文章目录
- 1. 下载安装 Scala
- 1.1 下载 Scala 安装包
- 1.2 基础环境准备
- 1.3 安装 Scala
- 2. 下载安装 Spark
- 2.1 下载 Spark 安装包
- 2.2 安装 Spark
- 2.3 配置 Spark
- 2.4 创建配置文件 spark-env.sh
- 3. pyspark 启动
- 4. 建立/user/spark文件夹
1. 下载安装 Scala
1.1 下载 Scala 安装包
下载地址 https://www.scala-lang.org/download/ 。此指导书中使用的 Scala 版本为 scala-2.11.12.tgz ,实验环境中存放在 /hadoop-packages/ 目录下。(在平台做实验本部分不需要自己下载)
1.2 基础环境准备
配置 Scala 环境之前需要有 Hadoop 。实验环境中已经安装配置好了 Hadoop 伪分布式环境 。执行 HDFS 的启动命令:
start-all.sh
jps
5345 SecondaryNameNode
5093 DataNode
5958 NodeManager
6135 Jps
5628 ResourceManager
4924 NameNode
检查启动成功。通过命令 jps,能看到 NameNode,DataNode 和 SecondaryNameNode 都已经成功启动,表示 Hadoop 启动成功。
实操环节:
点击HDFS 的启动:
输入指令”start-all.sh”: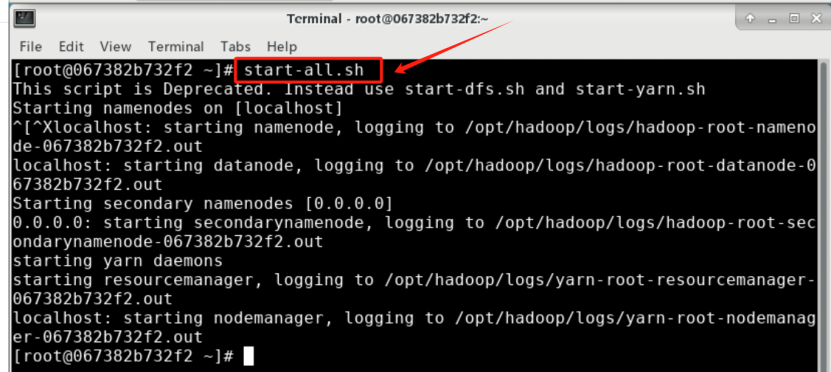
输入指令”jps”: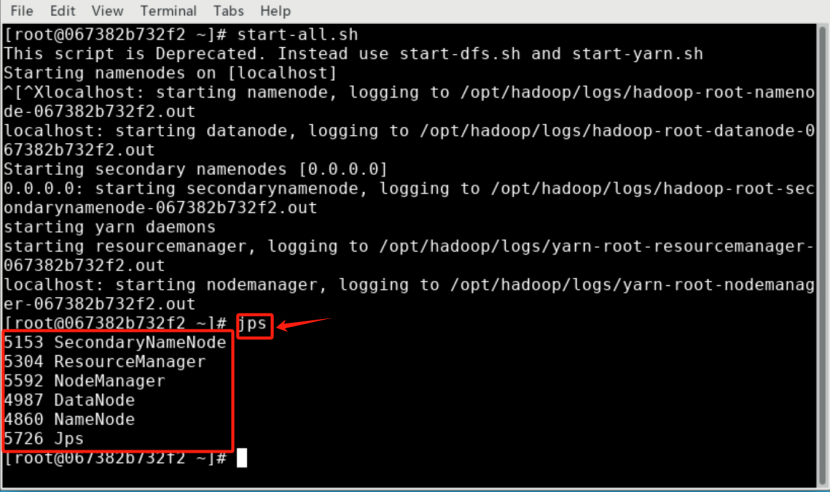
1.3 安装 Scala
步骤1: 解压安装包 scala-2.11.12.tgz 至路径 /opt,在 Linux 系统终端中执行以下命令:
sudo tar zxvf /hadoop-packages/scala-2.11.12.tgz -C /opt/
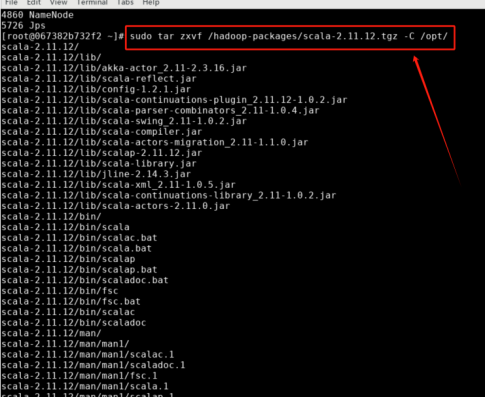
步骤2: 将解压的文件夹名 scala-2.11.12 改为 scala,以方便使用,命令如下:
cd /opt/

