一、为什么需要DPU?
在信息爆炸的时代,数据处理单元(DPU)作为新兴的数据中心基础设施核心,正逐步崭露头角,成为提升数据处理效率、优化成本结构的关键角色。
传统的数据中心架构主要以CPU为中心,这使得数据中心的计算和存储任务主要依赖于CPU的处理能力。但是,随着数据量的不断增长,这种架构逐渐显现出一些问题和瓶颈,如处理速度慢、效率低下等。
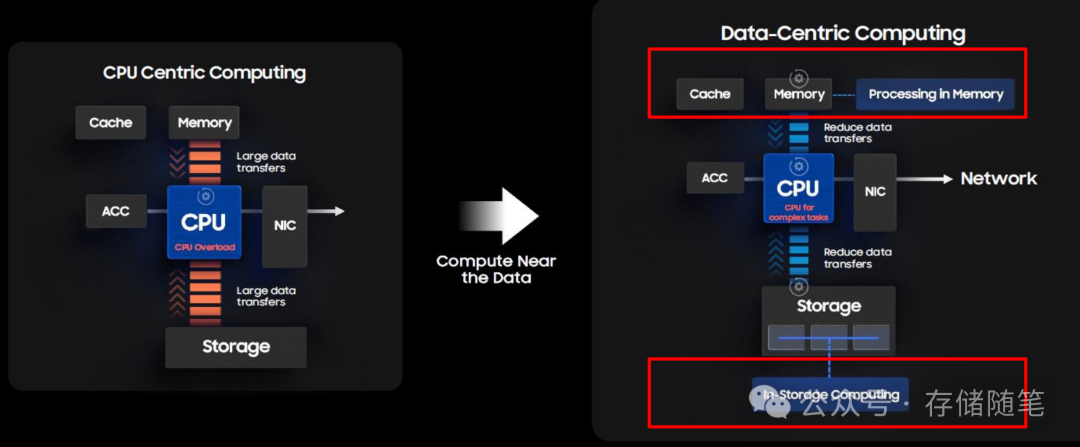
目前已经从传统CPU为中心的架构,开始向以数据为中心的新型架构转变。新的架构处理需求,就涌现了多种卸载传统CPU计算能力的产品,比如DPU、CSD等。
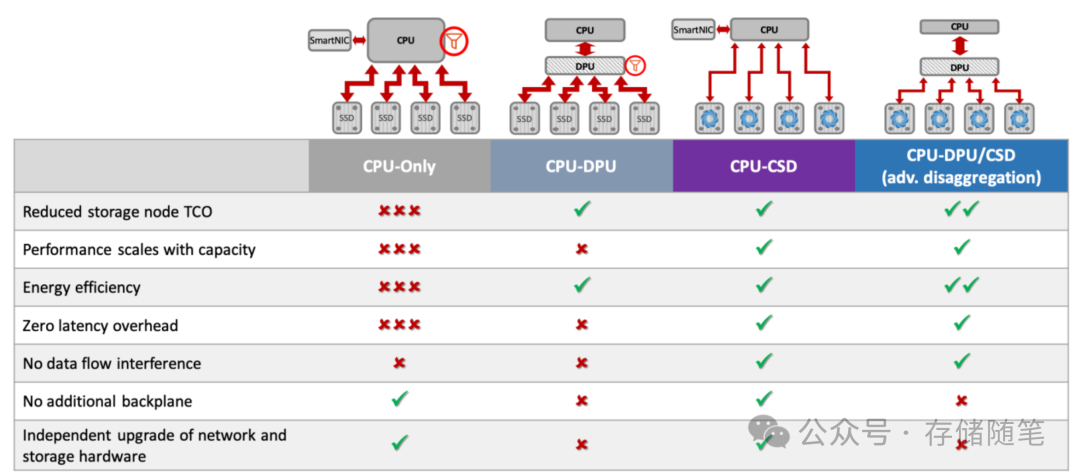
特别是AI场景,随着AI模型的复杂度增加以及数据量爆炸性增长,GPU服务器在执行训练和推理任务时,不仅面临计算密集型问题,还必须处理大量的数据移动、网络通信、存储I/O以及安全防护等非计算密集型任务。这些问题往往会成为性能瓶颈,消耗宝贵的CPU资源,进而影响整体系统的效率和扩展性。

主要面临挑战与难题:
-
网络性能瓶颈:AI训练通常需要多个GPU节点间的高速、低延迟数据交换。传统架构中,这部分工作往往依赖于CPU处理,导致CPU负载过高,且网络性能受限。
-
存储I/O问题:AI训练涉及海量数据读取,若完全依赖CPU处理存储访问请求,会导致延迟增加,无法充分发挥GPU的计算效能。
-
