大语言基础
GPT : Improving Language Understanding by Generative Pre-Training
提出背景
从原始文本中有效学习的能力对于减轻自然语言处理中对监督学习的依赖至关重要。很多深度学习方法需要大量人工标注的数据,限制了它们在很多领域的应用,收集更多的人工标注数据耗时且费钱。而且在有大量标注数据情况下,无监督学习到的好的向量表示能表现的更好。
但是从无标注的文本中利用信息有下面两个挑战
- 不清楚那种优化目标能最有效的向量表示,NLP中不同的任务(文本推理、文本问答、文本相似度评估等)用不同的目标,使得在仅在当前任务得到最优结果。
- 将学习到的文本表示迁移到目标任务上面的最有效的方法还没有共识,有的改模型结构,有的增加辅助目标。
GPT使用无监督的预训练(pre-training)和有监督的精调(fine-tuning)这种半监督的方式来解决这个问题,目标就是学习一个通用的向量表示,大量的下游任务仅需要做一点调整即可。
评估
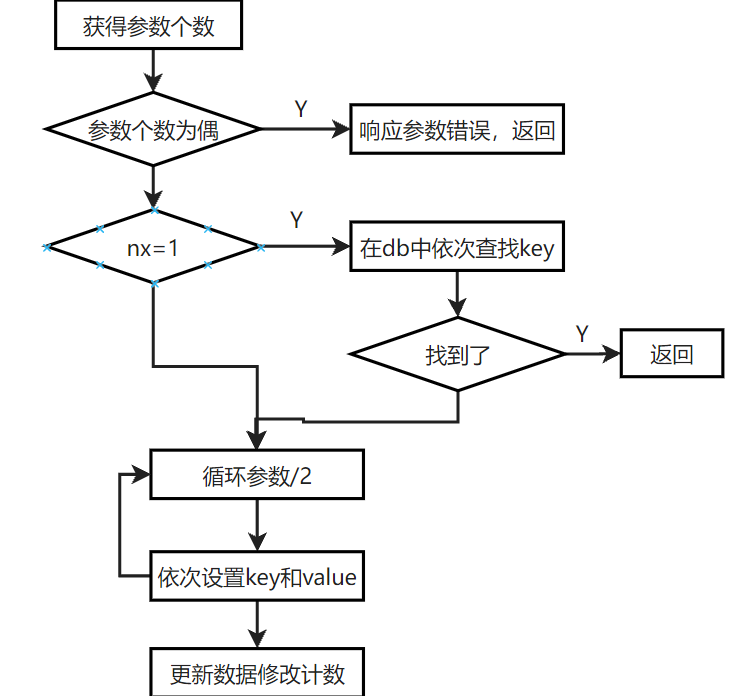
四类语音理解任务:自然语言推断、问答、语义相似性、文档分类。
方案详情
两阶段,第一阶段在一个大的文本语料库上面学习一个大容量的语言模型,第二阶段针对下游具体任务精调。
第一阶段:Unsuperviserd pre-training
对于token语料库 U = { u 1 , u 2 , . . . , n n } \mathcal {U}=\{u_1,u_2, ..., n_n\} U={u1,u2,...,nn},用标准的语言建模目标最大化下面的似然函数
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(\mathcal{U} ) = \sum_i \log P(u_i|u_{i-k}, ..., u_{i-1};\Theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;Θ)
这里 k k k表示上下文窗口size大小,模型参数 Θ \Theta Θ,使用SGD训练。
U = ( u − k , . . . , u − 1 ) U=(u_{-k},...,u_{-1}) U=(u−k,...,u−1)表示上下文token向量, n n n表示decoder层数, W e W_e We表示token的Embedding矩阵, W p W_p Wp表示位置向量矩阵
h 0 = U W e + W p h_0=UW_e+W_p h0=UWe+Wp
h l = t r a n s f o r m e r _ b l o c k ( h l − 1 ) h_l=\mathrm{transformer\_block}(h_{l-1}) hl=transformer_block(hl−1)
P ( u ) = s o f t m a x ( h n W e T ) P(u)=\mathrm{softmax}(h_nW_e^T) P(u)=softmax(hnWeT)
GPT参数量计算,参考Attention机制
使用Transformer的decoder,因为没有encoder,这里去掉了decoder里面需要encoder输入的multi-head attention模块,保留了masked multi-head attention。层数6->12,embedding维度512->768,注意力头数head_num 8->12,FFN层的隐层维度1024->3072。

这里 N = 4 , d = 768 , V = 40000 N=4,d=768,V=40000 N=4,d=768,V=40000
GPT预训练模型大小为
12 ∗ ( ( 4 + 2 ∗ 4 ) ∗ 76 8 2 + ( 5 + 4 ) ∗ 768 ) + 40000 ∗ 768 = 115737600 = 115 M 12*((4+2*4)*768^2+(5+4)*768)+40000*768=115737600=115\mathrm M 12∗((4+2∗4)∗7682+(5+4)∗768)+40000∗768=115737600=115M
GPT还有最后的一个线性输出层,参数量为 d ∗ V d*V d∗V,加上精调线性层的任务参数,总量为
12 ∗ ( ( 4 + 2 ∗ 4 ) ∗ 76 8 2 + ( 5 + 4 ) ∗ 768 ) + 40000 ∗ 768 + 768 ∗ 40000 + 768 ∗ 40000 = 146457600 = 146 M 12*((4+2*4)*768^2+(5+4)*768)+40000*768 + 768*40000 + 768*40000 =146457600=146\mathrm M 12∗((4+2∗4)∗7682+(5+4)∗768)+40000∗768+768∗40000+768∗40000=146457600=146M
第二阶段:fine-tuning
精调阶段的线性层
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l W y ) P(y|x^1,...,x^m)=\mathrm{softmax}(h_lW_y) P(y∣x1,...,xm)=softmax(hlWy)
精调阶段最大化下面的似然函数
L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , . . . , x m ) L_2(C)=\sum_{(x,y)} \log P(y|x^1,...,x^m) L2(C)=(x,y)∑logP(y∣x1,...,xm)
最终的似然函数
L 3 = L 2 + L 1 L_3 = L_2 + L_1 L3=L2+L1
模型结构

所有任务,都需要插入开始和结束符;
对于文本推断任务,把前提和假设用分隔占位符concat起来;
对于语义相似评估任务,因为没有顺序,所以讲text1和text2连接起来作为一个输入,同时将text2和text1连接起来作为输出,经过各个的Transformer后concat起来;
多项选择任务,把context和各个候选答案分别concat起来作为输入;
实验
数据集:BookCorpus,超过7000本书,

预训练参数配置

精调参数配置

在文本推断任务的表现

在问答任务的表现

在文本分类任务的表现

Transformer层数的影响(下面左图),层数越大效果越好;比较Zero-shot的表现,和LSTM比较,Transformer随更新步数增长效果更好,LSTM就差很多,预训练的模型容量比较重要。

消融分析
精调阶段使用/不使用辅助的LM目标(aux LM);去掉预训练;相同层数的LSTM(单层2048个unit);

BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
提出背景
GPT是从左到右单向的语言模型,ELMo也是单向的(单向的从左到右和单向的从右到左,然后concat到一起),单向的语言模型会限制它在下游的表现。
BERT提出双向的Transformer模型
方案详情
示意图如下

BERT的输入包括三部分,Token Embedding、Segment Embedding(句子pair中的句子A还是句子B)、Position Embedding

和其他结构比较

BERT是双向的Self-Attention,既可以看到前面的token,也可以看到后面的token,BERT的目标与GPT不一样了,GPT是根据前面的词预测后面的词,BERT是根据前后的词预测当前位置的词,类似于完形填空。
为此BERT引入了掩码语言任务(Masked LM),随机mask一个token,然后根据这个token之前及之后的token来预测这个token;mask的token用[MASK]占位符替代,在每个sequence里面随机mask15%的比例的token。但是[MASK]这个token并不在fine-tuning阶段出现,为了缓解预训练和精调之间这种不一致,预训练在mask的时候并不总是用[MASK]这个token代替,80%的概率用[MASK]代替,10%的概率随机选择一个token代替,10%的概率就用原来的token不做替换。
这里mask策略也是调参调出来的

示意图如下:

这里最上面是 MLM 的多分类任务,多出的这个线性层矩阵 W ∈ R d i m ∗ V W \in R^{dim*V} W∈Rdim∗V是和输入的词汇表 embedding 矩阵共享的,就是多了一个偏置 b ∈ R 1 ∗ V b \in R^{1* V} b∈R1∗V,也就是此处多了 V V V个模型参数。
很多NLP的任务像问答、推断都是理解两个句子的关系,语言模型不容易直接识别到时哪种任务,为了使模型理解两个句子之间的关系,引入了下一个句子预测任务(Next Sentence Prediction , NSP),构造样本的时候,句子A后面50%的概率是后面接着的句子B(label标记为IsNext),50%的概率从语料库从语料库随机选(label标记为NotNext)
最上面是个二分类任务,有一个线性矩阵 W ∈ R d i m ∗ 2 W \in R^{dim*2} W∈Rdim∗2 来表示。
fine-tuning细节和GPT一致
实验
实验配置, B E R T B A S E \mathrm {BERT_{BASE}} BERTBASE 为了和GPT对比,和GPT的参数配置几乎完全一样。
B E R T B A S E \mathrm {BERT_{BASE}} BERTBASE L=12,H=768,A=12
B E R T L A R G E \mathrm {BERT_{LARGE}} BERTLARGE L=24,H=1024,A=16
token数量(V)和GPT不一样,其他一致, N = 4 , d = 768 , V = 32000 N=4,d=768,V=32000 N=4,d=768,V=32000,不算后面fine-tuning阶段线性层的参数
B E R T B A S E \mathrm {BERT_{BASE}} BERTBASE预训练模型大小为(加上每个位置的 embedding 512768、NSP 二分类任务参数 7682、MLM 多分类任务参数 32000(分类任务权重矩阵和词表 embedding 矩阵共享,但是有独立的偏置,参数量32000))
12 ∗ ( ( 4 + 2 ∗ 4 ) ∗ 76 8 2 + ( 5 + 4 ) ∗ 768 ) + 32000 ∗ 768 + 512 ∗ 768 + 768 ∗ 2 + 32000 = 110020352 = 110 M 12*((4+2*4)*768^2+(5+4)*768)+32000*768 + 512*768+768*2 + 32000=110020352=110\mathrm M 12∗((4+2∗4)∗7682+(5+4)∗768)+32000∗768+512∗768+768∗2+32000=110020352=110M
B E R T L A R G E \mathrm {BERT_{LARGE}} BERTLARGE预训练模型大小为
24 ∗ ( ( 4 + 2 ∗ 4 ) ∗ 102 4 2 + ( 5 + 4 ) ∗ 1024 ) + 32000 ∗ 1024 + 512 ∗ 1024 + 1024 ∗ 2 + 32000 = 335537408 = 335 M 24*((4+2*4)*1024^2+(5+4)*1024)+32000*1024 + 512*1024 + 1024*2 + 32000=335537408=335\mathrm M 24∗((4+2∗4)∗10242+(5+4)∗1024)+32000∗1024+512∗1024+1024∗2+32000=335537408=335M
实验效果

RoBERTa: A Robustly Optimized BERT Pretraining Approach
BERT的升级优化版本
提出背景
BERT训练不充分,还有很大的空间
提升措施:
- 让模型训练的更久、使用更大的batch size,使用更多的数据
- 去除下一个句子预测任务NSP
- 在更长的sequence序列上面训练
- 在训练数据中动态改变mask方式
方案详情
增加语料库
- BOOKCORPUS加上英语WIKIPEDIA,这是BERT用的语料库(16GB)
- CC-NEWS,这是RoBERTa从CommonCrawl新闻数据集手机的,包含6300万英语新闻文章(2016年至2019年)(76GB)
- OPENWEBTEXT开源的WebText语料库,从Reddit上面根据URL抽取的web内容(38GB)
- STORIES包含了过滤的CommonCraw数据子集(31GB)
下游任务评估基准
GLUE:The General Language Understanding Evaluation,包含9个数据集来评估自然语言理解。
SQuAD:The Stanford Question Answering Dataset 提供一个上下文的段落及以问题,任务是通过抽取上下文回答问题。
RACE:The ReAding Comprehension from Examinations 大规模的阅读理解数据集,包含28000篇文章和100000个问题,来自中国的中学英文考试题目。
改进BERT
配置和 B E R T B A S E \mathrm {BERT_{BASE}} BERTBASE一样 (L=12, H=768, A=12, 110M参数量)
BERT模型在数据预处理的时候就mask好了,称为静态mask(static masking)数据复制了10份,在40个epoch里面,每份训练数据会相同mask4次。这里采用动态mask(dynamic masking)训练数据每次都是动态mask,保证训练时不会有重复的mask数据。动态masking效果更好,后面的评测均用动态masking。

原始BERT里面有个NSP任务,预测下一个句子的任务,去掉NSP会影响效果,但是有很多质疑的研究,起作用的主要是MLM,并不是NSP,为此做了一些消融实验来验证。
SEGMENT-PAIR+NSP:原始的BERT的方式,每个输入是一个Segment pair对,每个Segment可以包含多个自然句子,多个句子的总长度不超过512个tokens。
SENTENCE-PAIR+NSP:每个输入是一个自然句子pair对,因为这些句子显著低于512个tokens,因此增大batch size使得batch内总的token数量与SEGMENT-PAIR+NSP相似,也有NSP loss。
FULL-SENTENCES:每个输入是从一个或者多个文档中连续采样得来的,每个输入最多512个tokens,输入可能跨文档,如果跨文档,增加一个额外的分割token在里面,同时去除NSP loss。
DOC-SENTENCES:构造方式和FULL-SENTENCES类似,就是句子不跨文档。那么采样文档末尾的句子的时候,token长度可能小于512个,那就动态增加batch size,使得batch内的token和FULL-SENTENCES相似。
结果如下:
SEGMENT-PAIR+NSP vs SENTENCE-PAIR+NSP 说明使用单个句子模型没法学习到长距离依赖关系。
FULL-SENTENCES vs SEGMENT-PAIR+NSP:说明去除NSP loss会提升下游任务表现
FULL-SENTENCES vs DOC-SENTENCES:限制sequence来自同一个文档有轻微提升,但是batch size是动态的,为了对比方便,后面都使用FULL-SENTENCES这一组。

更大的batch size
更大的batch size带来更好的效果

文本编码方式
Byte-Pair Encoding(BPE)是字符级和单词级表示的混合,该编码方案可以处理自然语言语料库中常见的大量词汇。BPE不依赖于完整的单词,而是依赖于子词(sub-word)单元,这些子词单元是通过对训练语料库进行统计分析而提取的,其词表大小通常在 1万到 10万之间。
原始的BERT使用的是字符级的编码,词汇量30K,RoBERTa使用BPE编码,词汇量50K,相对 B E R T B A S E \mathrm {BERT_{BASE}} BERTBASE和 B E R T L A R G E \mathrm {BERT_{LARGE}} BERTLARGE会多出15M到20M的参数量。
实验效果