爬虫:通过编写程序,来获取获取互联网上的资源
需求:用程序模拟浏览器,输入一个网址,从该网址获取到资源或内容
一、入门程序
#使用urlopen来进行爬取
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
# print(resp.read().decode("utf-8"))
with open("mybaidu.html",mode="w",encoding="utf-8") as f:f.write(resp.read().decode("utf-8"))
print("over")二、web请求过程剖析
1、服务器渲染
在服务器那边直接把数据和html聚合在一起,统一返回给浏览器。
直观的现象就是查看网页源代码能拿到所有的页面内容。
eg:https://www.douban.com/note/809408645/?_i=2050824ZzQJI3Y
2、客户端渲染
第一次请求只拿到html骨架,第二次请求拿到数据,然后客户端进行渲染。
直观的现象就是查看网页源代码看不到数据。
因此想要看到从哪个请求拿到的数据,要熟练使用抓包工具。
eg:https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=

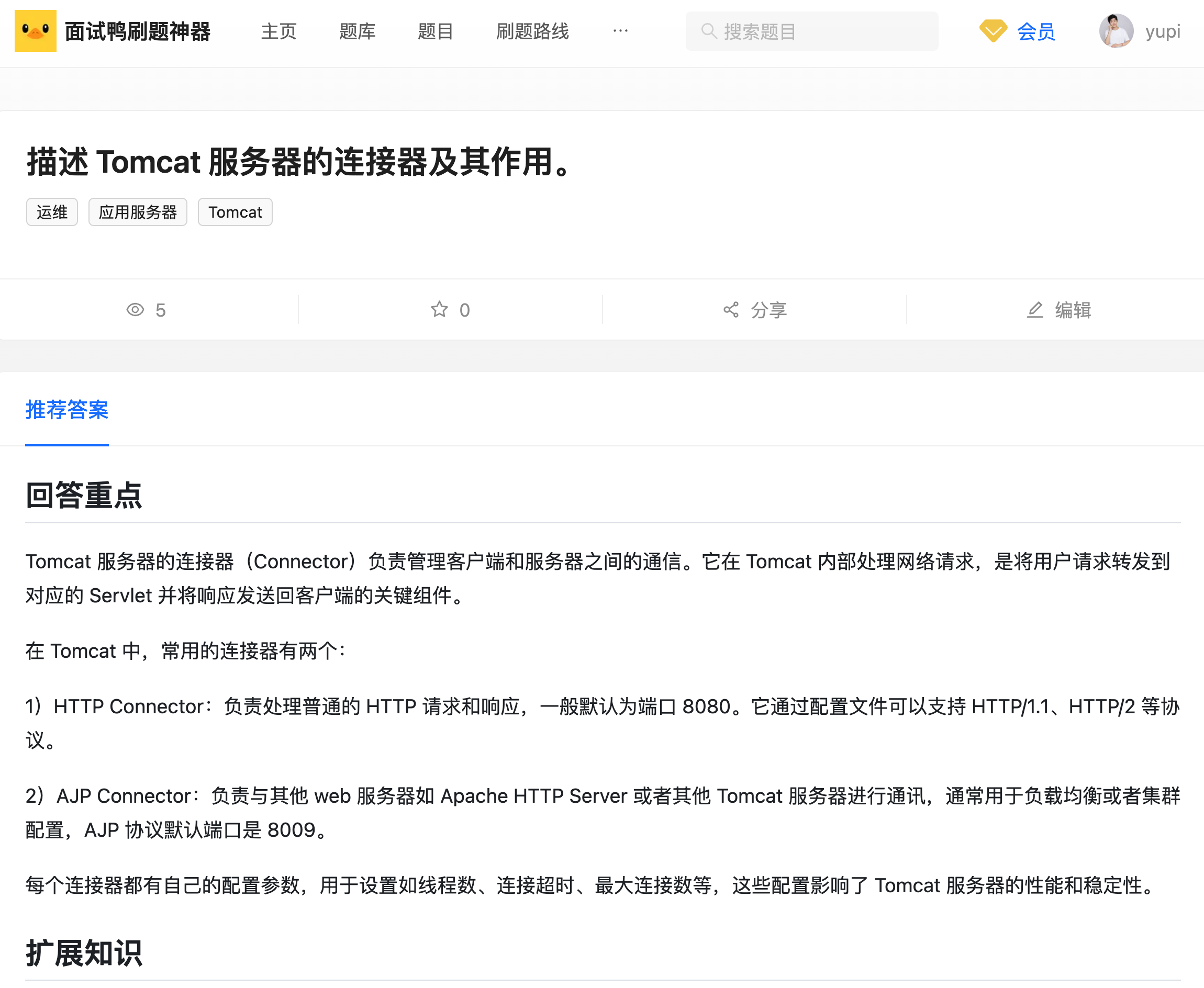
三、HTTP协议
协议就是两个计算机之间为了能够流畅的进行沟通而设置的一个君子协议,常见的协议有TCP/IP,SOAP协议,SMTP协议.....
HTTP协议就是超文本协议,作用为浏览器和服务器之间的数据交互遵守的协议
1、请求:
(1)请求行:请求方式(get/post),请求url地址,协议
(2)请求头:放一些服务器使用的附加信息。例如请求从哪来的,或者一些反爬信息
(3)请求体:请求参数
2、响应
(1)状态行:协议 状态码
(2)响应头:放一些客户端要使用的一些附加信息
(3)响应体:服务器返回的真正客户端要用的内容(HTML,JSON)等
3、请求头中最常见的一些重要内容(爬虫需要)
(1)User-Agent:请求载体的身份标识(用啥发送的请求)
(2)Refere:防盗链(这次请求是从哪个页面来的?反爬会用到)
(3)cookie:本地字符串数据信息(用户登录信息,反爬的token)
4、响应头中一些重要的内容
(1)cookie:本地字符串数据信息(用户登录信息,反爬的token)
(2)各种神奇的莫名其妙的字符串(这个需要经验了,一般是token字样,防止各种攻击和反爬)
5、常见的请求方式
GET:查询东西的时候。所有在地址栏输入的url都是get请求
