摘要
1、问题
通过实验发现如今的PDA方法在利用重新调整对齐分布来使适应特征对于源域数据的“噪声”权重,在很多挑战基准测试点上会导致域的负迁移。
2、目的

对抗性调整(AR)方法:对抗性学习源域数据的权重去对齐源域和目标域的分布,和用可转移的深度识别网络来学习源域数据的权重。
方法:
①建立一个训练算法模型去,交替更新这个识别网络的参数。
②优化源域数据的权重。
3、结果
大量的实验显示此方法在很多数据的测试点都达到更好的一个结果。消融研究(简化模型)也证明方法的有效性。
一、Introduction(介绍)
首先指出深度学习模型的问题:依赖大量有标签的训练数据、需要昂贵和耗时量大的标记过程。
1、DA方法
介绍:领域自适应(domain adaptation, DA)将具有丰富标签数据的相关源领域的知识转移到目标领域。DA的核心是利用源域的训练数据建立目标域的预测模型,该模型预计对源域和目标域之间的分布差异(也称为域偏移)具有鲁棒性。
方法:通过用矩匹配或者对抗性训练来对齐不同域的差异以此来训练健壮的模型,常规闭集DA方法是假设源域和目标域共享相同的标签空间。
不足:这种假设在实际中不总是正确的,找到一个相关的源域有着和目标域相同的标签是不容易的。
2、PDA方法
介绍:Partial domain adaptation(PDA)是DA的一个子类别,解决目标域的标签空间是源域的一个子集的场景。比普通的闭集DA更具有挑战性。
原因:
①域的转变。
②一个类仅存在于源域,而不存在于目标域,导致当对齐分布时会导致类的特征不匹配。
这两个潜在的问题就会导致负迁移,即DA方法会损害学习域的学习性能。
负迁移:负迁移一般是指一种学习对另一种学习起干扰或抑制作用。负迁移通常表现为一种学习使另一种学习所需的学习时间或所需的练习次数增加或阻碍另一种学习的顺利进行以及知识的正确掌握。
方法:为减轻负迁移,当前有的PDA方法通常对源域数据进行重加权,以降低仅属于源类数据的重要性。使用目标域和重新加权的源域数据通过对抗性训练或核均值匹配来训练特征提取器实现对齐分布。
对抗性学习:在训练过程中引入对抗样本——即通过在原始输入样本上微小但足以误导模型的扰动构造而成的样本——来增强对于这类攻击的防御能力。
核均值匹配:旨在通过重新加权源域的训练样本来减轻域偏移核均值匹配。
3、发现问题
方法:使用目标域数据被错误分类为仅源类的概率来测量PDA数据集的硬度。
发现:发现当前有的重新调整分布对齐损失的方法,例如:PADA、BAA、MMD在两个数据集上导致了负迁移。通过对齐重新加权的源和目标域数据的特征分布来学习/调整特征提取器甚至会使基线模型的性能恶化,而不进行特征分布对齐。
负迁移效果的原因:在对齐损失中错误地为一些仅为源类的数据分配了非零权重。
4、提出解决方法(AR方法)
adversarialre weighting(AR):通过对抗性学习来重新加权源域数据,以对齐源域和目标域分布。
此方法依赖于对抗性训练来学习源域数据的权重来降低在重新调整源域和目标域分布的Wasserstein距离。这个权重学习过程是基于对抗性重分配模型上进行的,使用Wasserstein距离的对偶形式。
接着在重新加权的源域数据上定义一个重新加权的交叉熵损失,利用在目标域上的条件熵损失取训练目标域上的可转移识别网络。在迭代训练算法中交替进行网络训练和权值学习。
步骤:
①在提出的对抗性调整权重模型中,学习源域数据的权重,以降低仅有源类数据的权重。
②通过重新加权源域数据来减少域间隙,而不是直接优化特征提取器来匹配特征分布。
预测:当源域数据包含“噪声”权重时,减轻负域传输。
使用深度学习框架中特征空间PDA的对抗性重权模型对源数据进行重权。
对源域数进行重加权,降低源类数据在源分类损失中的重要性,以减轻PDA的负迁移。
https://github.com/XJTU-XGU/ Adversarial-Reweighting-for-Partial-Domain-Adaptation.
二、Limitations of Feature Adaptation by Domain Distribution Alignment(域分布对齐的特征自适应的局限性)
主要内容:提出了PDA基准的硬度度量,并显示了重新加权分布对齐的局限性。
图的介绍
(1)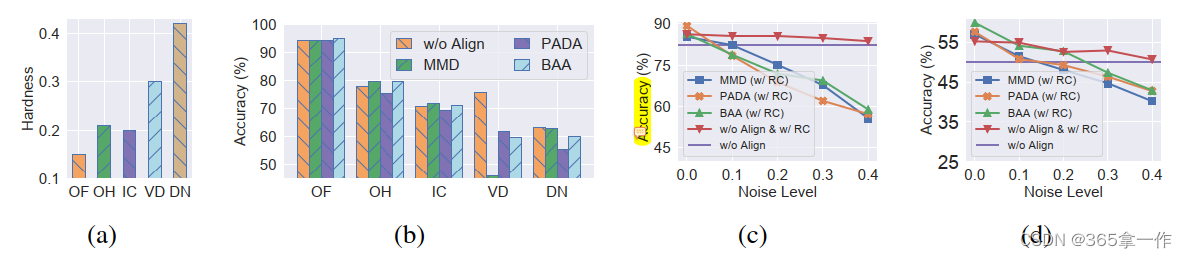
(a)五个基准数据集的硬度
(b)在5个基准数据集上,PDA不同重加权分布对齐损失(PADA、BAA和MMD)和基线(w/o Align)结果的比较。
(c-d)在不同噪声水平下,模拟源数据权重重加权分布对齐损失的结果(c) Synthetic (S) →Real (R) on VisDA-2017 and (d) Clipart (C) → Painting (P) on DomainNet
1、Problem Setting:
源域:标签数据集
目标与:无标签数据集
,分别表示源域和目标域。
是源域的标签,并且
是源域的标签空间
目标:训练一个源域标签空间的子集,并且不同于DA的闭集。
PDA方法常用一个特征提取器F去提取特征,一个分类器C去预测标签,可选一个鉴别器D去区分域。
2、PDA中重加权分布对齐方法综述
两个方面的挑战:
(1)目标域和源域的转变
(2)但源类数据在适应中的负迁移
之前的方法通常用最小化重新加权的源域和目标域之间的特征分布距离来调整特征提取器,该距离由重更新加权的分布对齐损失来衡量。重新加权的分布对齐损失中的权重通常是根据分类器或鉴别器的输出来设计的。广泛采用的分布距离度量包括最大化均值差异(MMD)和Jensen-Shannon散度(JS)。
最小化MMD匹配分布再生核希尔伯特空间中的核均值嵌入。
最小化JS散度相当于生成对抗网络中的对抗训练。
附录A:
这一节中,比较了第2节中得到的几种基于特征自适应的部分域自适应方法。有些最先进的PDA方法(如SAN,PADA、ETN、DRCN、BA3US、TSCDA和IWAN)的损失包含了三个术语,包括源域数据的(重加权的)交叉熵损失、目标域数据的条件熵损失和重新加权的分布对齐损失。PDA方法通常使用特征提取器F提取数据的特征,使用分类器C预测类标签。
总损失可以写成:
J(·,·)为交叉熵,H(·)为条件熵,
是重新加权的目标域数据和重加权的目标域数据的对齐分布损失,基于分布距离度量设计。
表示源域数据的权重向量。
这些PDA方法在交叉熵损失中是否重新加权源域数据的重要性、采用的分布距离度量、获取数据权重的策略、是否利用条件熵损失等四个方面存在差异。
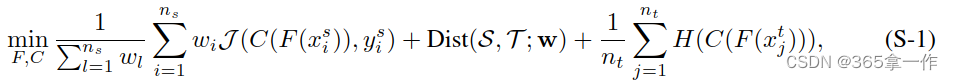

3、对PDA的数据集的硬度进行测量
使用目标域数据被错误分类为仅源类的概率来测量PDA数据集的硬度。
第一步:通过最小化源分类损失和目标域的熵损失来训练模型,这是PDA的基线
第二步:将PDA任务的硬度定义为使用训练好的模型,对目标域样本被错误分类为纯源类的平均预测概率。
第三步:取数据集中所有任务的平均硬度作为数据集的硬度(平均硬度=整体硬度)
4、通过重新加权分布对齐来调整特征提取器可能导致负域迁移(重加权对齐分布的局限性)
报告了不同重加权分布对齐损失的平均分类精度(包括重新加权的PADA(部分对抗域适应)和BAA(一种平衡和不确定性感知的局部域自适应方法)的对抗训练,还有重新加权的MMD损失和基线(无对齐))
附录B: 图1(b)的详细结果
在本文的图1(b)中报告了每个数据集上的所有任务的平均分类精度。在本节中额外报告了每个数据集上所有任务的详细分类精度。
Office-Home数据集的详细分类精度。上图为在Office-Home数据集上PDA不同重加权分布对齐损失和基线(无对齐)的准确性(%)比较。
DomainNet数据集的详细分类精度。上图为DomainNet数据集上PDA不同重加权分布对齐损失和基线(无对齐)的精度(%)比较。
Office-31、ImageNet-Caltech和VisDA-2017的详细分类精度如上图。数据集上PDA不同重加权分布对齐损失和基线(无对齐)的精度(%)比较。
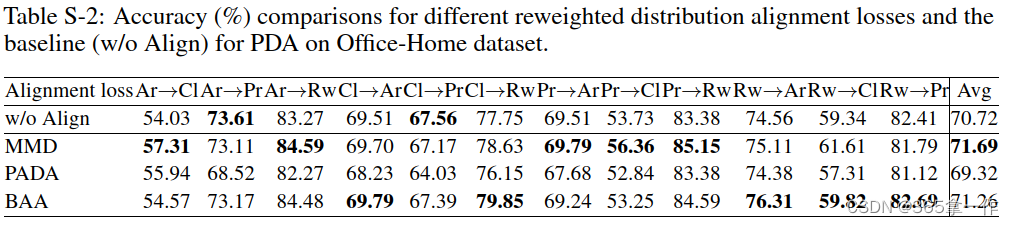
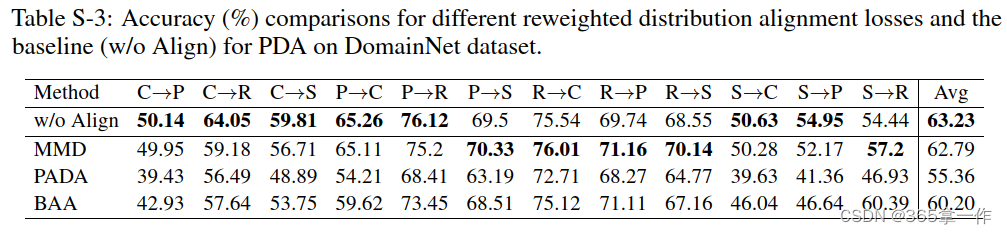
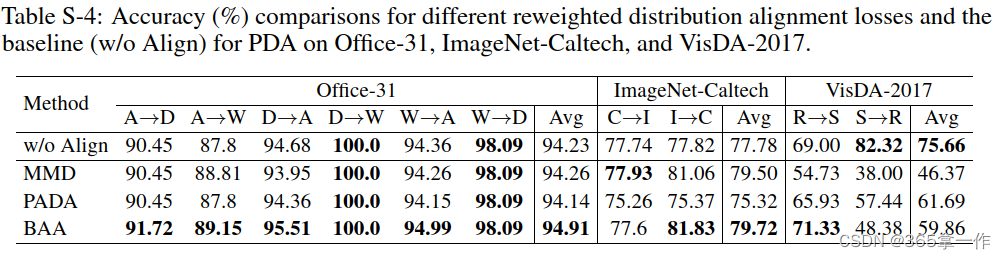
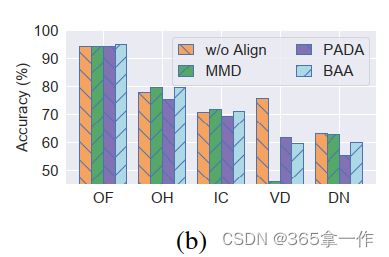
上图可以观察除,通过特征提取器最小化这些重新加权的分布对齐损失会使基线在一些具有挑战性的数据集上的性能恶化(VD和DN),这表明,通过重新加权分布对齐损失来调整特征提取器会导致这些数据集上的负迁移。
5、通过重加权分布对齐自适应特征提取器对噪声权重的鲁棒性较差(负迁移的原因)
在一些方法中,源域数据的权重被定义为
类在目标域数据上的平均预测概率,即
是
的元素。当源域与目标域的差异较大时,源分类器对目标域可能存在不确定性。目标数据分类为纯源类的预测概率可能不为0,可能会显著大于0.因此,基于分类器的输出重新加权源类可能会为仅为源类分配非零的权重,即权重包含“噪声”。
分析了通过重新加权分布对齐来调整特征提取器的有效性可能是因为他对“噪声”权重的鲁棒性不强,进行了模拟不同噪声水平的源域数据权重的实验。将噪声按上述分类器预测的权重比例分配给每个纯源类。
如果分类器预测的权值是,对于对于噪声水平p∈[0,1],每个纯源类的模拟权重为
。
类似地,每个源共享类(类同时存在于源和目标标签空间中)的模拟权重是。
如果p=0,则理想情况下,源类的数据被赋为0的权值,随着p的增加,这些数据被赋予更大的权值,这些权值被视为“有噪声的”权值。
还使用模拟的权重来重新加权源数据在分类损失中的重要性 ,记为“RC”。
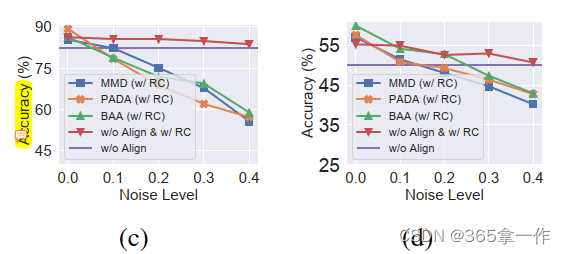
(c)图和(d)图显示了在不同噪声水平下,不同权重加权分布中损失与模拟权重的结果。
可以看到,当噪声水平接近于0时,所有的对齐损失都优于无对齐(w/o Align),说明在这种情况对齐损失导致了正迁移。
但是随着噪声水平的增加,对齐损失的性能迅速下降,甚至明显不如无对齐(w/o Align)。
具体来说,在任务S->R(图c),当噪声水平为0.1时,对齐损失的性能开始不如无对齐(w/o Align)。
同样的,在任务C->P中(图d),在噪声水平为0.3时,对齐损失的性能开始低于无对齐(w/o Align)。
而在这两个任务中,“真实”噪声水平(基于分类器对仅源类的权重总和)大于0.3(相对于0.4)。
因此,重加权分布对齐损失的负迁移可能是由于权重中的“噪声”。
还可以看到,当噪声水平在0~0.4范围内,在源分类损失中重新加权数据重要性的无对齐并且有RC(w/o Align & w/ RC)方法在两个任务中都始终优于基线“w/o Align”方法。
这表明,在两个任务中,与重新加权的分布对齐损失相比,在源分类损失中重新加权数据重要性鲁棒性更强。
总结:
上述观察结果表明,通过重新加权的分布对齐来调整特征提取器对源数据权重的中的噪声不具有鲁棒性,并且在一些具有挑战性的数据集上可能导致负迁移。
但是,令人惊讶的是,在源分类损失中重新加权数据重要性可能比重新加权分布对齐损失对噪声权重的鲁棒性更强
三、部分域自适应的对抗性加权
图像介绍
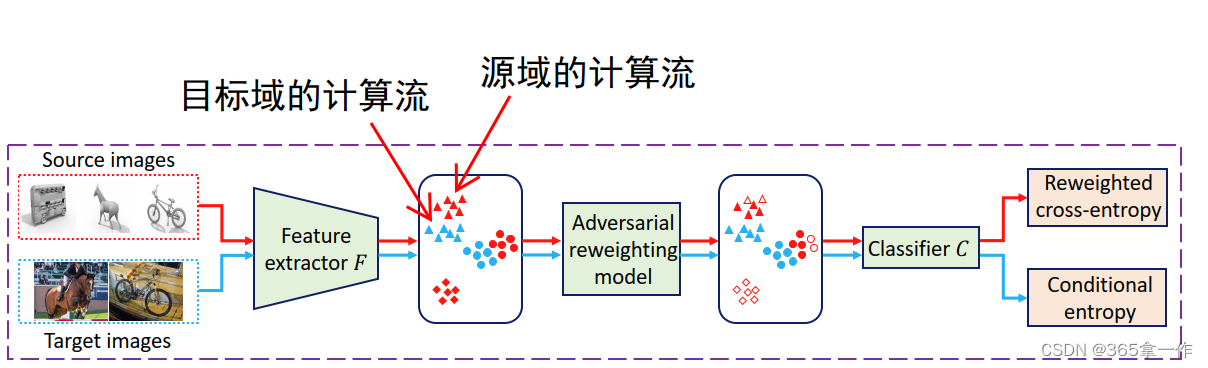
PDA对抗性重加权方法的体系结构:
红色(分别地,蓝色)箭头表示源(目标)域的数据流。特征提取器将源图像和目标图像都映射到特征空间中。对抗性权重模型自动重权源域数据的重要性,以匹配目标域在特征空间中的分布,以降低仅源类数据的重要性。在重加权的源域数据分布上定义重加权交叉熵损失,在目标域数据上定义条件熵损失,学习目标域的可转移识别网络。
新方法:PDA对抗性重加权(AR)方法,该方法依赖于源数据权重的对抗性学习对齐源域和目标域。
上图说明了这个方法:
(1)通过特征提取器F将源数据和目标数据映射到特征空间。
(2)设计一个对抗性重加权模型来重新加权源域数据的重要性,以匹配目标域在特征空间中的分布。在这种对抗新重加权模型中,我们通过重加权源域数据特征来减少间隙,而不是调整特征提取器。
(3)定义了源域数据的重加权交叉熵损失(通过对抗性重加权模型学习的的权重)和目标域数据的条件熵损失,以学习目标域的可转移识别网络。
接下来,正文开始,一共三步:
①介绍网络损失
②对抗性重加权模型
③训练算法
1、训练识别网络的损失
训练识别网络的损失是源域上重加权交叉熵损失和目标域熵条件熵损失的组合,被定义为
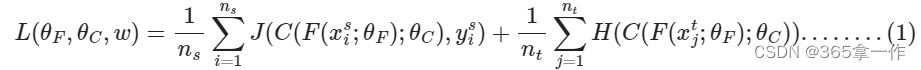
第一项是J(·,·)是交叉熵损失,定义为
:特征函数,当y=k时取1,其余情况取0。
第二项时H(·)是条件熵损失,定义为
两项都在分布下,
是指定源域数据重要性的权重,使得
,并且
和
分别是F(特征提取器)和C(分类器)的参数。
这些权重将在下面的对抗性重加权模型中训练得到。
最小化重加权交叉熵损失使识别网络能够预测输入图像的标签。最小化条件熵损失可以促进目标域上类之间的低密度分离。
2、对抗性重加权模型
假设共享类的源域数据比仅源类
的源类数据更接近目标域数据。
为了降低仅源类数据的重要性,同时减少域偏移,通过最小化重新加权的源域分布与目标域分布之间的Waaserstein距离来学习源域数据的权值。
权重学习过程被表述为一个对抗性权重模型。
接下来先介绍Wassertein距离
(1)Wasserstein distance(Wassersetin距离)
Wasserstein距离是一个度量两个分布之间差异的度量。
分布在μ和v之间的Wasserstein距离被定义为
是µ和ν的耦合集合,即
||·||是2型范数。
整个式子的意思是当时,
符合
分布时,x-y的范数的数学期望最小值。
利用Kantorovich-Rubinstein对偶性,Wasserstein距离具有对称形式,其中最大值在1-Lipschitz函数
上。
为了计算Wasserstein距离,用参数为θD的神经网络D(鉴别器)参数化f,然后Wasserstein距离
式子(2)允许在大规模数据集上使用基于梯度的优化算法近似计算Wasserstein距离。
附录C:计算Wasserstein距离的细节
本节说明计算第3.2节讨论的Wasserstein距离的细节。计算Wasserstein距离对偶形式的近似值。
采用梯度惩罚技术来强制执行上式中的约束。因此
上式
表示沿分布μ和v中采样点对之间的直线均匀分布的样本,上式可采用基于梯度的优化算法求解,如Adam算法。根据上式,Wasserstein距离可以近似为:
1、Distribution distance metric(分布度量距离)
广泛使用的分布距离包括最大均值差异(MMD)和JS散度。
MMD定义为:
其中H为再现核希尔伯特空间。
为特征映射。最小化MMD是为了在再现希尔伯特空间中匹配分布的核均值嵌入。
JS散度满足:
通过F最小化JS散度相当于生成对抗网络中对F和D的对抗训练。
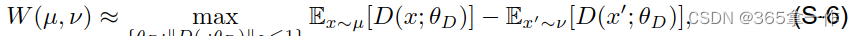
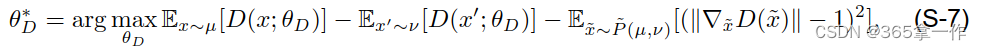
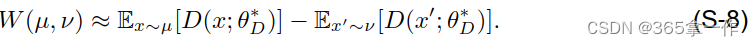
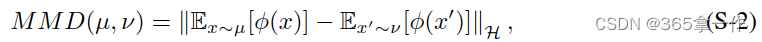
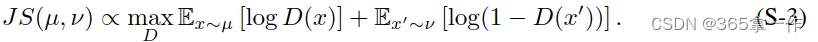
用Wasserstein距离的好处:与其他流行的统计距离相比,例如JS散度,Wasserstein距离对于学习分布具有较好的连续性。
(2)Adversarial reweighting(对抗性重加权)
作者的对抗重加权模型是在特征空间中定义的。
将源域数据中提取的特征表示为,将目标域数据中提取中的特征表示为
。
将目标域数据T的经验分布记为,
