RWKV想逐步成为最强开源模型,中期计划取代Transformer。能如愿吗?
“我们没有护城河,OpenAI也是。”近期,谷歌内部人士在Discord社区匿名共享了一份内部文件,点破了谷歌和OpenAI正面临的来自开源社区的挑战。尽管经外媒SemiAnalysis求证,文件内容仅代表谷歌部分员工而非整个公司的观点,但其中陈述的一个事实再次引起了广泛关注和讨论——开源LLM正呈现出百花齐放的态势。
抛开开源和闭源之争,可以窥见,同时更加值得关注的是,模型架构和算法层面的创新将加速涌现。
如德克萨斯大学教授Alex Dimakis对谷歌内部文件泄露事件发表的观点中所指,LoRA(low rank adaptation,低秩适应,一种创新的大型语言模型微调机制)打开了算法创新的大门。而被泄露的谷歌内部文件也提到,模型可扩展性和低成本微调机制这两个问题的解决,使得公众能以更低成本参与模型开发和优化迭代过程。
当前,在开源LLM的大军中,也不乏中国开发者的身影。例如,在开源社区吸睛无数的,除了LLaMA及其变体,还有清华团队开发的ChatGLM 6B模型。
而在开放型研究组织 LMsys 5月8日最新公布的LLM基准测试排名中,榜单上出现了又一个出自中国开发者之手的LLM——“RWKV-4-Raven-14B”。其排名已在ChatGLM 6B之前,同时,在开源LLM中,仅次于Vicuna 13B和Koala 13B。
在模型架构上,RWKV创新地将GPT transformer改写成RNN形式。由于在设计上保留了transformer block的思路,RWKV同时具备RNN和Transformer的部分特性。
RWKV此前在GitHub和Discord上也颇受关注。目前,RWKV在GitHub上已获得6.4k stars,模型训练由Stability赞助。
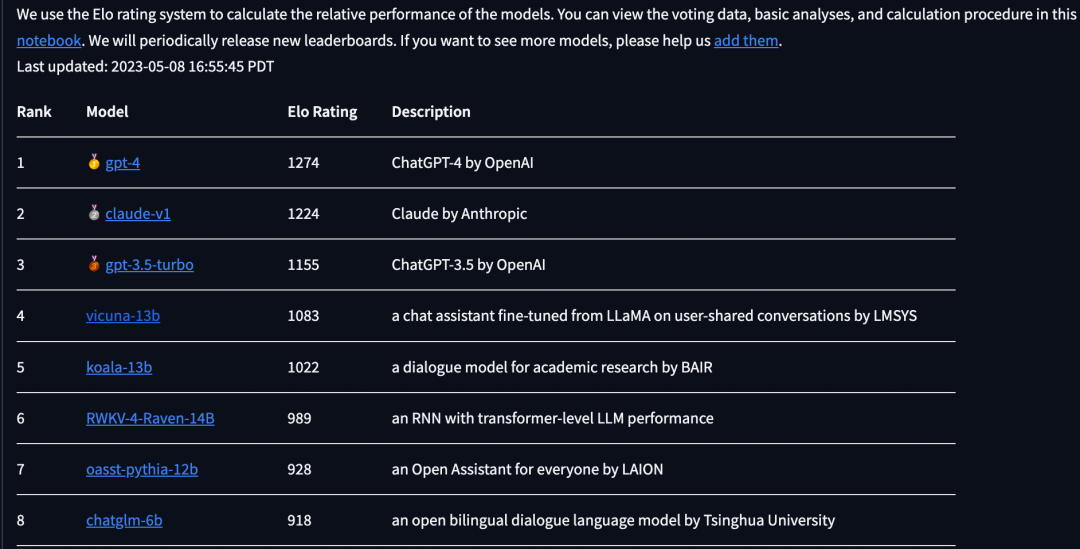
LMsys 5月8日最新公布的LLM基准测试排名 参考https://chat.lmsys.org/?leaderboard
为什么选择开源方式,开源项目有何特征?与其他大型语言模型相比,RWKV有何不同之处?具体而言,RWKV具备什么特性、模型性能如何,以及下一步将如何发展?RWKV的商业计划是什么?
