一、引言
1.1 数据库压力过大
由于用户量增大,请求数量也随之增大,数据压力过大
一个请求的url 背后可能有有4-5个 sql的操作 每秒钟 qps(并发数) 1000 背后的sql操作 4000-5000mysql 单机并发量读写 8000-10000 ,随着用户量的增加,mysql压力会非常大此时我们就可以使用redis作为缓存数据库,查询数据时,先去redis查询 ,redis没有该数据,再出去mysql,此时就会降低mysql 压力
1.2 数据不同步
多台服务器之间,数据不同步
1.3 传统锁失效
多台服务器之间的锁,已经不存在互斥性了。
二、Redis介绍
Redis是一个key-value存储系统,属于非关系型数据库(NoSQL -> 非关系型数据库 -> Not Only SQL)。它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)等类型。
为了保证效率,数据都是缓存在内存中,因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作。
redis主要应用场景:缓存热点数据,分布式锁,计数器,全局id,简单消息队列,排行榜,点赞,签到,关注模型等。
官网:https://redis.io/
有一位意大利人,在开发一款LLOOGG的统计页面,因为MySQL的性能不好,自己研发了一款非关系型数据库,并命名为Redis。
Redis(Remote Dictionary Server)即远程字典服务,Redis是由C语言去编写,Redis是一款基于Key-Value的NoSQL,而且Redis是基于内存存储数据的,Redis还提供了多种持久化机制,性能可以达到110000/s读取数据以及81000/s写入数据,Redis还提供了主从,哨兵以及集群的搭建方式,可以更方便的横向扩展以及垂直扩展。
| Redis之父 |
|---|
 |
三、Redis安装
3.1 Linux下安装
略
3.2 Docker安装
略
3.3 Windows下安装
3.3.1 安装
Redis官方不支持window平台
微软开源组织实现了扩展版,https://github.com/MSOpenTech/redis
下载压缩版,解压后
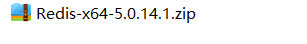
3.3.2 启动redis服务
使用命令行或者双击 redis-server.exe 都可
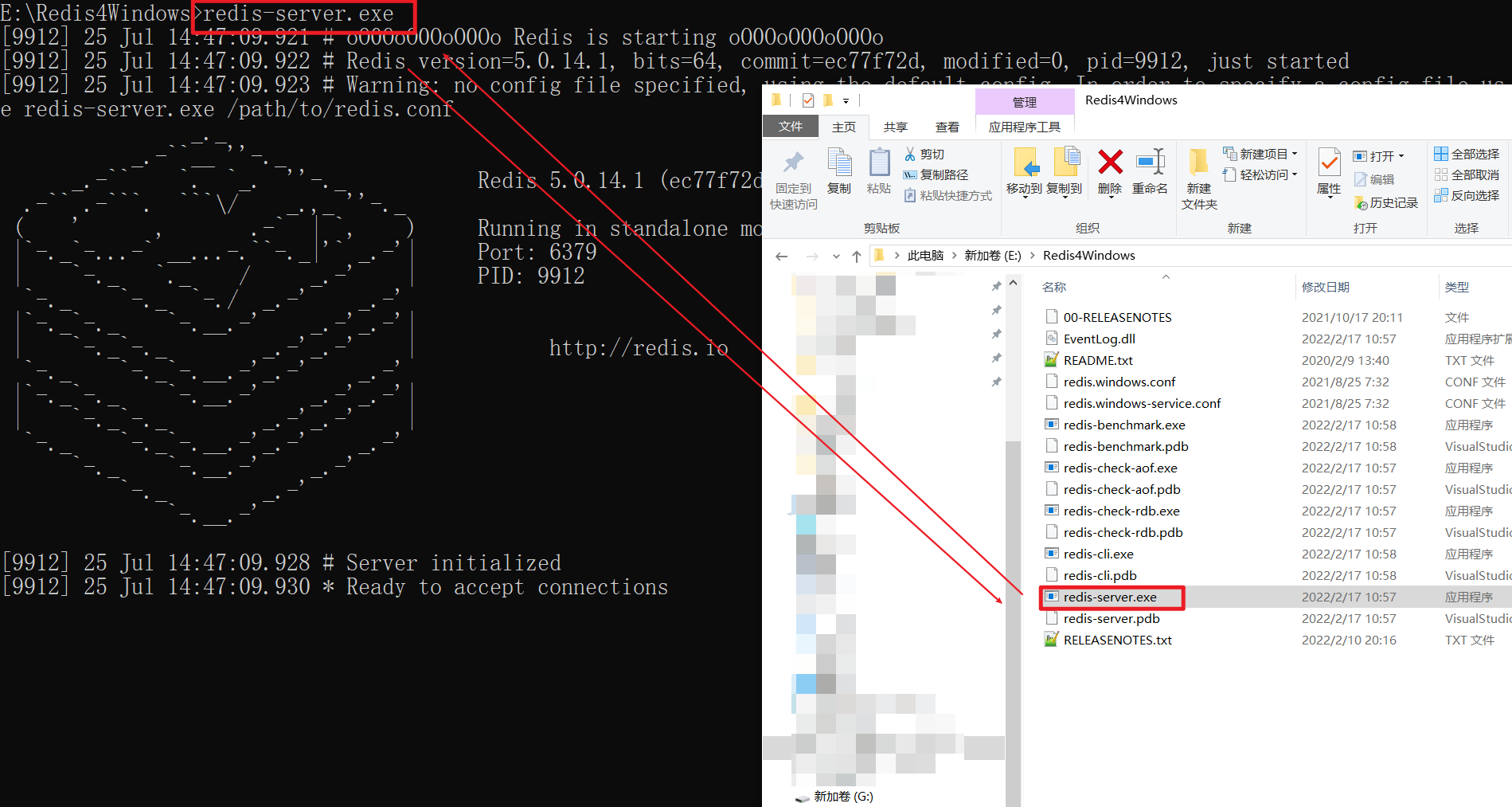
3.3.3 进入客户端
再开一个命令行,执行redis-cli.exe命令或者双击其 也可
可以演示一些基本命令测试

