目录
一、项目介绍
(一) 项目背景
(二) 项目介绍
二、系统实现
(一) 爬虫
1. 实现步骤
一、爬取字段
二、分析页面
三、具体实现
2. 爬虫结果
系列文章
Python升级打怪—Django入门
Python升级打怪—Scrapy零基础小白入门
实现技术
- Scrapy
- Django
- Echarts
一、项目介绍
(一) 项目背景
在信息技术高速发展的今天,数据已经成为决策的重要依据。旅游业作为服务性行业的重要支柱,其数据资源尤为丰富。去哪儿网作为中国领先的在线旅游平台,拥有大量的景点数据,这些数据对于分析旅游市场动态、游客行为以及景点管理策略等具有极高的价值。通过对去哪儿网景点数据的分析,我们可以了解游客的偏好、旅游市场的趋势以及景点的竞争力等信息。同时,数据可视化可以将复杂的数据信息以直观、易懂的方式呈现出来,有助于决策者更好地理解数据背后的含义
(二) 项目介绍
本项目采用Scray框架爬取去哪儿网的景点数据以及景点的评论数据,将爬取到的数据存储为csv,再通过Django Web框架技术将数据存储到Mysql,然后通过编写接口、分析数据,通过接口将数据返回前端,前端结合Echarts制作可视化表
二、系统实现
(一) 爬虫
爬取网址:去哪儿网
1. 实现步骤
一、爬取字段
本项目爬取的数据分为两部分:【景点数据、景点评论数据】,并将爬取的数据分别存入两个CSV文件中
景点字段
# 景点名称
name = scrapy.Field()
# 景点价格
price = scrapy.Field()
# 所属城市
province = scrapy.Field()
# 评级
star = scrapy.Field()
# 地址
address = scrapy.Field()
# 详情url
detail_url = scrapy.Field()
# 评论数
comment_total = scrapy.Field()
# 短评
short_intro = scrapy.Field()
# 详评
detail_intro = scrapy.Field()
# 封面
cover = scrapy.Field()
# 销售额
sale_count = scrapy.Field()
# 地区
districts = scrapy.Field()
# 评分
score = scrapy.Field()景点评论字段
# 景点名称
travel_name = scrapy.Field()
# 内容
content = scrapy.Field()
# 评论时间
date = scrapy.Field()二、分析页面
以地区为北京的景点为例子,搜索结果如下
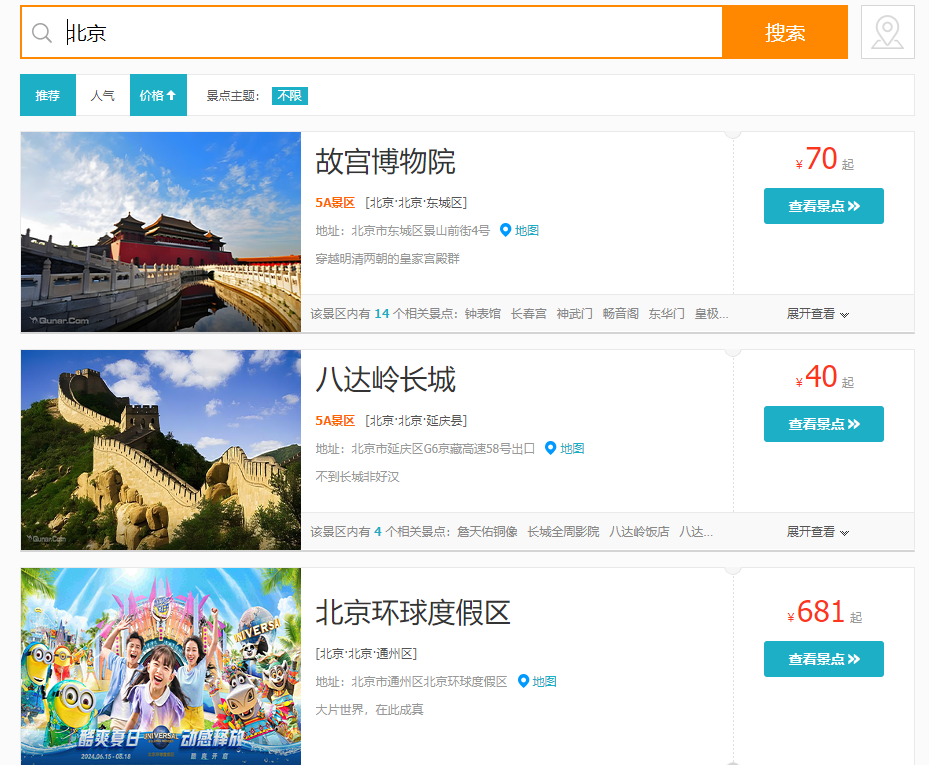
景点数据
通过分析页面得出,景点数据是通过发送Ajax请求获得,那么我们就不用解析页面,可以直接通过请求获取景点数据即可
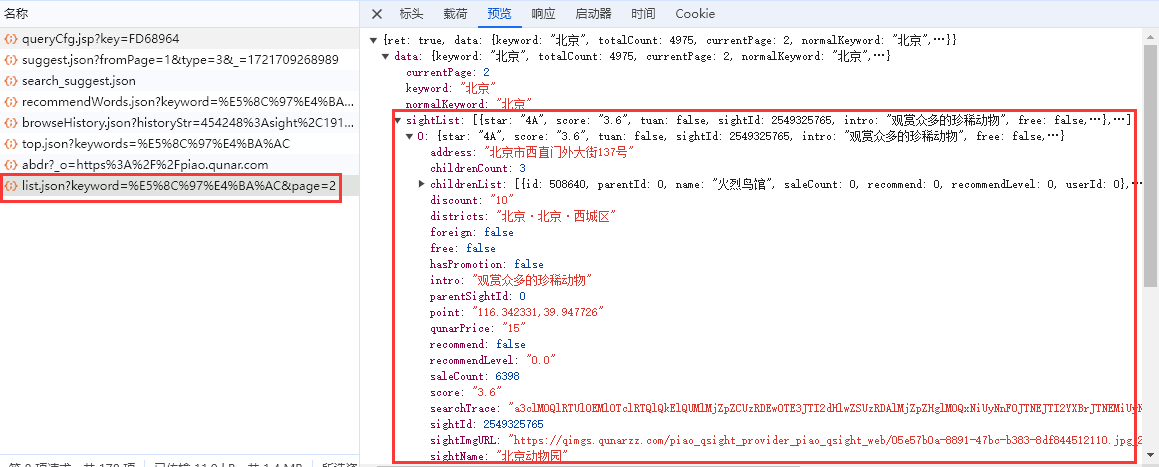
当然请求里的景点数据有些字段是没有的,需要我们进入到景点的详情页去爬取
第一个景点:故宫博物院详情页路由
故宫博物院门票,故宫博物院门票预订,故宫博物院门票价格,去哪儿网门票
第二个景点:八达岭长城详情页路由
八达岭长城门票,八达岭长城门票预订,八达岭长城门票价格,去哪儿网门票
通过对比路由地址得出
景点的详情页路由是由基本的路由地址加上景点Id拼接得出,那么在Ajax请求的景点数据字段就有景点id,