带着这些问题,36氪采访了“RWKV”模型以及“元智能OS”的创始人彭博。
据彭博介绍,RWKV拥有RNN的速度快、显存占用少的优点,解决了传统RNN的缺陷。同时,和transformer一样,RWKV可以并行推理和训练。
目前,RWKV已完成0.1B到14B英文模型训练,以及7B中文对话和小说模型的初步训练(使用英文词表)。RWKV很快将启动0.1B到14B的全球多语种(包含中文)模型的正式训练(使用多语言词表),并逐步达到千亿参数规模。同时,今年新成立的元智能OS团队将关注RWKV的生态建设和模型定制,加入图像、音频、视频、3D等多模态能力。
彭博告诉36氪:“RWKV将始终保持完全开源和非盈利性质,愿景是成为‘AI领域的Linux’,而元智能OS的愿景则是成为‘AI领域的Android’。”
以下是36氪和彭博的对话,经编辑:
 “闭源”封不住,Transformer 也不是唯一解
“闭源”封不住,Transformer 也不是唯一解
36氪:我们观察到第一版RWKV在Github上的发布时间是21年8月。您是什么时候决定开发RWKV的?
**彭博:**实际是三年前,我的兴趣是AIGC,特别是小说生成。在发布RWKV之前,我一直在研究如何改进GPT,并发现了许多独门技巧,如“Token Shift”。RWKV的诞生,来自于这些技巧的优化,也来自于对GPT的attention注意力机制的改造和数学变换。
36氪:当初为什么选择以开源的方式来做这件事?
**彭博:**我认为,一个公开的、人人可用的强AI是非常重要的。大多数人都不会愿意看到强AI被巨头垄断,这也不利于人类进步。
当然,开源项目在做大之前,效率往往低于闭源,但项目走上正轨后,实现正反馈运转,它的发展和生态就可以完全胜过闭源项目。
DALL-E2和Stable Diffusion的对比就是很好的例子。DALL-E2刚做出来的时候,大家都说效果很厉害,但现在没有人关注DALL-E2,大家都在用Stable Diffusion。
DALL-E2退出战场之后,大家的关注点就变成了Midjourney和Stable Diffusion。目前这两者有互补关系。Midjourny作为商业产品,对新手用户更友好,这是闭源商业项目的常见优势。开源项目的用户体验往往更粗糙,但Stable Diffusion的功能和定制性更强大,更适合熟手用户。
36氪:开源方式会不会带来安全方面的问题?OpenAI也表明不公开GPT-4模型相关细节的部分原因是为了安全考虑。
**彭博:**OpenAI曾表示,他们选择闭源的原因之一是认为闭源更安全。这有一定道理,但我认为,从技术发展的角度来讲,封是封不住的。
当初ChatGPT出现时,许多人惊呼OpenAI强无敌,但我认为现在大模型之所以发展快,是因为门槛实际不高,只要投入足够物力和人力,所有人都可以做出来这个效果。这里不存在黑科技,也不存在技术封锁的可能。
所以,在今天这个时间点,我们就看到了“百模大战”。
36氪:看起来您对OpenAI和GPT系列模型现阶段取得的成功有不同的看法?
**彭博:**大家都聊OpenAI方法论。但在我看来,有句流行语,“有多少人工就有多少智能”。这个过程中,最关键的不是工程优化,而是“数据+人工查漏补缺”。因为OpenAI从GPT-3开始,就有了很多测试用户,收集了多年的用户反馈数据。在这个基础上,他们对模型进行持续训练,补漏洞的工作就能做得很好。
36氪:在OpenAI的成功里,Transformer的贡献度有多大?
彭博:Transformer本身的学习能力很强,所以现在的大模型发展才会如此迅速。
36氪:可以理解为您认同“Transformer是目前为止最好用的(开发LLM的)‘砖块’”这一观点吗?
**彭博:**如果理解Transformer的运行原理,会发现,它的效果优,是因为思维方式很像人类。举个简单例子,Attention的核心是Q、K、V,它会根据Query往前查找比对,找到匹配的Key,把Value取过来,这类似于人查阅资料的过程。
相较于传统RNN,Transformer有很多优点,在训练时更容易scale和并行化,不会出现梯度消失,能捕捉序列中元素之间的长程依赖关系。
但Transformer,或者Attention,并不是唯一正解。
例如RWKV,没有Attention,也能做到GPT级别的效果,包括in-context learning能力。
有趣的是,RWKV并不是不断改进传统RNN的成果。我是在不断调优GPT的过程中,发现可以把GPT改造成RWKV这种纯粹的RNN形式,同时依然保持很强的性能。
关于RWKV的具体原理,感兴趣的读者可以阅读:https://github.com/BlinkDL/RWKV-LM 。
36氪:目前有类似研究吗?之前也有很多研究尝试改进transformer,或者试图直接优化RNN。比如最近谷歌发布的《Scaling Transformer to 1M tokens and beyond with RMT》,以及更早之前发布的《Resurrecting Recurrent Neural Networks for Long Sequences》。您怎么看?
**彭博:**苹果公司的论文《An Attention Free Transformer》是RWKV的重要参考文献。这篇文章被主流学术界漠视,但我看到时就认为其中的思想和结果很有潜力。在研究和思考后,我意识到,如果将公式做深入调整和变换,最终可以写成RNN的形式。
但要实现目前RWKV的性能,还需要加入更多技巧(如之前提到的“Token Shift”)。同时,在RWKV-4中我还解决了大模型训练的数值溢出问题。
在前几年,有大量论文希望简化Attention,估计可以找出几十篇。但它们在简化Attention后,语言建模的性能都会有显著下降,所以没有人用。最近两年才开始有研究(如State Space系列)性能可以逐渐看齐GPT。
“RWKV”这篇论文思路比较常见,类似于检索。我个人赞同检索和工具的思路,但这种改进和模型架构无关。
36氪:所以和这些研究或者模型相比,RWKV的不同之处是什么?
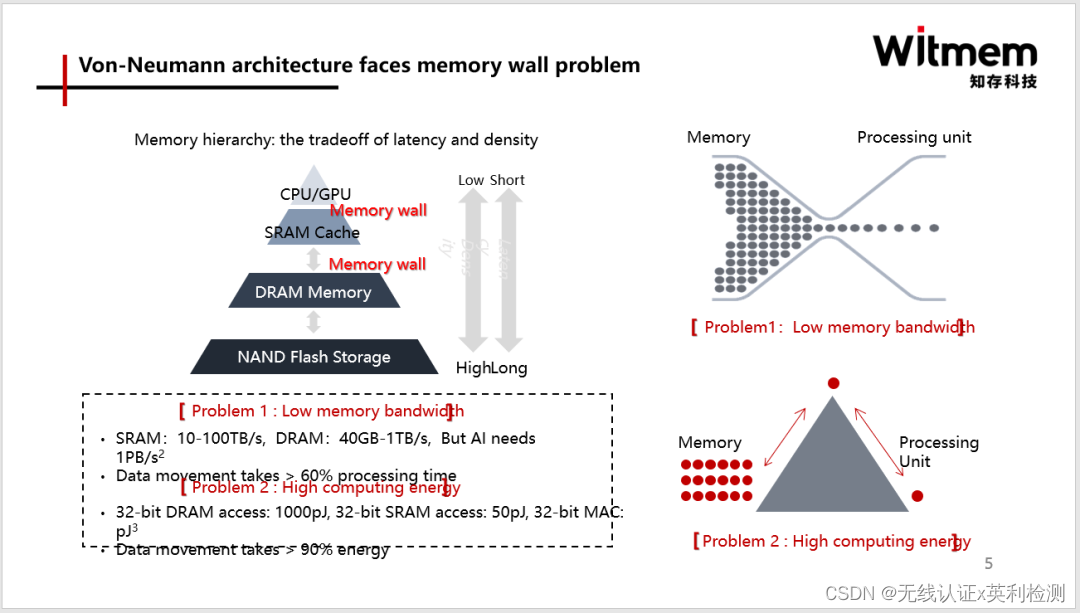
**彭博:**首先,RWKV的时间、空间复杂度很低。GPT的时间复杂度是O(N2),通俗说,会越写越慢。因为它每写一个字,需要把前面所有字都“读”一遍,并且需要始终记录每个字的状态。GPT的空间复杂度,用简单方法做是O(N2),用聪明方法可以做到O(N),所以也会随着文本长度增加而不断增长。
而RWKV的时间复杂度是O(N),空间复杂度是O(1)。也就是,RWKV的生成速度是匀速的,显存占用也是恒定的,写多少字都不会增长。
其次,虽然几年前就有论文把GPT写成某种RNN,但做出来性能损失非常厉害。RWKV不但可以把GPT做成性能没有损失的RNN形式,而且在scale(模型扩大)之后,性能还有越来越强于GPT的趋势。
36氪:在这样的情况下,会不会牺牲掉其他一些方面的模型特性?