资源隔离与安全性:在多租户环境中,如何在不牺牲性能的前提下,实现GPU资源的安全隔离和访问控制是一个挑战。
-
总体效率低下:由于CPU需同时处理计算、网络、存储和安全等多种任务,导致其难以专注在计算密集型AI训练上,整体系统效率不高。
为了应对数据中心和GPU服务器在处理AI工作负载时所面临的挑战和难题,DPU(数据处理单元,Data Processing Unit)进入了大家的视野。
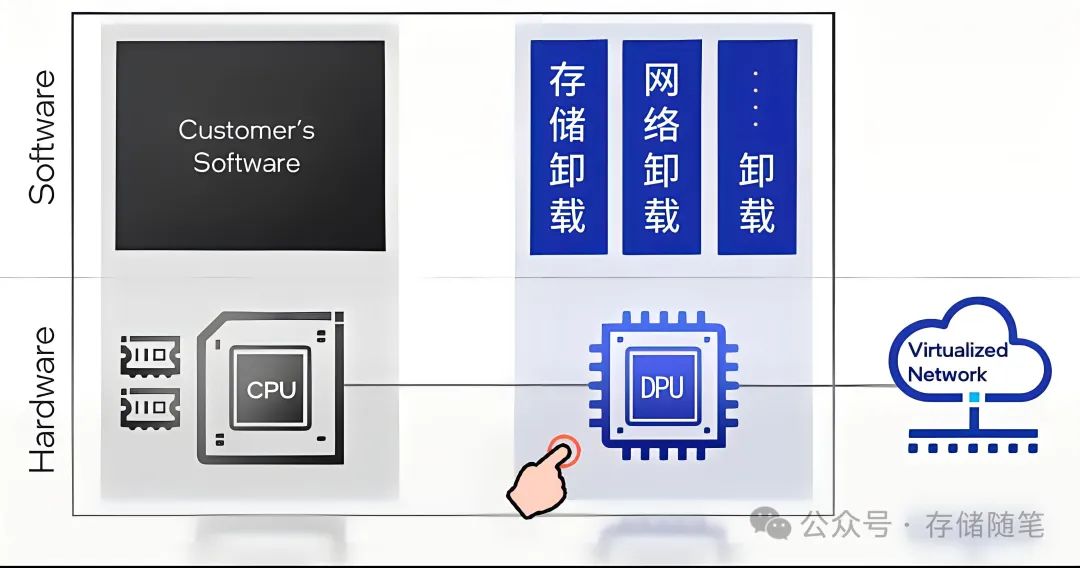
DPU的出现为以数据为中心的计算架构提供了创新思路。它主要分担数据中心其他处理器的工作,如网络卸载、计算卸载或数据服务卸载等,以节省成本,尤其是降低进入数据中心的资本成本和降低数据中心的运营成本。通过将基础设施服务卸载和隔离出来,DPU通过卸载CPU和GPU的工作负载,可以使CPU和GPU专注于处理核心的计算任务,提高整体性能。此外,DPU还通过硬件加速技术,以更快的速度处理这些服务,从而大大提高了数据中心的效率。
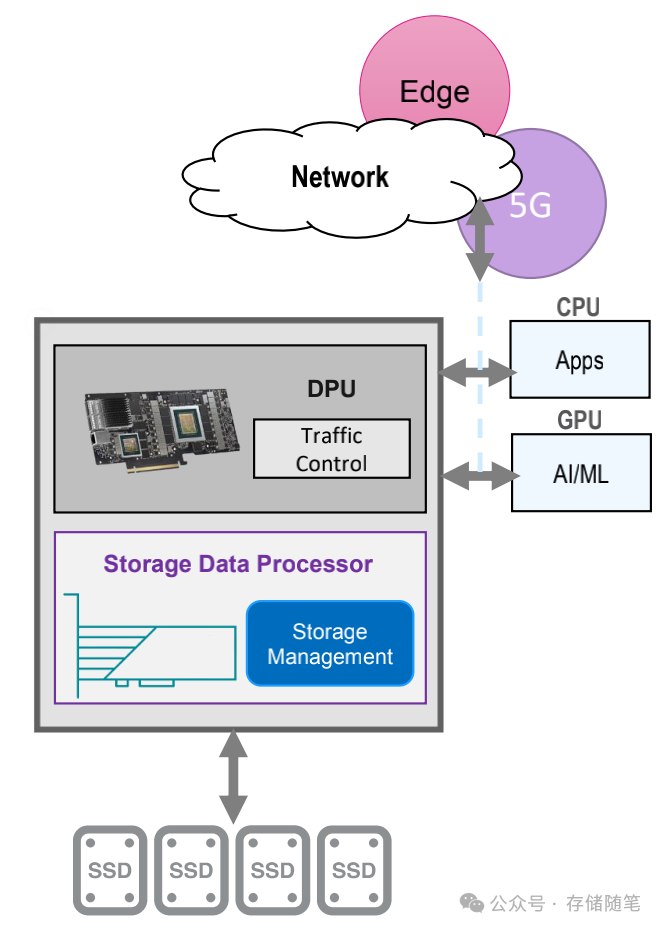
DPU通常包含外部网络接口,通过NVMeoF/TCP和RoCE协议连接数据存储与计算引擎;DPU内嵌强大的网络处理引擎和硬件加速器,能够直接处理网络数据包,支持高速网络协议如RoCE v2(RDMA over Converged Ethernet),实现零拷贝数据传输。这样一来,网络流量不再经由CPU处理,而是由DPU接管,大幅降低网络延迟,提升数据交换效率,使得GPU可以更快获取所需数据。
