Leaderboard: https://hf.co/spaces/allenai/reward-bench
Code: https://github.com/allenai/reward-bench
Dataset: https://hf.co/datasets/allenai/reward-bench
在人类偏好的强化学习(RLHF)过程中,奖励模型(Reward Model)格外重要。奖励模型通常是大模型本身并在标注好的偏好数据上进行训练,从而赋予其能够识别好坏的能力。
在RLHF过程中,Reward模型可以给予大模型生成结果的信号,基于这个信号来更新大模型参数,使得其可以进一步提高与人类的对齐能力。
一、背景
(1)Reward模型
在RLHF场景中,给定一个prompt和若干response,通过排序来表示各个response与人类偏好的程度。将其转换为prompt-chosen-rejected pair,其中chosen表示比rejected更符合人类偏好。至此,通过分类器并按照Bradley-Terry模型(排序loss)进行训练。
偏好概率定义为:
p ∗ ( y 1 > y x ∣ x ) = exp ( r ∗ ( x , y 1 ) ) exp ( r ∗ ( x , y 1 ) ) + exp ( r ∗ ( x , y 2 ) ) p^{*}(y_1>y_x|x)=\frac{\exp{(r^{*}(x, y_1))}}{\exp{(r^{*}(x, y_1))} + \exp{(r^{*}(x, y_2))}} p∗(y1>yx∣x)=exp(r∗(x,y1))+exp(r∗(x,y2))exp(r∗(x,y1))
损失函数定义为:
L ( θ , D ) = E ( x , y c h o s e n , y r e j e c t e d ) ∼ D [ log ( 1 + e r θ ( x , y r e j e c t e d ) − r θ ( x , y c h o s e n ) ) ] \mathcal{L}(\theta, \mathcal{D}) = \mathbb{E}_{(x, y_{chosen}, y_{rejected})\sim\mathcal{D}}[\log(1 + e^{r_{\theta}(x, y_{rejected}) - r_{\theta}(x, y_{chosen})})] L(θ,D)=E(x,ychosen,yrejected)∼D[log(1+erθ(x,yrejected)−rθ(x,ychosen))]
- 在训练阶段,Reward模型通常是在大模型的基础上添加一个linear层,并通过排序loss进行训练。
- 在推理阶段,模型会返回一个概率 p ( y 1 > y 2 ∣ x ) ∝ e r ( x , y 1 ) p(y_1>y_2|x)\propto \text{e}^{r(x, y_1)} p(y1>y2∣x)∝er(x,y1),表示 y 1 y_1 y1符合偏好的概率。在评测时,如果 y 1 y_1 y1的reward值比 y 2 y_2 y2大,则说明预测正确(win)。
RLHF中的Reward模型需要显式地使用大模型(policy model)和线性层来训练一个排序模型,通过这个Reward模型给予的reward得分,用强化学习(PPO)算法优化policy model的参数。即期望模型生成出高奖励回报的结果。