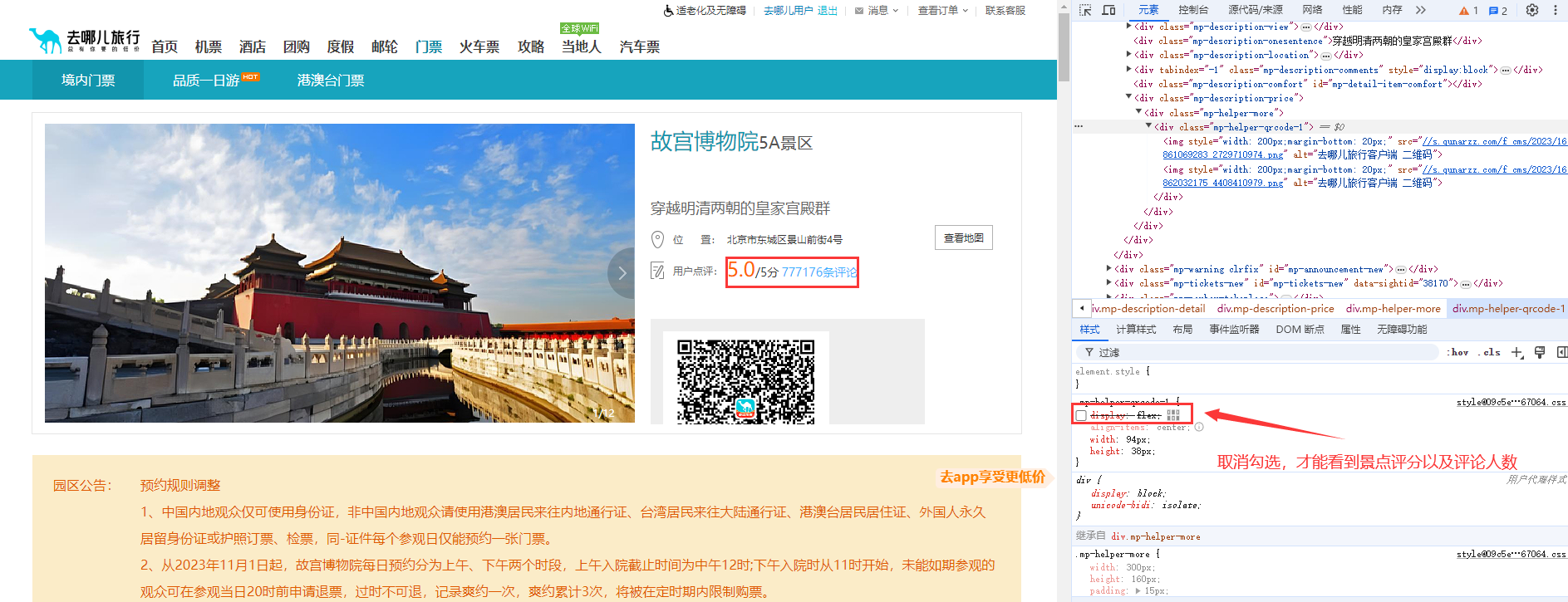
那么如果获取指定的景点详情地址,就可以通过拼接该景点id获得进入到景点详情页,解析页面,获取景点的【评分、评论人数、评论数据】
这里我们可以通过Xpath解析页面 ,获取景点的评分以及评论人数
景点评论
请求URL示例:https://piao.qunar.com/ticket/detailLight/sightCommentList.json?sightId=38170&index=2&page=2&pageSize=10&tagType=0

景点评论数据也是通过发送Ajax请求获取,但不同的是需要携带上景点的id,在这个景点的id不同于进入景点详情页的景点id,它是在景点详情页中的,在查看网页源代码中,我们也是可以找到这个id的,后面我们就可以通过页面解析得到这个id,再拼接请求地址就可以去获取景点评论数据了

三、具体实现
基础的项目搭建就不在赘述,如有不懂的请看系列文章
爬虫前必看
- 一定要设置休眠时间!!!这对网站和你都好
- 因为爬取的数据量很大,爬虫时间会很长,大家可以根据自己的需求合理改造,比如选择合适时间爬取、爬取少量城市或每个城市爬取1-2页数据等
问题一:爬取的数据(景点数据、评论数据)分开存储
可以通过scrapy框架提供的pipelines文件中解决,根据定义数据结构存储到指定文件中,还可以进行数据处理等等操作
问题二:爬取数据层层嵌套
通过前面的页面分析,我们所要爬取的数据层层嵌套,爬取起来比较麻烦,当然也是难不倒我们的
首先准备基础数据
name = "Quanar"
allowed_domains = ["piao.qunar.com"]
start_urls = ["https://piao.qunar.com/daytrip/list.htm"]# 所要爬取景点的城市
province_list = ['北京', '天津', '河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '上海', '江苏','浙江', '安徽', '福建', '江西', '山东', '河南', '湖北', '湖南', '广东','广西', '海南', '重庆', '四川', '贵州', '云南', '西藏', '陕西', '甘肃','青海', '宁夏', '新疆', '台湾', '香港', '澳门']# 城市景点列表的ajax请求网址:keyword:城市名称 page:第几页 sort:pp=》按人气排名
url = 'https://piao.qunar.com/ticket/list.json?keyword=%s®ion=&from=mpl_search_suggest&page=%s&sort=pp'
# 景点url
travel_url = 'https://piao.qunar.com/ticket/detail_%s.html'
# 景点评论url
comment_url = 'https://piao.qunar.com/ticket/detailLight/sightCommentList.json?sightId=%s&index=1&page=%s&pageSize=10&tagType=0'发起请求,获取指定城市的指定页的景点数据