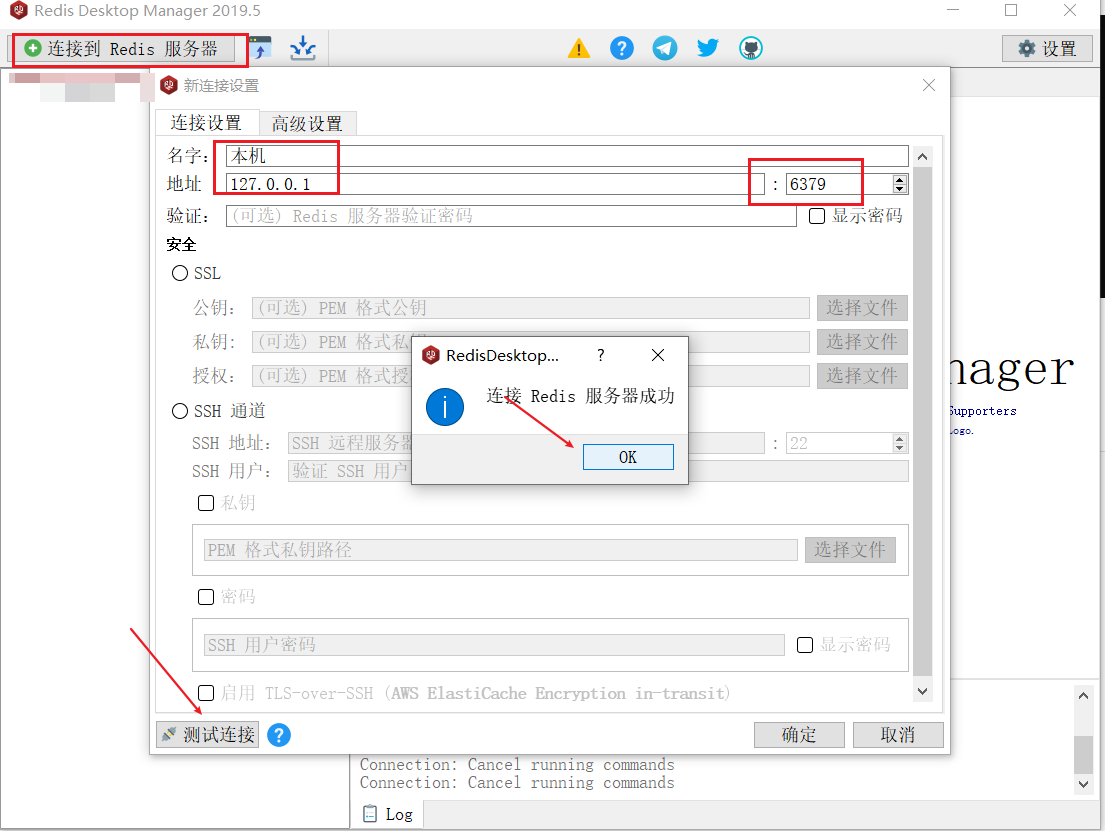
3.4 图形化工具
傻瓜式安装

安装好,点击左上角,连接本机Redis
四、常用命令(一)
4.1 Redis存储数据的结构
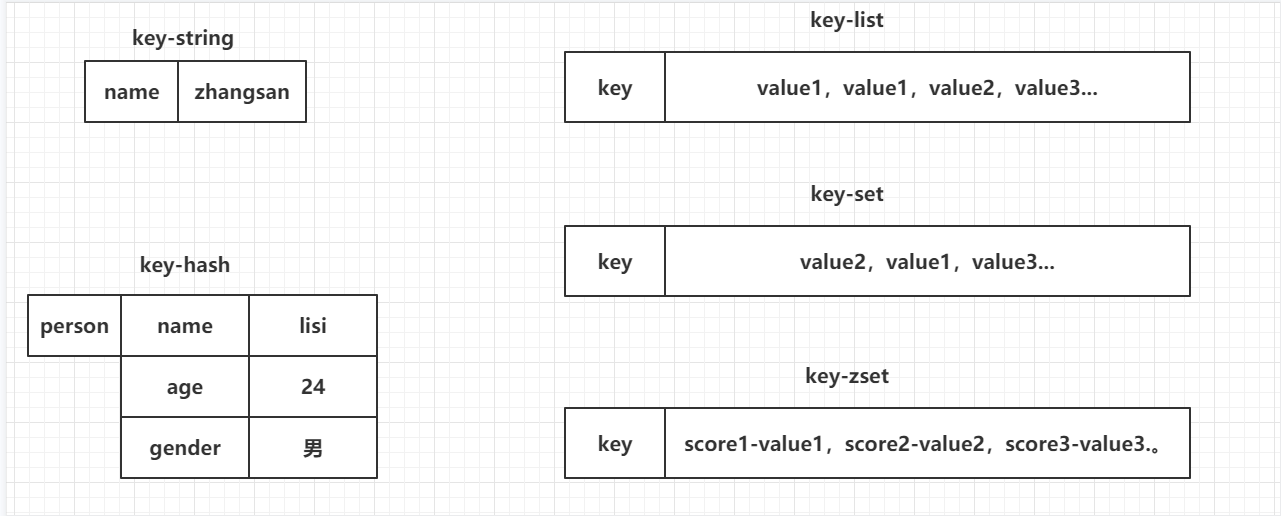
常用的5种数据结构:
- string:一个key对应一个值。最常用的,一般用于存储一个值。
- hash:一个key对应一个Map。存储一个对象数据的。
- list:一个key对应一个列表。使用list结构实现栈和队列结构。
- set:一个key对应一个集合。交集,差集和并集的操作。
- zset:一个key对应一个有序的集合。排行榜,积分存储等操作。
另外三种数据结构:
- HyperLogLog:计算近似值的。
- GEO:地理位置。
- BIT:一般存储的也是一个字符串,存储的是一个byte[]。
| 五种常用的存储数据结构图 |
|---|
 |
4.2 string类型
Redis SET 命令_设置指定 key 的值
1 存 set
语法:set key value
设置key的值,若key存在则覆盖原来的value

key值可以使用":"分隔,用于进行分类管理,比如下面例子中,"goods:id"表示key值

2 取 get
语法:get key
获取key对应的值

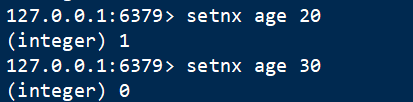
3 条件存 setnx
语法:setnx key value
设置值,如果当前key不存在的话(如果这个key存在,什么事都不做,如果这个key不存在,和set命令一样)
4 多存 mset
语法:mset key1 value1 key2 value2 … keyN valueN
设置多个key的值,若存在则覆盖

