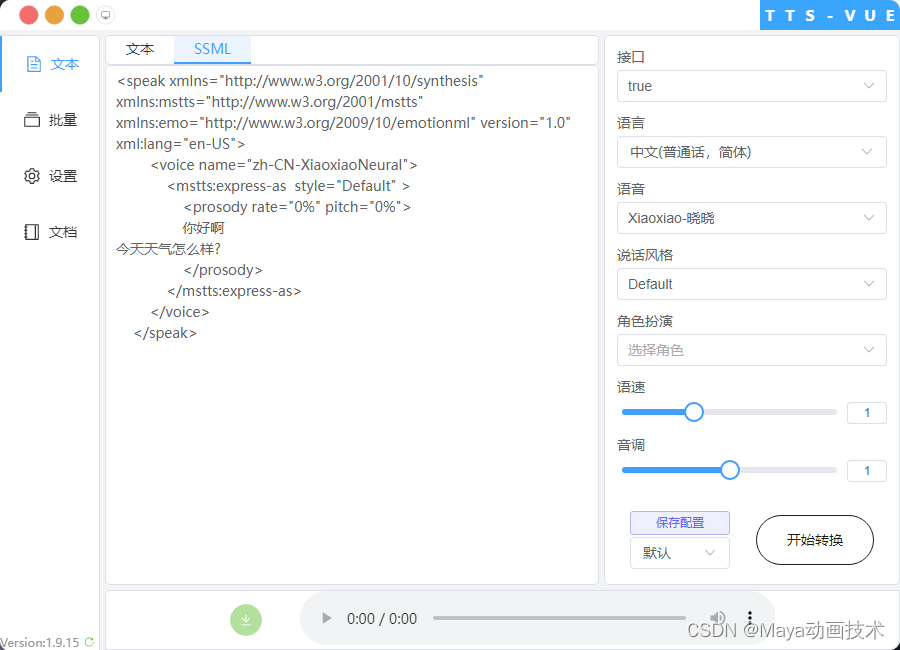
e、关于佛教多音字发音校对的问题,微软ai对于专有中文名词发音有勿,需要用相应的其他词替代。
官方没提供快速字幕文字查找定位时间线功能。需要手动到处srt字幕,之后,在外部文本工具里,查看剪映相应的时间定位点。
不同的字数,会影响多音字发音ai判断。比如“一乘了义”中的“了” 不带标点 ',仅四个字 了 发liao,多字带标点发le。
【阿弥陀佛】阿发错音e,需要转为 【阿`弥陀佛】发a音。
【一乘了义】了误读le,改为 【一乘`了义】了应发liao,多字带标点,发le音。
【十行】行 错误音 hang, 需要改为 【十`行】后发 xing音。
【诸佛刹土】刹 错误音 sha 需要改为【诸`佛刹土】 后发cha 音。
【迦叶】叶 误读为 ye,需要转为拟音字“舍” 后,【迦舍】 后发she音。
【舍利弗】弗误读fu,改为拟音替代字“佛”后,【舍利佛】后发fo音。
2、配乐音效素材:
剪映官方,不多说,技术已经普及。
3、音色转换:
预方案:RMAIVoiceChanger(原入梦RVC软件)。因为涉及音频版权问题,暂时没使用。
选择了微软云希,简单快捷,语速设为0.8,平稳清晰。
二、图像部分:
1、图片素材来源:
主要使用了baidu图片搜索,没别的,省心省时间,免争议,因为是非商业小范围用途,与名利无关,所以也没啥可担心的,阿弥陀佛,哈哈。如果使用本地ai图片生成程序,比如:fooocus 图片生成和修改也很方便,但为了提升出图速度,建议关闭其他程序,仅运行ai程序。对于显存小于8G的设备,就别本地了,直接随缘,用现有公共平台生图就好了。
PS:虽然科技越来越发达,但是其实,永远满足不了人对快捷方便的需求,欲望是无忧截止的!哈哈。而且,新东西背后也伴随着大量未知问题与隐患的诞生。这就是为啥,高技术时间越长,越抵触技术更新,不是新技术不好,而是,很多潜在问题,你不知道。哈哈。所以,中国的科技创新都是很谨慎的,对于越大的项目,选择技术方案也更谨慎,因为利弊是同时并存的。同时并存而生。人要做的就是权衡权重了。
在自媒体方面,看似最简陋的方式,比如自拍或是原创手绘,在后期版权争议方面,却是最安全保险的开发方式。从历史的角度看,越是肯前期投入的,或是遵循承传老方法(尊重版权),成熟技术的行业,越是最稳当保险的,走的也会越长远。比如:各类民族老字号行当,同仁堂。艺术文化方面,更是如此,魅力就在于它古香古色原汁原味,才有价值,就像古董,越老越有价值。哈哈。
注意:现在ai 生图存在大量的版权争议,相关法律法规还不成熟稳定。所以,真正商用最好是纯原创,以免最后法律纠纷,自己用三维或是平面软件自制虽然看似麻烦,却省去了后边大量的麻烦。不要耍小聪明,以为占别人便宜,用现成的多好呀,哈哈,其实,钻别人漏洞就是钻自己漏洞。一切皆有因果,报应只是来早与来迟而已。老实人总是走的最远,活得最久的那一个。哈哈。南无阿弥陀佛。
A、fooocus内置了脸部替换,如果不满意,可以用ai换脸工具涉及到一些法律问题,争议也是有的,所以最好的方式,尽量避免使用真人角色出镜。即使是ai全虚拟角色,只要是出名了,就有人找你麻烦,蹭热度,哈哈。这就是所谓的,识人多处是非多,名利背后就是地狱,哈哈。
B、图片测试工具:开源krita或GIMP修图足够。
C、手部修复,fooocus内置了手部修复。经测试,但仅限于一个一个替换,效率不高。多首修复时,仍然还会有问题。当然软件也在不断迭代。
D、图片缩放,fooocus 1.5倍放大,nv2070s显存能承担2k左右。2倍放大就卡死了,估计显存不足。ai这东西就是浪费你显卡的把戏,不但费钱,还费时间,不管那种ai都需要你等待和不断修改,测试出图,真正能直接用的,都是没啥特别要求凑数的。哈哈。
所以,ai看似方便,其实,还是需要大量精力和时间投入的,没亲自尝试过的人,都被忽悠了。传统影视制作虽然前期很慢,但是,后期维护和精准把控方面,比ai要方便的多。当然,成本也高。越是严谨的需要特别控制的领域,ai的自由度反而越小。特别是传统重工业航天领域,ai随机性的优势就发挥不出来。其实,人体就是一个ai生物机器人,真正要达到人工最能,需要实时的不停的对ai进行训练,而现有的所有的模型都是固话了经验,其实,发布的同时,就已经过时了。因为,人的需求都在实时的变化,而程序都是死的,固化了的。哎虽然看似灵活,也只是在某一范围给予自由度。为机器与生命最大的界限就在于,生命体是完全不定的,刹那变化生死的,生命体也不是偶然的,是大自然造化制造出来的影像,量子领域的研究让人类逐渐接近宇宙的真相。科技与宗教的边界在逐渐打破。很多无法解释的问题,都会被认知。
PS:其实ai是没有创造力的,因为现有ai也只不过是在原有人类原有经验基础上的一种 二次混合 技术而已。ai无法做到无中生有。这也是哲学领域对人类未知的最大探索谜题,道的存在,是无法被制造和模仿的,道没有实体却能生万物。其实,如果你学过大乘佛法和道经,对于人生真相的认知早就成熟了。只是我们没有机会接触古老的智慧而已。人类现有的科技也不过是过去人类生生世世轮回经验的积累。通过催眠科学,大家发现,原来人类的灵魂是永生的,地球文明生生不息,连续不断的。现在人类300年间,解锁的科技其实早就是前人研究过的。人的所谓的灵感,不过是前世潜意识,记忆的恢复。也包含一些其他维度灵性的指导。说的有点深了,哈哈。
2、音频转字幕生成:
剪映内置,ai语音转字幕。 每次转换限制字数5000内。支持文字参考输入。
a、超长分钟以上音频,需要先将语音音频剪裁为多段,每段与输入文本对应的内容,如果文字与音频内容不对应,整体长度不一致,会出现字幕生成错位问题。
b、每次转字幕时,必须把每段音频拖到新轨道,并点选音频轨道后。锁定并静音其他轨道,一次次生成。最终合并一起。
c、最后,每转一段,最好把音轨与字幕合成一个剪辑组,便于拖动组合。最后都合并为一轨道里,最后,可以取消各分段的剪辑组。恢复字幕和音频独立状态,再合并为一个大剪辑组。便于管理分割。
d、如果音频与视频分离的,可以合为同步视频,最后合为一个大的剪辑组,便于之后剪辑。
e、视频转化低编码,可以用开源工具file converter (右键快速菜单)工具。高效环保。
3、剪映剪辑技巧:
a、同轨道两片段拖动对齐时,后一个对不上前一个,差一点就自动建到新轨去了。经实验,发现,将当前游标,移到前片段尾部自动吸附后,再拖动后片段到前片段尾部就对齐了。
b、剪映没有阴影特效。只能通过假阴影模拟,一种是默认官方黑片+方形蒙版(边缘模糊)
另一种是用绘图软件, 手动做个png透明阴影图片,导入。
c、复合片段,有变速标签项,可以后期整体变速,但音频部分要适当做音频变速补偿,否则会失真。
d、封面的导出,任何视频、音频、字幕导出,都会自动包含封面,可仅选择字幕导出即可输出封面,加快输出速度。
e、修改内容后,剪映预览无法更新问题。可以关闭自动渲染功能,并删除预渲染视频文件,即可完成视频的更新显示。在全局设置中,第三个标签项下,可以找到预渲染视频文件夹设置,和自动渲染选项,关闭自动渲染,固态硬盘无需预渲染,流畅度不影响。
4、其他经验:
b站视频回复时,如何添加快捷时间标记到回复里,作为内容预览大纲:
直接输入时间码,比如: 52:00 +空格+内容文字 ,即可生成时间跳转索引。
三、感言:
最后,再提示大家,技术只是…只是…只是…工具而已,就像人的画笔,不要执着于任何工具,因为你无法得到一劳永逸的技术,他们都是无常苦空因缘所生。感叹,自己从事技术几十年,就没有一天能安心的。总在因技术日新月异,学不完,学不尽,而且还老出新问题,新麻烦,哈哈。真不如佛法,一劳永逸。一句名号,念到死都能得利。哈哈哈。可能是我年纪大了,中年后学不动了吧。科技这东西确实该交给年轻人研究了。南无阿弥陀佛。