def start_requests(self):# 遍历每个城市列表for index, province in enumerate(self.province_list, 1):# 每个城市爬取 多少页 数据for page in range(5):yield Request(url=(self.url % (province, page)), callback=self.parse_travel_list,meta={"province": province})return解析景点数据,拼接景点详情页地址,继续发起请求
# 解析单个城市里的多个景点数据
def parse_travel_list(self, response):# 城市名称province = response.meta['province']# 城市景点列表travel_list = response.json()['data']['sightList']for index, travel in enumerate(travel_list):try:travel_item = TravelItem()# 景点名称name = travel['sightName']print("正在爬取该页 %s 条数据,景点名称为:%s" % (str(index + 1), name))# 门票价格try:price = travel['qunarPrice']except:price = 0# 有点景点可能没有评等级,所以需要判断一下try:star = travel['star']except:star = '未评'# 详细地址address = travel['address']# 短评short_intro = travel['intro']# 封面cover = travel['sightImgURL']# 销售额sale_count = travel['saleCount']# 地区districts = travel['districts']# ======================================= 详情爬虫# 景点idsightId = travel['sightId']# 详情地址detail_url = self.travel_url % sightIdtravel_item['name'] = nametravel_item['province'] = provincetravel_item['price'] = pricetravel_item['star'] = startravel_item['address'] = addresstravel_item['short_intro'] = short_introtravel_item['cover'] = covertravel_item['sale_count'] = sale_counttravel_item['districts'] = districtstravel_item['detail_url'] = detail_url# 生成新的Request,并传递给下一个解析函数yield scrapy.Request(detail_url, callback=self.parse_travel_details, meta={'travel_item': travel_item})returnexcept:continue解析页面,获取景点的评分以及评论人数、请求景点评论所需的id,拼接获取景点评论的url,继续发起请求