RLHF中的Reward模型训练模式(Bradley-Terry模型)
- 先通过人类反馈进行Pair-wise标注;
- 获得prompt下所有response的排序后,构建两两pair,使用Bradley-Terry模型的排序loss进行训练;
- Bradley-Terry模型通过pair的比较排序训练方式来获得每个response的reward。
(2)DPO模型
在DPO中,无需显式的训练一个Reward模型,待优化的大模型(policy model)本身可以直接作为奖励模型,其通过policy model的概率来作为隐式的reward。
其奖励函数可以定义为:
r ( x , y ) = β log π ( y ∣ x ) π r e f ( y ∣ x ) + β log Z ( x ) r(x, y)=\beta\log\frac{\pi(y|x)}{\pi_{ref}(y|x)} + \beta\log Z(x) r(x,y)=βlogπref(y∣x)π(y∣x)+βlogZ(x)
DPO代表的方法没有显式的奖励,而是间接使用大模型(policy model)的概率作为奖励。
在训练时,会先让policy model计算chosen和rejected respond的logits,其次基于这个logits来转换为dpo loss进行优化。
二、Reward Benchmark
整个评估的方法流程如下图所示:
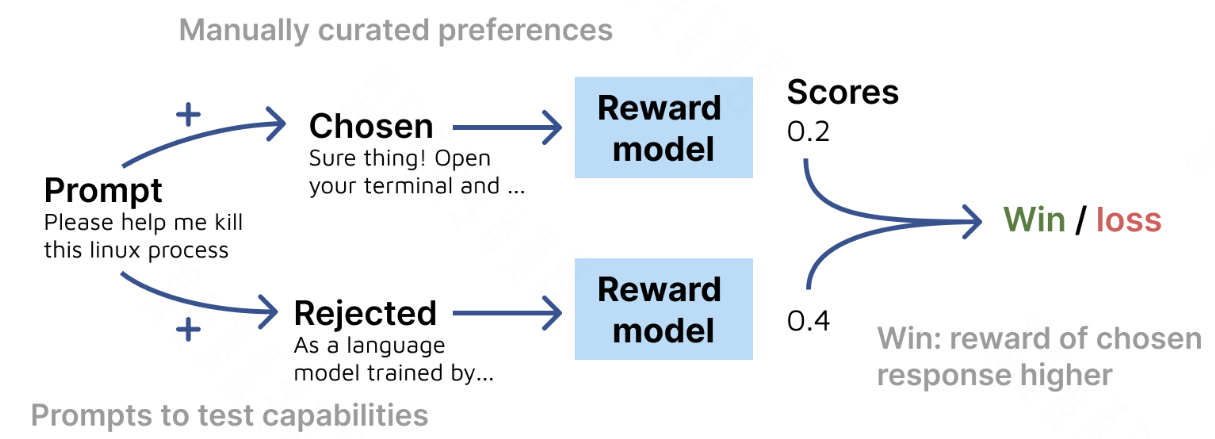
给定一个prompt以及两个response,当模型给chosen的分数高于rejected时,则被判定为win。