是狄拉克函数。
重新加权后的源域分布记为。
然后我们在以下原则模型中自动学习权重。基于前面的假设,仅源类数据比共享类的源数据离目标域数据更远,最小化重新加权的源域和目标域分布之间的Wasserstein距离,以学习权重如下:
为了避免模态崩溃,即只在少数数据上支持重加权分布,执行。解空间是
。
通过近似式(2)中的对偶形式,将式(3)转换为以下对抗性重权模型:
在(4)中,鉴别器被训练为最大化(最小化)其在源(目标)域上的输出的平均值,以区分源和目标域。相反,学习源数据权重以最小化源域上鉴别器输出的重新加权平均值。因此,具有较小鉴别器输出的源数据(更接近目标域)将被赋予较大的权重。因此,定义了重加权交叉熵损失重新加权的源数据分布促进了训练后的识别网络对目标域的可移植性。
(3)Implementation techniques(实现技术)
第一步:使用球面逻辑回归(SLR层)作为分类器
第二步:式子(1)中的熵损失仅用于更新特征提取器F,而不是同时更新F和C。
球面逻辑回归层输出目标特征和源原型的余弦相似度。
在熵较低的情况下,学习到的目标特征需要接近源特征,这样分类器(由源原型组成)才能更准确地识别目标特性。
因此,对抗性重加权和熵最小化可以互相补充,以减少域间隙。
(4)Automatically adjusting ρ(自动调节ρ)
ρ的适当大小对作者的方法很重要,如果目标域和与源域的标签空间大小之比()较大,ρ需要很小,以迫使更多的源数据对重新加权的交叉熵做出贡献,反之依然。
由于目标标签空间是未知的,作者自动调整ρ以在预设区间内强制执行计算出的Wasserstein距离(即式(4)中的损失值,记为
)。
为了做到这点,选择ρ的初始值和常数
,调整ρ如下:
①,将用
来调整ρ。
②,将用
来调整ρ。
最终调整到。
设置
作者将在4.2节中表明,此方法的性能对这些超参数不敏感。
3、Training Algorithm(训练算法)
为了训练识别网络以最小化式(1)中的熵损失,交替优化网络参数并通过固定其他已知值来学习权重w。
对于所有i,用初始化
,然后,在训练网络时交替运行以下两个过程:
(1)用固定的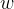 来更新
来更新
固定后,更新
和
,使用小批量随机梯度下降算法(SGD),在M步中最小化式(1)中的损失。
(2)用固定的来更新
固定后,提取源域和目标域熵所有训练的特征,并在式(4)中学习
。由于式(4)式一个最小-最大优化问题,可以通过固定一个已知来交替优化鉴别器的权重
和参数
。为了减少计算成本,作者只进行了一次交替优化,实验结果令人满意。
因此,首先对所有i固定,并使用梯度惩罚技术优化
以最大化方程(4)中的目标函数。接着固定鉴别器,对
优化过程:表示
和
。接着
的优化问题变成:
式(5)为二阶锥规划,使用CVXPY包(用于凸优化的python嵌入式建模语言包)来求解式子(5)。
当源域数据的大小大于100k时,一次求解所有源数据的式子(5)是不可行的。在这种情况下,随机抽取源数据集的一个子集(大小为N)来更新它们的权重w,然后使用它们更新,并迭代上述两个过程。
附录D:训练算法伪代码
算法1给出了第3.3节训练算法的伪代码

四、实验
在五个基准数据集上进行实验,以评估对抗性重加权(AR)方法,并将其与最先进的PDA方法进行比较。
数据集
Office-31数据集包括31个类别的4652张图像,从三个领域收集:亚马逊(A)、数码单反(D)和网络摄像头(W)。
从Office-31和Caltech-256共享的10个类别中选择图像来构建新的目标域。Image-calten使用ImageNet(I)和Caltech-256(C)构建,分别包含100个和256个类。利用84个共享类来构建目标域。由于大多数网络都是在ImageNet的训练集上进行预训练的,因此作者使用来自ImageNet验证集的图像来构建C->I的目标域。