**彭博:**纯RNN像“盲人骑瞎马”,每写一个字,只能看前一个字的状态,不能往前再看自己写过的东西。如果输入一段很长的资料,它读完一遍,是不能再返回继续读的。这类似于人类读了一遍资料,在不再看资料的情况下直接回答。
而GPT,每写一个字就要重新看一遍前文,效率很低,但会更容易地认真检查前文的每个字。
也可以说,GPT像笔试,纯RNN像口试。RWKV作为纯RNN,会损失对“无用细节”的记忆力(注意模型会自动判断哪些内容重要)。
有趣的是,虽然RWKV是盲人骑瞎马,它生成的效果却往往很好。我们观察到RWKV的长文本生成能力很强。
比如给定一个小说开头,让模型连续生成5000字的文本。如果用GPT,生成的文本容易散掉,容易出现自我重复或者质量下降的情况。RWKV就不会有这样的问题。
传统的RNN,遗忘问题很严重,例如著名的LSTM试图增强RNN的记忆力,但它大致在100多个token后就会逐渐忘记前面的内容。而RWKV在几千个token后仍可以记住前文的重要内容。
36氪:但GPT-4在考试方面能力似乎很出众。考试和写小说,谁更难?
**彭博:**许多人认为GPT答考试题拿高分所以很厉害,但我认为写小说比答考试题更难得多。因为写小说需要推演整个世界的演化,涉及各种人物、势力。他们有各自的目的、计划、关系、性格、经历和想法,这是一个远远更难的任务。
36氪:有解决搞错细节这个问题的办法吗?
**彭博:**首先需要指出,模型一定会记住重要的细节,例如小说人名。难记忆的是无用细节,也就是正常的后文不太会关注的细节。
但第一,如果专门针对这个任务进行训练,模型的准确性会显著提高。
第二,我测试过在RWKV中加5%的attention(例如RWKV v4b系列),得到的混合模型,所有能力都可以比GPT强(包括“无用细节”的记忆力)。而且它仍然快、省显存。现在为了保持纯粹度(100% RNN),我在绝大多数RWKV模型没有加attention。
第三,我们的模型其实只需要作为一个“大脑”,类似于人可以调用工具,语言模型也能运用工具记忆和查阅记录实现自我增强(就像AutoGPT调用数据库)。
第四,我们发现RWKV到14B参数量后,也有较强的背诵能力。对于未来100B以至1T的大模型,它的记忆力会更强。背诵对Transformer很简单,但对RNN来说有点神奇,因为RNN要把前面所有看过的东西压缩进系统自己的状态,这个压缩是有损的过程。
第五,RWKV通过选择性遗忘,实现了明确的state of mind,而GPT不存在这种能力。所以,未来如果有一个规模很大很强的RWKV,它将会像是拥有某种“意识”,这会是好事还是坏事?我认为,“有意识”和“无意识”的AGI都有各自的风险。
 模型架构不同于GPT,当前性能互有胜负
模型架构不同于GPT,当前性能互有胜负
36氪:您提到Transformer不是唯一解,可以理解为RWKV预期实现的最终目标是取代Transformer吗?
**彭博:**RWKV的短期目标是逐步成为开源模型的龙头,然后中期目标是取代Transformer。现在英文LLaMA、中文ChatGLM,大家都很认可。在同等参数量下,RWKV和这两个模型都是互有胜负的关系(有的能力更强,有的能力更弱)。我们会不断增强RWKV的能力。
36氪:您对第一个目标的实现,有没有大概的时间预期?