sudo mv scala-2.11.12/ scala/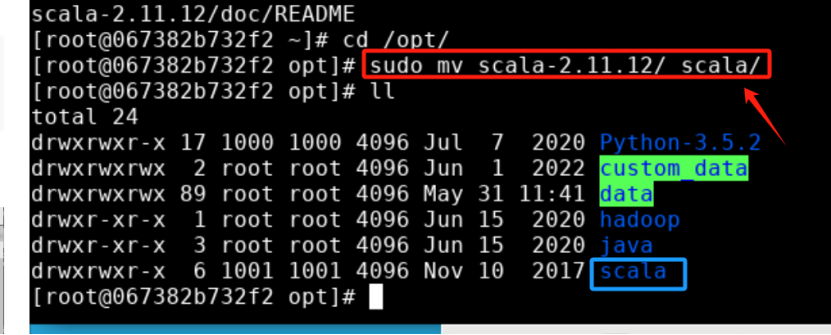
改名后的 /opt/ 目录可以输入“ll”查看,下图是示例。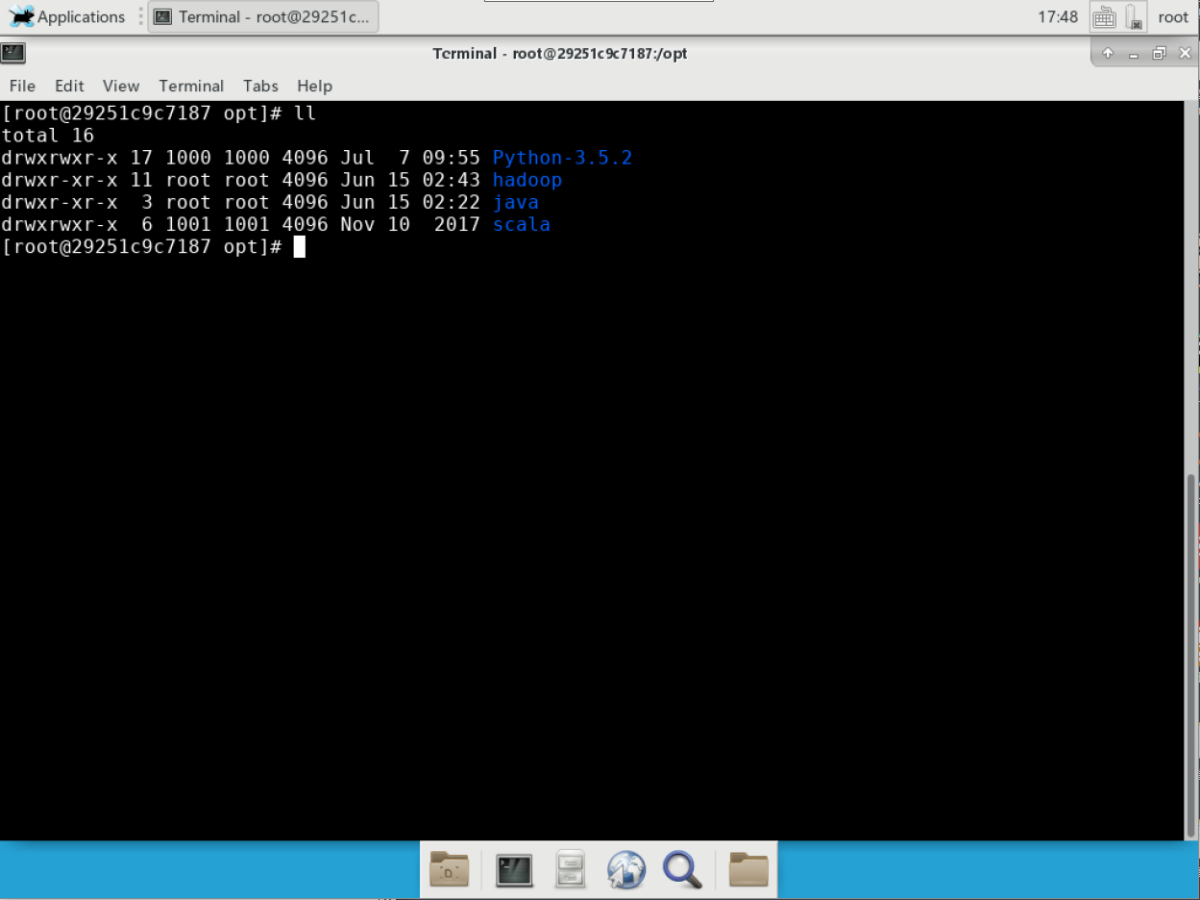
步骤3: 配置环境变量,将 scala 目录下的 bin 目录添加到 path 中,这样使用 Scala 时就无须到 /opt/scala 目录下,以方便 Scala 的使用。编辑 ~/.bashrc 文件,执行以下命令:
sudo vim ~/.bashrc

输入显示:
点击“i”按键进入编辑模式:
请在 ~/.bashrc 文件中添加如下内容。如图所示。
export SCALA_HOME=/opt/scalaexport PATH=$SCALA_HOME/bin:$PATH
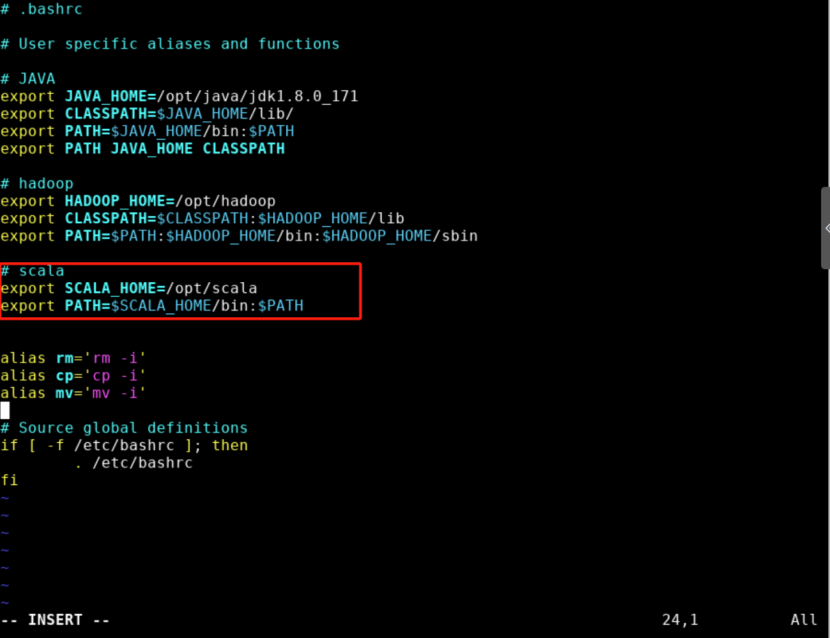
步骤4: 按 Esc 键退回一般模式,然后输入 :wq 命令并回车保存退出文件。
再执行以下命令使变量立即生效:
source ~/.bashrc

