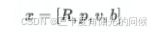前言
在上一篇文章中,我们讲解了 Canvas 中单个变换的原理和效果,即缩放、旋转和平移。但是单个旋转仅仅是基础,Canvas 变换最重要的是能够随意组合各种变换以实现想要的效果。在这种情况下,就需要了解如何组合变换,以及组合变换背后的矩阵是如何计算出来的。
阅读本文之前,建议先阅读:深度解析 Android Matrix 变换(一):缩放 scale、旋转 rotate、平移 translate
在这篇文章中,我就带领大家理解组合变换以及其背后的原理。通过这篇文章,大家肯定能随意组合变换以达到想要的效果。
从一个点开始
在二维平面中,表示一个点只是需要其 x,y 坐标,但是在表换过程中,并不是使用两个值的表示方式,而是用齐次坐标来表示。简单来说,就是 x,y 坐标再加上一个 1 来表示。当用列向量来表示这个点的坐标时,因为其具有三行,因此可以与各种变换的矩阵相乘,因为矩阵都是 3*3 的,可以与 3*1 的向量相乘。
我们用 Ms 表示缩放矩阵,Mr 表示旋转矩阵,Mt 表示平移矩阵,如果对于一个点 P0,我们对它依次应用旋转平移和缩放,那么变换后得到的点 P1 为:
P1 = Ms * Mt * Mr * P0
注意相乘的顺序,我们必须从又往左相乘,但是由于矩阵乘法满足结合律,因此这三个矩阵可以合并为一个与 P0 相乘。
在了解了如何组合矩阵之后我们就从代码层面理解如何构建想要的组合矩阵。

构建矩阵
在上篇文章中,我们介绍过,缩放旋转和平移都有对应的 post 和 pre 版本。在这一节中,我们来介绍这两个种类的方法的具体意义:
- Matrix.preScale(float sx, float sy);
- Matrix.postScale(float sx, float sy);
- Matrix.preRotate(float degrees);
- Matrix.postRotate(float degrees);
- Matrix.preTranslate(float dx, float dy);
- Matrix.postTranslate(float dx, float dy);
在上面的方法中,我们先过滤掉 preXXX 和 postXXX 的方法名和参数,因为这些方法实际上都是通过方法名和参数来构建一个矩阵,然后 pre 或者 post 这个矩阵。也就是说,上述的方法可以总结为两个方法:
- Matrix.preConcat(Matrix other)
- Matrix.postConcat(Matrix other)
那么这两个方法有什么区别呢?说简单一点就是 pre 是左乘,post 是右乘。举个例子:
A.preConcat(B)表示 A * B 结果设置到 A 中;A.preConcat(B)表示 B * A 结果设置到 A 中;
变换顺序
在构建矩阵时,变换顺序是非常重要的。上面只是对变换时矩阵的乘法进行了讲解,但是在实际编码时,我们通常是按照 先缩放,再旋转,最后平移 的顺序来进行的。
对于一个变换,我们必须考虑按照这个顺序来完成,特别是平移需要最后完成。否则后续的旋转或缩放会影响平移变换,变换的结果可能完全不同,甚至不符合直觉。
而按照这个变换做的好处是:
- 缩放发生在局部坐标系,不影响旋转或平移的方向。
- 旋转发生在缩放之后,不会影响缩放比例。
- 平移最后执行,不会受到缩放或旋转的干扰。
实例
最后我们组合一个变换,并通过动画的形式演示变换过程。
我们还是以上篇文章的图片为基础:

我们先对这个图片进行缩放(1.5,0.5),再旋转30度,最后移动(500, 200)。
根据上面对构建矩阵的描述,我们通过下面的代码来生成变换矩阵:
Matrix matrix = new Matrix();
matrix.postScale(1.5F, 0.5F);
matrix.postRotate(30);
matrix.postTranslate(500, 200);
在将这个 matrix 应用到 Canvas 后,可以看到变换后的结果:

其实,对于某一个结果,可以通过多种方式来构造变换矩阵。例如这个变换,我们还可以通过下面的矩阵生成:
Matrix matrix = new Matrix();
matrix.setRotate(30);
matrix.preScale(1.5F, 0.5F);
matrix.postTranslate(500, 200);
既然同一个变换有多种构建方式,那么应该用哪种构建矩阵的方式呢?这里还是建议用复杂的方式,至少,别人越是看不懂,越是显得你的重要性。
最后,通过动画,来演示一下这个组合变换是如何生效的: