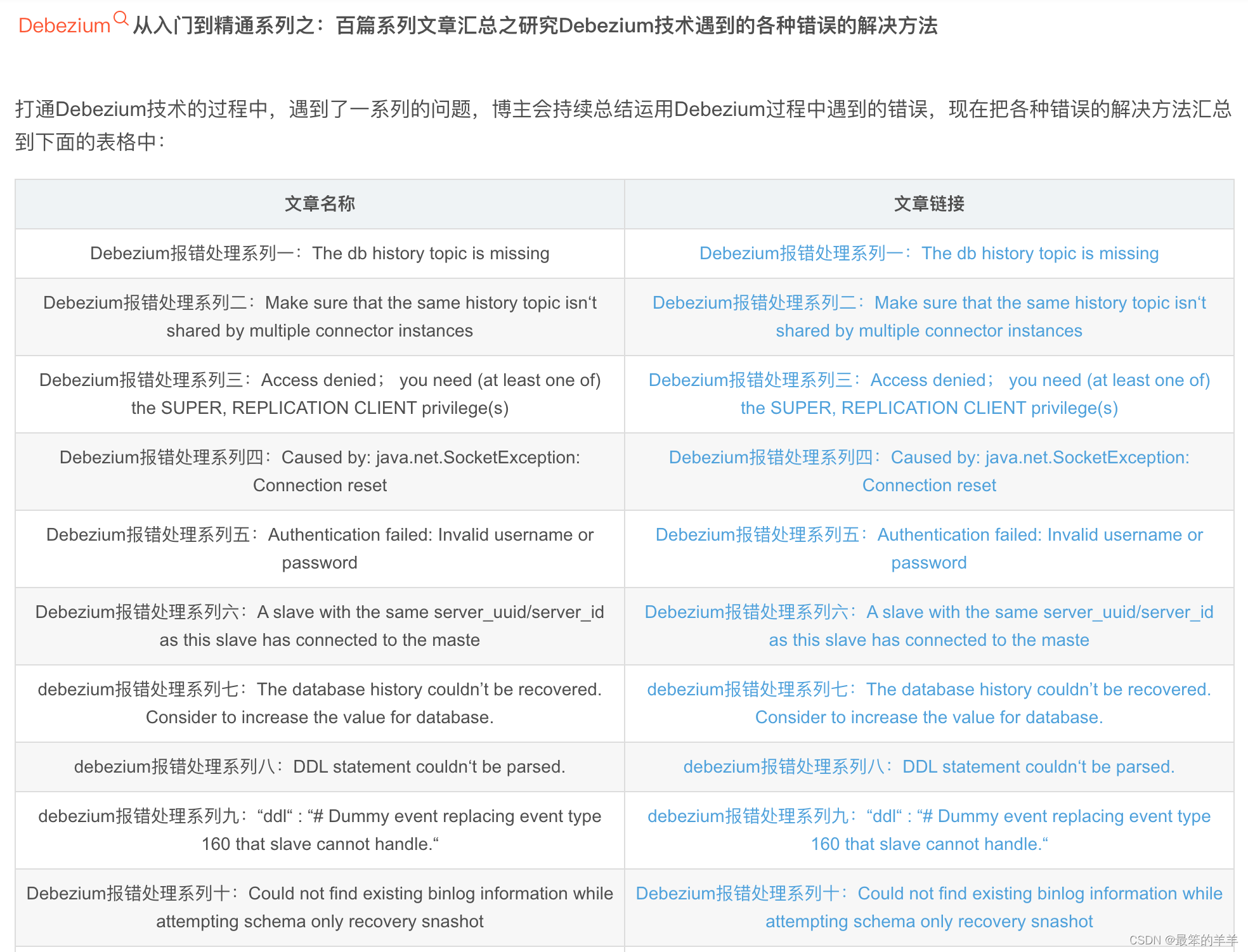
论文:2406.06911 (arxiv.org)
代码:czg1225/AsyncDiff: Official implementation of "AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising" (github.com)
简介
异步去噪并行化扩散模型。提出了一种新的扩散模型分布式加速方法,该方法在对生成质量影响最小的情况下显著降低了推理延迟。