POST:上传一些内容/对服务器的内容进行更改
四、Requests入门
安装:pip install requests
需求1、爬取搜狗页面搜索薛之谦得到的页面内容
此处添加User-Agent处理一个简单的反爬
import requests
url = 'https://www.sogou.com/web?query=%E8%96%9B%E4%B9%8B%E8%B0%A6'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
# 所有在地址栏输入的url都是get请求
resp = requests.get(url, headers=headers)
print(resp)
print(resp.text) #拿到页面源代码
resp.close()需求2、拿到百度翻译联想词(post)

经过查看抓包,发现这个请求为https://fanyi.baidu.com/sug

import requests
url = 'https://fanyi.baidu.com/sug'
s = input("输入你要翻译的英文单词")
data = {"kw": s
}
#发送post请求,发送的数据必须放在字典中,通过data进行传递
resp = requests.post(url,data=data)
print(resp.json())#将服务器返回的内容直接处理为json() =>python中的字典
需求3、拿到豆瓣排行榜的数据(在第二次请求中返回数据)(get)
客户端渲染返回的数据一般在xhr中,可以进行筛选。

import requests
url = "https://movie.douban.com/j/chart/top_list"
#参数很长的时候可以扔到字典里,重新封装参数
param ={"type": "24","interval_id": "100:90","action": "","start":"0","limit": "20"
}
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0"
}
resp = requests.get(url=url,params=param,headers=headers)
print(resp.request.url)
print(resp.json())
resp.close()




![[Docker][Docker Registry]详细讲解](https://i-blog.csdnimg.cn/direct/001206fb518d4fae9ca5054dd010455f.png)