步骤5: 将 scala 目录下的所有文件的给予权限。执行以下命令:
cd /opt

sudo chmod -R 777 scala/*

步骤6: 验证 scala 版本,在终端中执行以下命令:
scala -version

输入后显示:
Scala code runner version 2.11.12 – Copyright 2002-2017, LAMP/EPFL
正确输出如上版本信息则安装无误。
2. 下载安装 Spark
2.1 下载 Spark 安装包
下载地址 http://spark.apache.org/downloads.html 。此指导书中使用的 Spark 版本为 spark-2.3.3-bin-hadoop2.7.tgz ,实验环境中存放在 /hadoop-packages/ 目录下。本实验平台不需要下载
2.2 安装 Spark
步骤1: 解压安装包 spark-2.3.3-bin-hadoop2.7.tgz 至路径 /opt ,在 Linux 系统终端中执行以下命令:
sudo tar zxvf /hadoop-packages/spark-2.3.3-bin-hadoop2.7.tgz -C /opt/

输入后显示:
步骤2: 将解压的文件夹名 spark-2.3.3-bin-hadoop2.7 改为 spark,以方便使用。
改名前的 /opt/ 目录如图所示。
执行以下命令:
sudo mv spark-2.3.3-bin-hadoop2.7/ spark/

改名后的 /opt/ 目录如图所示。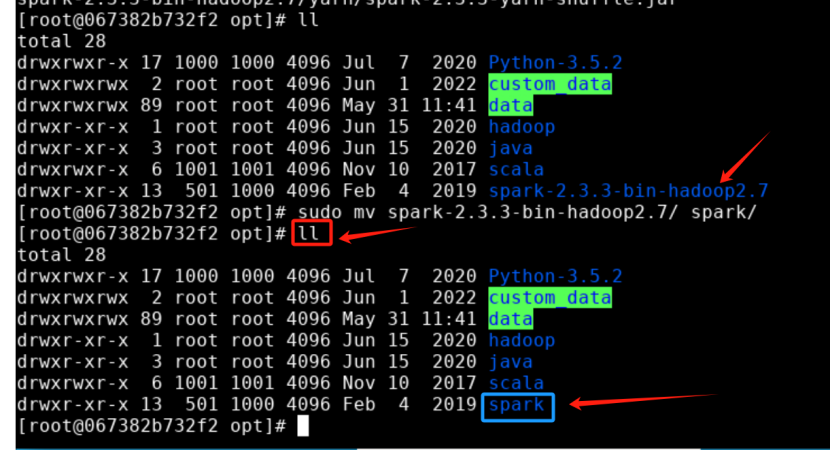
步骤3: 配置环境变量,将 spark 目录下的 bin 目录添加到 path 中。编辑 ~/.bashrc 文件,执行以下命令:
sudo vim ~/.bashrc

输入后显示:
点击”i”按键进入编辑模式:
请在 ~/.bashrc 文件中添加如下内容。如图所示。
export SPARK_HOME=/opt/sparkexport PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.7-src.zip:$PYTHONPATHexport PYSPARK_PYTHON=pythonexport PATH=$PATH:$SPARK_HOME/bin
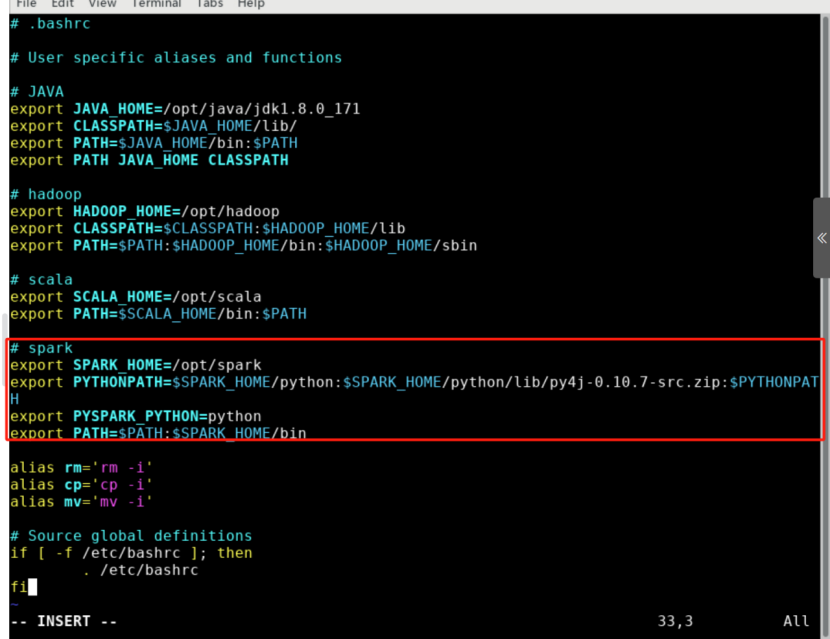
PYTHONPATH环境变量主要是为了在Python3中引入Pyspark库,对于不同版本的Spark , 其py4j-0.10.7-src.zip文件名是不同的,要进入相应目录 $SPARK_HOME/python/lib/ 下具体查看确定具体名称,再对PYTHONPATH环境变量的相应值加以修改。PYSPARK_PYTHON变量主要是设置Pyspark运行的Python版本。另外,如果环境中未安装Python3环境,需要手动执行命令yum -y install python3进行安装,后面才可正常进入到Pyspark终端。
步骤4: 按 Esc 键退回一般模式,然后输入 :wq 命令并回车保存退出文件。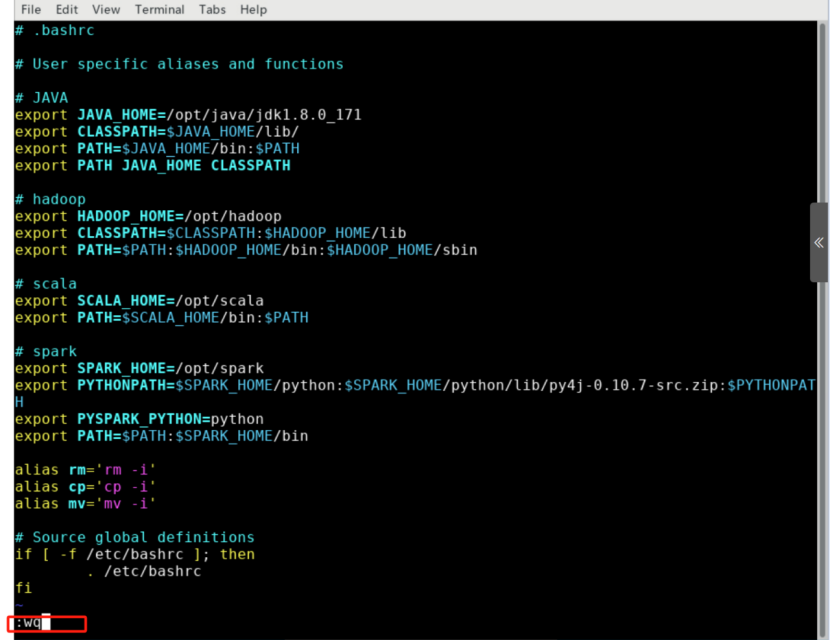
执行以下命令使变量立即生效:
source ~/.bashrc

步骤5: 将 spark 目录下的所有文件的给予权限。执行以下命令:
cd /opt
sudo chmod -R 777 spark/*

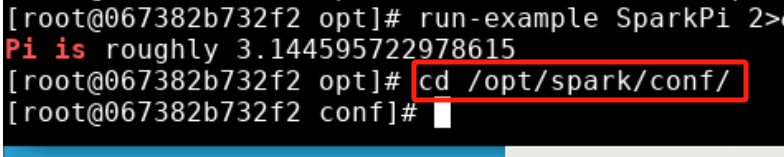
步骤6: 通过运行Spark自带的一个示例程序,验证Spark是否安装成功。在终端中执行以下命令:
run-example SparkPi 2>&1 |grep "Pi is"

输入后显示:Pi is roughly 3.1381756908784544
正确输出类似如上信息则安装无误。
2.3 配置 Spark
切换到 Spark 的 conf 目录下并查看。执行以下命令:
cd /opt/spark/conf/
ls

可发现 conf 目录下有配置文件模板 spark-env.sh.template 和 spark-defaults.conf.template 等。
2.4 创建配置文件 spark-env.sh
在 Spark 的 conf 目录下执行以下命令:
cp -r spark-env.sh.template spark-env.sh

vim spark-env.sh
输入后显示: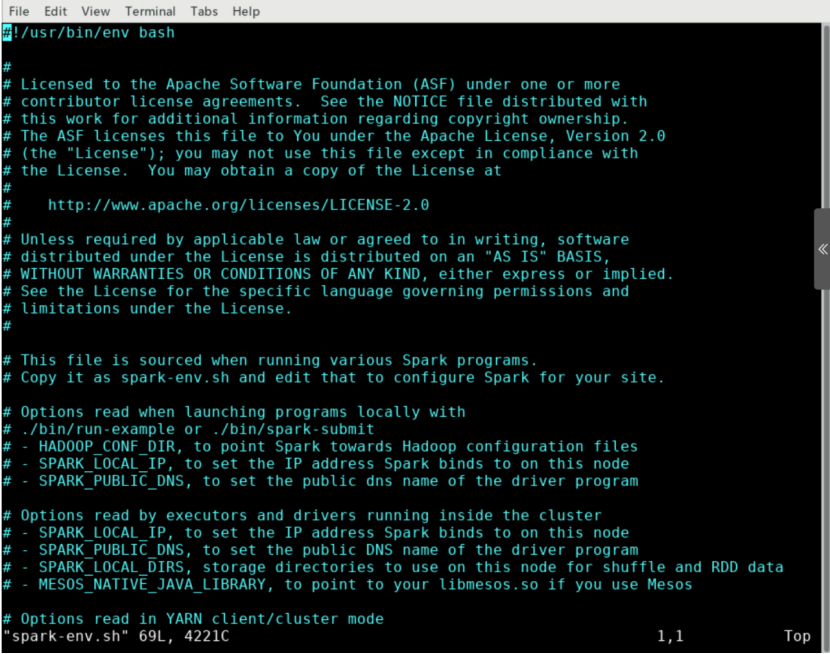
进入 Vim 编辑界面,按 i 键之后进入编辑状态,在文件首行中补充如下路径的信息:
export SPARK_DIST_CLASSPATH=$(/opt/hadoop/bin/hadoop classpath)
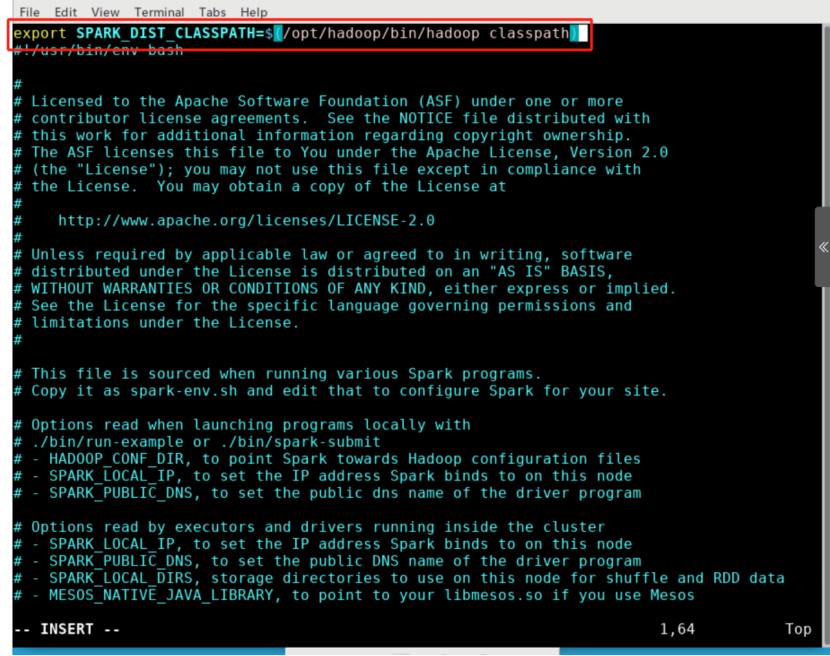
上面这条配置信息的作用是让Spark具备从Hadoop分布式文件系统HDFS读、写数据的能力;如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。配置完成的文件如图所示。
然后,按键盘上的 ESC 键退出 Vim 的编辑状态,再输入 :wq,保存并退出 Vim 编辑器。
3. pyspark 启动
