引言
- 介绍本地知识库的概念和用途
在现代信息时代,我们面临着海量的数据和信息,如何有效地管理和利用这些信息成为一项重要的任务。本地知识库是一种基于本地存储的知识管理系统,旨在帮助用户收集、组织和检索大量的知识和信息。它允许用户在本地环境中构建和管理自己的知识资源,以便更高效地进行信息处理和决策。
本地知识库通常采用数据库、索引和搜索技术,以构建一个结构化的存储系统,使用户可以快速地访问和查询所需的信息。
- 引出使用GPT-3.5、LangChain和FAISS构建本地知识库的动机
当面临一个知识类问题时,我们往往需要利用自己获取到的信息加以总结,对海量信息中包含的要点进行快速地查询和了解,而现在出现的GPT-3.5技术则能够使得用户向语言模型提问并得到一个回答。LangChain则是对大语言模型技术所用到的一些功能进行了统一的封装,这使得我们可以利用本地的知识资源,以获得我们需要的信息,FAISS则是一个可以存储这种类型数据的向量数据库。
ChatGPT
ChatGPT 是由 OpenAI 开发的一种高级语言模型,可以根据给定的提示生成类似人类语言的文本,从而实现对话、文本摘要和问答等多种功能。
出于演示的目的,我们将专注于OpenAI的"gpt-3.5-turbo-16k"模型,因为它目前价格合适,速度较快,回答比较准确。
如果想深入了解chatgpt相关信息,请参考下面链接:
https://platform.openai.com/docs/api-reference
LangChain
LangChain 是一个库(以 Python、JavaScript 或 TypeScript 提供),提供了一组用于处理语言模型、文本嵌入和文本处理任务的工具和实用程序。 它通过组合语言模型、向量存储和文档加载器等各种组件来简化创建聊天机器人、处理文档检索和执行问答操作等任务。
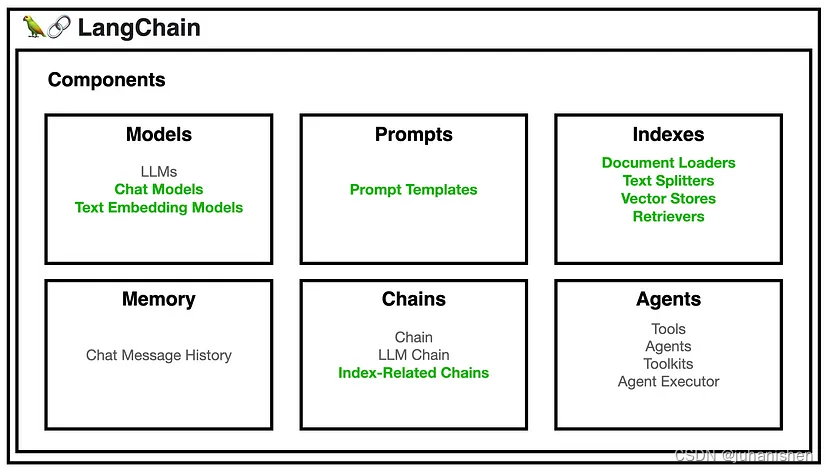
我们将专注于创建一个问答聊天机器人,其中包含上面图中所展示的绿色的部分。
如果想深入了解LangChain相关信息,请参考下面链接:
https://python.langchain.com/docs/get_started
FAISS
FAISS(Facebook AI相似性搜索)是Facebook AI Research开发的开源库。 它旨在有效地搜索大量高维数据中的相似项(向量)。 FAISS 提供了索引和搜索向量的方法,使您可以更轻松、更快速地找到数据集中最相似的项目。现在的一个简单理解是,FAISS并不能直接存储数据,它只是一个索引和搜索向量的工具,这个工具可以根据emdebbing的后生成的向量,从文本中匹配跟问题相关的内容出来。FAISS的存储数据只是把向量化后的一系列数据存在本地文件,之后需要的时候再从本地文件进行加载进去。所以我们设计的时候应该得分成两步进行设计,一部分是生成本地文件的代码,一部分是加载本地文件的代码,当然加载本地文件就是直接写在业务代码里面,不需要单独拆出来了。
它在以下任务中特别有用:
- 推荐系统
- 信息检索
- 聚类——找到相似的项目很重要
如果您有一个基本的聊天机器人并且满足以下条件,那么 FAISS 是一个可靠的矢量存储选择:
- 查询可由CPU支持的有限数据集
- 寻求免费开源的矢量存储解决方案
- 不打算在您的架构中引入其他服务器或云 API
如果想深入了解FAISS相关信息,请参考下面链接:
https://faiss.ai/
Document loaders
Document loaders是langchain中的一个组件,它的功能是从文件中读取数据,比如PDF,csv,url,txt等。经过loaders加载后的数据Document主要由两部分组成,即page_content和metadata。metadata中存储了文件名,第几页等基础信息,page_content中存储了该页的内容。
其基础用法如下:
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(r"loRA _refer.pdf")
print(loader.load())
代码解释:
- PyPDFLoader是document_loaders 中加载pdf的组件,这段代码将pdf加载为一个loader对象,并打印了其中内容,可以看出打印为一个列表,这个列表中存放了一个Document对象。
- 除了PyPDFLoader,langchain还提供了
