前言
首届YashanDB「迁移体验官」开放后,陆续收到「体验官」们的投稿,小崖在此把优秀的投稿文章分享给大家~今天分享的用户文章是《崖山异构数据库迁移利器YMP初体验-Oracle迁移YashanDB》(作者:小草),满满干货,不要错过!
号外!新的征文活动已开启,点击此处或戳一戳下方图片即可跳转活动链接,最高可获千元大奖!

一、背景
我司主要软件生态数据库使用的是Oracle,国产数据库中崖山兼容Oracle做的比较好。在国产化替换进程中崖山无疑是首选,因为替换的研发和运维成本相对较低。为了提前了解国产数据库与Oracle的兼容适配情况,测试并研究生产应用的可能性,特意关注国产化数据库的最新动态。通过测试国产数据库及相关生态工具验证其可行性。本文主要介绍如何通过崖山YMP异构迁移工具将Oracle数据库迁移到YashanDB数据库。
二、YMP简介
2.1概述
崖山迁移平台(YashanDB Migration Platform,YMP)是YashanDB提供的数据库迁移产品,支持异构RDBMS与YashanDB之间进行迁移评估、离线迁移、数据校验的能力。YMP提供可视化服务,用户只需通过简单的界面操作,即可完成从评估到迁移整个流程的执行与监控,实现低门槛、低成本、高效率的异构数据库迁移。
2.2产品功能
2.2.1 迁移评估
-
提前自动评估元数据迁移代价及可行性
-
预估数据迁移时间、评估风险及可行性
-
在线/离线评估,统计并生成评估报告
-
一站式完成数据库迁移方案设计,支撑自动化迁移
2.2.2 元数据迁移
-
自动生成DDL语法
-
PL/SQL一键自动转换
-
支持源库自动抽取或手工导入
-
提升迁移效率,降低人力投入成本
2.2.3 数据迁移
-
异构数据库元数据自动迁移,全量/增量
-
支持传统离线方式,在线直连不停机方式
-
支持元数据兼容映射
-
全库/单表/批量/对象级灵活任务管理和调度
-
并行高速迁移调度
2.2.4 数据校验
-
支持对象校验/数据校验/全量校检
-
数据支持统计校验、抽样校验和精确校验
-
快速准确给出校验结果,确保迁移结果正确性和可靠性
-
可自动校检/实时校检/随时校检
2.3产品架构
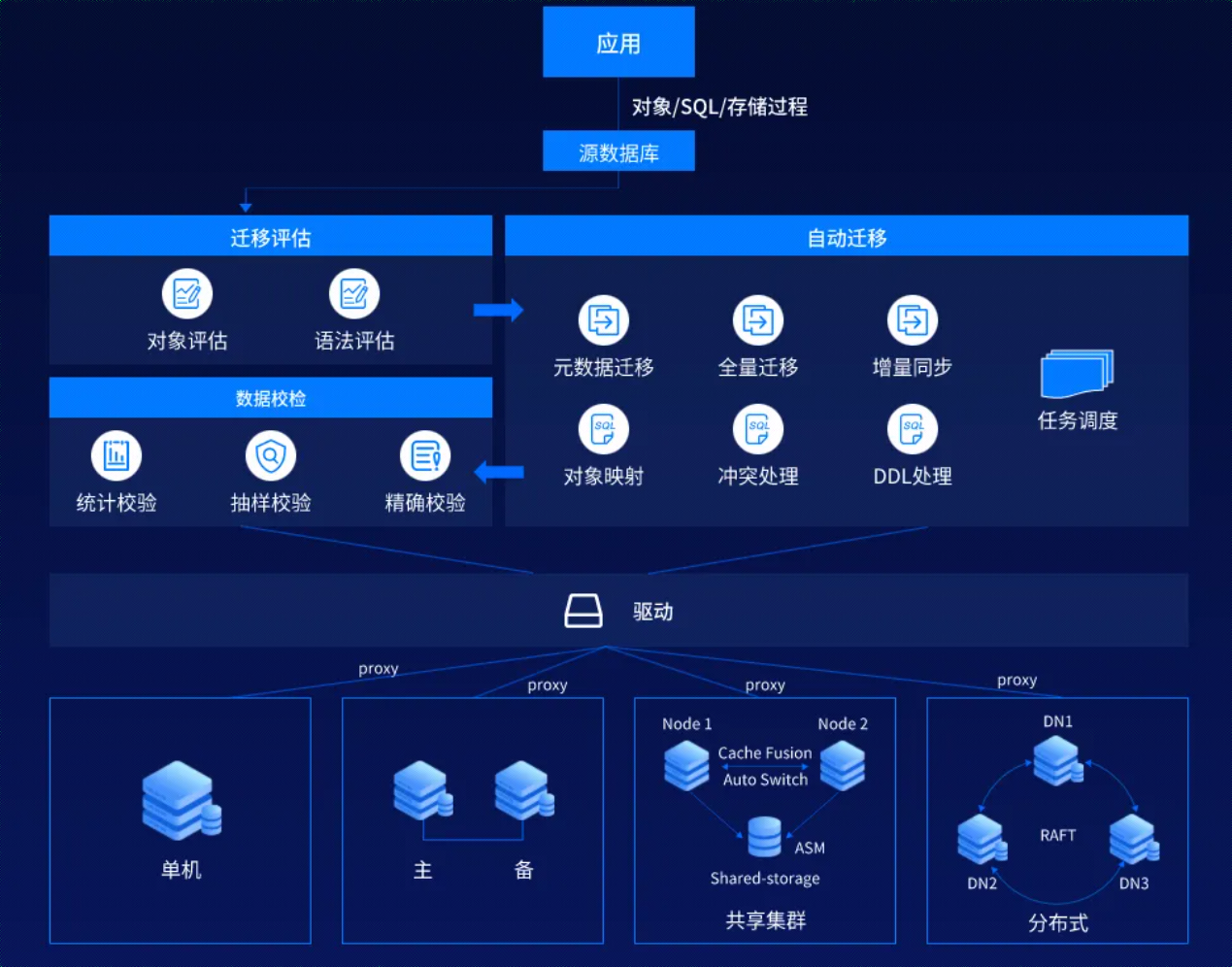
2.4产品规格
2.4.1 数据库版本支持
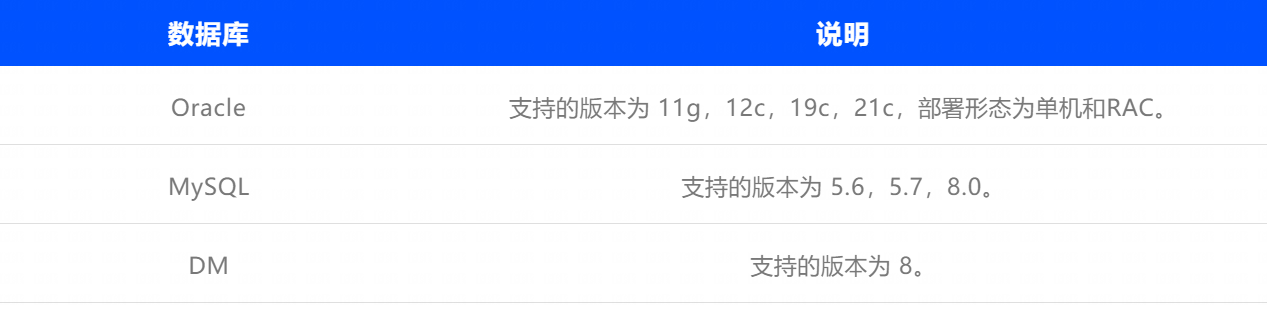
2.4.2 数据类型支持

三、本次体验环境说明
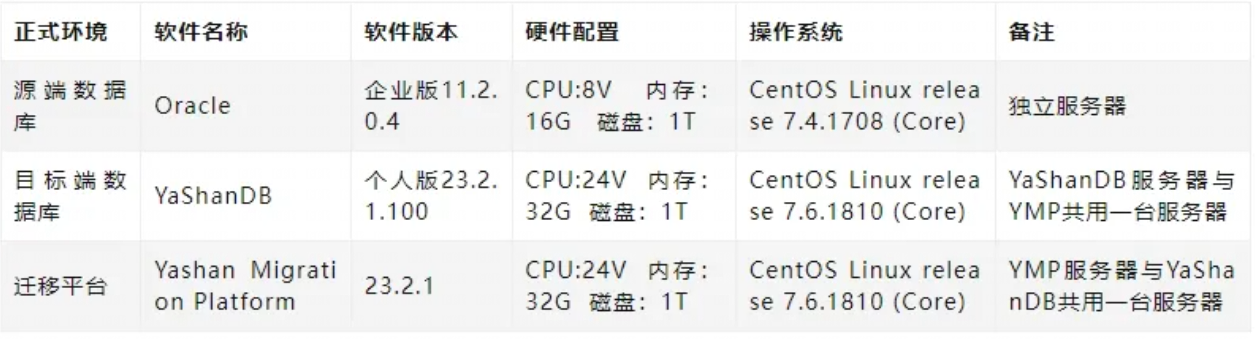
四、YMP部署
4.1安装前准备
4.1.1 操作系统参数调整
# 查看最大用户线程数 # ulimit -u# 执行如下命令使最大用户线程数临时生效,重启后无效 # ulimit -u 65536# 执行执行如下命令将最大用户线程数写入/etc/security/limits.conf文件,重启后参数永久生效
# echo "
# * soft nproc 65536
# * hard nproc 65536 # " >> /etc/security/limits.conf#使参数立即生效 # sysctl -p
4.1.2 防火墙设置
如下为YMP默认使用端口

我们只需要放行8090管理平台web访问端口即可。
查看防火墙放行情况:
# firewall-cmd --zone=public --list-ports
防火墙放行8090端口:
# 添加(–permanent 永久生效,没有此参数重启后失效) # firewall-cmd --zone=public --add-port=8090/tcp --permanent# 重新载入 # firewall-cmd --reload# 查看 # firewall-cmd --zone=public --query-port=8090/tcp如需删除请使用如下命令:# 删除已添加的端口 # firewall-cmd --zone=public --remove-port=8090/tcp --permanent
4.1.3 创建YMP部署用户
# 新建YMP用户
# useradd -d /home/ymp -m ymp # passwd ymp
4.1.4 JDK环境准备
YMP仅支持在JDK8或JDK11的环境下安装。
# 以JDK安装路径为/usr/tools/jdk8为例 # vi /etc/profile
# 在文件结尾添加如下 #java_8u221
export JAVA_HOME=/usr/local/java/jdk1.8.0_221
export MAVEN_HOME=/usr/local/maven/apache-maven-3.9.6
export PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib
# 重新载入配置文件 # source /etc/profile
# 安装成功后查看JDK版本信息 # java -version

4.1.5 libaio环境准备
YMP运行需要libaio动态库。
# 查看是否已安装libaio动态库
# rpm -qa | grep libaio# 若未有版本信息打印,安装libaio
# yum install -y libaio

4.1.6 OCI环境准备
如需要使用Oracle到YashanDB的数据迁移功能,需进行OCI环境安装。
准备OCI环境需从Oracle官网下载OCI客户端并依据官网所列步骤进行安装。
(https://www.oracle.com/cn/database/technologies/instant-client/linux-x86-64-downloads.html)
YMP现仅支持OCI Version 19.19.0.0.0及以上版本。建议下载和安装的版本信息如下:
-
x86平台使用:instantclient-basic-linux.x64-19.19.0.0.0dbru.el9.zip
-
arm平台使用:instantclient-basic-linux.arm64-19.10.0.0.0dbru-2.zip
上传安装包至YMP用户/home/ymp/路径。
# 修改安装包所属用户及用户组为ymp用户 # chown ymp:ymp instantclient-basic-linux.x64-19.19.0.0.0dbru.el9.zip# 从root用户切换至ymp用户 # su - ymp# 切换至安装路径 $ cd /home/ymp# 解压OCI安装包 $ unzip instantclient-basic-linux.x64-19.19.0.0.0dbru.el9.zip
4.1.7 YashanDB环境准备
使用默认内置库时,本步骤可省略。(推荐使用内置库,比较省事)
使用外部内置库时:
-
如需一个全新的YashanDB单机环境,参考YashanDB官网文档进行安装部署。
-
如为一个已有的YashanDB单机环境,则需由DBA在该环境中执行如下脚本:
–创建一个ymp用户(以YMP_DEFAULT为例)并为其授权
create user YMP_DEFAULT IDENTIFIED BY ymppw602 DEFAULT TABLESPACE users;
GRANT ALL PRIVILEGES TO YMP_DEFAULT; GRANT DBA TO YMP_DEFAULT;
4.1.8 软件包准备
下载YMP及YashanDB安装包。
yashan-migrate-platform-v23.2.1.0-linux-x86-64.zip
yashandb-personal-23.2.1.100-linux-x86_64.tar.gz
上传安装包至YMP用户/home/ymp/路径。
#修改安装包所属用户及用户组为ymp用户
# chown ymp:ymp yashandb-personal-23.2.1.100-linux-x86_64.tar.gz
# chown ymp:ymp yashan-migrate-platform-v23.2.1.0-linux-x86-64.zip
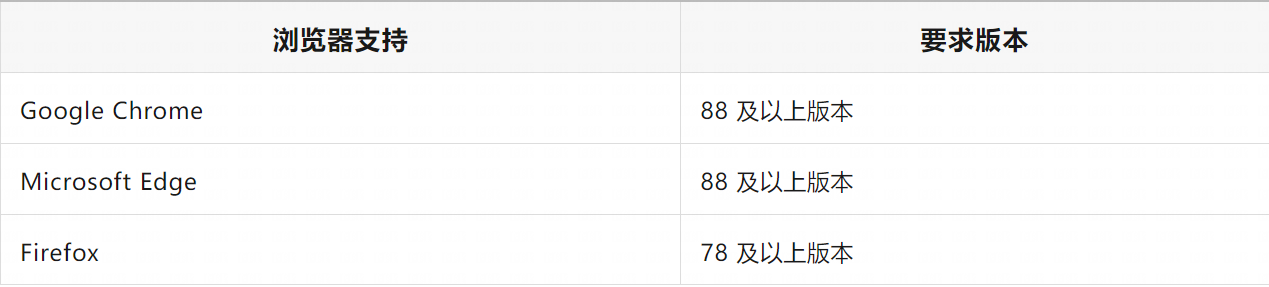
4.1.9 客户端浏览器
YMP支持浏览器Google Chrome、Microsoft Edge和Firefox,建议使用当前较新的版本。
4.2安装
4.2.1 解压安装包
# 从root用户切换至ymp用户 # su - ymp# 切换至YMP安装目录
$ cd /home/ymp/ $ unzip yashan-migrate-platform-v23.2.1.0-linux-x86-64.zip
4.2.2 安装参数调整
依据实际需要对默认内置库安装及YMP启动参数进行调整。
$ vi /home/ymp/yashan-migrate-platform/conf/db.properties默认内置库安装配置文件# db.propertiesYASDB_PASSWORD=3uplbtbnyZ5XFRtpg5F5JQ== # 默认内置库sys用户默认密码密文 YYASDB_PASSWORD=ymppw602.YASDB_PORT=8091
YASDB_CHARACTER_SET=UTF8 ## character_set optional: UTF8, ASCII, ISO88591, GBKYMP默认配置 $ vi /home/ymp/yashan-migrate-platform/conf/application.properties# YMP服务端口 server.port=8090# 用户登录后空闲过期时间,单位秒(s),默认15分钟
shiro.session.timeout=900
# YMP使用的最大堆内存,单位: GB
ymp_memory=4
# YMP使用的堆外内存,单位: GB ymp_direct_memory=2#YMP业务数据库=====
# YMP业务数据库连接信息
spring.datasource.url=jdbc:yasdb://127.0.0.1:1688/yashandb
spring.datasource.username=YMP_DEFAULT
spring.datasource.password=ymppw602
spring.datasource.largePoolSize=64M
spring.datasource.cursorPoolSize=64M
# 默认内置库表类型,默认HEAP,可选HEAP,TAC,LSC
spring.datasource.defaultTableType=HEAP
spring.datasource.openCursors=3000
spring.datasource.sharePoolSize=2G
spring.datasource.dateFormat=yyyy-mm-dd hh24:mi:ss spring.datasource.ddlLockTimeout=2#评估=====# YMP的最大并行任务数
task.parallel.max-num=500
# 预计数据迁移速度,KB/s。修改会影响评估结果预计迁移时间的大小
commons.dataMigrateSpeed=51200
# 预计对象迁移速度,number/s。修改会影响评估结果预计迁移时间的大小
commons.objMigrateSpeed=200
# 评估任务单个会话获取DDL的数量,如果Oracle性能较差,则需要降低该值
assessment.ddlCount=50
# 评估任务最多同时拥有的会话数,如果Oracle性能较差,则需要降低该值
assessment.maxThreadCount=20
# 内置库表类型是否为LSC,默认为false
isLscTable=false
# 拦截的Oracle数据源db/schema黑名单
schemaBlackList.oracle=ANONYMOUS,APEX_030200,APEX_PUBLIC_USER,APPQOSSYS,BI,CTXSYS,DBSNMP,DIP,EXFSYS,FLOWS_FILES,HR,IX,MDDATA,MDSYS,MGMT_VIEW,OE,OLAPSYS,ORACLE_OCM,ORDDATA,ORDPLUGINS,ORDSYS,OUTLN,OWBSYS,OWBSYS_AUDIT,PM,SCOTT,SH,SI_INFORMTN_SCHEMA,SPATIAL_CSW_ADMIN_USR,SPATIAL_WFS_ADMIN_USR,SYS,SYSMAN,SYSTEM,WMSYS,XDB,XS$NULL