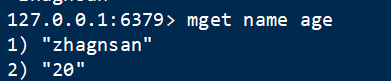
5 多取 mget
语法:mget key1 key2 … keyN
获取多个key对应的值
6 多条件存 msetnx
语法:msetnx key1 value1 key2 value2 … keyN valueN
同mset,但如果其中一个key已经存在了,则都不设置。这些操作都是原子的。

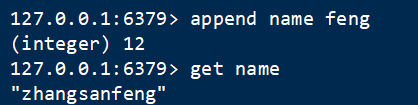
7 追加 append
语法:append key value
向指定key的value的字符串追加数据
8 自增 incr
语法:incr key
自增1,只针对值是整数的key

9 指定自增 incrby
语法:incrby key increment
针对key对应的value值增加一个增量值,如果key不存在,初始化为0,然后再增加


10 自减 decr
语法:decr key

11 指定自减 decrby
语法:decrby key increment
针对key对应的value的值减去一个值

12 过期 时间setex
可以考虑验证码这方向发展
语法:setex key seconds value
等价于先设置变量再设置超时(单位是秒),这个操作是原子的

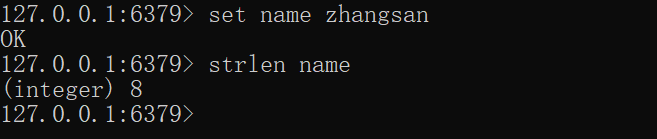
13 长度 strlen
语法: strlen key
查看value字符串的长度
14 删除 del
语法: del key
根据键删除数据
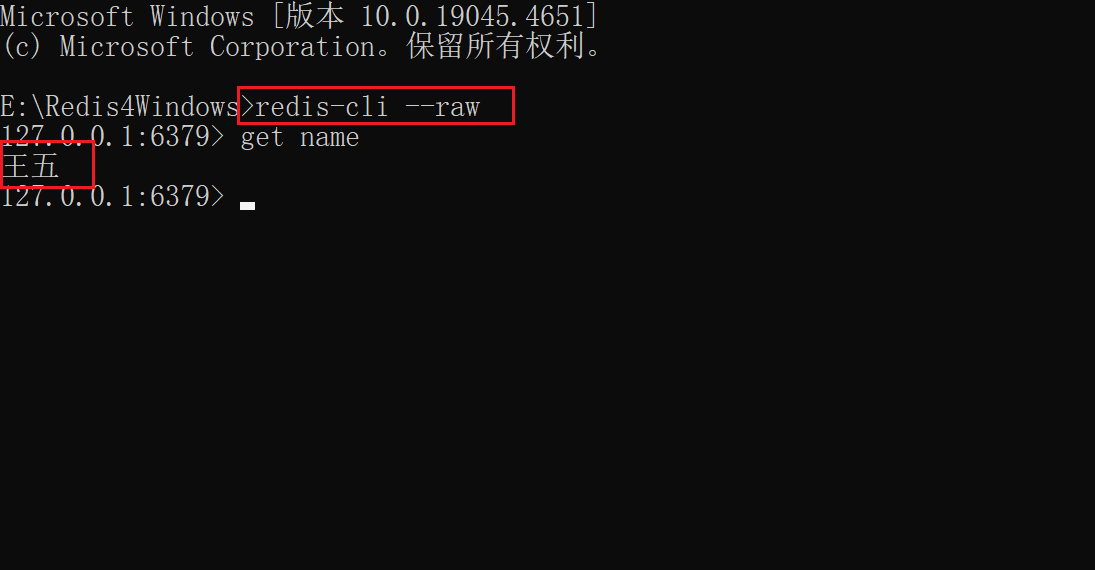
15 补充:中文问题
redis的汉字 : 不是乱码,只是redis的显示问题.redis显示成utf-8格式,
想要得到汉字原文, 只需在进入Redis客户端时,输入 redis-cli --raw
4.3 键的其他操作
1 判断存在 exists
语法:EXISTS key
查看是否存在该元素

2 删除 del
语法:del key
根据key删除元素

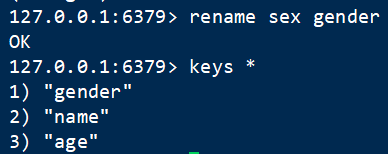
3 重命名 rename
语法:rename oldkey newkey
给key值重命名
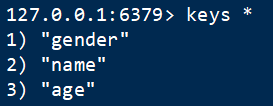
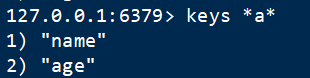
4 查键 keys
语法:keys * ,查看所有key
5 类型 type
语法:type key
查看key的类型