CSVLoader,HTMLLoader,JSONLoader,MarkdownLoader,File Directory,ExcelLoader,Microsoft Word,Microsoft PowerPoint,GitHub,EPub,Images,WebBaseLoader,URL等多种加载器,具体可查看其document_loaders文档:
https://python.langchain.com/docs/modules/data_connection/document_loaders/
File Directory loader
File Directory loader可以从文件夹中同时加载多个文件,其基本用法如下:
from langchain.document_loaders import DirectoryLoader,PyPDFLoader loader_pdf=DirectoryLoader('./docs/',glob="**/*.pdf",loader_cls=PyPDFLoader)documents = loader_pdf.load()
代码解释:
from langchain.document_loaders import DirectoryLoader: 这行代码从langchain.document_loaders模块中导入DirectoryLoader类。DirectoryLoader类是用于从目录加载文档的工具。loader_pdf = DirectoryLoader('./docs/', glob="**/*.pdf", loader_cls= PyPDFLoader): 这行代码创建一个名为loader_pdf的对象,它是DirectoryLoader类的一个实例。构造函数的参数如下所示:'./docs/': 这是要加载的目录路径,即包含PDF文档的目录。在这个例子中,路径为'./docs/',表示当前目录下的docs文件夹。glob="**/*.pdf": 这是一个用于匹配文件的通配符模式。在这里,**/*.pdf表示匹配任意目录下的任意文件名以.pdf结尾的文件。loader_cls=PyPDFLoader: 这是一个指定要使用的加载器类的参数。在这个例子中,指定的加载器类是PyPDFLoader。最佳实践为,当明确需要加载文件类型时,应该明确指定这里的loader_cls,即加载器是什么。
documents = loader_pdf.load(): 这行代码使用之前创建的loader_pdf对象调用load()方法来加载文档。load()方法将根据之前设置的目录路径、文件匹配模式和加载器类来加载满足条件的PDF文档,并将加载的文档存储在名为documents的变量中。
Document transformers
因为在现在的技术条件下,chatgpt或其他的大语言模型均有受到文本长度的限制,所以对于一个大型文件或者很多个大型文件时,若将全部文本一次性发送给chatgpt,则模型往往会报错token超出。在这种情况下,我们则会先将长文档拆分为可以放入模型上下文窗口的较小块。在langchain中内置了很多函数,使我们可以直接进行这个操作。、
from langchain.document_loaders import DirectoryLoader,PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter loader_pdf=DirectoryLoader('./docs/',glob="**/*.pdf",loader_cls=PyPDFLoader)
documents = loader_pdf.load()
text_splitter=CharacterTextSplitter(chunk_size=1000,chunk_overlap=0)
docs = text_splitter.split_documents(documents)
代码解释:
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0): 这行代码创建一个名为text_splitter的对象,它是CharacterTextSplitter类的一个实例。构造函数的参数如下所示:chunk_size=1000: 这是指定拆分文本片段的大小的参数。在这里,设置为1000,表示每个片段的字符数为1000。chunk_overlap=0: 这是指定片段之间重叠部分的大小的参数。在这里,设置为0,表示片段之间没有重叠。设置重叠部分有可能会在某些长句子面临被切开情况会很有用,或者上下两句联系较为紧密时起作用。可以根据实际情况来写入,默认可以设置为0.