# 拦截的MySQL数据源db/schema黑名单
schemaBlackList.mysql=information_schema,mysql,performance_schema,sys
# 拦截的dm数据源db/schema黑名单 schemaBlackList.dm=SYS,SYSDBA,SYSSSO,SYSAUDITOR,CTISYS#迁移=====# 元数据迁移过程中源端、目标端查询视图连接数。在元数据迁移过程中会有分批量的查询的动作, 需要开启多个查询连接并行查询。该参数配置元数据迁移的源端、目标端查询的并行线程数,决定了对数据库的查询最大连接数,不设置默认20
migration.parallel.query=20
# 元数据迁移过程中目标端执行创建连接数。在元数据迁移过程中会并行把对象在目标端的执行,以提升迁移效率。该参数配置元数据迁移的目标端DDL执行的并行线程数,决定了连接数据库的执行最大连接数,不设置默认20。migration.parallel.query和migration.parallel.execute的连接总和,是最终迁移过程中所有的目标端数据库连接数。
migration.parallel.execute=20
# 创建索引是否使用并行参数,true/TRUE:使用,false/FALSE:不使用
migration.parallel.createIndexUseParallel=true
# 索引创建的并行度,需要考虑migration.parallel.execute。例:migration.parallel.execute:10,migration.parallel.index: 5,表示,同时10个连接在并行建索引,每个索引的并行度是5(CREATE INDEX XXX PARALLEL 5)。不填默认CPU核数。
migration.parallel.index=5
# 数据迁移前是否将表设为nologging,默认为false
setNoLogging=false
# 导出oracle时使用的导出方式,支持 [dts, jdbc] 两种方式
export.oracle.tool=dts
# 导出时每个csv文件的行数
export.csv.exportRowsEveryFile=2000000
# 迁移成功时候是否删除csv文件
export.csv.isRemoveCsvFileInSuccess=true
# csv文件存储路径包含对schema和table的拼接,schema名或table名中包含以上字符时,将会被替换,以避免被操作系统识别错误导致迁移失败;不过这可能会使某些表(比如AA$与AA.)在替换后使用的csv文件存储路径相同,导致迁移失败(No such file or directory),可以通过重新迁移失败表来解决
export.csv.path.replacement.from=\ /’."*$
/dev/sda4 926G 36G 891G 4% /
# YMP服务端口 server.port=8090# 用户登录后空闲过期时间,单位秒(s),默认15分钟
shiro.session.timeout=900
# YMP使用的最大堆内存,单位: GB
ymp_memory=4
# YMP使用的堆外内存,单位: GB ymp_direct_memory=2#YMP业务数据库=====
# YMP业务数据库连接信息
spring.datasource.url=jdbc:yasdb://172.16.60.219:1688/yashandb
spring.datasource.username=YMP_DEFAULT
spring.datasource.password=ymppw602
spring.datasource.largePoolSize=64M
spring.datasource.cursorPoolSize=64M
# 默认内置库表类型,默认HEAP,可选HEAP,TAC,LSC
spring.datasource.defaultTableType=HEAP
spring.datasource.openCursors=3000
spring.datasource.sharePoolSize=2G
spring.datasource.dateFormat=yyyy-mm-dd hh24:mi:ss spring.datasource.ddlLockTimeout=2#评估=====# YMP的最大并行任务数
task.parallel.max-num=500
# 预计数据迁移速度,KB/s。修改会影响评估结果预计迁移时间的大小
commons.dataMigrateSpeed=51200
# 预计对象迁移速度,number/s。修改会影响评估结果预计迁移时间的大小
commons.objMigrateSpeed=200
# 评估任务单个会话获取DDL的数量,如果Oracle性能较差,则需要降低该值
assessment.ddlCount=50
# 评估任务最多同时拥有的会话数,如果Oracle性能较差,则需要降低该值
assessment.maxThreadCount=20
# 内置库表类型是否为LSC,默认为false
isLscTable=false
# 拦截的Oracle数据源db/schema黑名单
# 拦截的MySQL数据源db/schema黑名单
schemaBlackList.mysql=information_schema,mysql,performance_schema,sys
# 拦截的dm数据源db/schema黑名单 schemaBlackList.dm=SYS,SYSDBA,SYSSSO,SYSAUDITOR,CTISYS#迁移=====# 元数据迁移过程中源端、目标端查询视图连接数。在元数据迁移过程中会有分批量的查询的动作, 需要开启多个查询连接并行查询。该参数配置元数据迁移的源端、目标端查询的并行线程数,决定了对数据库的查询最大连接数,不设置默认20
migration.parallel.query=20