DPU还能进行存储I/O的硬件加速和卸载,支持NVMe-oF(NVMe over Fabrics)等协议,实现存储操作的直接硬件执行。通过DPU,存储访问操作得以绕过CPU,显著降低延迟,提升存储I/O性能,从而加快AI训练和推理的速度。
DPU能够提供硬件级别的安全功能,如IPSec/TLS加密加速、防火墙、深度包检测等,实现数据在传输过程中的安全防护。同时,通过DPU的虚拟化能力,可以对GPU资源进行细粒度的隔离与控制,确保不同租户间的安全性。
DPU的核心优势与应用场景:
-
TCO(总拥有成本)优化:DPU通过承担网络卸载、计算卸载和数据服务卸载等功能,显著降低了数据中心的运营成本。这包括减少硬件开支、降低能源消耗及简化管理流程,从而实现更高的每瓦性能和每美元投资回报。
-
性能与效率的双重提升:DPU专为高效数据处理而设计,其内部架构包括高性能核心、硬件加速器和优化的软件,能够在处理大量数据流时展现极高的效率。它能够处理如数据压缩、加密、去重等任务,同时确保数据的安全性和完整性。
-
存储场景的革新:
-
-
QLC SSD优化:DPU能有效管理QLC SSD的读写效率问题,通过智能数据放置策略减少写入放大,延长SSD寿命,同时优化读取性能,确保高密度存储设备的高效利用。(深度剖析:大容量QLC SSD为何遭疯抢?)
