高斯过程其在回归任务中的应用我们都很熟悉了,但是我们一般介绍的都是针对单个任务的,也就是单个输出。本文我们将讨论扩展到多任务gp,强调它们的好处和实际实现。
本文将介绍如何通过共区域化的内在模型(ICM)和共区域化的线性模型(LMC),使用高斯过程对多个相关输出进行建模。
多任务高斯过程
高斯过程是回归和分类任务中的一个强大工具,提供了一种非参数方式来定义函数的分布。当处理多个相关输出时,多任务高斯过程可以模拟这些任务之间的依赖关系,从而带来更好的泛化和预测效果。
数学上,高斯过程被定义为一组随机变量,其中任何有限数量的变量都具有联合高斯分布。对于一组输入点 X,相应的输出值 f(X) 是联合高斯分布的:
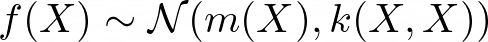
其中 m(X) 是均值函数,k(X, X) 是协方差矩阵。
在多任务环境中,目标是建模函数 f: X → R^T,这样我们就有 T 个输出或任务,f_t(X) 对于 t = 1, …, T。这意味着均值函数是 m: X → R^T,核函数是 k: X × X → R^{T × T}。
我们如何模拟这些任务之间的相关性?
独立多任务高斯过程
一个简单的独立多输出高斯过程模型将每个任务独立建模,不考虑任务之间的任何相关性。在这种情况下,每个任务都有自己的高斯过程,具有自己的均值和协方差函数。数学上可以表达为:
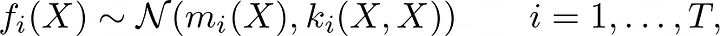
这使得协方差矩阵 k(x, x) 是块对角形的,即 diag(k_1(x, x), …, k_T(x, x))。
这种方法没有利用任务之间的共享信息,可能导致性能不佳,尤其是当某些任务的数据有限时。
Intrinsic model of coregionalization(ICM)
ICM(共区域化的内在模型)方法通过引入核心区域化矩阵 (B) 来推广独立多输出高斯过程,该矩阵模型化任务之间的相关性。ICM方法中的协方差函数定义如下:
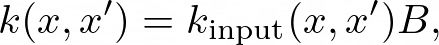
其中 k_input是在输入空间上定义的协方差函数(例如,平方指数核),而 B ∈ R^{T × T} 是捕捉任务特定协方差的核心区域化矩阵。矩阵 (B) 通常参数化为 (B = W W^T),其中W ∈ R^{T × r*}* ,且 ® 是核心区域化矩阵的秩。这确保了核函数是半正定的。
ICM方法可以学习任务之间的共享结构。任务之间的皮尔逊相关系数可以表示为:
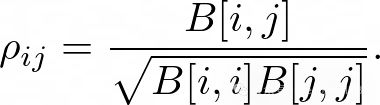
Linear model of coregionalization (LMC)
另一种常见的方法是LMC(线性核心区域化模型)模型,它通过允许更多种类的输入核来扩展ICM。在LMC模型中,协方差函数定义为:
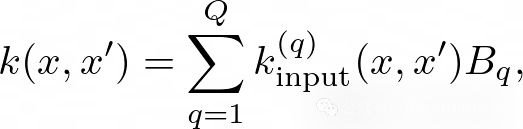
其中 (Q) 是基核的数量,k_input^q 是基核,而 (B_q) 是每个基核的核心区域化矩阵。通过结合多个基核,这个模型可以捕捉任务之间更复杂的相关性。
我们可以通过设置 (Q=1) 来恢复ICM模型。或者说ICM是Q=1的LMC模型
噪声建模
在多任务高斯过程中,我们需要考虑一个多输出似然函数,该函数为每个任务模型化噪声。
标准的似然函数通常是多维高斯似然,可以表示为:

其中 (y) 是观测输出,(f(x)) 是潜在函数,Sigma是噪声协方差矩阵。
这里的灵活性在于噪声协方差矩阵的选择,它可以是对角线Σ=diag(σ12,…,σT2)(每个任务独立噪声)或完整(任务间相关噪声)。
后者通常表示为 Σ=LLT,其中 L∈RT×r,且 r是噪声协方差矩阵的秩。这允许捕捉不同任务的噪声项之间的相关性。
最终包含噪声的协方巧矩阵则由以下给出:
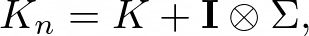
其中 (K) 是没有噪声的协方差矩阵,(I) 是单位矩阵,⊗表示克罗内克乘积,以便将噪声项添加到协方差矩阵的对角块中。
PyTorch实现
我们上面介绍了多任务的高斯过程的数学原理,下面开使用’ GPyTorch '与ICM内核实现多任务GP的示例。
首先需要安装所需的软件包,包括’ Torch ', ’ GPyTorch ', ’ matplotlib ‘和’ seaborn ', ’ numpy '。
%pip install torch gpytorch matplotlib seaborn numpy pandasimport torchimport gpytorchfrom matplotlib import pyplot as pltimport numpy as npimport seaborn as snsimport pandas as pd
然后,定义多任务GP模型。使用ICM内核(秩r=1)来捕获任务之间的相关性。
我们为两个任务(正弦和移位正弦)生成合成的噪声训练数据,以便有相关的输出。
噪声协方差矩阵为
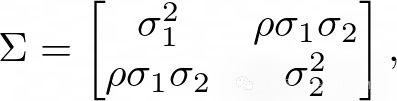
其中σ²1 = σ²2 = 0.1²,ρ = 0.3。
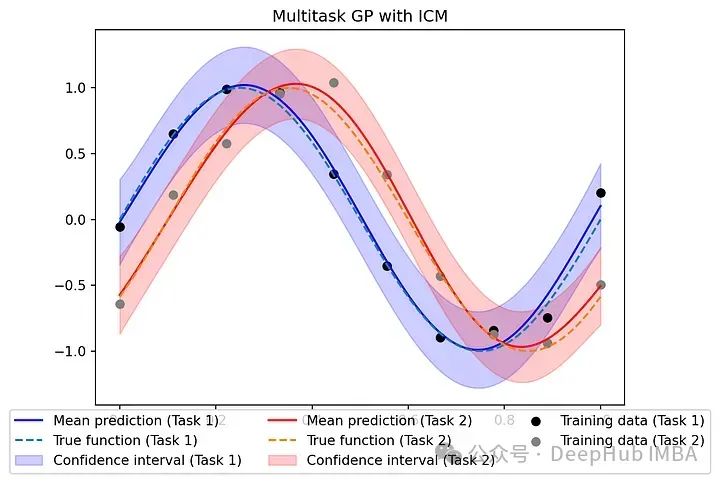
最后,我们通过绘制每个任务的平均预测和置信区间来训练模型并评估其性能。
# Define the kernel with coregionalizationclass MultitaskGPModel(gpytorch.models.ExactGP):def __init__(self, train_x, train_y, likelihood, num_tasks):super(MultitaskGPModel, self).__init__(train_x, train_y, likelihood)self.mean_module = gpytorch.means.MultitaskMean(gpytorch.means.ConstantMean(), num_tasks=num_tasks)self.covar_module = gpytorch.kernels.MultitaskKernel(gpytorch.kernels.RBFKernel(), num_tasks=num_tasks, rank=1)def forward(self, x):mean_x = self.mean_module(x)covar_x = self.covar_module(x)return gpytorch.distributions.MultitaskMultivariateNormal(mean_x, covar_x)# Training dataf1 = lambda x: torch.sin(x * (2 * torch.pi))f2 = lambda x: torch.sin((x - 0.1) * (2 * torch.pi))train_x = torch.linspace(0, 1, 10)train_y = torch.stack([f1(train_x),f2(train_x)]).T# Define the noise covariance matrix with correlation = 0.3sigma2 = 0.1**2Sigma = torch.tensor([[sigma2, 0.3 * sigma2], [0.3 * sigma2, sigma2]])# Add noise to the training datatrain_y += torch.tensor(np.random.multivariate_normal(mean=[0,0], cov=Sigma, size=len(train_x)))# Model and likelihoodnum_tasks = 2likelihood = gpytorch.likelihoods.MultitaskGaussianLikelihood(num_tasks=num_tasks, rank=1)model = MultitaskGPModel(train_x, train_y, likelihood, num_tasks)# Training the modelmodel.train()likelihood.train()optimizer = torch.optim.Adam(model.parameters(), lr=0.1)mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)num_iter = 500for i in range(num_iter):optimizer.zero_grad()output = model(train_x)loss = -mll(output, train_y)loss.backward()optimizer.step()scheduler.step()# Evaluationmodel.eval()likelihood.eval()test_x = torch.linspace(0, 1, 100)with torch.no_grad(), gpytorch.settings.fast_pred_var():pred_multi = likelihood(model(test_x))# Plot predictionsfig, ax = plt.subplots()colors = ['blue', 'red']for i in range(num_tasks):ax.plot(test_x, pred_multi.mean[:, i], label=f'Mean prediction (Task {i+1})', color=colors[i])ax.plot(test_x, [f1(test_x), f2(test_x)][i], linestyle='--', label=f'True function (Task {i+1})')lower = pred_multi.confidence_region()[0][:, i].detach().numpy()upper = pred_multi.confidence_region()[1][:, i].detach().numpy()ax.fill_between(test_x,lower,upper,alpha=0.2,label=f'Confidence interval (Task {i+1})',color=colors[i])ax.scatter(train_x, train_y[:, 0], color='black', label=f'Training data (Task 1)')ax.scatter(train_x, train_y[:, 1], color='gray', label=f'Training data (Task 2)')ax.set_title('Multitask GP with ICM')ax.legend(loc='lower center', bbox_to_anchor=(0.5, -0.2),ncol=3, fancybox=True)
在使用
GPyTorch
时,通过使用
MultitaskMean
、
MultitaskKernel
和
MultitaskGaussianLikelihood
类,ICM模型的实现非常简单。这些类可以处理多任务结构、噪声和核心区域化矩阵,允许我们专注于模型定义和训练。
训练的循环也与标准高斯过程类似,以负边际对数似然作为损失函数,并使用优化器来更新模型参数。
在训练过程中添加了一个调度器来降低学习率,这可以帮助稳定优化过程。
W = model.covar_module.task_covar_module.covar_factorB = W @ W.Tfig, ax = plt.subplots()sns.heatmap(B.detach().numpy(), annot=True, ax=ax, cbar=False, square=True)ax.set_xticklabels(['Task 1', 'Task 2'])ax.set_yticklabels(['Task 1', 'Task 2'])ax.set_title('Coregionalization matrix B')fig.show()L = model.likelihood.task_noise_covar_factor.detach().numpy()Sigma = L @ L.Tfig, ax = plt.subplots()sns.heatmap(Sigma, annot=True, ax=ax, cbar=False, square=True)ax.set_xticklabels(['Task 1', 'Task 2'])ax.set_yticklabels(['Task 1', 'Task 2'])ax.set_title('Noise covariance matrix')fig.show()
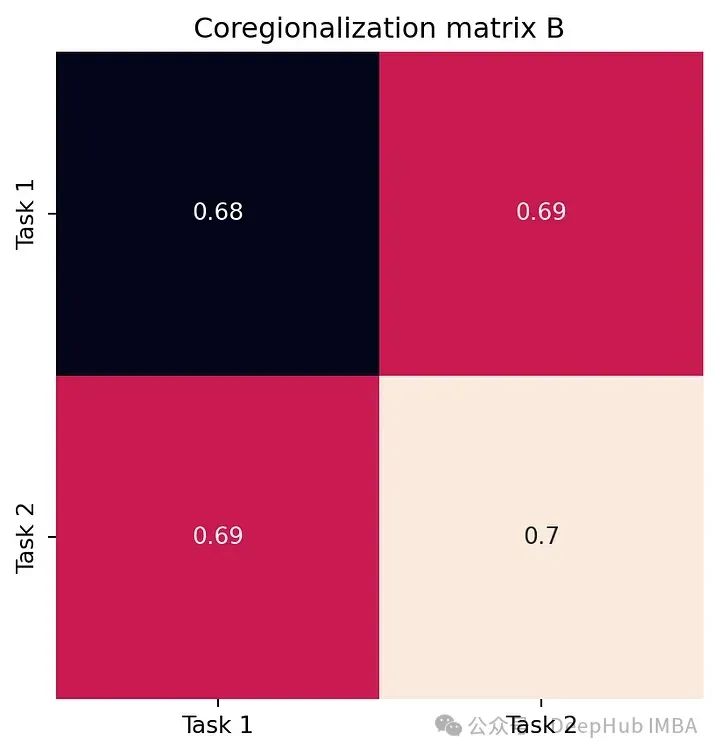
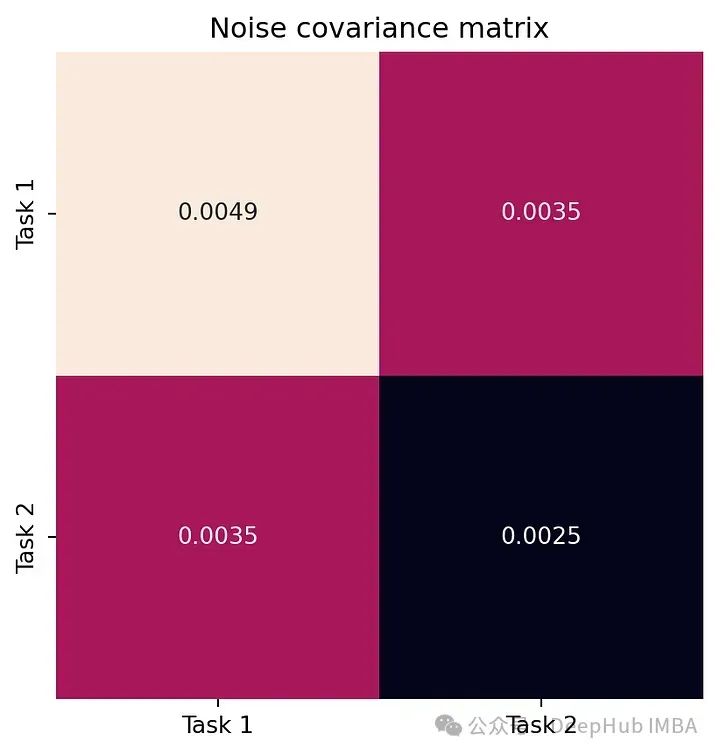
下面的图展示了模型学习的核心区域化矩阵 B 以及噪声协方差矩阵 Σ。
这张图捕捉了任务之间的相关性。如我们所见,B 的非对角线元素是正的。
这个图代表每个任务的噪声水平。注意到模型已经正确学习了噪声相关性。
比较
为了突出使用ICM方法对相关输出建模的优势,我们可以将其与独立处理每个任务、忽略任务之间任何潜在相关性的模型进行比较。
为每个任务定义一个单独的GP,训练它们,并在测试数据上评估它们的性能。
class IndependentGPModel(gpytorch.models.ExactGP):def __init__(self, train_x, train_y, likelihood):super(IndependentGPModel, self).__init__(train_x, train_y, likelihood)self.mean_module = gpytorch.means.ConstantMean()self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel())def forward(self, x):mean_x = self.mean_module(x)covar_x = self.covar_module(x)return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)# Create models and likelihoods for each tasklikelihoods = [gpytorch.likelihoods.GaussianLikelihood() for _ in range(num_tasks)]models = [IndependentGPModel(train_x, train_y[:, i], likelihoods[i]) for i in range(num_tasks)]# Training the independent modelsfor i, (model, likelihood) in enumerate(zip(models, likelihoods)):model.train()likelihood.train()optimizer = torch.optim.Adam(model.parameters(), lr=0.1)mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5)for _ in range(num_iter):optimizer.zero_grad()output = model(train_x)loss = -mll(output, train_y[:, i])loss.backward()optimizer.step()scheduler.step()# Evaluationfor model, likelihood in zip(models, likelihoods):model.eval()likelihood.eval()with torch.no_grad(), gpytorch.settings.fast_pred_var():pred_inde = [likelihood(model(test_x)) for model, likelihood in zip(models, likelihoods)]# Plot predictionsfig, ax = plt.subplots()for i in range(num_tasks):ax.plot(test_x, pred_inde[i].mean, label=f'Mean prediction (Task {i+1})', color=colors[i])ax.plot(test_x, [f1(test_x), f2(test_x)][i], linestyle='--', label=f'True function (Task {i+1})')lower = pred_inde[i].confidence_region()[0]upper = pred_inde[i].confidence_region()[1]ax.fill_between(test_x,lower,upper,alpha=0.2,label=f'Confidence interval (Task {i+1})',color=colors[i])ax.scatter(train_x, train_y[:, 0], color='black', label='Training data (Task 1)')ax.scatter(train_x, train_y[:, 1], color='gray', label='Training data (Task 2)')ax.set_title('Independent GPs')ax.legend(loc='lower center', bbox_to_anchor=(0.5, -0.2),ncol=3, fancybox=True)
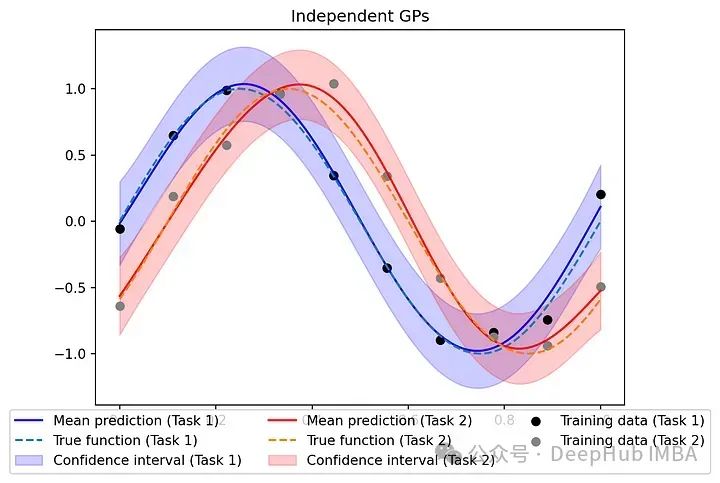
在性能方面,比较多任务GP与ICM和独立GP在测试数据上预测的均方误差(MSE)。
mean_multi = pred_multi.mean.numpy()mean_inde = np.stack([pred.mean.numpy() for pred in pred_inde]).Ttest_y = torch.stack([f1(test_x), f2(test_x)]).T.numpy()MSE_multi = np.mean((mean_multi - test_y) ** 2)MSE_inde = np.mean((mean_inde - test_y) ** 2)df = pd.DataFrame({'Model': ['ICM', 'Independent'],'MSE': [MSE_multi, MSE_inde]})df

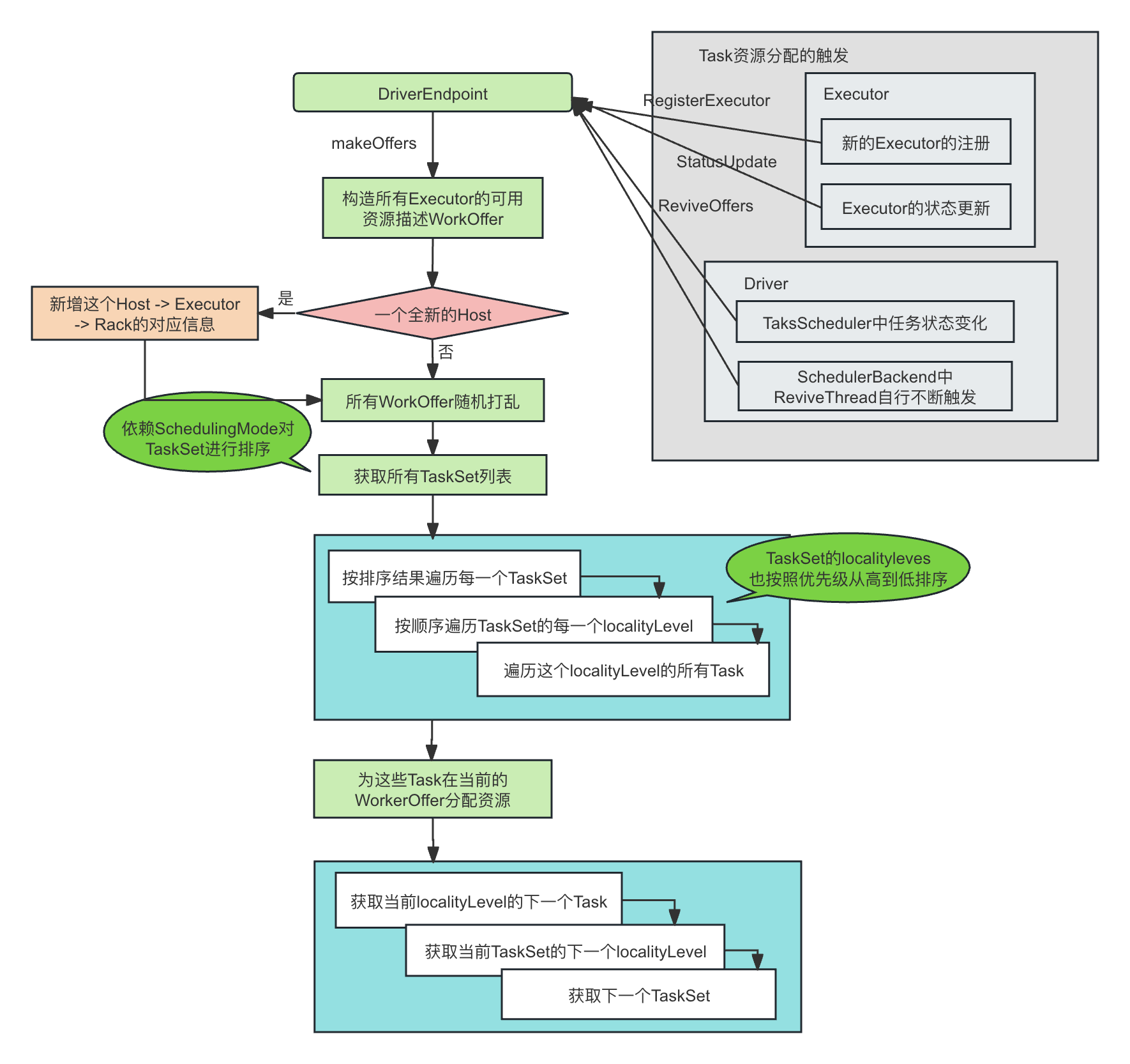
可以看到由于共区域化矩阵学习到的共享结构,ICM在MSE方面略优于独立gp。当处理更复杂的任务或有限的数据时,这种改进可能更为显著。
在独立GP的场景中,每个GP从一个较小的10个点的数据集中学习,这可能会导致过拟合或次优泛化。具有ICM的多任务GP使用所有20个点来学习指数核参数的平方。这种共享信息有助于改进对这两个任务的预测。
https://avoid.overfit.cn/post/f804e93bd5dd4c4ab9ede5bf1bc9b6c8
作者:Andrea Ruglioni