# 解析单个景点里的详情def parse_travel_details(self, response):travel_item = response.meta['travel_item']name = travel_item['name']travel_detail_xpath = Selector(response)# 评论总数comment_total = travel_detail_xpath.xpath('//span[@class="mp-description-commentCount"]/a/text()')[0].get().replace('条评论', '')# 详情介绍detail_intro = travel_detail_xpath.xpath('//div[@class="mp-charact-desc"]//p/text()').get()# 评分score = travel_detail_xpath.xpath("//span[@id='mp-description-commentscore']/span/text()").get()if not score:score = 0else:score = score[0]travel_item['comment_total'] = comment_totaltravel_item['detail_intro'] = detail_introtravel_item['score'] = score# print("爬取存储的travel_item:%s" % travel_item)yield travel_item# ======================================= 评论爬虫data_sight_id = travel_detail_xpath.xpath('//div[@class="mp-tickets-new"]/@data-sightid')[0].get()comment_url = self.comment_url % (data_sight_id, 1)# 生成新的Request,并传递给下一个解析函数yield scrapy.Request(comment_url, callback=self.parse_comments, meta={"name": name})解析评论数据
# 解析单个景点里的评论
def parse_comments(self, response):try:print("正在爬取%s的评论数据" % response.meta['name'])comment_json = response.json()['data']['commentList']name = response.meta['name']for comment in comment_json:item = CommentItem()if comment['content'] != '用户未点评,系统默认好评。':item['travel_name'] = nameitem['content'] = str(comment['content'])item['date'] = comment['date']yield itemexcept:return2. 爬虫结果
整个爬虫代码结束,让我们看看爬取到结果
爬取1958个景点数据

每个景点对应评论6213条

好的,爬虫部分实现,接下来就是项目可视化,请看