6 过期时间 expire
语法:EXPIRE key seconds
设置该元素多少秒后失效
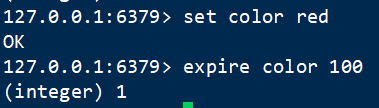
注意:设置过期时间的应用场景广泛,比如缓存的数据设置过期时间,防止长时间占用内存;手机验证码;限时优惠等
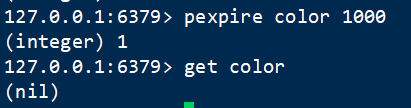
7 过期 pexpire
语法:PEXPIRE key milliseconds
设置该元素多少毫秒后失效
8 活得久 ttl
语法:TTL key:查看还可以存活多少秒,-2表示key不存在,-1表示永久存储

9 取消过期 persist
语法:persist key
取消过期时间

4.4 list类型
类似队列或者堆栈的数据结构
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。列表类型内部是使用双向链表(double linked list**)实现**的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
1 右存 rpush
语法:rpush key value
key表示列表的名字,从右边向key对应的列表添加元素,每次添加,放在结尾


2 左存 lpush
语法:lpush key value
从左边向key对应的列表添加元素,每次添加,放在开头

3 范围取值 lrange
语法:lrange key beginIndex endIndex
获取key的元素,用两端的索引取出子集,endIndex=-1则表示全部取出
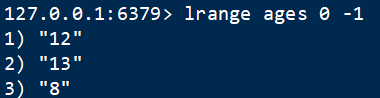
0 -1 就是查全部
4 长度 llen
语法:llen key
获取key的长度大小

5 左删 lpop
语法:lpop key
取出并移除key第一个元素,左边的元素

6 右删 rpop
语法:rpop key
取出并移除key最后一个元素,右边的元素

7 查询单个 lindex
语法:LINDEX key index
获取该索引下的元素

8 指定修改 lset
语法:LSET key index value
设置索引为index下的元素的value.超出索引范围报错

9 删除 lrem
语法:lrem key count value
删除count个value。(count为正数,从头开始,删除count个value元素;count为负,则从尾部向头删除count个value元素;count为0,则所有的元素为value的都删除)

10 两头删 ltrim
语法:LTRIM key start end
清空索引在start 和end之外的元素,索引从0开始

4.5 hash类型
使用string的问题
假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下:
User对象 —> json(string) —> redis
如果在业务上只是更新age属性,其他的属性并不做更新,应该怎么做呢? 如果仍然采用string类型,无法单独更新其中某个属性,需要删除然后重新添加,这样的话在传输、处理时会造成资源浪费,下边讲的hash可以很好的解决这个问题。
redis hash
hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。如下:
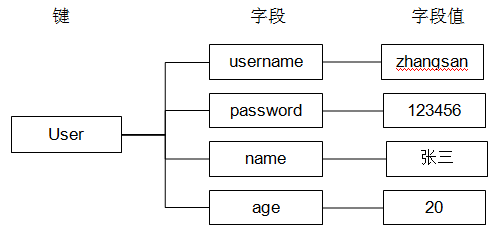
1 存 hset
HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0。
语法:HSET key field values
key是对象名,field是属性,value是值;
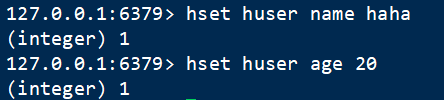

2 多存 hmset
语法:HMSET key field value [field value …]:同时设置多个属性

3 取 hget
语法:HGET key field:获取该对象的该属性对应的值

4 多取 hmget
语法:HMGET key field value [field value …]:获取多个属性值

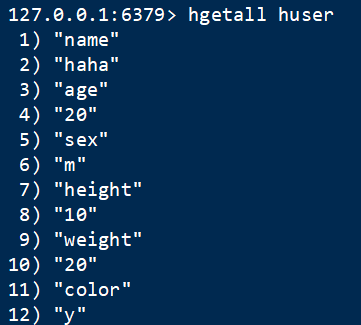
5 全取 hgetall
语法:HGETALL key 获取对象的所有信息(字段+值)
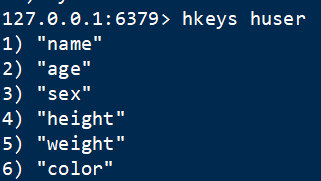
6 只取键 hkeys
语法:HKEYS key:获取对象的所有属性(field)
7 只取值 hvals
语法:HVALS key:获取对象的所有属性的值(value)
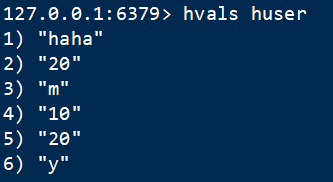
8 删属性hdel
语法:HDEL key field:删除对象的该属性

9 存在否 hexists
语法:HEXISTS key field:查看对象是否存在该属性

10 自增 hincrby(hash必须要加by 后面要跟开劈的长度)
语法:HINCRBY key field increment:原子自增操作,只能是integer的属性值可以使用;


注意: 没有hincr命令,只有hincrby命令
11 键数 hlen
语法:HLEN key:获取属性的个数。

4.6 set类型
集合(set)中的数据是不重复且没有顺序。
集合类型(set)的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型的Redis内部是使用值为空的散列表实现,所有这些操作的时间复杂度都为0(1)。
Redis还提供了多个集合之间的交集、并集、差集的运算。
1 存 sadd
语法:sadd key value1 value2 valueN 向set添加元素

2 删 srem
语法:srem key value :从set中移除指定元素

3 取所有 smembers
语法:smembers key : 取出所有set元素

4 判断 sismember
语法:SISMEMBER key value: 查看value是否存在set中

5 个数 scard
语法:scard key
获取set中元素的个数

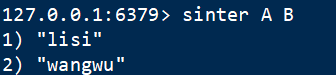
6 交集 sinter
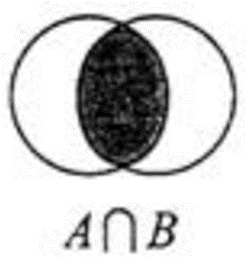
语法:sinter key1 key2 …
返回多个集合的交集

7 并集 sunion

语法: sunion set1 set2 …
获取全部集合中的数据
8 差集 sdiff
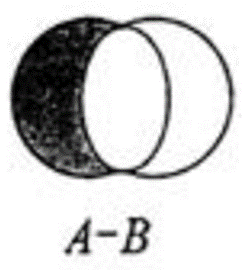
语法: sdiff set1 set2 …
获取多个集合中不一样的数据
tip: 集合数量 多的放在前面, 相当于 set1 - set2 剩余的元素
9 随机删 spop
注意:由于集合是无序的,所有SPOP命令会从集合中随机选择一个元素弹出
语法:SPOP key
语法: SPOP key count n 删除指定n个数的元素
随机获取一个数据(获取的同时,移除数据,count默认为1,代表弹出数据的数量)
4.7 Sorted Set有序集合(也叫Z-Set)主要用于热度排名
在集合类型(Set)的基础上,有序集合类型为集合中的每个元素都关联一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作。
在某些方面有序集合(ZSet)和列表(List)类型有些相似。
- 二者都是有序的。
- 二者都可以获得某一范围的元素。
但是,二者有着很大区别:
- 列表(list)类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。
- 有序(zset)集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快。
- 列表(list)中不能简单的调整某个元素的位置,但是有序集合(zset)可以(通过更改分数实现)
- 有序(zset)集合要比列表类型更耗内存。
1 存 zadd
语法:ZADD key score member
向有序set中添加元素member,其中score为分数(权重,可以为小数),该值决定了元素的顺序,默认升序;
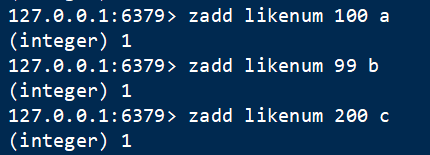
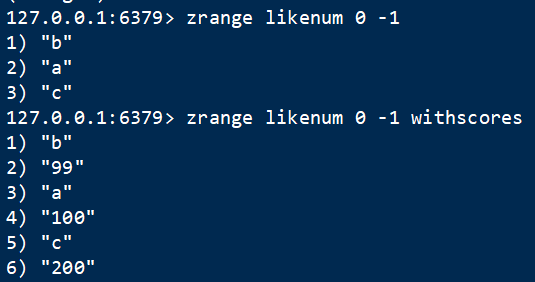
2 取 zrange
语法:ZRANGE key start end [WITHSCORES]
获取按score从低到高索引范围内的元素,索引可以是负数,-1表示最后一个,-2表示倒数第二个,即从后往前。withscores可选,表示获取包括分数
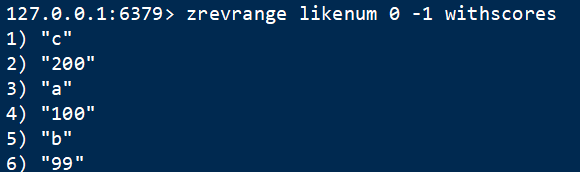
3 反取zrevrange
语法:ZREVRANGE key start end [WITHSCORES]
同上,但score从高到低排序。
3 计数 zcount
语法:ZCOUNT key min max
获取score在min和max范围内的元素的个数