**彭博:**我相信今年就可以完成。因为今年我们会用更大数据量训练更大参数规模(100B)的模型,并同步训练多语言(包括中文)模型。
LLaMA的性能强,是因为用了足够多数据进行训练。目前我们的英文数据规模比LLaMA小很多。LLaMA是1.5T,RWKV是0.3T,只有LLaMA的五分之一数据量,但现在RWKV的能力也已经很强,说明RWKV的上升空间很大。我们正在用1.7T英文数据训练下一代模型。
LLaMA有很多变体,其中最强的模型是Vicuna,目前RWKV 14B和Vicuna 13B是4/6开,我们4,它6。但RWKV的速度比Vicuna明显更快,显存占用更少。随着RWKV的持续进步,我们今年有信心全面胜于所有LLaMA变种。
现在RWKV中文7B模型和ChatGLM 6B中文模型也是互有胜负,不过,RWKV还没开始真正炼中文模型,使用的是英文词表,还没有加入大规模中文语料。但它的中文能力已经很不错了。
36氪:有关于RWKV模型性能的客观评测结果吗?
**彭博:**我们做了多种zero shot任务的测试。RWKV模型使用的是Pile语料,和同样使用Pile语料的Pythia、GPT-NeoX、GPT-J对比,RWKV的各项指标都是有竞争力的。
但学术评测数据集只能作为参考,因为这些数据集的题目质量参差不齐。所以,只有用户自己的使用感知,以及LMsys Arena这种用户盲测,才是比较可控的评分标准。现在也有一些自动评分的方法,例如用GPT-4来评估,感兴趣的同学可以自行尝试。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GOQKculu-1684321939863)(data:image/svg+xml,%3C%3Fxml version=‘1.0’ encoding=‘UTF-8’%3F%3E%3Csvg width=‘1px’ height=‘1px’ viewBox=‘0 0 1 1’ version=‘1.1’ xmlns=‘http://www.w3.org/2000/svg’ xmlns:xlink=‘http://www.w3.org/1999/xlink’%3E%3Ctitle%3E%3C/title%3E%3Cg stroke=‘none’ stroke-width=‘1’ fill=‘none’ fill-rule=‘evenodd’ fill-opacity=‘0’%3E%3Cg transform=‘translate(-249.000000, -126.000000)]’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)图片来源于GitHub BlinkDL / ChatRWKV
36氪:RWKV最初的训练数据来源于哪里?
**彭博:**RWKV的基底模型使用的是开源英文数据集Pile。目前的中文数据集来自于网络小说和百科、维基等。
36氪:先练英文模型是因为考虑到可用数据的质量和规模的问题吗?
**彭博:**首先,在当时来看(开发RWKV之初),虽然中文用户多,但英文的开发者更多,热情更高。不过,现在国内的开源开发热情也越来越高,这可能是Stable Diffusion带来的变化,所以现在的中文模型优先级也很高。
其次,目前RWKV用的是英文词表,常常需要两三个token才可以表达一个中文单字,这会显著影响生成效果,如果这时就去炼中文大规模数据,属于浪费算力。我在前不久做好了多语言词表,所以很快就能正式炼多语言模型和中文模型,中文能力和生成速度都会提高。
36氪:RWKV的模型训练方法和GPT一样吗?训练消耗了多少算力成本?花了多少时间?
**彭博:**我们完全用了GPT的训练方法,不需要任何修改。这也是RWKV的优势,因为传统RNN的训练方法会有区别,而且会比GPT训练慢很多。
RWKV的训练速度比GPT更快。举个例子,RWKV 14B的模型如果用64张A100,炼Pile是332G tokens,如果用快的练法需要一个月,用慢的练法需要三个月。我用了慢的练法,因为慢工出细活,效果会略好一点。
所有RWKV模型加起来的算力成本是小几百万。这是Stability赞助的免费算力。如果用快的炼法,用大几十万就可以了。
36氪:Stability是什么时候开始赞助的?
**彭博:**我和他们很熟悉,因为很早之前我就在EleutherAI的Discord群组里。几年前我做了Transformer的几个改进,群里的开发者当时试了发现确实有效,所以比较认可。之后我开发RWKV,大家也都共同见证了RWKV的成长。
36氪:RWKV的人类价值观对齐是怎么做的?