Office-Home由四个领域组成:艺术(Ar)、剪纸艺术(Cl),产品(Pr)和显示世界(Rw),共享65个类。使用按字母顺序排列的前25类图像作为目标域。
VisDA-2017是一个大规模挑战性数据集,包括两个领域:合成(S)和真实(R),共12类。使用按字母顺序使用前6个类作为目标域。
DomainNet是另一个大规模挑战性数据集,由6个领域345个类组成。由于一些领域和类的标签非常嘈杂,采用四个领域剪纸艺术(C),绘画(P),真实(R)和素描(S)126个类。按字母顺序使用前40个类来构建目标域。在这些数据集上,依次将每个域设置为源域,并使用每个剩余域来构建目标域。
实现细节
设备:Nvidia Tesla v100 GPU,使用Pytorch。
特征提取器F:使用在ImageNet上预训练的RestNet-50,它排除了最后一个全连接层。
鉴别器D:使用和Unsupervised domain adaptation by backpropagation[8]中相同的架构(三个完全连接的层,分别是1024、1024、1个结点),不包括最后一个sigmoid函数。
更新算法:动量为0.9的SGD算法。
的学习率是
的十倍。
更新算法:Adam算法,学习率是0.001。
根据[8],将的学习率
用
调整,p是训练进度从0到1的线性变化。
批量大小:36,即M(步数大小)=500,N=36M
附录E:完整的实现细节
这节提供了完整的实现细节。
设备:Nvidia Tesla v100 GPU,使用Pytorch
特征提取器F:在ImageNet上预训练的ResNet-50,排除了最后一个完全连接层
鉴别器D:使用三个完全连接的层,分别有1024、1024、1个节点,不包括最后一个sigmoid函数。
更新
的学习率是
的十倍。
更新
算法:Adam算法,学习率是0.001。
将
用
调整,p是训练进度从0到1的线性变化。
批量大小:36,即M(步数大小)=500,N=36M
在大规模源的自适应任务中(例如:VisDA-2017数据集上的S->R任务,以及ImageNet-Caltech和DomainNet数据集上的所有任务),根据学习到的权值(使用加权随机采样器)对小批量源数据进行采样,计算分类损失。发现在这些任务上,这种策略比对均匀取样的小批中每个数据的分类损失重新加权的策略更加稳定。
1、Results(结果)
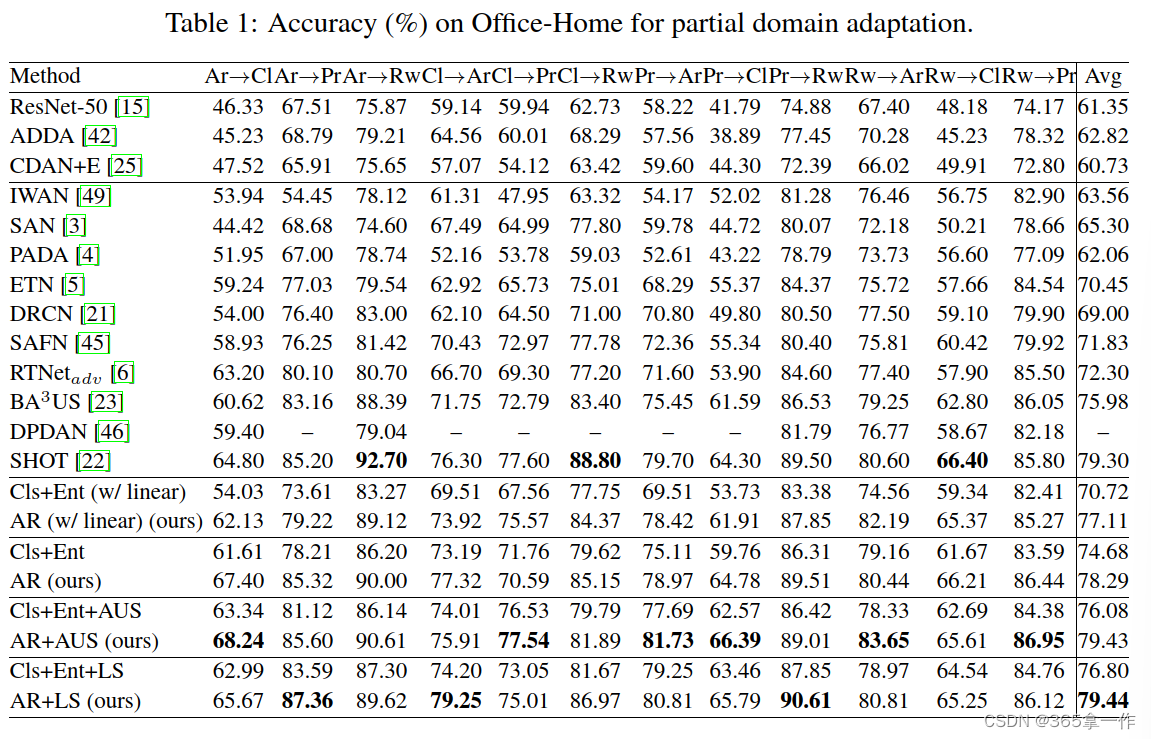
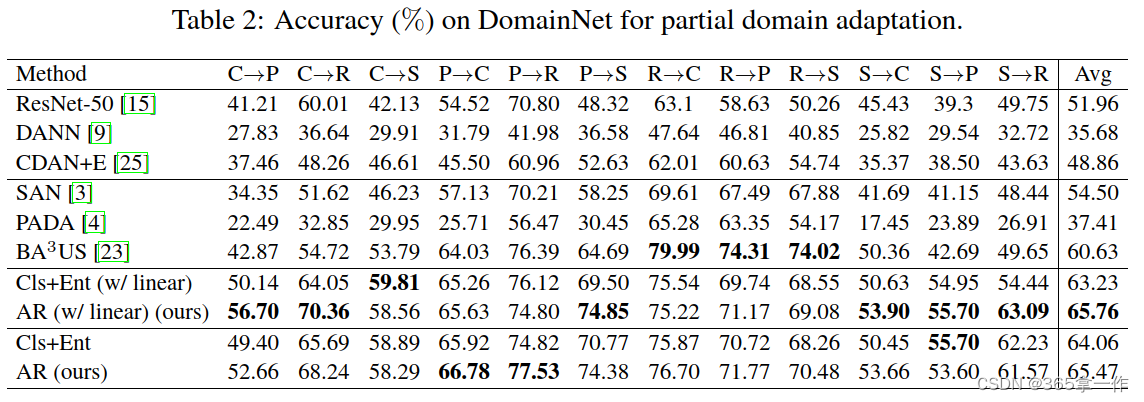
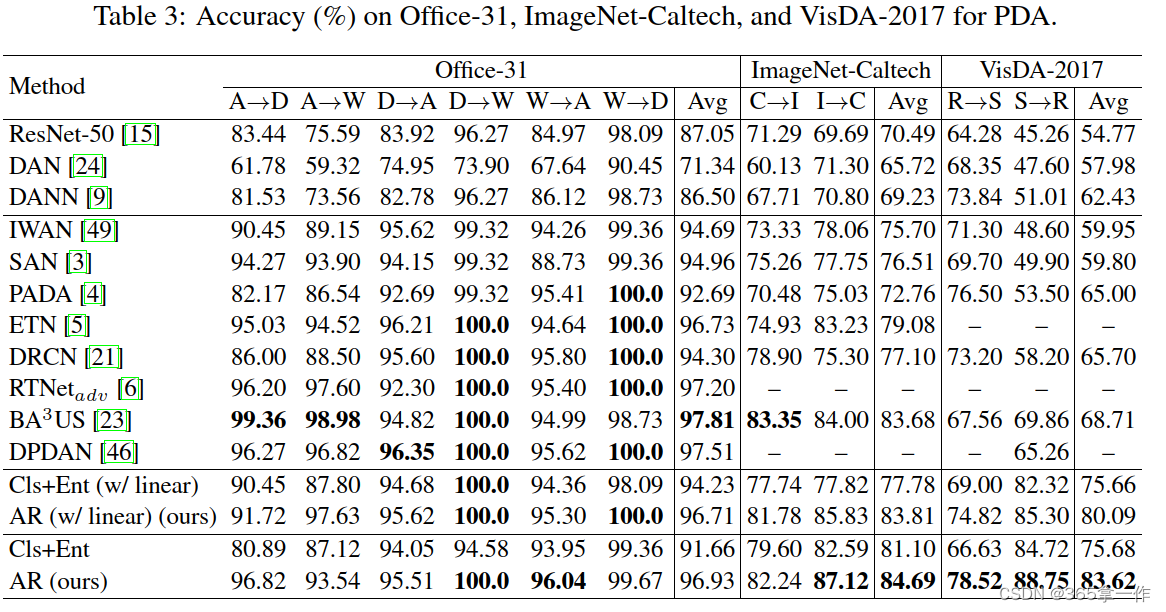
在上面的表1和表2分别报告了Office-Home和DomainNet上的结果。表三报告了Office-31、ImageNet-Catech和VisDA-2017的结果。
注意:表2中的DomainNet上比较方法的结果是通过在DomainNet数据集上运行其官方代码获得。
”Cls+Ent“表示基线方法,该方法使目标域上的熵损失和源分类损失最小化,而不是用式(1)中的重加权。
由于作者使用使用球性逻辑回(SLR)层作为分类器,为了完全公平的比较,作者报告了AR和Cls+Ent版本的结果,其中线性层作为分类器(分别表示AR(w/线性)和Cls+Ent(w/线性))。
在所有五个数据集上,AR和AR(w/线性)方法分别显著优于Cls+Ent和Cls+Ent(w/线性)基线。
在Office-Home上,还将AR与自适应不确定性抑制(AUS)损失和标签平滑(LS)相结合,这两种方法用于BAUS和SHOT的最先进(SOTA)方法。
AR+AUS和AR+LS方法分别持续提高其基线的性能。值得注意的是,AR+LS实现了SOTA结果为79.44%,在DomainNet上,AR和AR(w/线性)均显著优于所比较的方法,AR(w/线性)达到65.76%的SOTA结果。
在ImageNet-Caltech和VisDA-2017数据集上,AR分别实现了84.99%和83.62%的SOTA结果。
注意,在VisDA-2017和DomainNet数据集上,AR(w/线性)以很大的有时优于之前的SOTA方法BAuS(分别高出11.38%和5.13%)
在表3中,在Office-31上,AR(w/线性)与其他方法相比取得了具有竞争力的结果。可以看到, 在Office-31上的准确率都在97%以上。
在Office-31上的准确率都在97%以上。
这表明分类器在目标域上的预测可能是可靠的,并且基于分类器的源权值可能包含较少的噪声,在这种情况下,正域迁移可以通过特征自适应来实现。
注意,尽管 没有使用分类器输出显示地重新加权数据,但目标域上的分类器输出被用作强化学习框架中用于选择源的状态组件特征自适应数据。
没有使用分类器输出显示地重新加权数据,但目标域上的分类器输出被用作强化学习框架中用于选择源的状态组件特征自适应数据。
2、分析
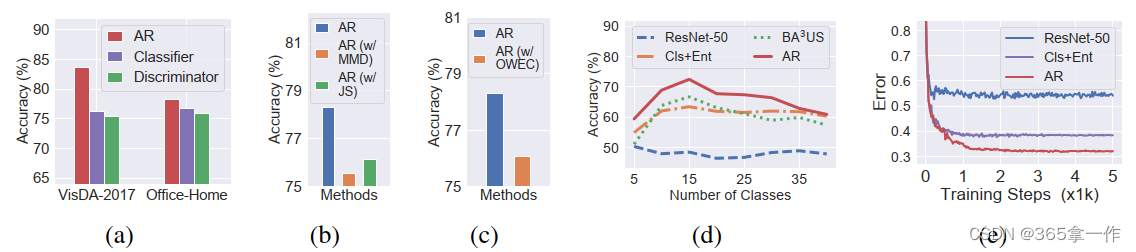
(a)不同权重调整策略的结果
(b)在作者的Office-Home框架中,消除MMD和JS的差异,以学习源数据权重
(c)在Office-Home上学习每类一个权重(OWEC)的消融实验
(d)同目标类别数量下的准确性
(e)在Office-Home的任务Ar→Cl中测试误差的收敛性
(1)与其他权重调整策略的比较
比较了在式子(1)损失中获得权重的不同重权策略,包括我们的对抗性权重(AR),基于分类器的重权,以及通过鉴别器对源数据的输出重权。图(a)的结果表明,作者的对抗性重权重在VisDA-2017和Officr-Home数据集上的表现明显优于其他两种重权重策略,证实了作者的重权重策略的有效性。
附录A:Strategies for designing the source data weights(设计源数据权重策略)
源数据权重是根据分类器C或鉴别器D的输出来设计的。
如果策略基于分类器,则源数据
的权重由
类在目标域数据上的平均预测概率定义,即:
其中
是向量
的第
如果该策略基于鉴别器D,该鉴别器D被训练来预测源(目标)域标签1(0),则
属于目标域的预测概率定义,即
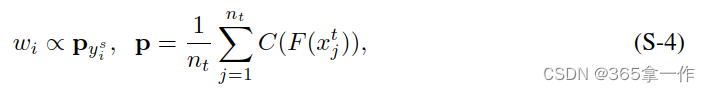

(2)MMD的消融和JS散度来学习权重
在Office-Home数据集上对JS散度和MMD进行消融研究,以了解作者的框架(分别表示为AR(w/JS)和AR(w/MMD)中的权重,在图(b)中,可以看到使用Wasserstein距离的AR优于AR(w/MMD)和AR(w/JS)。当源分布和目标分布的支持不相交时,Wasserstein距离可能比JS散度更适合测量它们的距离。广泛地使用核地MMD可能无法捕获高维空间中非常复杂的距离,这可能使其不如作者的框架中的Wasserstein距离有效。
(3)为每个类别学习一个权重的消融(OWEC)
在Office-Home数据集上进行实验,为框架(表示为AR(w/OWEC)中的每个类学习一个权重,如图(c)所示。
在图(c)中,学习每个样本权重的AR显著优于每个类学习一个权重AR(w/OWEC)。如果每个样本的权重都被学习到了,那么就有可能给更接近目标域的样本分配更高的权重,即使在相同的源类中。在这种情况下训练的模型可能更具有移植性,因为与目标域不太相关的样本(甚至在源共享类中)变得不那么重要。
(4)不同数量的目标类别的准确性
在图(d)中使用不同数量的目标类来研究作者的方法。当分类数小于35个时,作者的AR方法明显优于Cls+Ent和 。这表明当源域和目标域之间的标签空间不匹配较大时,作者的方法对PDA是有效的。
。这表明当源域和目标域之间的标签空间不匹配较大时,作者的方法对PDA是有效的。
(5)收敛性
在图(e)中,以任务Ar->Cl(Office-Home)为例研究作者的方法的收敛性。
仅使用源数据训练网络的”ResNet-50“方法收敛速度快,但目标测试误差高。
作者提出的AR实现了最低的目标误差。可以观察到,AR收敛速度略慢于Cls+Ent,这可能是因为重加权的交叉熵损失中的源数据权重在整个训练过程中都在更新。
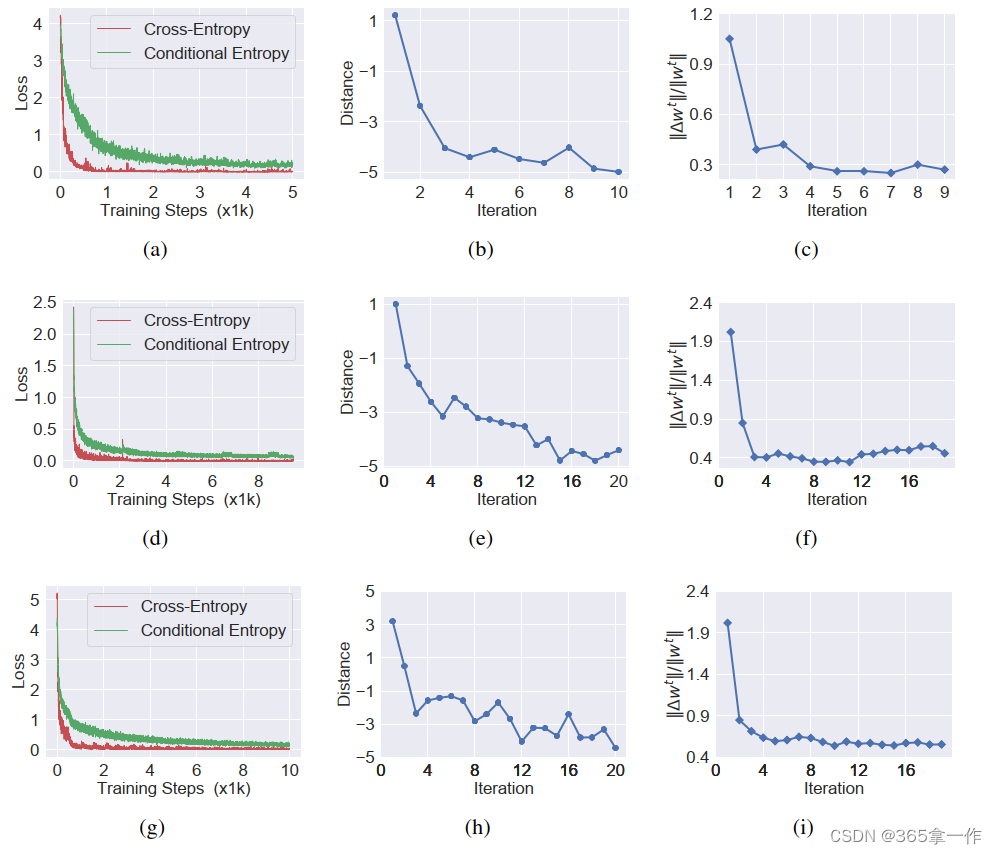
附录F:关于训练算法收敛性的论证
本节为证明训练算法的收敛性提供了更多证据,对第4.2节讨论收敛性的补充材料。
图(1):在Office-Home上的Ar→Cl (a-c),在VisDA-2017上的S→R (d-f),在DomainNet上的c→P (g-i)任务中的训练损失(a、d、g),近似距离(b、e、h),权值(c、f、i)的相对差值。
在式子(1)中绘制了训练损失,在式子(2)下绘制了近似距离,在图(1)中绘制了权重的相对差。
相对差为
,其中
,
为交替训练算法第t次迭代的权值。
在图1(a)、(b)、(c)中,作者的方法的训练损失随着训练过程稳定减小并收敛。图1(b)、(e)、(h)中近似距离的波动,以及图1(c)、(f)、(i)中
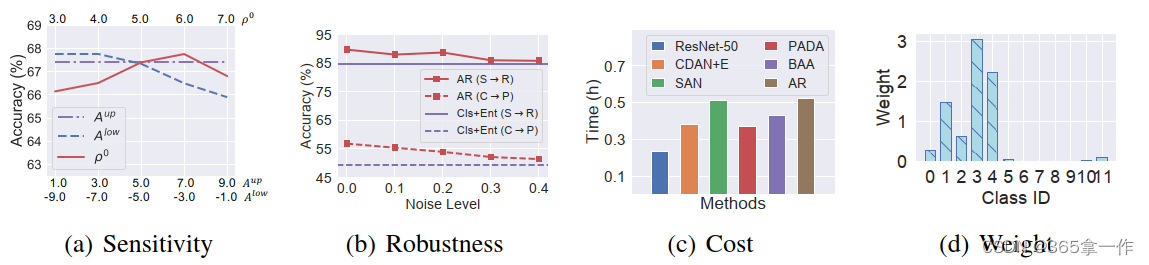
(a)任务Ar->Cl超参数敏感性
(b)AR对权值噪声的鲁棒性
(c)PDA方法的计算成本
(d)任务S->R中每个类的平均权值
(1)对超参数的敏感性
作者证明了他们的方法对3.2节中提到的超参数的敏感性,如图(a)所示,图(a)表明,作者提出的对抗性重加权的性能对这些超参数不敏感。
(2)AR对权值噪声的鲁棒性
为了验证AR加权噪声的鲁棒性,在不同噪声水平下对自己的方法进行了仿真实验
在图(b)中,可以观察到,在不同噪声水平下,AR 在C->P和S->R任务中始终优于基线Cls+Ent。这证明了AR对权值噪声的鲁棒性。
附录G:验证AR对权值噪声鲁棒性的细节
为了验证AR对权值的噪声鲁棒性,作者对该方法进行了不同噪声水平下的仿真实验。具体而言,首先通过对抗性重权模型获得源数据权重
。对于噪声水平
,作者模拟属于纯源类的第i个样本的权重:
,对于i,使得
(即属于纯源类的第i个原样本被分配与作者的对抗性模型学习到的权重成比例的噪声权重)。
同样的,对于i,为源类共享类的第i个样本分配
,
噪声权重。如图4(b)所示。
(3)计算成本
比较了不用方法在相同训练步骤(5000步)下计算成本和总训练时长,如图(c)所示。图(c)显示,AR方法在计算成本方面与其他方法相当
(4)特征和权重可视化
作者可视化了任务S->R中每个类的源域数据的学习平均权重,如图(d)所示。
可以看到,源共享类(前六个类)数据通常具有更大的权重(第六个类除外)。
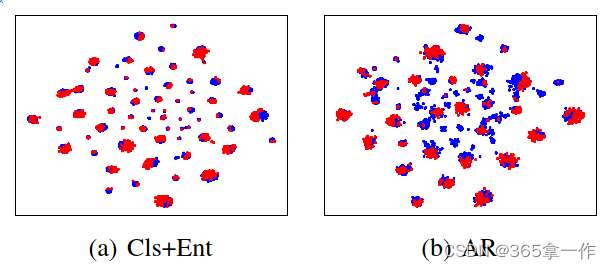
(a-b)Cls+Ent对学习源(蓝色)和目标特征(红色)的t-SNE可视化在任务Ar->Cl
在上图中展示了任务Ar->Cl(Office-Home)中学习到的特征的t-SNE嵌入。
通过条件熵最小化,Cls+Ent学习到的(a)中的目标特征与源特征对齐所有类(包括纯源类)的类,这在PDA中不可预料。
在图(b)中,提出的AR将目标特征与部分源特征对齐,这些可视化可以部分解释PDA问题的方法的成功。
附录H:学习权值的可视化
图2:在Ar→Cl (a)和S→R (b)任务中,源数据的学习权值。(a)和(b),左图绘制了学习到的源(蓝色)和目标(棕色)特征。右图绘制了加权的源(蓝色)特征和目标(棕色)特征,源数据点在其中蓝色越清晰,重量越大。
在图2中可视化了源域数据的学习权重。从图2中可以看出,距离目标域较远的源数据权重

五、总结
在本文中,作者通过实验观察到,通过重新加权分布对齐来适应特征提取器对源域数据的“噪声”权重不具有鲁棒性,并且可能会损害目标域的学习性能。作者进一步提出了一种新的对抗性加权方法来解决PDA问题。大量实验表明,我们提出的方法在ImageNet-Caltech、Office-Home、VisDA-2017和DomainNet等具有挑战性的数据集上取得了SOTA结果。