文章目录
- 1. 什么是OCR
- 2. 什么是Tess4J库?
- 3. 引入依赖
- 4. 下载默认的训练数据
- 5. 配置训练数据的目录路径
- 6. 测试代码
- 6.1 TesseractOcrConfig
- 6.2 OcrController
- 6.3 OcrService
- 6.4 OcrServiceImpl
- 7. 功能测试
- 7.1 调试请求接口
- 7.2 测试结果
1. 什么是OCR
**OCR (Optical Character Recognition,光学字符识别)指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程. **
2. 什么是Tess4J库?
**Tess4J是一个开源的Java库,它为Tesseract OCR(光学字符识别)引擎提供了一个简单的Java API。Tesseract是一个强大的开源OCR引擎,可以将图像中的文本转换为可编辑的文本。Tess4J使得在Java应用程序中使用Tesseract OCR变得更加容易。 **
主要功能和特点
- 文本提取:能够从图像中提取文本,包括印刷文本和手写文本。
- 多语言支持:支持多种语言的OCR,包括但不限于英语、中文、日语、韩语等。
- 简单的API:提供了易于使用的Java API,使开发者可以轻松地将OCR功能集成到他们的Java应用程序中。
- 扩展性:支持自定义词典和训练数据,以提高特定应用场景下的OCR准确性。
- 图像处理:支持基本的图像处理功能,如图像预处理,以提高OCR的准确性。
3. 引入依赖
<!-- tess4j -->
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.4</version>
</dependency>
4. 下载默认的训练数据
训练数据下载地址
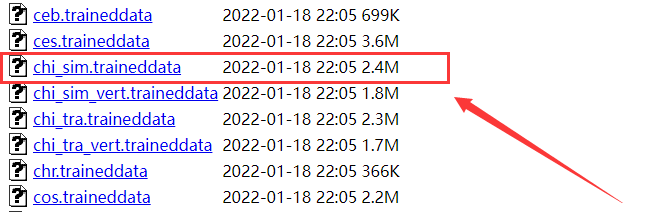
5. 配置训练数据的目录路径
# 训练数据文件夹的路径
tess4j:datapath: E:\Software\trainData # 注意改成自己的文件路径
6. 测试代码
6.1 TesseractOcrConfig
/*** @author Ccoo* 2024/7/19*/
@Configuration
public class TesseractOcrConfig {@Value("${tess4j.datapath}")private String dataPath;@Beanpublic Tesseract tesseract() {Tesseract tesseract = new Tesseract();// 设置训练数据文件夹路径tesseract.setDatapath(dataPath);// 设置为中文简体tesseract.setLanguage("chi_sim");return tesseract;}
}
6.2 OcrController
/*** @author Ccoo* 2024/7/19*/
@RequestMapping("/ocr")
@RestController
@AllArgsConstructor
public class OcrController {private final OcrService ocrService;@PostMapping(value = "/recognize", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)public String recognizeImage(@RequestParam("file") MultipartFile file) throws TesseractException, IOException {// 调用OcrService中的方法进行文字识别return ocrService.recognizeText(file);}}
6.3 OcrService
public interface OcrService {String recognizeText(MultipartFile file) throws IOException, TesseractException;}
6.4 OcrServiceImpl
/*** @author Ccoo* 2024/7/19*/
@Service
@AllArgsConstructor
public class OcrServiceImpl implements OcrService {private final Tesseract tesseract;/*** 识别图片中的文字* @param imageFile 图片文件* @return 文字信息*/public String recognizeText(MultipartFile imageFile) throws IOException, TesseractException {// 转换InputStream sbs = new ByteArrayInputStream(imageFile.getBytes());BufferedImage bufferedImage = ImageIO.read(sbs);// 对图片进行文字识别return tesseract.doOCR(bufferedImage);}
}
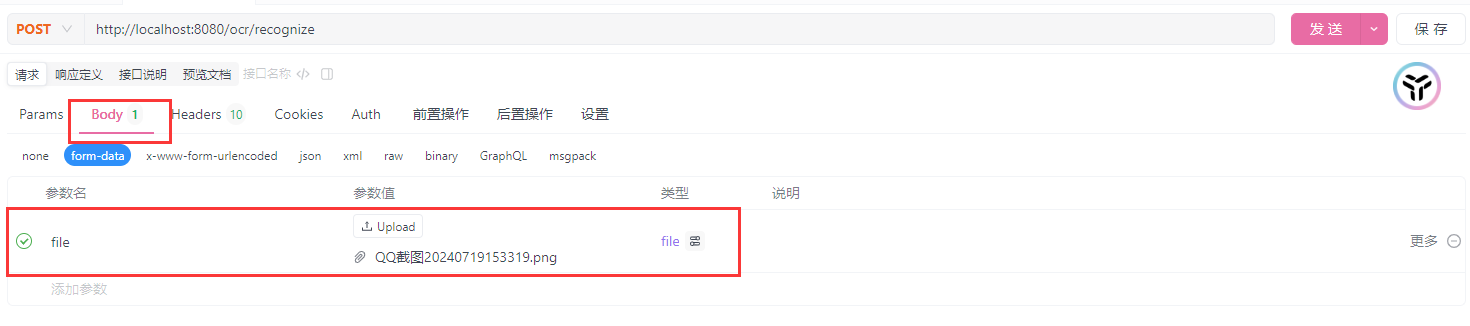
7. 功能测试
7.1 调试请求接口

7.2 测试结果
默认训练库的识别率还是可以的, 对于需要识别率更高的, 需自行训练!!