一、数据库相关概念
1.1 相关概念
| 名称 | 全称 | 简称 |
|---|---|---|
| 数据库 | 存储数据的仓库、数据是有组织的进行存储 | DataBase(DB) |
| 数据库管理系统 | 操作和管理数据库的大型软件 | DataBase Management System(DBMS) |
| SQL | 操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准 | Structured Query Language(SQL) |

客户端连接
系统自带的命令行工具执行命令:mysql [-h 127.0.0.1] [-P 3306] -u root - p
1.2 关系型数据库(RDB)
建立在关系模型的基础上,由多张相互连接的二维表组成的数据库。
特点:
- 使用表存储数据,格式统一,便于维护;
- 使用SQL语言操作,标准统一,使用方便。
二、SQL语句
2.1 SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾;
- SQL语句可以使用空格/缩进来增强语句的可读性;
- MySQL数据库的SQL语句不区分大小写,关键字建议使用大写。
- 注释:
- 单行注释:-- 或 #
- 多行注释:/* */
2.2 SQL分类
| 分类 | 全称 | 说明 | 语句 |
|---|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库、表、字段) | Show/Create/Drop/Alter |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 | insert/delete/update |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 | select |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户,控制数据库的访问权限 | Create/Drop/Alter |
三、约束
约束是作用于表中字段上的规则,用于限制存储在表中的数据。
目的是为了保证,数据库中数据的正确性、有效性和完整性。
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段的数据不能为null | NOT NULL |
| 唯一约束 | 保证该字段的所有数据都是唯一的、不重复的 | UNIQUE |
| 主键约束 | 主键是一行数据的唯一标识,要求非空且唯一 | PRIMARY KEY |
| 默认约束 | 保存数据时,如果未指定该字段的值,则采用默认值 | DEFAULT |
| 检查约束 | 保证字段值满足某一个条件 | CHECK |
| 外键约束 | 用来让两张表的数据之间建立连接,保证数据的一致性和完整性 | FOREIGN KEY |
外键约束
- 添加外键
create table 表名(字段名 数据类型,……constraint (外键名称) foreign key(外键字段名) references 主表(主表列名));alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名);
-
删除外键
alter table 表名 drop foreign key 外键名称;
当删除或更新外键时,数据库可以执行的行为。