# 元数据迁移过程中目标端执行创建连接数。在元数据迁移过程中会并行把对象在目标端的执行,以提升迁移效率。该参数配置元数据迁移的目标端DDL执行的并行线程数,决定了连接数据库的执行最大连接数,不设置默认20。migration.parallel.query和migration.parallel.execute的连接总和,是最终迁移过程中所有的目标端数据库连接数。
migration.parallel.execute=20
# 创建索引是否使用并行参数,true/TRUE:使用,false/FALSE:不使用
migration.parallel.createIndexUseParallel=true
# 索引创建的并行度,需要考虑migration.parallel.execute。例:migration.parallel.execute:10,migration.parallel.index: 5,表示,同时10个连接在并行建索引,每个索引的并行度是5(CREATE INDEX XXX PARALLEL 5)。不填默认CPU核数。
migration.parallel.index=5
# 数据迁移前是否将表设为nologging,默认为false
setNoLogging=false
# 导出oracle时使用的导出方式,支持 [dts, jdbc] 两种方式
export.oracle.tool=dts
# 导出时每个csv文件的行数
export.csv.exportRowsEveryFile=2000000
# 迁移成功时候是否删除csv文件
export.csv.isRemoveCsvFileInSuccess=true
# csv文件存储路径包含对schema和table的拼接,schema名或table名中包含以上字符时,将会被替换,以避免被操作系统识别错误导致迁移失败;不过这可能会使某些表(比如AA$与AA.)在替换后使用的csv文件存储路径相同,导致迁移失败(No such file or directory),可以通过重新迁移失败表来解决
export.csv.path.replacement.from=\ /’."*$
# 发生csv文件存储路径字符替换时(详见export.csv.path.replacement.from),指定替换的目标字符或字符串
export.csv.path.replacement.to=_
# 导出时大表拆分的个数
export.table.splitCount=5
# 导出时触发大表拆分的行数
export.table.splitConditionCount=10000000
# 导出时触发大表拆分的表大小(G)
export.table.splitConditionSize=5
# 导出时带lob字段大表拆分的个数
export.lobTable.splitCount=5
# 导出时触发带lob字段大表拆分的行数
export.lobTable.splitConditionCount=1000000
# 导出时触发带lob字段大表拆分的表大小(G)
export.lobTable.splitConditionSize=5
# 使用jdbc导出时每个csv文件的最大行数
export.jdbc.thresholdForSplittingFileLines=5000000
# 使用jdbc导出时每个csv文件的最大大小(M)
export.jdbc.thresholdForSplittingFileSize=3072
# #yasldr More References: http://doc.yashandb.com/yashandb/22.2/zh/%E5%B7%A5%E5%85%B7%E6%89%8B%E5%86%8C/yasldr/yasldr%E4%BD%BF%E7%94%A8%E6%8C%87%E5%AF%BC.html
# yasldr导入时的并行度
import.degree_of_parallelism=16
# yasldr导入时每批次的CSV数据行数
import.batch_size=2048
# yasldr导入方式,包括BASIC方式和BATCH方式
import.mode=BATCH
import.SENDERS=7 import.CSV_CHUNK_SIZE=128#校验=====# 校验任务限制每个数据源支持的最大连接数
checkTask.datasource.max-connection=500
# 校验任务获取连接超时时间,单位:ms
checkTask.datasource.connection-timeout=10000
# 校验任务获取的连接池中维持的最小连接数
checkTask.datasource.minimum-idle=0
# 校验任务的最大并行任务数
checkTask.task.parallel.max-num=20
# 校验任务的子任务的最大并行任务数,即一个任务多少个表在同时校验
checkTask.subTask.parallel.max-num=200
# 校验任务的全量校验对FLOAT数据类型的校验精度
checkTask.checkFloatPrecision=6
# 校验任务的数据类型映射有一边是char数据类型就移除数据右侧空格进行对比 checkTask.isRemoveCharBlank=true
4.2.3 执行安装
我这里采用的是安装默认内置库和OCI客户端并启动YMP
更改内置库SYS用户默认密码(可选)
进入安装目录执行更改密码命令,以yasdb_123为例:
$ cd /home/ymp/yashan-migrate-platform/ $ sh bin/ymp.sh password --sys yasdb_123# 进入安装目录执行安装命令
$ cd /home/ymp/yashan-migrate-platform/ $ sh bin/ymp.sh install --db /home/ymp/yashandb-personal-23.2.1.100-linux-x86_64.tar.gz --path /home/ymp/instantclient_19_19
4.2.4 查看运行状态
$ cd /home/ymp/yashan-migrate-platform/ [ymp@localhost yashan-migrate-platform]$ sh bin/ymp.sh statusYMP is running, pid is 240743.