docs = text_splitter.split_documents(documents): 这行代码使用之前创建的text_splitter对象调用split_documents()方法来将加载的文档拆分成较小的文本片段。拆分后的文本片段将存储在名为docs的变量中。split_documents()方法的参数documents是之前加载的文档。
Text embedding models
embedding (嵌入)这个动作的目的是创建一段文本的矢量表示形式。矢量是一个数学领域的概念,若对这部分不熟悉请学习线性代数这门课程。
矢量在数学上一般以一个有序数组来表示,相关概念见下文:
https://zhuanlan.zhihu.com/p/339974158
文本向量化之后,就可以执行诸如语义搜索之类的操作,在其中我们可以寻找向量空间中最相似的文本片段。
当我们需要查找向量空间的最相似的文本片段时,就必须引入另一个工具,即向量数据库。
Vector stores
存储和搜索非结构化数据的最常见方法之一是将数据embedding并存储生成的embedding向量。然后在查询时检索与查询内容"最相似"的embedding向量。Vector stores(矢量存储)负责存储embedding数据并为您执行矢量搜索。(请注意,在数学中矢量与向量同义)。
from langchain.document_loaders import DirectoryLoader,PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter loader_pdf=DirectoryLoader('./docs/',glob="**/*.pdf",loader_cls=PyPDFLoader)
documents = loader_pdf.load()
text_splitter=CharacterTextSplitter(chunk_size=1000,chunk_overlap=0)
docs = text_splitter.split_documents(documents)
faissIndex = FAISS.from_documents(docs, OpenAIEmbeddings()) faissIndex.save_local("faiss_midjourney_docs")
- 从文档块创建 FAISS 索引,使用
OpenAIEmbeddings()将文本块转换为矢量表示形式,并生成一个faiss对象. - 将创建的 FAISS 索引保存到名为"faiss_midjourney_docs"的本地文件中。然后,该索引可以重新用于将来的高效相似性搜索任务,而不需要重新从源文件中生成。
这个"faiss_midjourney_docs"的本地文件实际上是一个文件夹,其目录结构如下图:

从本地加载 FAISS 索引并加入到langchain的问答中
import os, dotenv
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain import PromptTemplate dotenv.load_dotenv() chatbot = RetrievalQA.from_chain_type( llm=ChatOpenAI( openai_api_key=os.getenv("OPENAI_API_KEY"), temperature=0, model_name="gpt-3.5-turbo", max_tokens=50 ),chain_type="stuff", retriever=FAISS.load_local("faiss_midjourney_docs", OpenAIEmbeddings()) .as_retriever(search_type="similarity", search_kwargs={"k":1}) ) template = """
respond as succinctly as possible. {query}?
""" prompt = PromptTemplate( input_variables=["query"], template=template,
) print(chatbot.run( prompt.format(query="what is --v")
))
- 导入必要的库和模块,包括
os、、OpenAIEmbeddings、FAISSdotenvRetrievalQA、ChatOpenAI和PromptTemplate。 - 使用 从
dotenv.env 文件加载环境变量(即 OPENAI_API_KEY)。 - 使用 GPT-3.5-turbo 模型初始化
ChatOpenAI实例,温度为 0,最多 50 个响应令牌和 OpenAI API 密钥。默认温度为 0.7 — 将值设置为 0 将降低 ChatGPT 完成的随机性。 - 使用 加载
OpenAIEmbeddings预构建的 FAISS 索引“faiss_midjourney_docs”。 - 设置包含
RetrievalQAChatOpenAI 实例、FAISS 索引以及搜索类型和参数的链。强烈建议设置search_type和search_kwargs- 不这样做将具有成本效益,因为向量存储中的所有块都将发送到LLM。还值得注意的是,chain_type是“东西”它试图将所有块填充到提示中作为您的LLM(即ChatGPT)的上下文。 - 定义一个包含变量“query”的提示模板,并要求提供简洁的答案。
- 使用定义的模板创建
PromptTemplate实例。 - 使用与中途相关的查询来设置提示的格式。
- 使用格式化的提示问题执行聊天机器人。
- 打印聊天机器人的答案。