默认是 no action/restrict。
设置行为:
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(主表列名) on update cascade on delete cascade;
四、事务
事务是一组操作的集合,它是不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
4.1 事务的操作
4.1.1 方式一
-
查看/设置事务提交方式
select @@autocommit;
set @@autocommit=0;
-
提交事务
commit;
-
回滚事务
rollback;
默认mysql的事务是自动提交的,也就是说,当执行一条DML语句,mysql会立即隐式的提交事务。
我们可以通过设置@@autocommit=0,改成手动提交事务。
当我们执行完所有sql语句后,执行commit命令,如果中间出现异常,可以使用rollback回滚事务。
4.1.2 方式二
-
开启事务
start transaction 或 begin;
-
提交事务
commit;
-
回滚事务
rollback;
4.2 事务的四大特性(ACID)
- 原子性:事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性:事务完成时,必须使所有的数据都保持一致状态。
- 隔离性:数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性:事务一旦提交或回滚,它对数据库中数据的改变就是永久的。
4.3 事务的并发问题
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另一个事务还没有提交的数据。 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取到的数据不同,称之为不可重复读。 |
| 幻读 | 原来不存在的数据行,现在存在了。一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了幻影。 |
4.4 事务的隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read | × | × | √ |
| Serializable | × | × | × |
读未提交:就是可以读取到其他事务还没有提交的数据,会出现三种并发问题。
读已提交:读取其他事务已经提交的数据,虽然可以解决脏读问题,但是,不能解决
不可重复读问题,因为如果其他事务的提交正好处于本事务的两次查询之间,就导致两次查询的结果不一致。不可重复读并不是指你不能读两次,而是指你读两次结果不一致,是一种无效的读。可重复读:是指在同一个事务中,不管读多少次,结果都是和第一次一样。这样也会导致新的问题就是
幻读,由于同一个事务中查询多少次都是和第一次一样,那么如果有新的事务在这个过程中插入了新数据,我们还是查不到的。串行化:终极大杀器,如果当前事务还没有执行完,其他事务必须排队等候。
mysql默认是
Repeatable Read查看事务的隔离级别
select @@transaction_isolation
设置事务的隔离级别