Built-in database is used, pid is 240616. [ymp@localhost yashan-migrate-platform]$
4.2.5 查看版本
[ymp@localhost yashan-migrate-platform]$ sh bin/ymp.sh -v
Yashan-migrate-platform version: Release v23.2.1.0
YashanDB SQL Personal Edition Release 23.2.1.100 x86_64
YashanDB Loader Personal Edition Release 23.2.1.100 x86_64 2d13f1d [ymp@localhost yashan-migrate-platform]$
4.2.6 访问YMP
访问方式:http://IP:PORT/,PORT默认8090,初始账户名和密码是(admin/admin)。首次登录会提示修改密码。

4.3卸载
$ cd /home/ymp/yashan-migrate-platform/ $ sh bin/ymp.sh uninstall# 使用uninstall功能时可携带-f参数,强制清理环境 $ sh bin/ymp.sh uninstall -f# 验证
$ ps -ef | grep yas ymp 20840 6322 0 10:02 pts/14 00:00:00 grep --color=auto yas
-
卸载YMP时,会删除默认内置库(自定义内置库不受影响)并清空db和yashan_client文件夹,若想替换数据库版本,请在卸载后重新部署。
-
强制清理功能会使用kill -9强制清理当前用户下YMP启动的所有进程,并删除内置库及yasldr文件夹下所有内容,请谨慎使用,建议在专用的YMP用户下使用。
-
最后还需要手动删除~/.bashrc中与YashanDB有关的环境变量。
4.4启动与停止
4.4.1 启动YMP
默认内置库启动YMP:
$ cd /home/ymp/yashan-migrate-platform/$ sh bin/ymp.sh start
自定义内置库启动YMP:
$ cd /home/ymp/yashan-migrate-platform/$ sh bin/ymp.sh startnodb
4.4.2 停止YMP
默认内置库停止YMP:
$ cd /home/ymp/yashan-migrate-platform/$ sh bin/ymp.sh stop
自定义内置库停止YMP:
$ cd /home/ymp/yashan-migrate-platform/$ sh bin/ymp.sh stopnodb
4.4.3 重启YMP
默认内置库重启YMP:
$ cd /home/ymp/yashan-migrate-platform/$ sh bin/ymp.sh restart
自定义内置库重启YMP:
$ cd /home/ymp/yashan-migrate-platform/$ sh bin/ymp.sh restartnodb
Caution:
在任务运行过程中停止或重启YMP会造成当前阶段任务运行失败,需重新开始当前阶段任务。
五、数据迁移
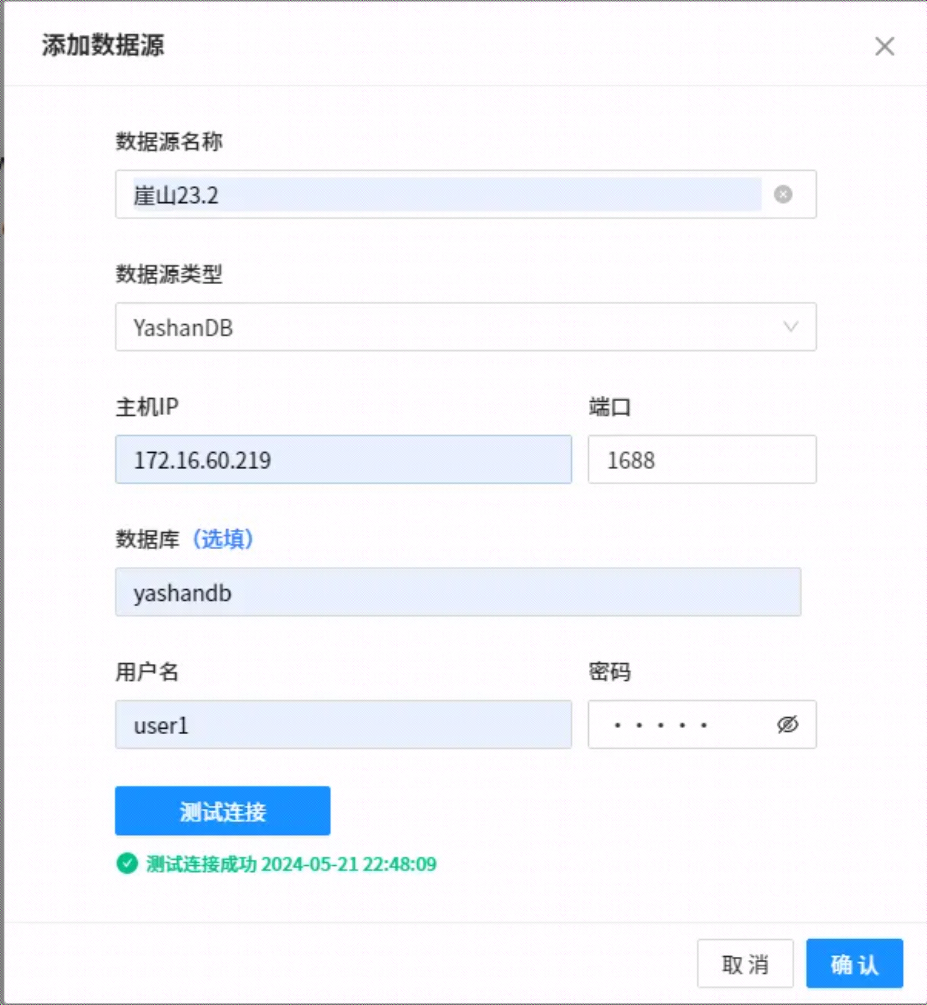
5.1创建数据源
5.1.1 创建Oracle数据库数据源并测试

5.1.2 创建YashanDB数据库数据源并测试
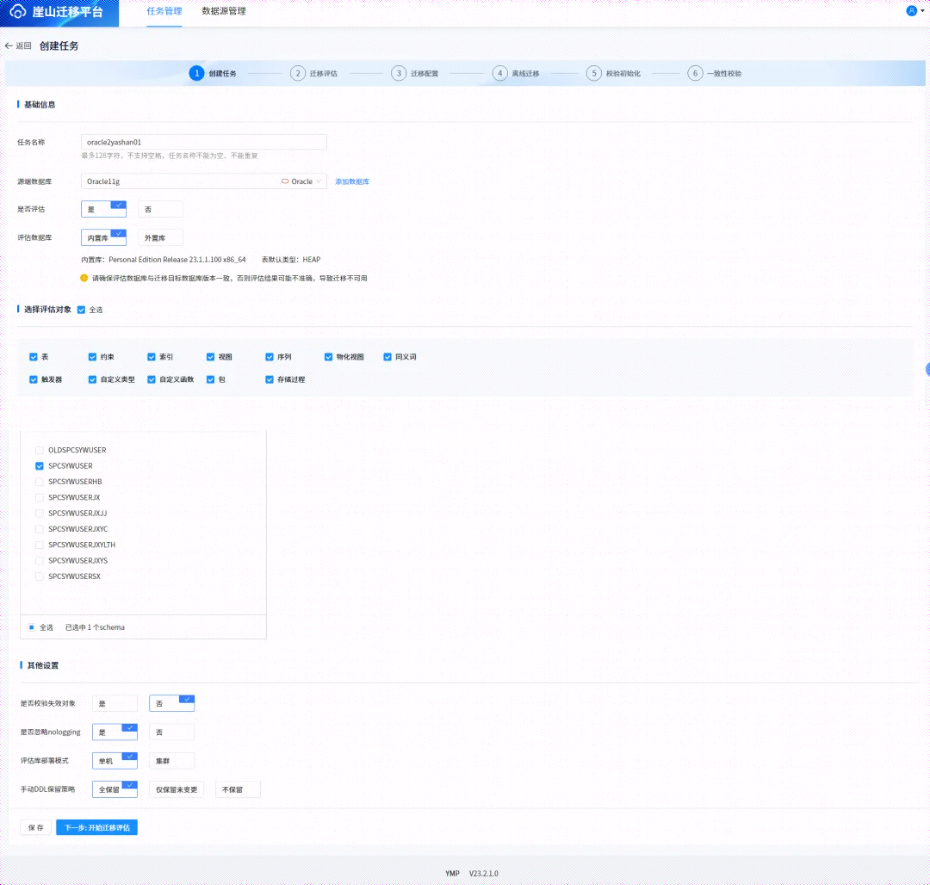
5.2创建迁移任务
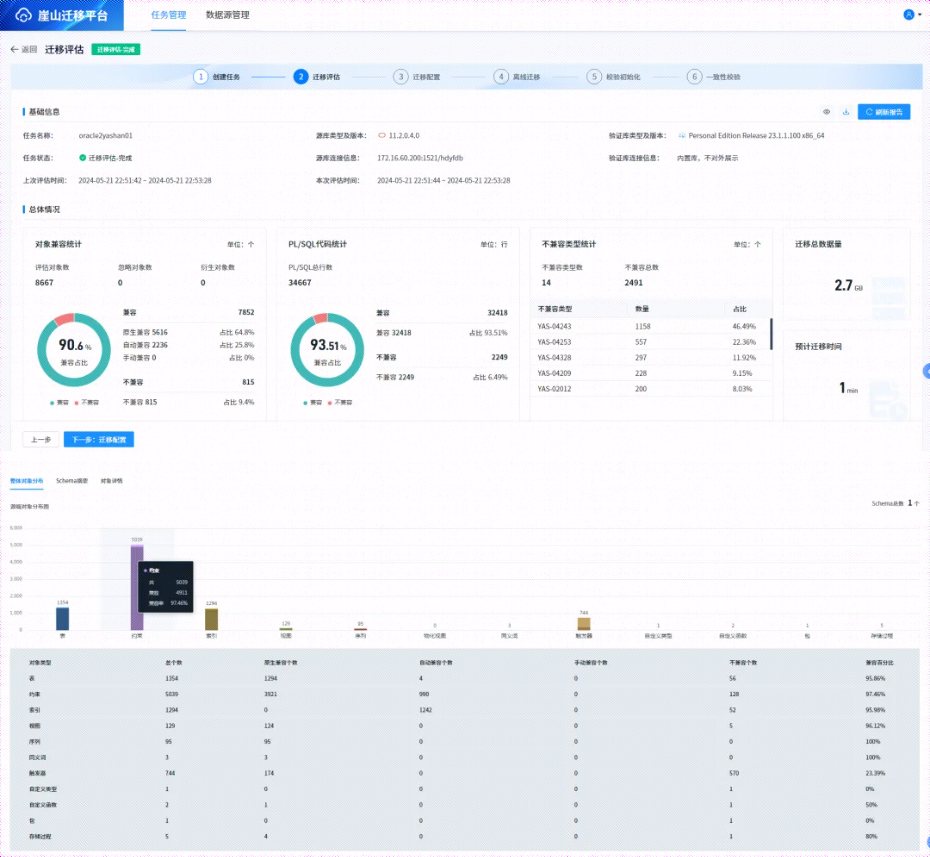
5.3评估迁移

评估完成结果如下:
5.4迁移配置
评估迁移完毕后点击下一步迁移配置:
评估兼容非百分百的话需要在对象浏览里将所有不兼容数据进行过滤,选择忽略,然后点击重新刷新报告。
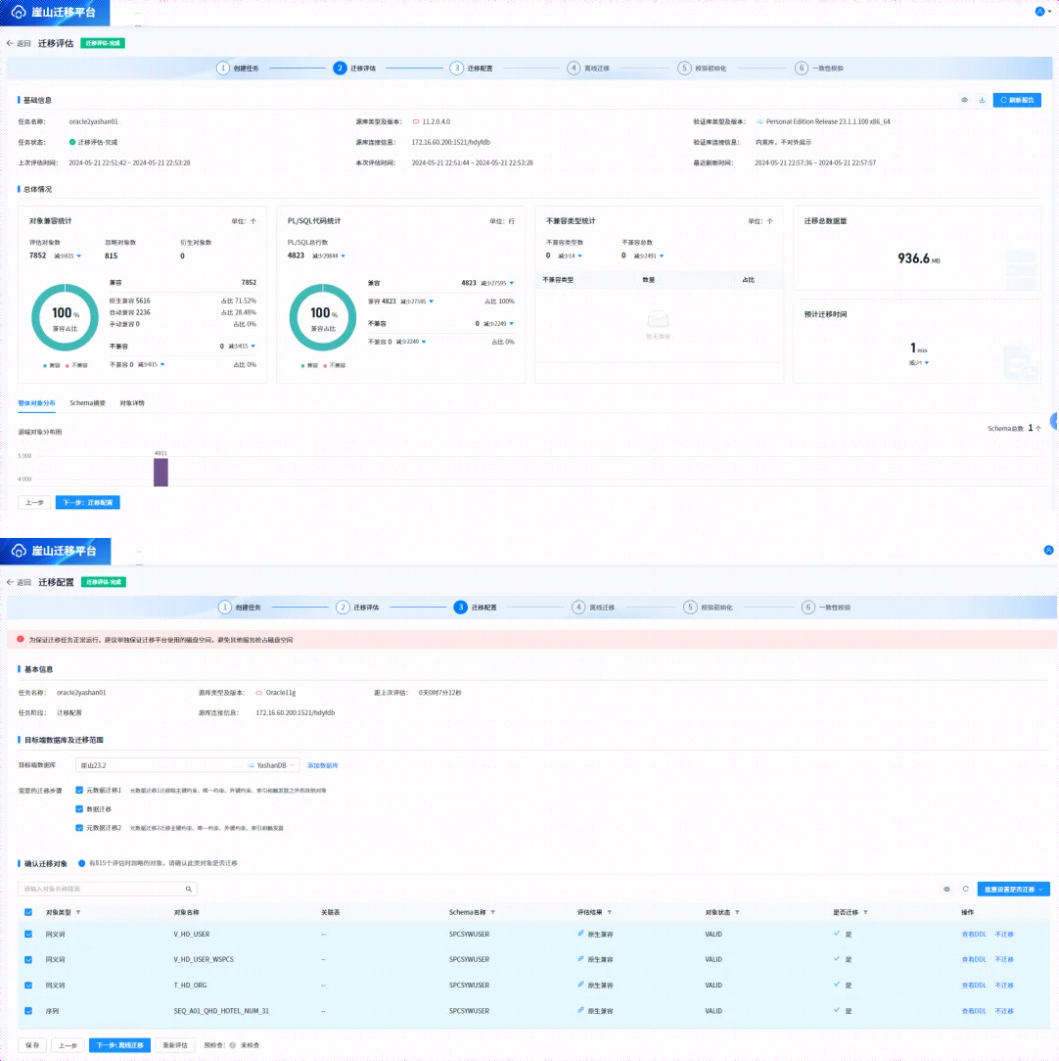
迁移对象可以根据实际情况进行选择。
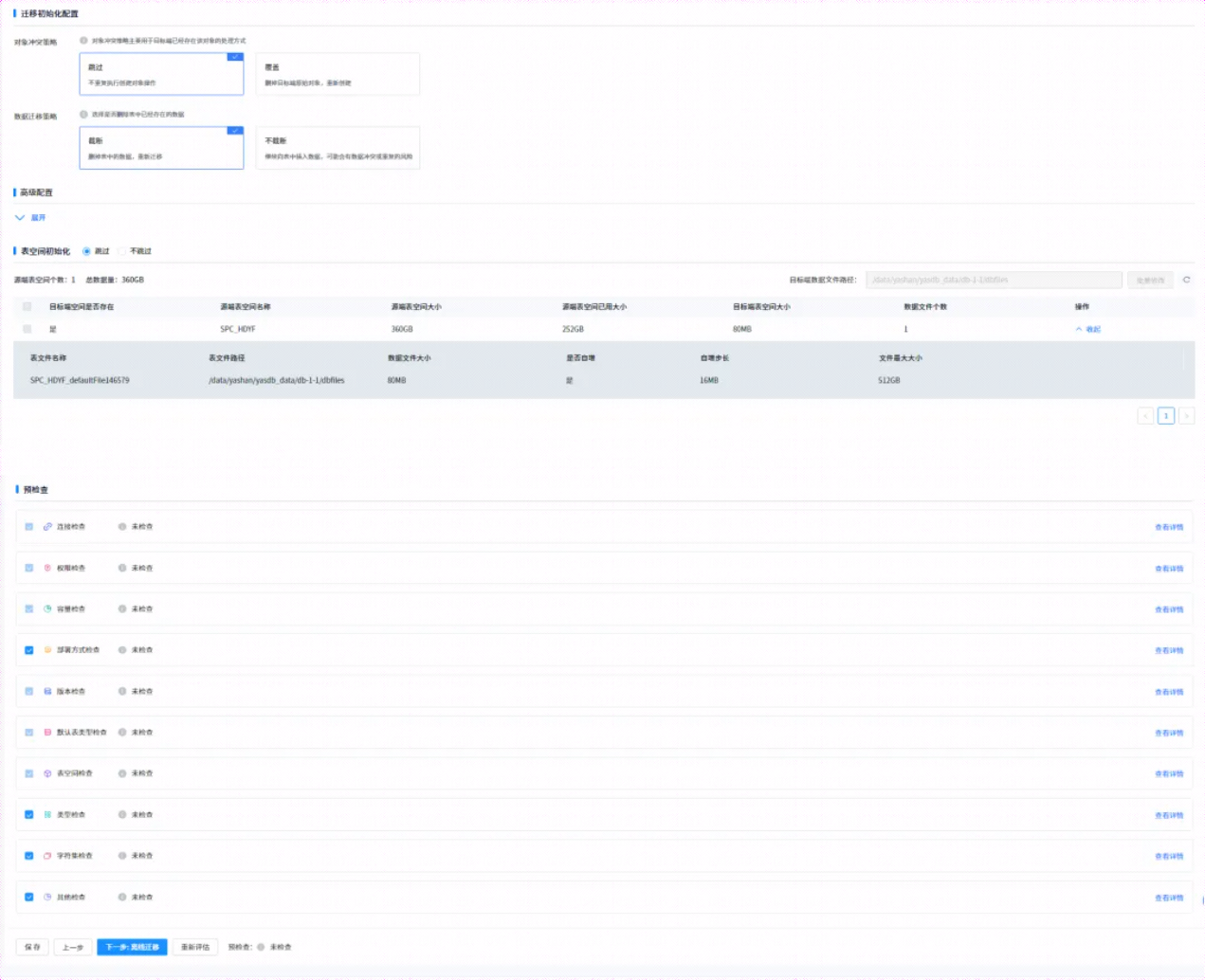
点击下一步开始数据迁移。
5.5开始迁移
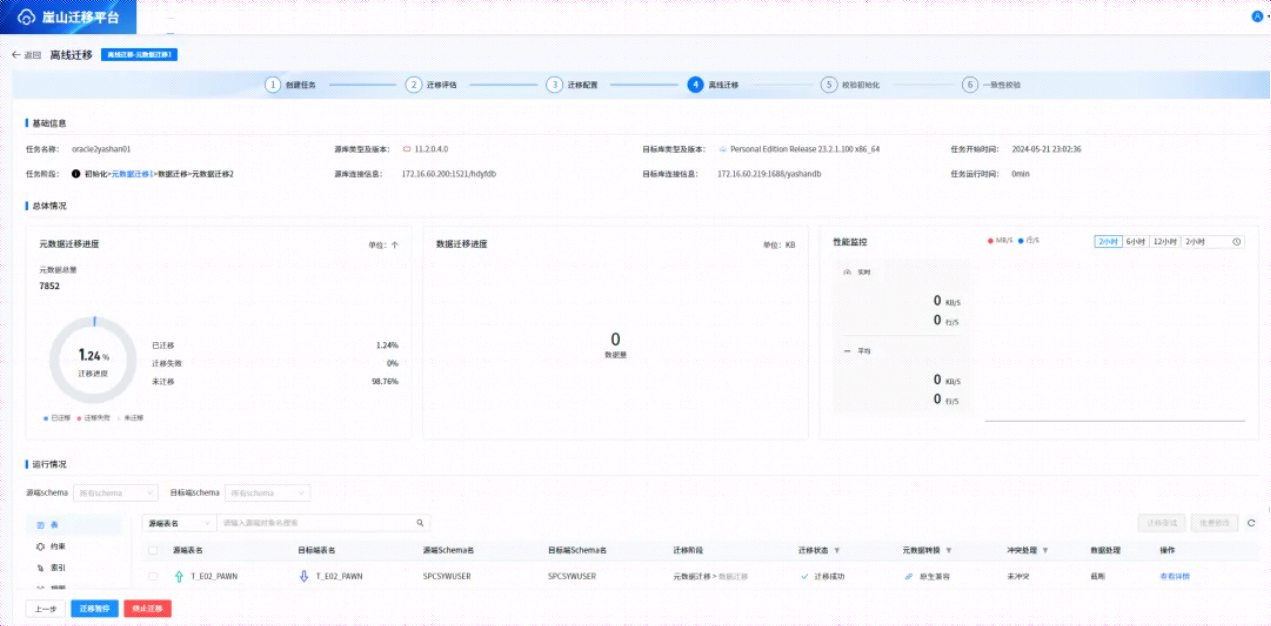
迁移完毕后结果如下:

可以发现有一部分数据没有迁移成功。
5.6一致性校验
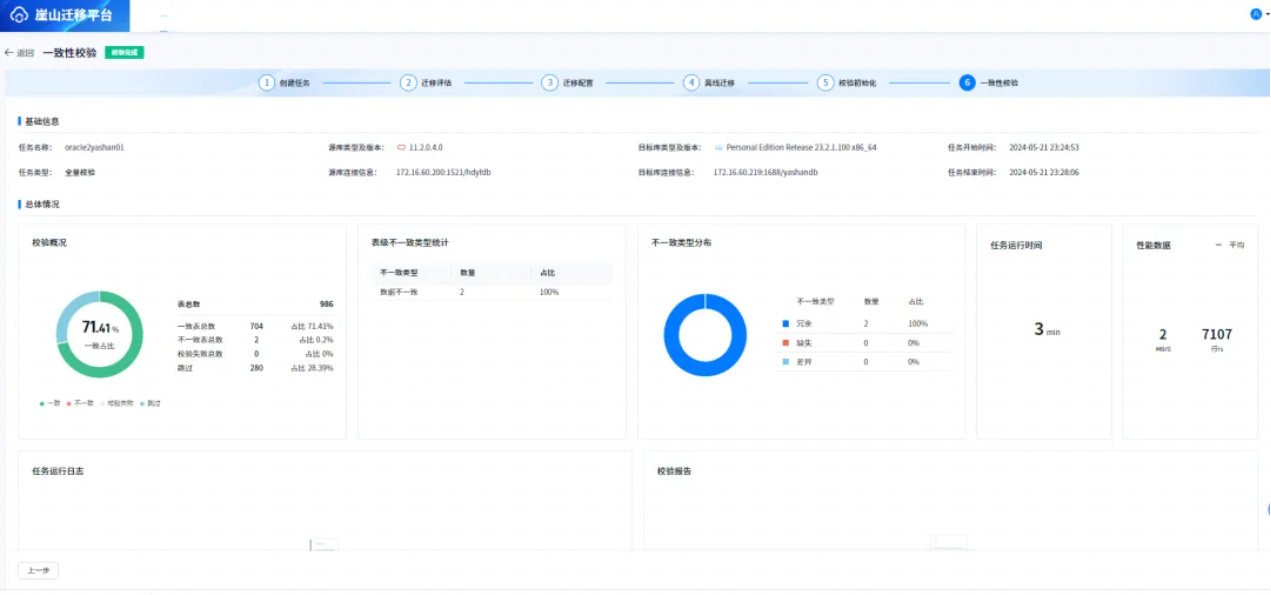
六、遇到的问题与解决过程
6.1遇到的问题
安装过程中使用了外置库,然后外置库和目标业务库是同一套数据,导致各种冲突现象,具体如下:
1.评估缓慢,不完全兼容的情况下忽略不兼容对象,刷下兼容报告时会报如下错误。

2.目标库数据源老提示账户锁定,反复解锁,反复锁定。

3.过段时间提示用户名或密码无效,新创建用户后进行了dba授权,过一会会被系统自动删除。

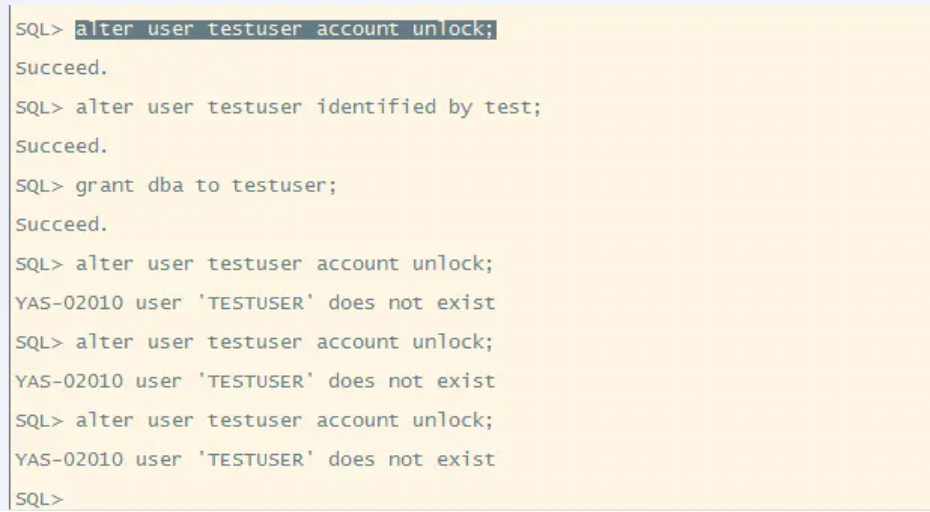
6.2解决过程
1.将YMP单独部署在一台服务器上,使用默认内置库。
2.修改默认内置库为外置库,外置库不能和目标迁移数据库是一个实例。
在此特别感谢崖山官方的李梦莹大拿,凌晨0:30帮我把问题解决了
小崖有话说🤩
历时一个月的【迁移体验官】活动已圆满收官~小伙伴们提到的大部分问题已得到了修复,最新的版本崖山迁移平台YMP已挂网。(下载链接👉https://download.yashandb.com/download)
此外,新的征文活动已开启,可点击此处进行跳转,欢迎小伙伴们体验后继续提出宝贵的反馈和建议~



















