前言
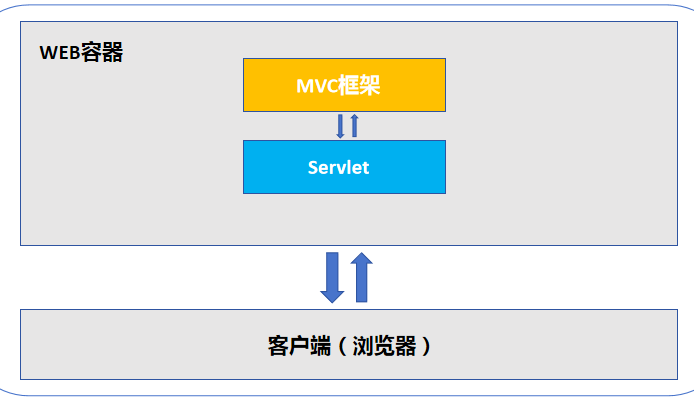
关于自动化测试的介绍,网上已有很多资料,这里不再赘述,UI自动化测试是自动化测试的一种,也是测试金字塔最上面的一层,selenium是应用于web的自动化测试工具,支持多平台、多浏览器、多语言来实现自动化,优点如下:
①开源、免费且对web界面有良好的支持;;
②多浏览器支持:chrome、Firefox、IE、Edge等;
③多平台支持:Linux、Windows、MAC;
④多语言支持:java、python、Ruby、C#、JavaScript、C++;
⑤简单(API简单)、灵活(开发语言驱动),支持分布式测试用例执行;
环境准备
- 浏览器(Chrome)
- Python
- Selenium
- chromedriver(请下载于Chrome对应版本的驱动)
- IDE(Pycharm)
1、python、pycharm安装
2、selenium安装
pip install selenium 关于selenium元素定位是开展web自动化测试的基础和关键,总共有八种定位方式,包括id,class,xpath等
3、chromedriver驱动安装
驱动下载:http://chromedriver.storage.googleapis.com/index.html
然后把chromedriver.exe拷贝到到chrome的安装目录下…\Google\Chrome\Application\ ,同时把chrome的安装目录加入到path环境变量。
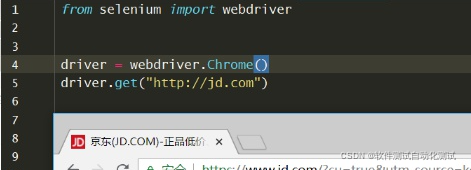
4、快速验证测试
自动化测试框架
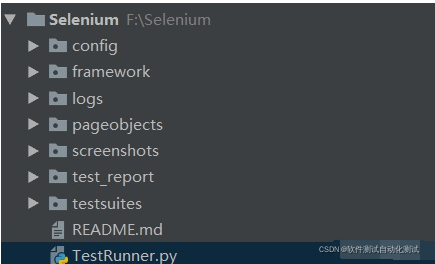
- config目录中存放的是测试配置相关的文件,文件类型ini,包括测试的网址、浏览器驱动等信息
- framework目录中存放的是页面基础类base_page: 封装一些常用的页面操作方法;日志类 Logger: 封装日志输出及控制台输出方法
- logs用来存放输出的日志文件
- pageobjects目录存放的是页面对象,一个页面封装为一个类,一个元素封装为一个方法
- screenshots目录存放的是测试过程中的相关截图
- test_report用来存放输出的测试报告
- testsuites目录存放测试用例,包括test_base和单个测试用例
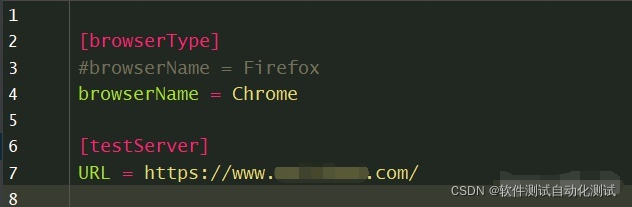
1、config.ini配置信息如下:
2、framework目录下base_page的封装:
import timefrom selenium.webdriver.common.action_chains import ActionChainsfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support.select import Selectimport os.pathfrom framework.logger import Logger# 创建一个日志实例logger = Logger(logger="BasePage").getlog()class BasePage(object):"""定义一个页面基类,让所有页面都继承这个类,封装一些常用的页面操作方法"""def __init__(self, driver):self.driver = driver#get an url linkdef open(self,url):self.driver.get(url)#quit browser and end testingdef quit_browser(self):self.driver.quit()# 浏览器前进操作def forward(self):self.driver.forward()logger.info("Click forward on current page.")# 浏览器后退操作def back(self):self.driver.back()logger.info("Click back on current page.")# 显示等待def wait(self,loc,seconds):try:wait_=WebDriverWait(self.driver,seconds)wait_.until(lambda driver:driver.find_element(*loc))logger.info("wait for %d seconds." % seconds)except NameError as e:logger.error("Failed to load the element with %s" % e)# 保存图片def get_windows_img(self):"""把file_path保存到我们项目根目录的一个文件夹.\Screenshots下"""file_path = os.path.dirname(os.path.abspath('.')) + 'Selenium/screenshots/'rq = time.strftime('%Y%m%d%H%M%S', time.localtime(time.time()))screen_name = file_path + rq + '.png'try:self.driver.get_screenshot_as_file(screen_name)logger.info("Had take screenshot and save to folder : /screenshots")except NameError as e:logger.error("Failed to take screenshot! %s" % e)self.get_windows_img()# 定位元素方法def find_element(self,loc):""":return: element"""return self.driver.find_element(*loc)# 输入def send_keys(self, selector, text):el = self.find_element(selector)el.clear()try:el.send_keys(text)logger.info("Had type \' %s \' in inputBox" % text)except NameError as e:logger.error("Failed to select in input box with %s" % e)self.get_windows_img()# 清除文本框def clear(self, selector):el = self.find_element(selector)try:el.clear()logger.info("Clear text in input box before typing.")except NameError as e:logger.error("Failed to clear in input box with %s" % e)self.get_windows_img()# 点击元素def click(self, selector):el = self.find_element(selector)try:el.click()logger.info("The element \'%s\' was clicked." % el.text)except NameError as e:logger.error("Failed to click the element with %s" % e)#鼠标事件(左键点击)def move_element(self,loc,sloc):mouse=self.find_element(loc)try:ActionChains(self.driver).move_to_element(mouse).perform()self.click(sloc)passexcept Exception as e:logger.error("Failed to click move_element with %s" % e)self.get_windows_img()# 强制等待@staticmethoddef sleep(seconds):time.sleep(seconds)logger.info("Sleep for %d seconds" % seconds)logger日志输入方法:
import loggingimport os.pathimport timeclass Logger(object):def __init__(self, logger):'''''指定保存日志的文件路径,日志级别,以及调用文件将日志存入到指定的文件中'''# 创建一个loggerself.logger = logging.getLogger(logger)self.logger.setLevel(logging.DEBUG)# 创建一个handler,用于写入日志文件rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time()))log_path = os.path.dirname(os.path.abspath('.')) + 'Selenium/logs/'log_name = log_path + rq + '.log'fh = logging.FileHandler(log_name)fh.setLevel(logging.INFO)# 再创建一个handler,用于输出到控制台ch = logging.StreamHandler()ch.setLevel(logging.INFO)# 定义handler的输出格式formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')fh.setFormatter(formatter)ch.setFormatter(formatter)# 给logger添加handlerself.logger.addHandler(fh)self.logger.addHandler(ch)def getlog(self):return self.logger3、关于页面对象的写法参考:
页面对象继承于base_page基类
from framework.base_page import BasePagefrom selenium.webdriver.common.by import Byfrom framework.logger import Loggerlogger = Logger(logger="cloud_page").getlog()class Cloud(BasePage):#定位器input_box = (By.ID,'kw')search_submit = (By.XPATH,'//*[@id="su"]')def value_input(self, text):self.wait(self.input_box,5)self.send_keys(self.input_box, text)def submit_btn(self):self.click(self.search_submit)logger.info("show results!")self.sleep(2)4、testsuite部分,每个用例都要执行的用例前的准备setup和清理teardown写在test_base文件里,单个测试用例文件继承于它
from selenium import webdriverimport unittestclass TestBase(unittest.TestCase):def setUp(self):self.driver=webdriver.Chrome() #驱动浏览器self.driver.implicitly_wait(10) #设置隐式等待self.driver.maximize_window() #最大化浏览器def tearDown(self):self.driver.quit()if __name__=='__main__':unittest.main()测试用例参考,注意测试用例方法命名一定要以test开头
import timefrom testsuites.test_base import TestBasefrom pageobjects.baidu_page import Cloudclass BaiduSearch(TestBase):def test_baidu_search(self):"""这里一定要test开头,把测试逻辑代码封装到一个test开头的方法里。:return:"""input = Cloud(self.driver)input.open('https://www.baidu.com/')input.value_input('selenium') # 调用页面对象中的方法input.submit_btn() # 调用页面对象类中的点击搜索按钮方法time.sleep(2)input.get_windows_img() # 调用基类截图方法try:assert 'selenium' in 'selenium'print('Test Pass.')except Exception as e:print('Test Fail.', format(e))5、最后就是核心代码,testrunner.py 用来批量执行测试用例,引用HTMLTestRunner模块生成测试报告。
import unittestfrom HTMLTestRunner import HTMLTestRunnerimport timeimport os# 定义输出的文件位置和名字DIR = os.path.dirname(os.path.abspath(__file__))now = time.strftime("%Y%m%d%H%M", time.localtime(time.time()))filename =now+"report.html"#discover方法执行测试套件testsuite = unittest.defaultTestLoader.discover(start_dir='./testsuites',pattern='*case.py',top_level_dir=None)with open(DIR+'/test_report/'+filename,'wb') as f:runner = HTMLTestRunner(stream=f,verbosity=2,title='gateway UI report',description='执行情况',tester='tester')runner.run(testsuite)6、测试报告展示
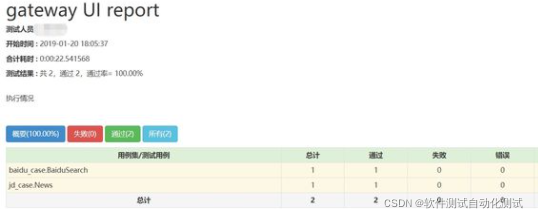
总结
基于selenium实现的web自动化框架不仅轻量级而且灵活,可以快速的开发自动化测试用例。本篇中的框架设计比较简单,希望对大家以后的web自动化框架的设计和实现有所帮助,共同交流,共同进步!
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!