4 计数 zcard
语法:ZCARD key
获取集合中元素的个数。

5 自增zincrby
语法:ZINCRBY key increment member:根据元素,score原子增加increment

6 查分 zscore
语法:ZSCORE key member
获取该元素的score

7 查排名 zrank
语法:ZRANK key member
获取元素的索引(照score从低到高排列)

8 移除 zrem
语法:ZREM key member
移除集合中的指定元素

9 移除 zremrangebyscore
z,rem,range,by,score
语法:ZREMRANGEBYSCORE key min max
清空集合内的score位于min和max之间的元素

10 其他
参考文档Redis Sorted Set API
4.8 bitmap类型(了解)
【Redis】Redis中BitMap(位图)
五、常用命令(二)
默认redis 有16个库, 默认情况下数据存储于 db0数据库
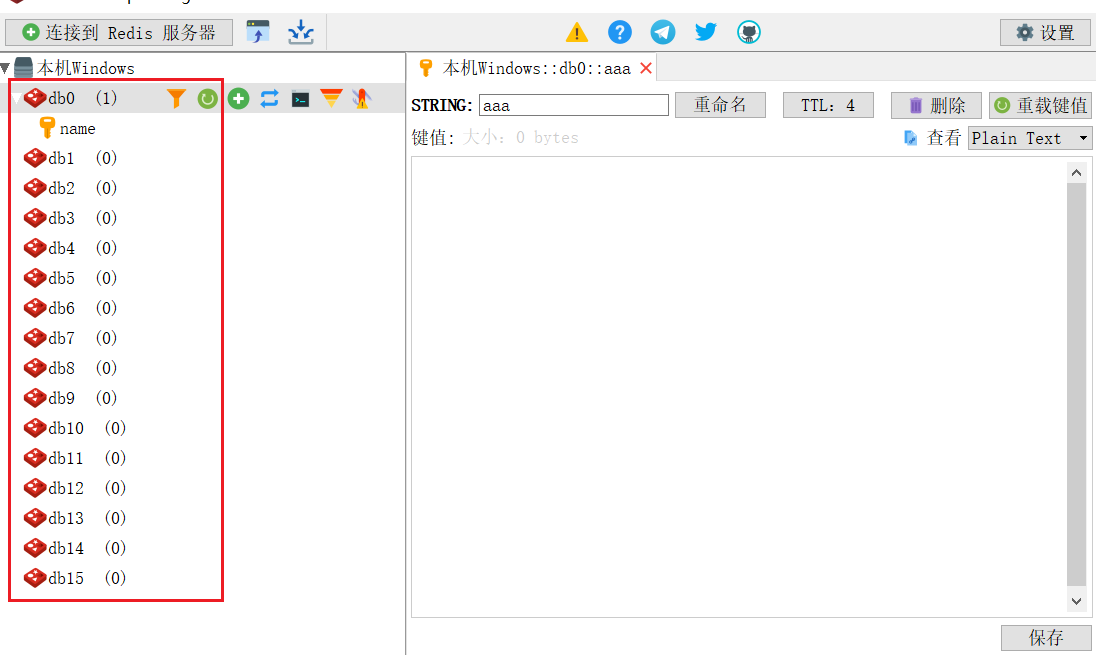
select数据库
切换到指定的数据库,数据库索引号 index 用数字值指定,以 0 作为起始索引值,0-15
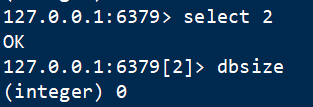
dbsize
查看数据库中key的数量