由于设置了 PYSPARK_PYTHON 环境变量,可以在任意路径下直接执行以下命令启动 Pyspark:
pyspark
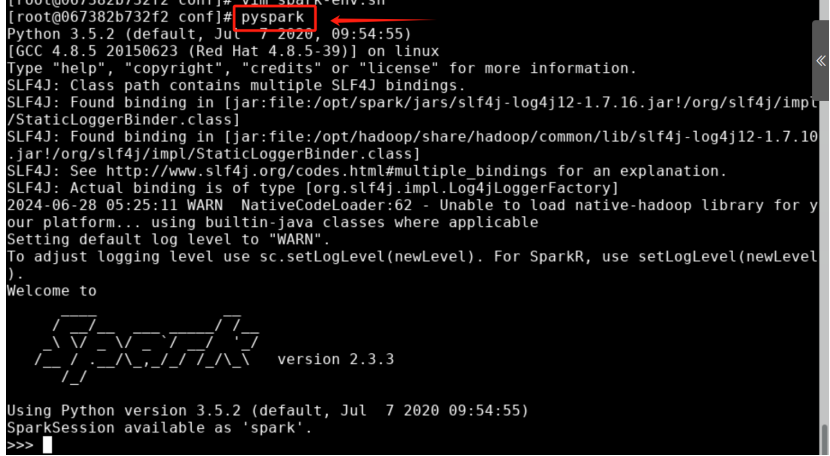
启动 Pyspark 后,就会进入到 >>>命令提示符状态,Pyspark的终端。 从上图可以看到 Spark 的版本号为2.3.3,Python版本为3.6.8。现在就可以在Pyspark的终端中输入Python代码进行调试了。如图所示。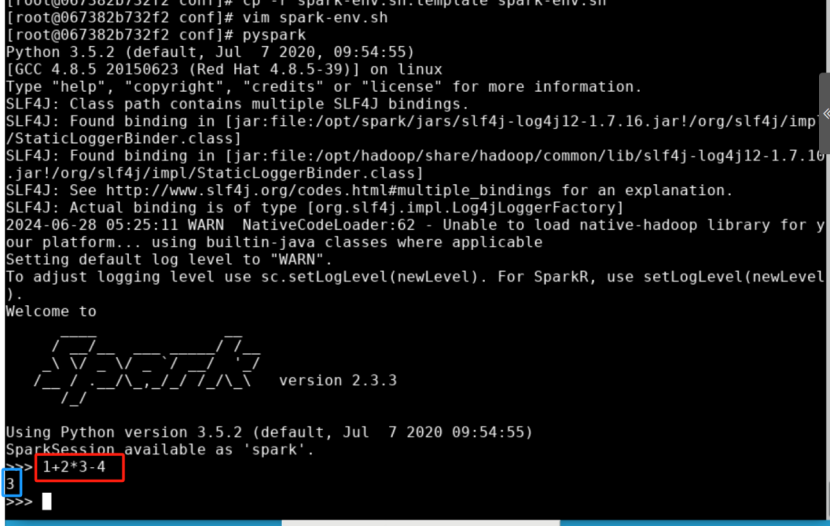
在Pyspark的终端中输入exit()可退出Pyspark终端。
4. 建立/user/spark文件夹
Hadoop中的许多组件在运行时会在HDFS上生成许多临时文件存储在/tmp文件夹中。
Spark应用历史服务在运行时会将一些数据存储在HDFS上的/user/spark/applicationHistory文件夹中。
使用hdfs dfs -mkdir命令创建文件夹/user/spark/applicationHistory以及hdfs dfs -chown命令将文件夹所有权移交给spark用户。
hdfs dfs -mkdir -p /user/spark/applicationHistory
hdfs dfs -chown -R spark /user/spark