原理:用异步过程取代顺序去噪过程,允许去噪模型的每个组件在不同的设备上独立运行。
动机:扩散模型的多步顺序去噪特性导致了高累积延迟,无法并行计算。AsyncDiff是一个通用的即插即用加速方案,可以跨多个设备实现模型并行,将噪声预测模型分成多个组件,并将每个组件分配给不同的设备。为了打破组件之间的依赖链,它利用连续扩散步骤中隐藏状态之间的高度相似性,将传统的顺序去噪转换为异步过程。因此,每个组件都便于在单独的设备上并行计算。该策略显著降低了推理延迟,同时对生成质量的影响小。AsyncDiff还可以应用于视频扩散模型。
原理
先验知识

异步扩散模型
为了解决扩散模型中高延迟的局限性,利用多GPU进行分布式推理是一个有前途的解决方案。通过将顺序去噪近似为异步过程,实现了噪声预测模型的并行推理,有效地减少了延迟并打破了顺序执行的限制。
异步去噪。
对于由T步组成的去噪过程,初始w步被指定为预热阶段。在此阶段,去噪模型ϵθ使用标准顺序推理进行操作。在热身步骤之后,不再分割输入图像,而是将去噪模型ϵθ划分为N个顺序分量,表示为![]() 。每个组件被划分以处理可比较的计算负载,并分配给不同的设备。
。每个组件被划分以处理可比较的计算负载,并分配给不同的设备。
这种划分旨在将每个组件的时间成本均衡到大约![]() ,从而减少总体最大延迟。xt的原始噪声预测可以表示为通过这些子模型的级联操作,定义为:
,从而减少总体最大延迟。xt的原始噪声预测可以表示为通过这些子模型的级联操作,定义为:
![]()

如图2所示,根据计算负荷,将重量级去噪模型ϵθ依次划分为多个分量![]() ,并将每个分量分配给单独的设备。核心思想在于通过利用 连续扩散步骤中隐藏状态的高相似性 来解耦 这些级联组件之间的依赖关系。
,并将每个分量分配给单独的设备。核心思想在于通过利用 连续扩散步骤中隐藏状态的高相似性 来解耦 这些级联组件之间的依赖关系。
每个组件将前一个组件的前一个步骤的输出作为其原始输出的近似值。这将传统的顺序去噪转换为异步过程,允许组件并行预测不同时间步长的噪声。此外,结合跨步去噪,以跳过冗余计算和减少设备之间的通信频率,进一步提高效率。
尽管每个设备都可以独立地计算其分配的组件,但依赖链仍然存在,因为每个组件的输入ϵθ,n派生自其前一个组件的输出ϵθ,n−1。因此,尽管模型组件分布在多个设备上,但完全并行化受到这些顺序依赖关系的约束。
我们的主要创新是通过利用前面步骤中的隐藏特性来打破级联组件之间的依赖关系。观察结果表明,去噪模型中每个块的隐藏状态在相邻的时间步长上总是表现出很大的相似性。利用这一点,时间步长为t的每个分量都可以将前一个分量在时间步长为t - 1的输出作为其原始输入的近似值。具体来说,第n-th个分量![]() 接收输出
接收输出![]() 。对xt的噪声预测表示如下:
。对xt的噪声预测表示如下:
![]()
在这个新框架中,噪声预测ϵt是从跨N个前时间步执行的组件派生的。这将去噪过程从顺序转换为异步,因为在步骤t + 1完成去噪之前,噪声ϵt的预测已经开始。在每个时间步,N个分量作为下一个N步的噪声预测模型的一部分运行。具体来说,在时间t并行计算的n-th个分量![]() 有助于对未来时间步t - N + n的噪声预测。图3使用n设为4的U-net模型描述了这个异步过程。连续扩散步骤之间隐藏状态的强相似性使得异步过程能够很好地模拟原始顺序过程的去噪结果。
有助于对未来时间步t - N + n的噪声预测。图3使用n设为4的U-net模型描述了这个异步过程。连续扩散步骤之间隐藏状态的强相似性使得异步过程能够很好地模拟原始顺序过程的去噪结果。
并行模型。通过转换到异步去噪策略,消除了同一时间步长内组件之间的依赖关系。这种调整允许提前准备时间步长t的每个组件的输入,从而使N个分裂组件能够跨多个设备并发处理。一旦计算出来,每个组件的输出必须被存储,然后广播到其他设备,以方便后续时间步骤的并行处理。
相比之下,在传统的顺序去噪过程中,每一步的时间成本累积如下:
图3:异步去噪过程概述。将去噪模型ϵθ分为四个分量![]() 。在预热阶段之后,提前准备好每个组件的输入,打破依赖链并促进并行处理。
。在预热阶段之后,提前准备好每个组件的输入,打破依赖链并促进并行处理。