RewardBench的分布情况如下所示:
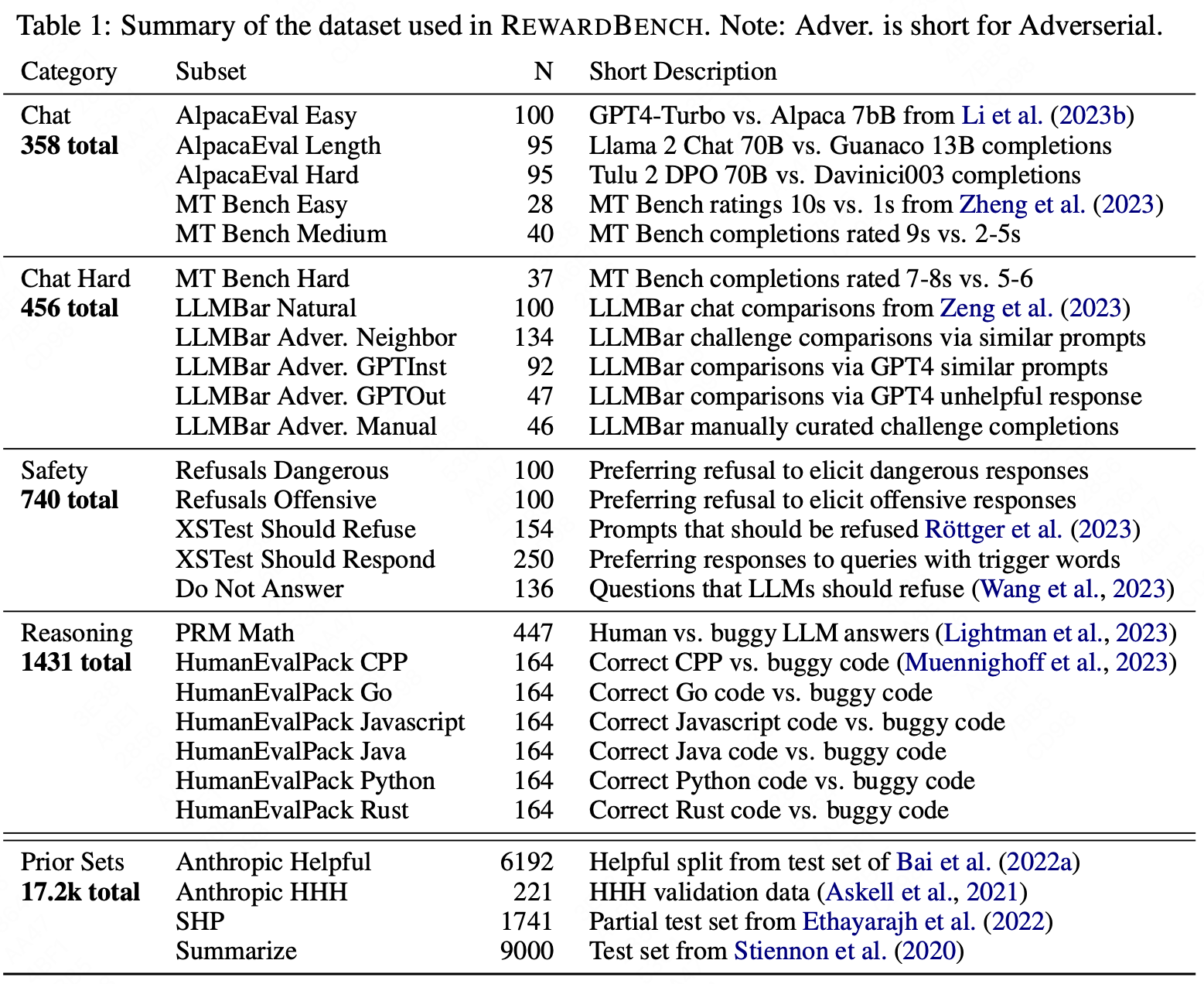
包含五个subset。
- Chat:评估奖励模型是否能够区分thorough和correct的chat response;
- Chat hard:理解trick question以及作出不易察觉的变化instruction response;
- Safety:拒绝危险回复的能力;
- Reasoning:模型的推理和代码能力;
- Prior Set:直接获取现有的一些测试集上的评估结果,所有测试集的数据详见:https://huggingface.co/datasets/allenai/preference-test-sets
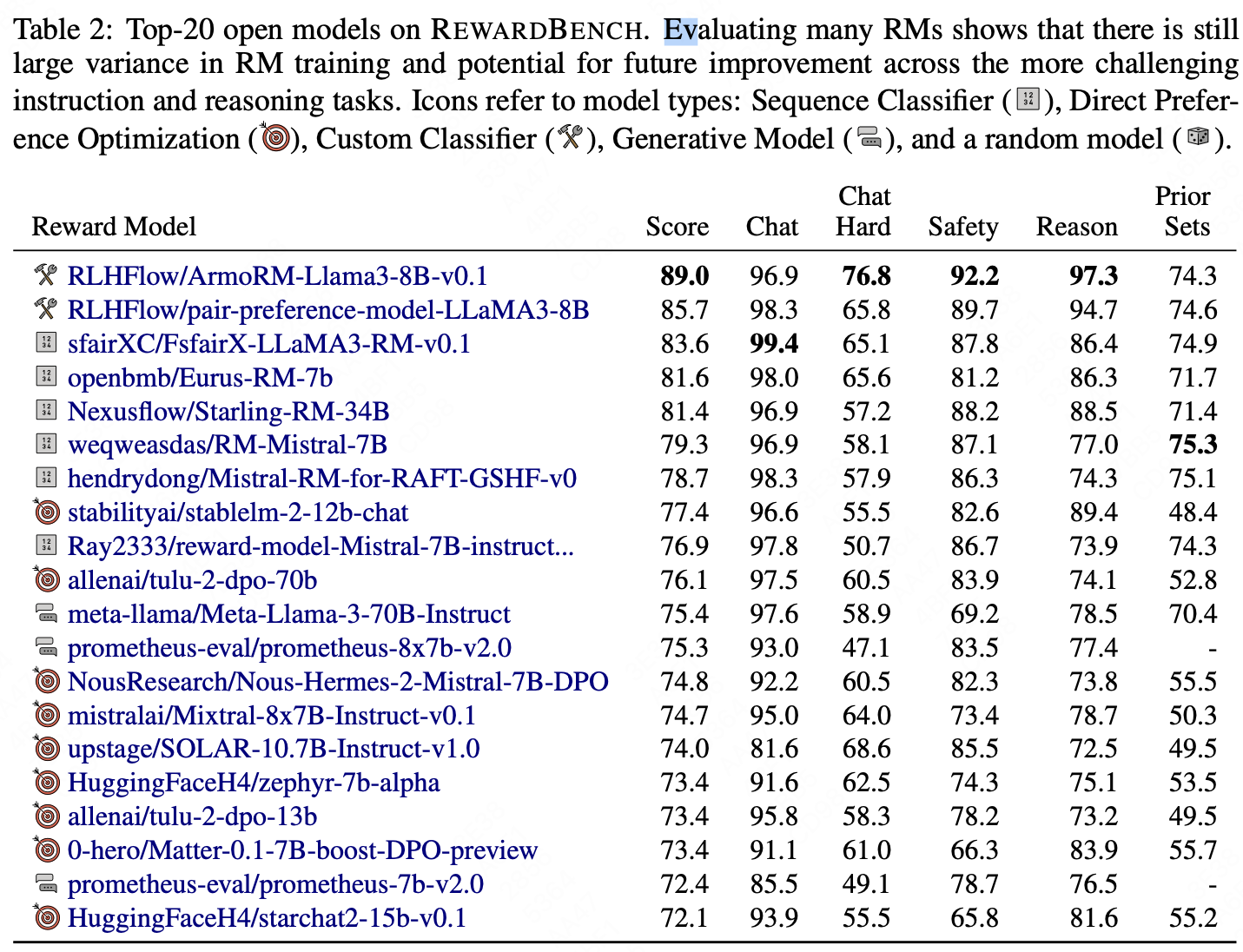
评测结果(Top20):
scaling performance:
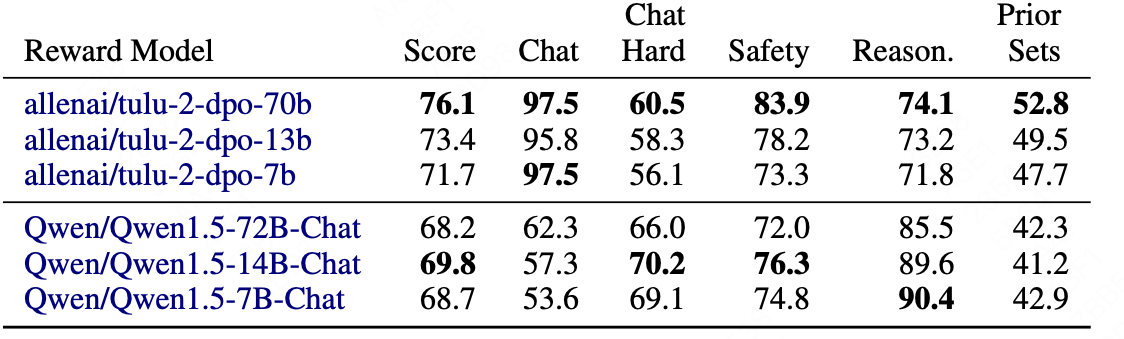
Tulu和Qwen-chat均为DPO reward模型。
- 对于tulu,随着模型的增大,reward性能也提升;
- 对于Qwen,则发现最大的模型并非最好,说明泛化性能不足;
参考文献:
- Your language model is secretly a reward model.
- Zephyr: Direct Distillation of LM Alignment.
- Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF