1 自媒体账号
目前运营的自媒体账号如下:
- 哔哩哔哩 【雪天鱼】: 雪天鱼个人主页-bilibili.com
- CSDN 【雪天鱼】: 雪天鱼-CSDN博客
QQ 学习交流群
- FPGA科研硕博交流群 910055563 (进群有一定的学历门槛,长期未发言会被请出群聊,主要交流FPGA科研学术话题)
- CNN | RVfpga学习交流群(推荐,人数上限 2000) 541434600
- FPGA&IC&DL学习交流群 866169462
- 关键词
dataflow 、 stream(fifo)、流水线突发、顺序突发、迭代次数细粒度控制、完美嵌套循环 - 实验环境
Vitis HLS 2021.1、 Vivado 2021.1(用于进行协同仿真)
2 问题描述 (公开)
所发现的设计问题:
现有一个三层嵌套循环通过 M_AXI 接口对全局存储器进行读取,如果此时对迭代次数进行细粒度控制,会导致模块延迟大约增加为原来的2倍。
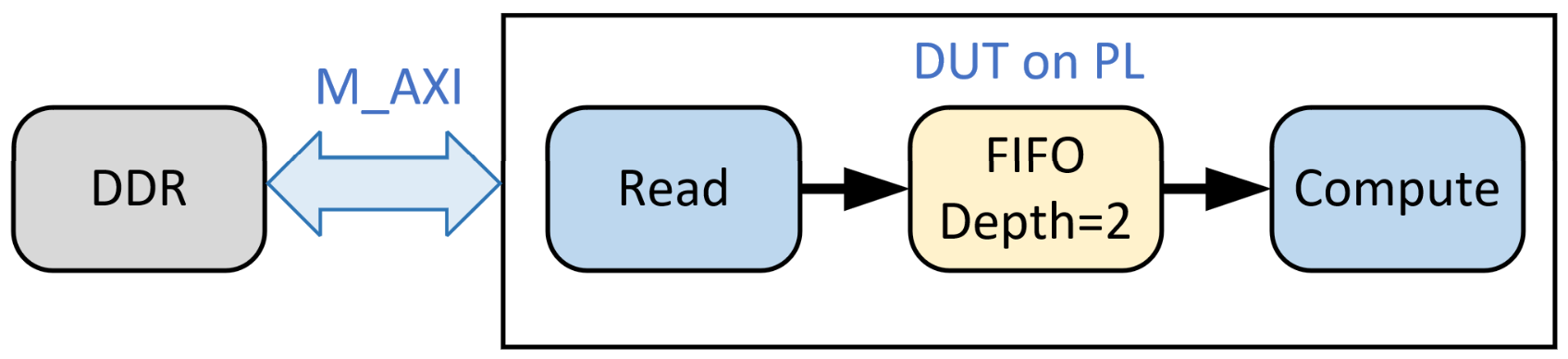
设计描述:设计内部包含两个模块,一个是Read模块,通过 AXI4 存储器映射接口(m_axi) 与 全局存储器(PS 的 DDR)进行通信,该接口支持双向通信,但这里 Read 模块只负责从 DDR 读取数据到设计内部的 FIFO 中,然后 Compute 模块从 FIFO 中取出一个数据进行其他操作。
代码如下:
// H = 20, W =15, C = 8void read_arr(hls::stream<int>& arr_stream, int in_arr[H][W][C])
{#pragma HLS inline offfor(int h=0; h < H; h++){for(int w=0; w < W; w++){for(int c=0; c < C; c++){#pragma HLS pipeline//if (h >= 10 ) return;//if (h >= 10 && w >= 5) return;arr_stream << in_arr[h][w][c]; } }}
}void compute_arr_on_stream( hls::stream<int>& arr_stream)
{#pragma HLS inline offint value;for(int h=0; h < H; h++){for(int w=0; w < W; w++){for(int c=0; c < C; c++){#pragma HLS pipeline//if (h >= 10) return;//if (h >= 10 && w >= 5) return;arr_stream >> value;cout<<" arr_stream["<<h<<"]["<<w<<"]["<<c<<"] = "<<value<<endl;} }}
}void compute_arr(int in_arr[H][W][C])
{#pragma HLS interface m_axi depth=20*15*8 port=in_arr offset=slave bundle=inout #pragma HLS inline off#pragma HLS dataflowhls::stream<int> arr_stream("arr_stream");read_arr(arr_stream, in_arr);compute_arr_on_stream(arr_stream);
}
其中 read_arr() 函数对应 read 模块, 用于读取数组数据到 FIFO中; compute_arr_on_stream() 函数对应 compute模块,用于从FIFO中取数据并打印;compute_arr() 函数是模块顶层。
FIFO深度默认为2。所以在 read_arr 执行过一次后,会同时执行 read_arr 和 compute_arr_on_stream 函数,即在写入一个数据到FIFO的同时会读取一个数据出来进行其他操作,这是我们所期望的结果。
接下来将会展示增加【细粒度迭代次数控制】语句对协同仿真得到性能(延迟)的影响。
2.1 【版本 1.0】 无迭代次数控制
不进行迭代次数控制,所有迭代都执行完。代码无需进行改变。
我们期望的迭代总次数(trip count) = HxWxC = 20x15x8 = 2400
- 综合报告

三层嵌套循环被展平了,迭代总次数为 2400 与预期一致。
仿真代码:
void test_compute_arr()
{int in_arr[H][W][C];for(int h=0; h < H; h++){for(int w=0; w < W; w++){for(int c=0; c < C; c++){in_arr[h][w][c] = h*W*C + w*C + c; // index}}}compute_arr(in_arr);
}
- 协同仿真报告
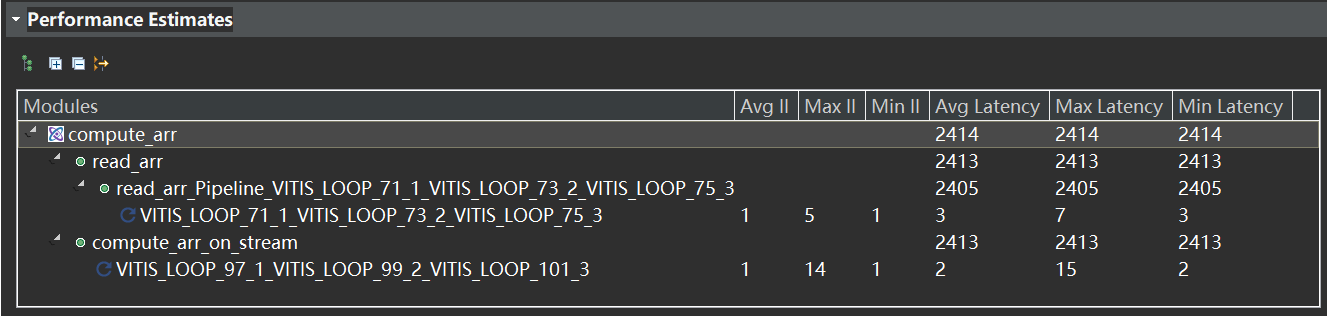
延迟和综合报告基本一致。
2.2 【版本 2.0】 迭代次数的细粒度控制
现在对此三层嵌套循环的迭代次数进行控制,取消最内部代码的该行语句注释即可。
if (h >= 10 && w >= 5) return;
即通过h和w的值来控制外两层循环的迭代进行,期望的迭代总次数为 10x15x8 + 5x8 = 1240
-
综合报告

II 和 trip count 的推断和版本 1.0 一致,但由于需要硬件实现 if 条件语句,资源用的会多点。这里说明编译器是没法根据 这种涉及多层循环迭代控制的 IF语句来推断真实的迭代次数的,也就不会进行专门的优化。
即 If 语句会被实现为 Read 模块中的硬件逻辑,在每次迭代中都需要进行执行,但我们期望的结果是编译器能识别到具体在哪一个迭代结束。具体的对比将在下文进行说明。 -
协同仿真报告
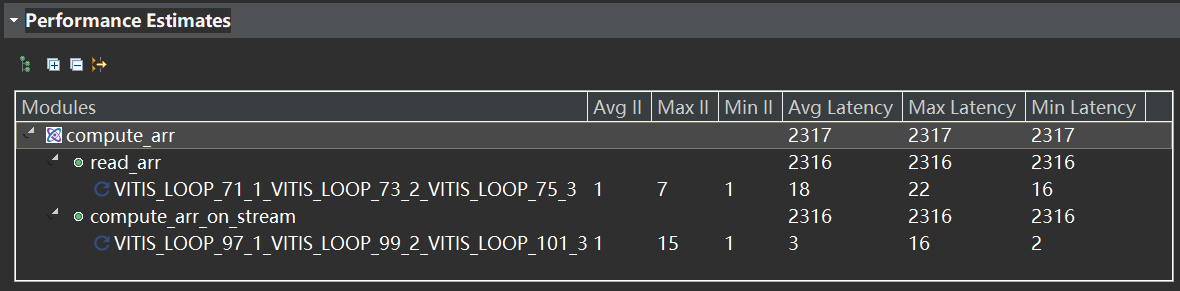
协同仿真的打印结果是正确的,打印到 arr_stream[10][4][7] = 1239 结束,正确识别出了在何时结束函数,但延迟却不是预期中的 1240 左右,反而几乎是 1240 的两倍。
2.3 相关视频介绍
综上所述,对于此设计,通过 if 语句来进行迭代次数的细粒度控制时,会导致模块产生额外的延迟。
那么,具体的导致额外延迟的原因是什么?如何解决该问题?以确保可以在实现细粒度迭代次数控制的同时,不产生额外的延迟。
问题描述对应的我的B站视频链接:https://www.bilibili.com/video/BV1mEvse8ECQ
如果对此问题的原因以及解决方法感兴趣的话,可观看本人的充电视频:https://www.bilibili.com/video/BV1LTv4e2EVL
18元
视频内容包括:
【问题解决方面】
- 额外延迟产生的具体原因分析
- 两种解决方案
- 对于通过 M_AXI 接口读取全局存储器的设计心得总结
【Vitis HLS 工具使用方面】 - M_AXI 接口 突发传输相关信号 和 协同仿真其他波形信号的分析
- Vitis HLS 设计C综合、C仿真、 C/RTL 协同仿真 操作演示
- C综合 和 C/RTL 协同仿真综合报告中 Performance 部分的分析
提供的配套资料:
- 测试代码 / 工程 (已在 Vitis HLS 2021.1 上运行过)
- 完整文档
声明: 基本概念参考了 Xilinx 的 UG1399 手册,实验制定以及结果分析均个人原创,建议勿拍。