set [session|global] transaction isolation level {Read uncommitted|Read committed|Repeatable Read|Serializable}
- session:会话级别,仅对当前客户端窗口有效;
- global:全局级别,针对所有客户端窗口有效。
注意:事务的隔离级别越高,数据越安全,但是性能越低。
4.5 当前读和快照读
当前读:读取最新的数据,而不是历史版本的数据。加锁的select、insert、update、delect。
快照读:读取的是快照数据。普通的select操作。
4.6 事务隔离性的实现
-
读写锁
最简单的事务隔离实现方式。每次读操作需要获取一个共享锁,每次写操作需要获取一个写锁。
共享锁之间不产生互斥,共享锁和写锁之间以及写锁与写锁之间会产生互斥。
-
MVCC(多版本并发控制)
在读写锁中,读和写的排斥作用大大降低了事务的并发效率,于是人们又提出了能不能让读写之间也不冲突的方法,就是读取数据时通过一种类似快照的方式将数据保存下来,这样读锁就和写锁不冲突了。不同的事务 session会看到自己特定版本的数据,即使其他的事务更新了数据,但是对本事务仍然不可见,本事务看到的数据始终是第一次查询到的数据。在数据库中,这个快照的处理方式叫多版本并发控制(Multi-Version Concurrency Control)。这种方式真正实现了非阻塞读,只有在写操作时才需要加行级锁,因此并发效率更高。
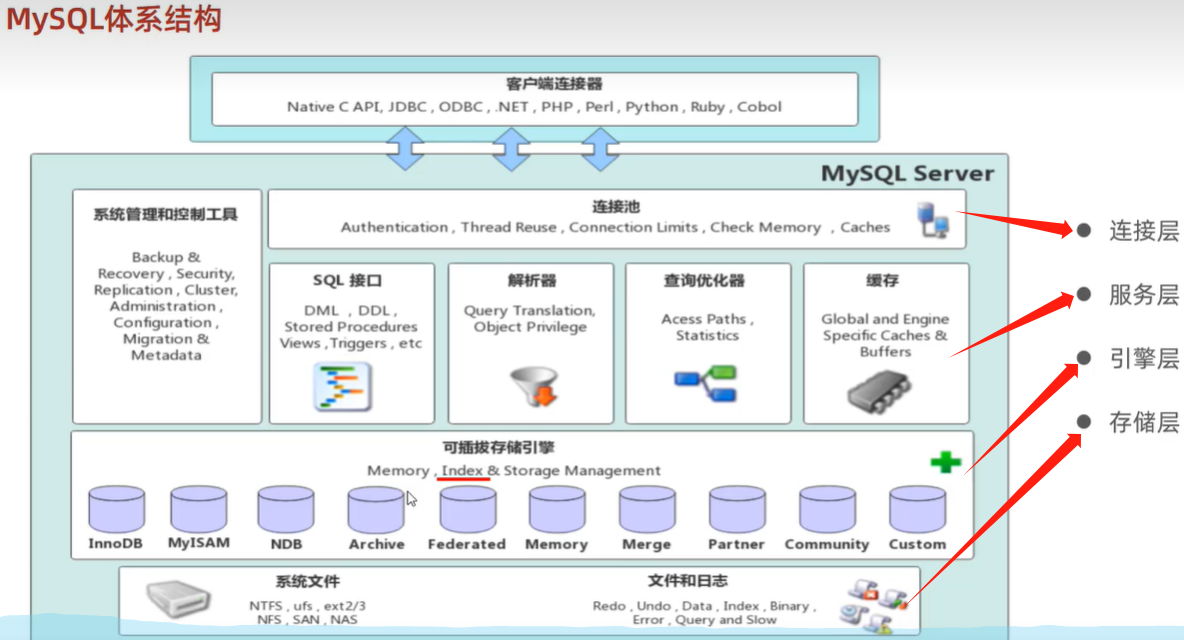
五、存储引擎
存储引擎就是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为表类型。
CREATE TABLE `account` (`id` int NOT NULL AUTO_INCREMENT COMMENT '主键ID',`name` varchar(10) DEFAULT NULL COMMENT '姓名',`money` int DEFAULT NULL COMMENT '余额',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='账户表'
mysql的默认存储引擎是InnoDB。
查看当前数据库支持的所有存储引擎:show engines;
5.1 存储引擎的特点
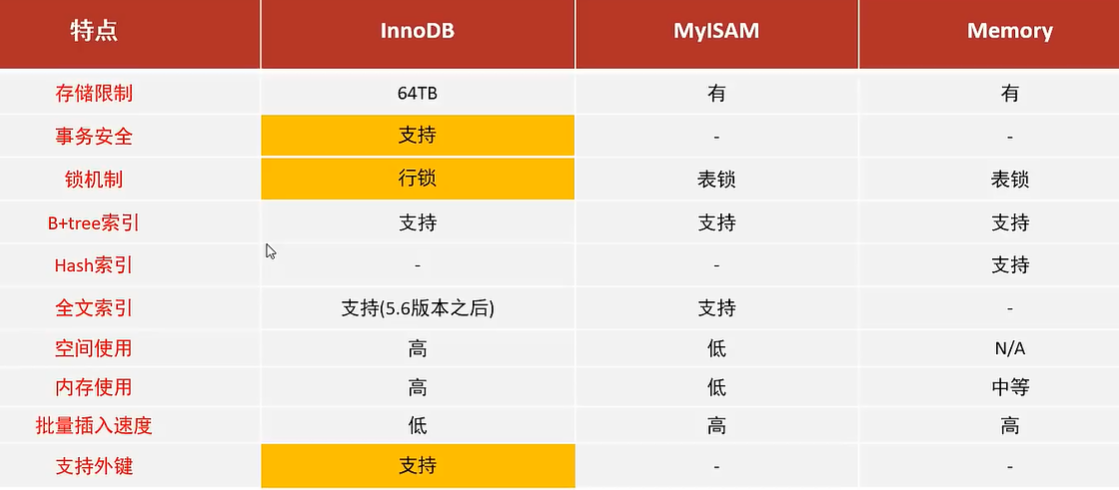
5.1.1 InnoDB
InnoDB是一种兼顾高可靠性和高性能的通用存储引擎,在mysql5.5之后,成为了mysql的默认存储引擎。
特点:
- DML操作遵循ACID模型,支持事务;
- 行级锁,提高并发访问性能;
- 支持外键Foreign key 约束,保证数据的完整性和正确性。
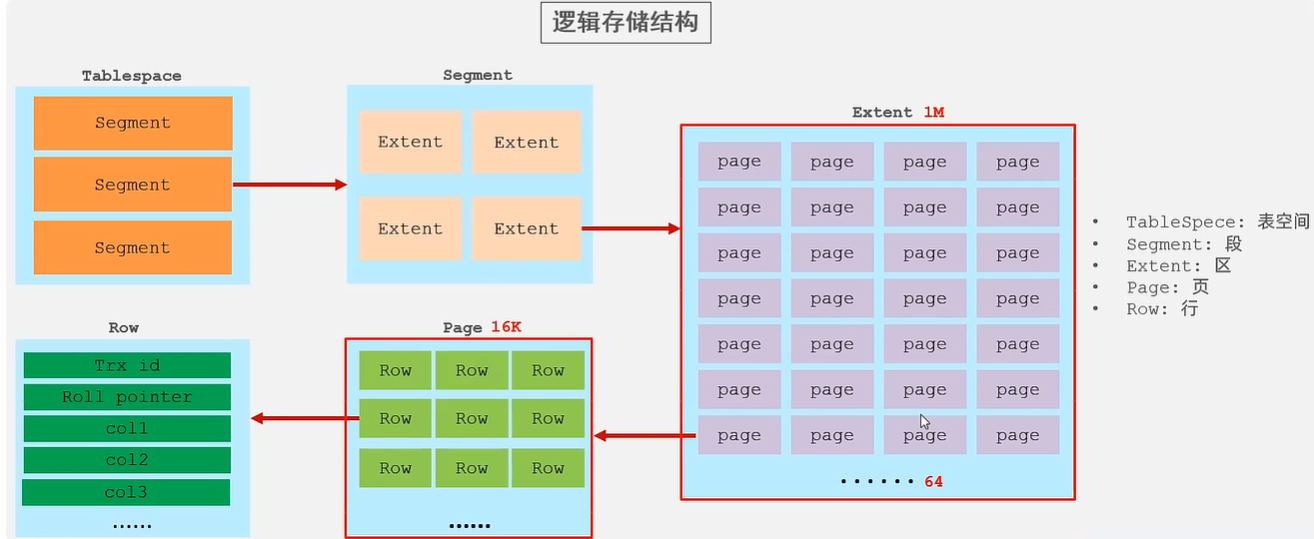
文件:
xxx.ibd:xxx代表表名,innoDB引擎的每张表都会对应这样一个表空间文件,存储该表的表结构、数据和索引。
5.1.2 MyISAM
MyISAM是mysql早期的默认存储引擎。
特点:
- 不支持事务、不支持外键;
- 支持表锁,不支持行锁;
- 访问速度快。
5.1.3 Memory
存储在内存中的,由于会受到硬件问题、或断电问题的影响,只能将这些表作为临时表或者缓存使用。
特点:
- 内存存放;
- hash索引(默认)。
文件:xxx.sdi 存储表结构信息。
5.2 存储引擎的选择

