- 1. 测试环境
- 2. 谷歌云平台注册
- 3. gtts 使用
- 3.1. 基本介绍
- 3.2. 准备工作
- 3.3. 本地环境变量设置
- 3.4. 安装python包
- 4. 测试
最近工作中要将文本转换成多国语音,试了下gtts,效果不错,来记录下
1. 测试环境
| 项目 | 版本 |
|---|---|
| 操作系统 | Ubuntu20.04 |
| python | 3.8 |
| Google Cloud Platform | 试用版 |
注意:
1、由于需要试用谷歌云平台,所以需要能够访问谷歌的方法,在此不在赘述
2、为了申请谷歌云平台账号,需要拥有VISA信用卡或者PayPal账号,用于注册时的验证
2. 谷歌云平台注册
点击谷歌云平台,转到谷歌云平台,申请账号,注册流程按照提示来就可以,但是必须要有前文提到的东西,注册成功后,会有90天的免费体验时间。
3. gtts 使用
3.1. 基本介绍
gtts(google text to speech)使用由 Google 的 AI 技术提供支持的 API 将文字转换为自然而逼真的语音。可以在这个页面看到一些官方的使用文档,本文也在该文档指导下进行。
3.2. 准备工作
从基本介绍可以看出,gtts是通过API调用的方式实现的,因此我们必须先启用谷歌云平台中的gtts api功能。为了能够成功开启该功能,具体操作步骤如下:
-
登录到云控制台,新建一个项目,这里设置名字为txt2wav
-
确认待使用项目已启用结算选项。这个是谷歌收费的,当前我们是免费使用期间,正常跳转到结算页后,是能找到我的结算账号的,如果出现没有结算账号的情况,按照这里的说明进行操作。
-
开启gtts API。在产品搜索框内输入speech,进行搜索,并打开 Cloud Text-to-Speech API 页面,之后选择启用 API。注意该操作是启用当前激活项目的 gtts API(Google Cloud Platform后面显示的即为当前激活项目)。

-
创建服务账号。必须通过服务账号才能访问 API,相当于认证,创建一个服务账号,可选项都可不填。注意该操作是在当前激活项目中创建服务账号(Google Cloud Platform后面显示的即为当前激活项目)。

-
创建完成后,点击服务账号的电子邮件信息,会打开配置页面,添加新密钥,正常添加即可,最后会选择密钥格式,这里选择json格式并进行下载。
3.3. 本地环境变量设置
- 设置用于身份验证的本地环境变量。本地每次调用 API 时,都会使用该变量指向的密钥进行身份认证,具体命令如下,将该命令添加到~/.bashrc中,并将KEYPATH换成你的密钥存储位置,具体到文件本身如/home/rsa/aaa.json
export GOOGLE_APPLICATION_CREDENTIALS="${KEY_PATH}"
3.4. 安装python包
本次测试使用的是系统自带的python3.8,也可以使用虚拟环境,使用以下指令安装gtts的python包。
pip3 install --upgrade google-cloud-texttospeech
4. 测试
注意:测试过程中,要保证能够正常访问谷歌。
-
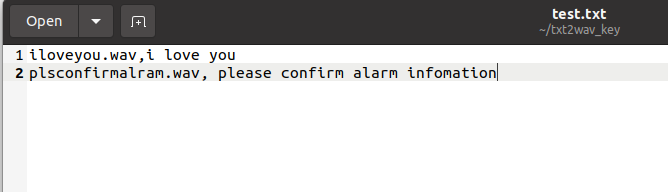
本次测试样例的功能为:读取txt内文本信息,转换为语音后,保存。文本内格式如下,每一行由保存文件名称和待转换文字组成,如第一行,将会将i love you转换为语音,并保存为iloveyou.wav
-
测试源码如下,部分代码进行了注释,gtts转换后的音频够实现指定采样率、通道、格式等信息,具体API使用手册参见这里
#!/bin/env pythonfrom google.cloud import texttospeech import waveclient = texttospeech.TextToSpeechClient()voice = texttospeech.VoiceSelectionParams(```转换的语言码 en-US 代表美国,支持的语言查看 https://cloud.google.com/text-to-speech/docs/voices```language_code="en-US", ```语音播报性别选择```ssml_gender=texttospeech.SsmlVoiceGender.FEMALE )audio_config = texttospeech.AudioConfig(```输出语音文件的编码方式,可以选择mp3、wav(LINEAR16)等```audio_encoding=texttospeech.AudioEncoding.LINEAR16,```输出语音文件的采样率```sample_rate_hertz = 8000 )index = 0 filenames = [] with open("test.txt", "r") as f:for line in f.readlines():line = line.strip('\n')filename, text = line.split(",", 1)filename = filename.strip(" ")filenames.append(filename)text = text.strip(" ")synthesis_input = texttospeech.SynthesisInput(text=text)response = client.synthesize_speech(input=synthesis_input, voice=voice, audio_config=audio_config)with open(filename, "wb") as out:out.write(response.audio_content)out.close()f.close()