flushall
清空全部数据库
六、Redis的持久化【背】
Redis 提供了 RDB 和 AOF 两种持久化方式,RDB 是把内存中的数据集以快照形式写入磁盘,实际操作是通过 fork 子进程执行,采用二进制压缩存储;AOF 是以文本日志的形式记录 Redis 处理的每一个写入或删除操作。
RDB 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
AOF 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
6.1 RDB(快照)方式
默认的持久化方式,rdb是将内存中的数据以快照的方式写入文件中,默认的文件名是dump.rdb
redis.conf(windows中文件名为redis.windows.conf)中针对rdb方式的默认配置:
save 900 1save 300 10save 60 10000
配置含义:
900秒内,如果超过1个key被修改,则发起快照保存300秒内,如果超过10个key被修改,则发起快照保存60秒内,如果1万个key被修改,则发起快照保存
默认配置不方便看效果,可将快照频率设大一点,在redis.conf中增加一行:
save 10 1
保存后,启动redis服务端和客户端。在客户端输入命令:
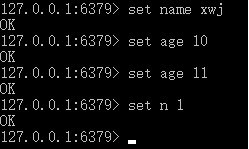
输入完,发现dump.rdb文件的修改日期变了,并且redis服务端增加了保存日志:
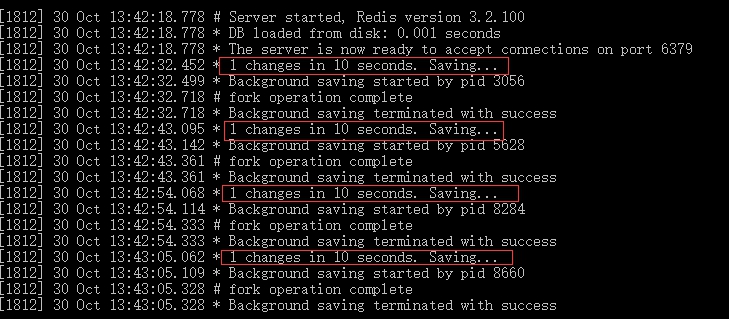
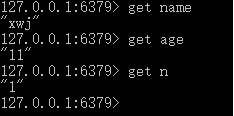
接下来,重启redis服务端和客户端,看数据是否真的持久化了:
6.2 AOF 方式
redis.conf中针对aof的配置:
appendonly no
将其修改为yes,开启AOF持久化,对应的文件名为appendonly.aof。使用redis命令后,该命令是以redis协议格式的形式追加到文件的最后!实际上,AOF方式中,并不会立即将命令写入到文件中,而是写入到硬盘缓存,然后根据配置的策略,将缓存写入到文件,配置如下:
appendfsync alwaysappendfsync everysecappendfsync no
配置含义:
always: 每次操作都会立即写入aof文件中everysec: 每秒持久化一次(默认配置)no: 不主动进行同步操作,默认30s一次
配置含义:
900秒内,如果超过1个key被修改,则发起快照保存300秒内,如果超过10个key被修改,则发起快照保存60秒内,如果1万个key被修改,则发起快照保存
默认配置不方便看效果,可将快照频率设大一点,在redis.conf中增加一行:
save 10 1
保存后,启动redis服务端和客户端。在客户端输入命令:
[外链图片转存中…(img-4gGJYXPg-1722243843563)]
输入完,发现dump.rdb文件的修改日期变了,并且redis服务端增加了保存日志:
[外链图片转存中…(img-B38dXGwp-1722243843563)]
接下来,重启redis服务端和客户端,看数据是否真的持久化了:
[外链图片转存中…(img-OWDDk6T3-1722243843564)]
6.2 AOF 方式
redis.conf中针对aof的配置:
appendonly no
将其修改为yes,开启AOF持久化,对应的文件名为appendonly.aof。使用redis命令后,该命令是以redis协议格式的形式追加到文件的最后!实际上,AOF方式中,并不会立即将命令写入到文件中,而是写入到硬盘缓存,然后根据配置的策略,将缓存写入到文件,配置如下:
appendfsync alwaysappendfsync everysecappendfsync no
配置含义:
always: 每次操作都会立即写入aof文件中everysec: 每秒持久化一次(默认配置)no: 不主动进行同步操作,默认30s一次

















![Redis学习[1] ——基本概念和数据类型](https://i-blog.csdnimg.cn/direct/3cb274a2db734c428d0516c8b6e9ded7.png)