六、索引
6.1 索引
索引(index)是帮助Mysql高效获取数据的数据结构(有序)。

优缺点
| 优势 | 劣势 |
|---|---|
| 提高数据检索的效率,降低数据库的IO成本 | 索引列也要占用空间 |
| 通过索引列对数据进行排序,降低数据排序的成本,降低cpu的消耗 | 索引大大提高了查询效率,同时却降低更新表的速度,如对表进行增删改时,效率低。 |
索引结构
mysql的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:
| 索引结构 | 描述 |
|---|---|
| B+Tree | 最常见的索引类型,大部分引擎都支持 |
| Hash | 底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询 |
| R-tree(空间索引) | MyISAM引擎的一种特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 是一种通过建立倒排索引,快速匹配文档的方式,类似于Lucene、solr、ES |
6.2 B-Tree

B-Tree(多路平衡查找树)
下面这棵树的度为5,树的度指的是一个节点的子节点的个数。
B-Tree的构建过程:一个节点存放度数-1个key(数据),超过这个数的时候,节点会向上分裂,将中间元素移动到父节点中。


插入2456时变成下面这样子:

B Tree的每一个节点中存放数据和索引。
6.3 B+Tree

红色框里面的是存放的数据,绿色框里面的数据起到索引的作用。
叶子节点之间形成一个单向链表。
B+Tree向上分裂的时候,分裂节点同时也会保留在叶子节点中,并在叶子节点之间形成链表。

Mysql的索引数据结构对经典的B+Tree进行了优化。在原来的基础上,形成了双向链表,并且首尾相连。

6.4 哈希索引
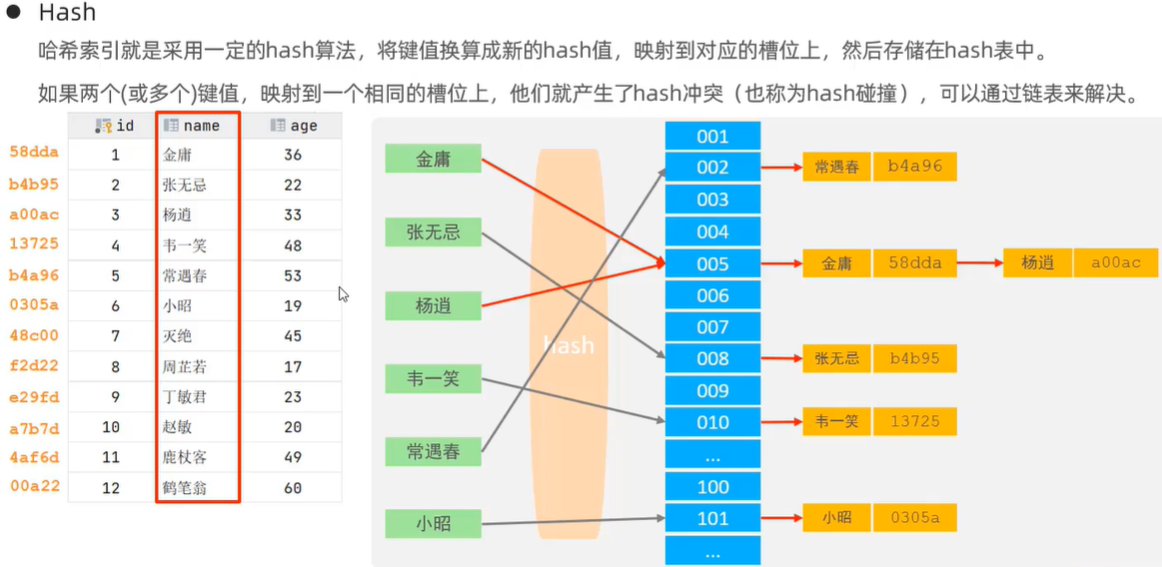
hash索引的特点:
- 只能用于对等比较(=,in),不支持范围查询(between,>,<);
- 无法利用索引完成排序操作;
- 查询效率高,通常只需要一次检索就可以,效率通常高于B+tree。
6.5 思考
为什么InnoDB选择B+tree?
- 相对于二叉树,层级更少,搜索效率更高;
- 对于B-tree,无论是叶子节点还是非叶子节点,都是保存在page中的,innodb的page大小为16k,如果采用BTree,会导致一页可存储的键值减少,指针跟着减少,要保存同样的数据时,只能增加树的高度,导致性能降低;
- 相对于hash索引,B+Tree支持范围匹配和排序操作。
6.6 索引的分类
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | primary |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | unique |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 查找文本中的关键词,而不是比较索引中的值 | 可以有多个 | fulltext |
在InnoDB存储引擎中,根据索引的存储形式,又可以分为以下两种:
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 | 将数据存储与索引放到一起,索引结构的叶子节点保存了行数据 | 必须有,且只有一个 |
| 二级索引 | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以有多个 |
聚集索引选取规则:
- 如果存在主键,主键索引就是聚集索引;
- 如果不存在主键,将使用第一个唯一索引;
- 如果这两都没有,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。

回表查询:查询时如果使用的不是聚集索引,就需要先查询二级索引,根据二级索引的结果,再去聚集索引中查找。