-
ZNS SSD应用:ZNS SSD结合DPU的智能管理,可以更精细地控制数据布局,避免不必要的数据迁移,减少写入操作的开销,提升整体存储效率。(为什么QLC NAND才是ZNS SSD最大的赢家?)
-
计算存储融合(CSD):DPU在CSD中的应用促进了数据处理与存储的紧密集成,使得数据处理更接近数据源,降低了数据传输延迟,特别适用于边缘计算和实时分析场景。(深度解读NVMe计算存储协议)
-
二、DPU在数据中心的融合与协同
DPU并非孤立存在,而是与CPU和GPU形成互补关系,共同支撑数据中心的高效运行。CPU负责通用计算任务,GPU处理并行计算密集型应用,而DPU则专注于数据处理相关的低延迟需求。三者协同,形成了一种高效的数据处理流水线,使得数据中心能够更灵活地应对多样化的数据处理需求。
在运行人工智能(AI)和高性能计算(HPC)负载的数据中心中,数据处理单元(DPU)已经成为不可或缺的角色。通用CPU在物理层面遭遇瓶颈,仅能支持单一线程的用户应用程序。GPU虽然擅长并行处理,但并非为高效管理多任务及数据而设计。DPUs的出现开创了一个加速处理的新纪元,能够高效运行异构数据密集型任务,同时减轻GPU和CPU的负担。
凭借专为低功耗设计的核心、协处理器以及高速接口,DPUs优化了数据处理流程,并确保与其他数据中心组件的无缝连接。面对任何工作负载或架构,评估DPUs、CPUs和GPUs时,应综合考虑这些因素的总和,以及它们对总体业务决策树的影响。
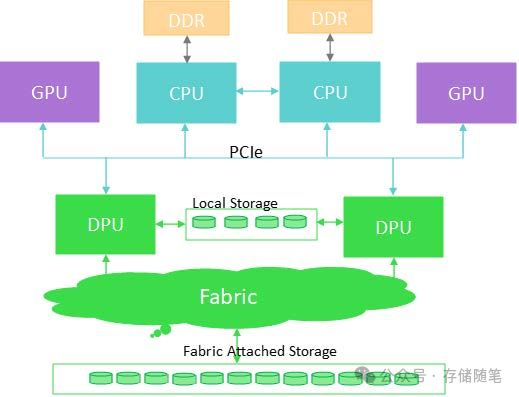
理想的数据中心应让三种处理器(DPU、CPU和GPU)协同作业,各司其职,不可替代。当前许多数据中心仅依赖两种处理器承担所有工作。引入第三种处理器DPU,则可将CPU和GPU上不匹配的任务卸载,以更高效的方式执行。DPU可轻松融入现有架构,与另两种处理器并肩作战,接管所有数据管理工作——保护、安全及优化。
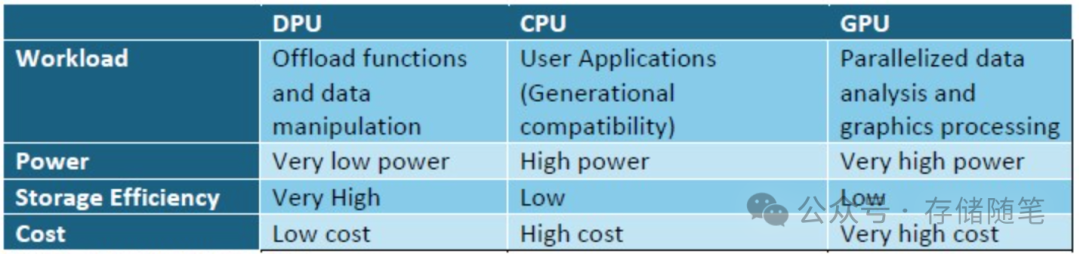
CPU - 劳模耕牛
CPU这个老将已存在数十年,为了向前兼容及满足广泛的应用需求,它必须保持通用性。CPU如同日复一日勤恳耕作的耕牛,支撑着成千上万应用程序的运行。它虽强大且普及,但因其通用性,在纯粹的数据处理任务上效率并不高。过去几年间,CPU作为唯一的计算主力,逐渐变得昂贵且能耗巨大。

GPU - 赛场良驹
相比之下,GPU则是专为视频和图形数据设计的处理器,它在图形处理上表现出色,但价格更高,能耗惊人。GPU好比赛马场上的纯血赛马,专攻一域,却在数据管理能力上略显不足,且因其编程复杂,历来难以适应图形处理之外的任务。尽管这一局限正逐渐被打破,GPU天生并不适合处理日常存储服务。

DPU - 快递小马
DPU则像快递小马,体型精悍,速度快,耐力强,能够高效地在多变的环境中完成任务。作为一种低功耗、低成本、专门设计的数据处理单元,DPU在数据处理效率上远超CPU和GPU。它不做CPU的田间重活,也不追求GPU的速度竞赛,但它在自己的领域内表现卓越。

CPU、DPU与GPU在数据中心各有千秋,应被视为互补的伙伴,根据各自优势分配任务。CPU负责运行用户应用、虚拟机和容器;GPU擅长处理高度并行化的计算;DPU则作为纽带,承担网络、安全和存储功能,包括数据操作,这些都是CPU和GPU不太擅长的。
DPU应运而生,一方面是为了满足数据分析领域对轻量级本地数据处理器的需求,另一方面则是为了提升网卡(NIC)的智能性,赋予其编程特性。随着DPU在存储卸载领域的角色扩大,精心设计的DPU在数据中心能以更低的功耗和成本更高效地处理数据,对于存储呈指数级增长的大规模数据中心而言,这意味着时间和成本的显著节省。随着技术的不断成熟和应用的深入,DPU将在未来数据中心的发展中扮演更加关键的角色。
在AI GPU场景下,DPU通过将非计算密集型任务从CPU中剥离出来,释放CPU资源专注于AI计算任务,从而优化整个系统的资源分配和利用效率。同时,DPU还可以提供智能调度和管理功能,实现硬件资源的动态调整,以适应不同阶段AI训练和推理对资源的需求变化。
从架构演进的角度看,DPU是对现有数据中心基础设施的一种革新。随着AI的发展,为了实现更高性能、更低延迟和更强安全性的需求,DPU应运而生,它填补了CPU和GPU在处理非计算密集型任务上的不足,形成了CPU-DPU-GPU三者协同工作的新型数据中心架构。这样,DPU不仅解决了当前AI GPU场景下的诸多挑战,也为未来更大规模、更复杂场景下的AI计算打下了坚实的基础。
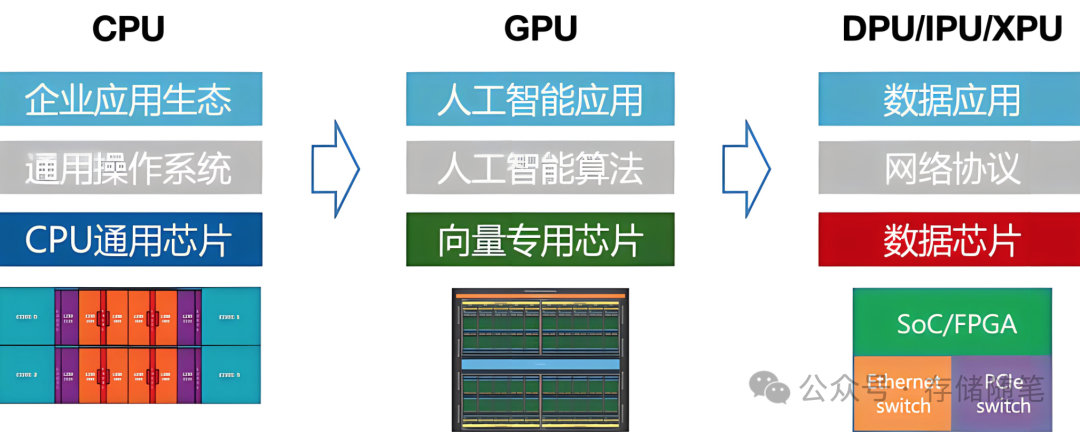
三、分布式存储应用场景
"后摩尔时代"的存储新挑战,标志着信息技术领域进入了一个全新的发展阶段。随着工业互联网、人工智能、大数据、5G等前沿技术的迅速推进,数据中心的存储需求呈现前所未有的爆炸性增长。这一趋势不仅要求更高的I/O带宽,还对存储性能提出了更为严格的挑战,促使数据中心存储网络的延迟标准从毫秒级别向微秒甚至纳秒级别迈进。
随着数据处理需求的激增,主机侧网络处理压力剧增,延迟要求的提高意味着留给存储软件处理单个数据包的时间大大缩短。为了解决这一难题,DPU(数据处理单元)作为一种新型可编程处理器,应运而生。DPU通过算力卸载、数据加速、NVMe-over-Fabrics(NVMe-oF)支持、无损网络传输和安全能力等关键功能,有效释放了CPU资源,提升了存储协议处理的效率。DPU能够处理如存储协议封装与解封装、数据去重与压缩等原本占用大量CPU资源的任务,从而让CPU能够专注于运行更多的应用业务,提高整体系统性能。
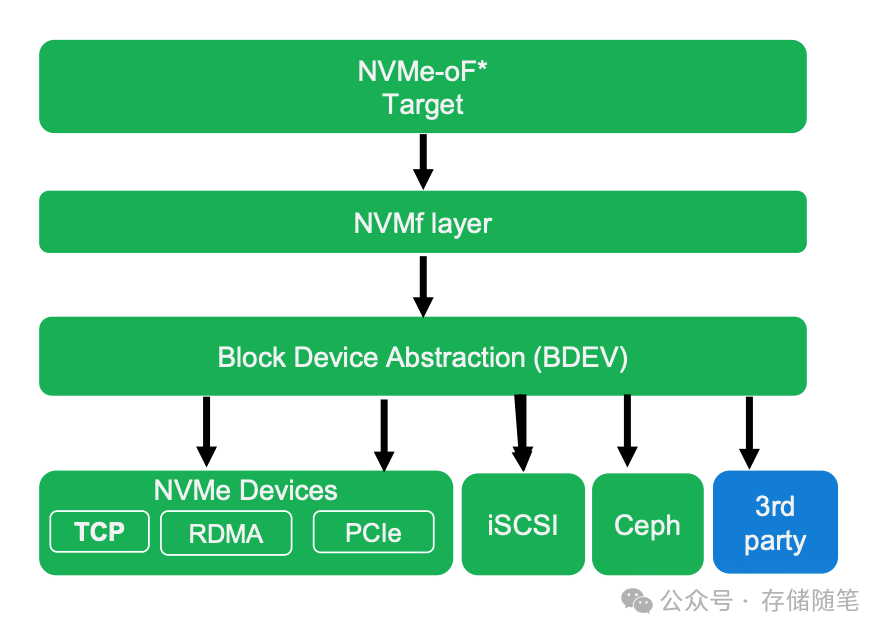
DPU的NVMe-oF功能允许其以NVMe设备的形式接入主机系统,操作系统无需额外的复杂配置即可直接访问远端的全闪存存储池,所有软件定义存储功能在DPU上完成,极大简化了存储访问的复杂度。此外,DPU助力实现“算存分离”,即业务应用和操作系统可以借助DPU透明地访问远程存储系统,同时在DPU上处理加密、去重、压缩等复杂功能,进一步释放了CPU资源,加速了数据处理流程。
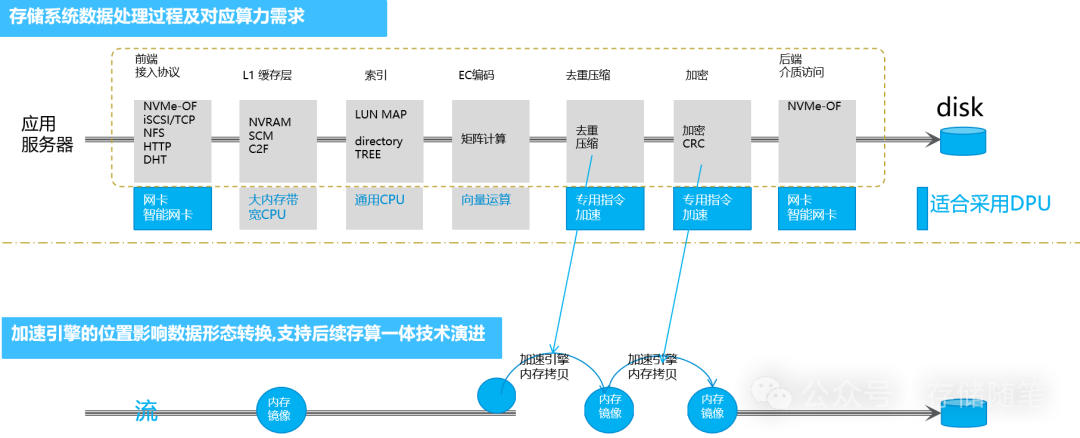
通过DPU技术,能够显著降低RDMA访问的延迟和CPU占用率,实现iSCSI、RBD、virtio fs客户端控制面指令和数据处理的卸载,提高数据访问的安全性,并通过协议加速器执行去重和压缩操作,进一步节省CPU资源。同时,DPU还支持NVMe卸载,简化主机存储协议栈,提高安全性,通过内置的密钥证书管理等机制强化静态数据安全。
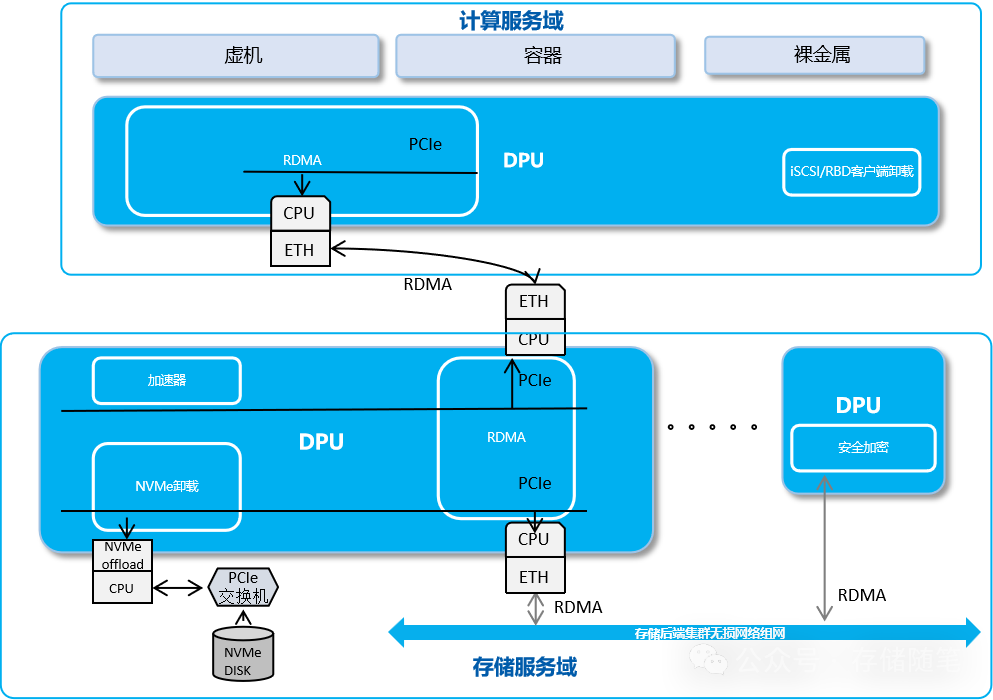
在后摩尔时代,面对存储性能与效率的双重挑战,DPU的出现为数据中心存储技术带来了革命性的变化。通过DPU的硬件加速方案,数据中心不仅能够有效应对存储性能瓶颈,实现更高的数据处理效率,还能确保数据的安全性与系统的稳定性。
四、DPU让QLC SSD发挥更大的价值
采用QLC NVMe设备与DPU技术相结合的案例,将基于ZNS QLC的SSD纳入数据中心。SMR HDD的行为非常相似,它们在数据中心被采用之前也经历了8-10年的时间,原因在于文件系统、操作系统,有时甚至是应用程序,都需要修改以处理SMR HDD的写入算法。ZNS SSD和QLC SSD普遍也是如此。
扩展阅读:
-
深度剖析:大容量QLC SSD为何遭疯抢?
-
为什么QLC NAND才是ZNS SSD最大的赢家?
-
字节跳动ZNS SSD应用案例解析
-
NVMe SSD:ZNS与FDP对决,你选谁?
DPU是完全虚拟化QLC SSD(以及未来的PLC SSD)的理想选择,因为它可以处理高度随机、任意块大小的写入,并管理SSD所需的后端顺序化。有了DPUs,任何数据中心都可以在不改变其软件堆栈的情况下利用最新技术的TCO节省。
为了实现最大的TCO效率,不要忽视DPU。DPU与CPU和GPU高度互补,必须与它们共存以实现最大的TCO效率。灵活的DPU可以在多种不同的工作负载和架构中被采纳。但并非所有的DPU都生而平等,最好的DPU具有高度可编程性,结合硬连线和计算能力,使它们能够适应每个数据中心的具体需求和用例。
如果您看完有所受益,欢迎点击文章底部左下角“关注”并点击“分享”、“在看”,非常感谢!
精彩推荐:
-
论文解读|数据中心内存RAS技术全景剖析
-
硬盘HDD:AI时代的战略金矿?
-
断电的固态硬盘数据能放多久?
-
CXL-GPU: 全球首款实现百ns以内的低延迟CXL解决方案
-
万字长文|下一代系统内存数据加速接口SDXI解读
-
数据中心:AI范式下的内存挑战与机遇
-
WDC西部数据闪存业务救赎之路,会成功吗?
-
属于PCIe 7.0的那道光来了~
-
深度剖析:AI存储架构的挑战与解决方案
-
浅析英伟达GPU NCCL P2P与共享内存
-
3D NAND原厂:哪家芯片存储效率更高?
-
大厂阿里、字节、腾讯都在关注这个事情!
-
磁带存储:“不老的传说”依然在继续
-
浅析3D NAND多层架构的可靠性问题
-
SSD LDPC软错误探测方案解读
-
关于SSD LDPC纠错能力的基础探究
-
存储系统如何规避数据静默错误?
-
PCIe P2P DMA全景解读
-
深度解读NVMe计算存储协议
-
浅析不同NAND架构的差异与影响
-
SSD基础架构与NAND IO并发问题探讨
-
字节跳动ZNS SSD应用案例解析
-
CXL崛起:2024启航,2025年开启新时代
-
NVMe SSD:ZNS与FDP对决,你选谁?
-
浅析PCI配置空间
-
浅析PCIe系统性能
-
存储随笔《NVMe专题》大合集及PDF版正式发布!






![[ACM独立出版] 2024年虚拟现实、图像和信号处理国际学术会议(VRISP 2024,8月2日-4)](https://i-blog.csdnimg.cn/direct/67ca176b92f1497394f1441e36dbff5b.png#pic_center)