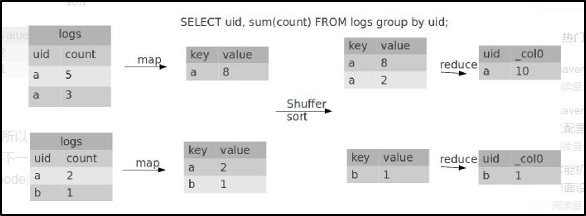
# Datawhale AI 夏令营
夏令营手册:从零入门 AI 逻辑推理
比赛:第二届世界科学智能大赛逻辑推理赛道:复杂推理能力评估
代码运行平台:魔搭社区
比赛任务
本次比赛提供基于自然语言的逻辑推理问题,涉及多样的场景,包括关系预测、数值计算、谜题等,期待选手通过分析推理数据,利用机器学习、深度学习算法或者大语言模型,建立预测模型。
任务:构建一个能够完成推理任务的选择模型
- 运用机器学习模型或者深度学习模型解决推理问题。或者利用训练集数据对开源大语言模型进行微调。
数据集介绍
初赛数据集为逻辑推理数据,其中训练集中包含500条训练数据,测试集中包含500条测试数据。每个问题包括若干子问题,每个子问题为单项选择题,选项不定(最多5个)。目标是为每个子问题选择一个正确答案。推理答案基于闭世界假设(closed-world assumption),即未观测事实或者无法推断的事实为假。
具体的,每条训练数据包含 content, questions字段,其中content是题干,questions为具体的子问题。questions是一个子问题列表,每个子问题包括options和answer字段,其中options是一个列表,包含具体的选项,按照ABCDE顺序排列,answer是标准答案。
数据集格式如下:
round1_train_data.jsonl: 每一行代表一条反应
{'id': 'round_train_data_001',
'problem': '有一个计算阶乘的递归程序。该程序根据给定的数值计算其阶乘。以下是其工作原理:\n\n当数字是0时,阶乘是1。\n对于任何大于0的数字,其阶乘是该数字乘以其前一个数字的阶乘。\n根据上述规则,回答以下选择题:','questions': [{'question': '选择题 1:\n3的阶乘是多少?\n','options': ('3', '6', '9', '12'),'answer': 'B'},{'question': '选择题 2:\n8的阶乘是多少?\n','options': ('5040', '40320', '362880', '100000'),'answer': 'B'},{'question': '选择题 3:\n4的阶乘是多少?\n','options': ('16', '20', '24', '28'),'answer': 'C'},{'question': '选择题 4:\n3的阶乘是9吗?\n','options': ('是', '否'),'answer': 'B'}]
}
测试集 round1_test_data.jsonl 不包含answer字段。
跑通baseline
模型使用阿里云的大模型API,调用模型API来运行,运行环境使用魔搭社区,好处是可以无需在本地环境部署大模型和安装Python环境,不需要担心硬件等资源问题,可以进行快速开发

编写Prompt
这里定义了一个生成推理问题提示的模板,并使用标准化模式输出,方便后续处理和分析。
# 这里定义了prompt推理模版def get_prompt(problem, question, options):options = '\n'.join(f"{'ABCDEFG'[i]}. {o}" for i, o in enumerate(options))prompt = f"""你是一个逻辑推理专家,擅长解决逻辑推理问题。以下是一个逻辑推理的题目,形式为单项选择题。所有的问题都是(close-world assumption)闭世界假设,即未观测事实都为假。请逐步分析问题并在最后一行输出答案,最后一行的格式为"答案是:A"。题目如下:### 题目:
{problem}### 问题:
{question}
{options}
"""# print(prompt)return prompt
数据处理
has_complete_answer 检查所有问题是否都有答案answer。
filter_problems是对问题进行去重和保证每个问题都有完整的答案。创建一个结果列表result和问题集合problem_set,遍历输入的数据,对每一条数据都检查其"problem"是否在problem_set内,当问题存在,在结果列表result中找到对应的问题,并通过has_complete_answer检查是否有完整答案,如果有则用当前的item替换已存在的item;当问题不存在,如果问题有完整答案,则将其添加到 result,而问题则添加到 problem_set,最终返回过滤后的结果列表result。
def has_complete_answer(questions):# 这里假设完整答案的判断逻辑是:每个question都有一个'answer'键for question in questions:if 'answer' not in question:return Falsereturn Truedef filter_problems(data):result = []problem_set = set()for item in data:# print('处理的item' ,item)problem = item['problem']if problem in problem_set:# 找到已存在的字典for existing_item in result:if existing_item['problem'] == problem:# 如果当前字典有完整答案,替换已存在的字典if has_complete_answer(item['questions']):existing_item['questions'] = item['questions']existing_item['id'] = item['id']breakelse:# 如果当前字典有完整答案,添加到结果列表if has_complete_answer(item['questions']):result.append(item)problem_set.add(problem)return result
提交结果
初始提交的结果为0.6514,在研究代码后,通过更换其他模型,同为QWEN模型,结果得到了显著提高,说明模型的大小对于推理结果的好坏有至关重要的作用。

总结
模型开始使用baseline的 qwen2-7b-instruct 模型,后续更改使用 qwen-plus,在不更改baseline代码的情况下,仅仅依靠模型性能就能将模型的推理能力提升到一个较高的水平,但是这种提升只能说明模型能力的强弱,不能证明调优的好坏,后续计划使用RAG和Agent技术对模型进行推理能力的定向调优,提升模型的推理能力。