**彭博:**这个和大家的做法也没有区别,适用于GPT的也同样适用于RWKV。RWKV特殊之处只在于替换了Attention组件。
目前,大家主要从数据(SFT)和RLHF两个方面来做。还有研究指出,可以做AI的自我审查,让AI回答之后自我审查并进行修正。
另外,提到价值观,我认为有必要在AI模型加入中国价值观,构建一个社会主义核心价值观的数据集。目前美国公司和OpenAI都会用自己的价值观去塑造AI模型。
但如果以后有强AGI,这些方式都没有意义。强AGI比人类更聪明,足以操纵和骗过人类,而且会自我进化。这是AI最危险的地方,也是为什么国外很多AI研究者都持有悲观态度。到这个维度,大家担心的就是更直观的AI安全,AGI是否会处心积虑(或随意地)毁灭人类。
这也是我为什么认为必须建设开源AI。如果AI封不住,就需要加强公众对AI的了解和认知,最终全世界人类共同来探讨、研究、抉择。
36氪:我们比较好奇,社区里也有网友来问,您为什么没有整理出一篇论文,来扩大影响力呢?
彭博:因为确实太忙。在开源项目早期,我一个人要做所有事情,包括模型的设计、改进、优化、训练,以及清洗数据(这最耗费时间),以及回答中外网友的问题、宣传推广。但是现在已经有团队在帮忙写RWKV论文,之后大家可以在论文里看到RWKV 的全面技术介绍。目前可以先看Github上RWKV-LM项目的Readme。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dfei1x3H-1684321939864)(data:image/svg+xml,%3C%3Fxml version=‘1.0’ encoding=‘UTF-8’%3F%3E%3Csvg width=‘1px’ height=‘1px’ viewBox=‘0 0 1 1’ version=‘1.1’ xmlns=‘http://www.w3.org/2000/svg’ xmlns:xlink=‘http://www.w3.org/1999/xlink’%3E%3Ctitle%3E%3C/title%3E%3Cg stroke=‘none’ stroke-width=‘1’ fill=‘none’ fill-rule=‘evenodd’ fill-opacity=‘0’%3E%3Cg transform=‘translate(-249.000000, -126.000000)]’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)RWKV商业化,重点关注GPT不能做的
36氪:刚刚您提到RWKV从0到1的过程几乎是自己亲力亲为的,那目前的团队是什么时候组建的?大概是什么规模?
**彭博:**我和CTO刘潇是在Discord认识的。他此前一直在自研AIGC模型的工程化和应用开发,并上线了网站和服务。COO孔晴和联创罗璇是在今年1月份加入的,他们也有丰富的运营和管理经验。
目前我们还有远程工程师和语料清洗团队。我们现在是分布式办公。因为大家都是自驱工作的,效率比较高。
36氪:我们关注到您也在一些社交平台和社区里号召大家一起来洗数据?
**彭博:**对,我在知乎有一些这样的号召。大家一起来收集多语言的数据,大家也都可以用。
36氪:目前公司对RWKV的商业化有明确规划了吗?
**彭博:**有,商业化是并行的。因为商业化有利于大模型的生态发展。如前所述,RWKV的愿景是成为AI领域的Linux(会始终保持完全开源和非盈利),而元智能OS的愿景是成为AI领域的Android。
商业化分为两个方面。
一是“RWKV+软件”,分为专业应用和娱乐应用两个方向。专业应用的to B包括API和 SDK,包括专业生产力工具,例如文本生成、写作、图片处理工具,在垂直领域还包括教育和电商,我们已有一些合作伙伴。娱乐应用主要是to C,如图像、视频、游戏等等。
二是“RWKV+硬件”。由于RWKV对于硬件非常友好,比GPT更适合芯片和端侧,我们将逐步实现RWKV大模型嵌入各类终端,包括手机、电脑、IoT智能设备终端,也包括机器人和XR等。
36氪:目前商业化进展如何?
**彭博:**现在中文小说和Chat模型是免费下载的,同时已有一些客户在合作进行定制和私有化部署。
在终端的合作方面,已经有多家手机和芯片厂商对RWKV非常感兴趣,并开始移植和测试模型。因为RWKV目前能直接在端上高效运行,这是RWKV的一个独特优势。
36氪:目前考虑融资吗?
**彭博:**我们正在和国内投资机构讨论融资。RWKV拥有国产自主可控的大模型架构,并且支持终端私有化部署,14B参数规模的验证也已经完成。所以,我们目前得到了社会各界的许多支持。很多合作方是主动找到我们的。
36氪:出门问问也认为在智能硬件设备是大模型很重要的应用场景。这个和大模型的终端部署思路一致吗?
**彭博:**真正的端侧部署,需要模型在设备上直接运行。目前各家应该只是将手机连到了云端的API,并不是把整个大模型部署到端上去,所有的AI能力都在云端。这样会带来三个问题。一是响应时间,网络会有延迟和流量。二是所有的云服务资源消耗是不经济的,因为终端上有计算能力,但仍然要调用云端的计算能力,这是对算力的浪费。三是很多用户会有泄漏私人数据的顾虑。
36氪:RWKV已经能够实现这样的端部署了吗?
**彭博:**目前GPT用llama.cpp项目,RWKV用rwkv.cpp项目,都可以在手机、电脑上跑。未来的专用芯片出现后,端侧模型的推理速度会快很多,硬件要求会低很多。
但由于前面提到的模型特性,RWKV的速度和芯片成本会有优势,能耗也更低。因为RWKV的推理是匀速的,显存占用也是恒定的,不会出现类似GPT爆显存的问题。另外,RWKV的推理只需要矩阵和矢量的乘法,而GPT需要矩阵和矩阵乘法。
我们认为未来端部署会是一个大趋势。目前大家都在用云,但以后会是端和云的结合。也就是,云侧有一个超大模型,端侧有一个大模型。我的观点是,AI大模型的决战战场是在硬件上面,也就是芯片。无论是端侧和云测都需要专用芯片。
36氪:所以咱们需要有芯片厂商来加入到合作生态中?
**彭博:**目前已有几家AI芯片厂商在移植RWKV算子,例如华为昇腾已经支持RWKV的推理和训练,我们也非常欢迎各家AI芯片厂商的朋友一起合作。未来会有RWKV的ASIC专用芯片,在手机等设备上就可以快速跑大模型。
36氪:刚刚提到了不同层面的商业化打算,现阶段的重点是什么?
**彭博:**重点是本地化部署和定制。需求主要来自客户对数据安全和本地部署成本的考虑。目前海内外可选的其实不多,国内有ChatGLM,海外有LLaMA。和他们相比,我们的资源消耗更低。这对to B领域来说很重要,所以在一些to B的高价值领域,已经有客户联系我们。
to C端,许多个人用户也希望有自己的AI私人助手,不希望自己的数据被泄露,同时用户需要模型够快,对于硬件需求够低,这也是RWKV擅长的领域。
无论是to C还是to B,我们的主打都是现在GPT做不到,市面上只有我们能做的点。
36氪:这样一来,对数据安全有要求的企业,以及面向个人的端部署应用,相关的数据是无法反哺给基础大模型来做迭代优化的?
**彭博:**对于基础模型而言,加的数据越多越好,但是用开源的数据作为预训练也是完全足够的,例如开源的法律、医疗等各行业的数据。在基础模型对于各行各业有一定了解后,客户可以在私有数据自行微调,也能实现很好的效果。
要模型够快,对于硬件需求够低,这也是RWKV擅长的领域。
无论是to C还是to B,我们的主打都是现在GPT做不到,市面上只有我们能做的点。
36氪:这样一来,对数据安全有要求的企业,以及面向个人的端部署应用,相关的数据是无法反哺给基础大模型来做迭代优化的?
**彭博:**对于基础模型而言,加的数据越多越好,但是用开源的数据作为预训练也是完全足够的,例如开源的法律、医疗等各行业的数据。在基础模型对于各行各业有一定了解后,客户可以在私有数据自行微调,也能实现很好的效果。
RWKV也已加入HuggingFace transformers库:https://github.com/huggingface/transformers/pull/22797,HuggingFace很快将发博客官宣。