目录
一、前言
二、如何区分【优先级队列】与【队列】?
三、priority_queue的介绍
四、priority_queue 的构造
五、priority_queue 的常用接口
💧push
💧pop
💧size
💧top
💧empty
💧swap
六、priority_queue 的模拟实现
🥝 堆的向上调整算法
🥝 堆的向下调整算法
🥝 priority_queue 的实现
七、priority_ququq 中的仿函数
八、priority_queue 的常考面试
九、总结
十、共勉
一、前言
优先级队列 priority_queue 是容器适配器中的一种,常用来进行对数据进行优先级处理,比如优先级高的值在前面,这其实就是数据结构中的 堆,它俩本质上是一样东西,底层都是以数组存储的完全二叉树,不过优先级队列 priority_queue 中加入了 泛型编程 的思想,并且属于 STL 中的一部分。本就就来详细的讲解一下 priority_queue 是如何使用的!!
二、如何区分【优先级队列】与【队列】?
首先要注意的就是别与 队列(queue)搞混了,队列是一种先进先出(First in First out,FIFO)的数据类型。每次元素的入队都只能添加到队列尾部,出队时从队列头部开始出。
优先级队列(priority_queue)其实,不满足先进先出的条件,更像是数据类型中的“堆”。优先级队列每次出队的元素是队列中优先级最高的那个元素,而不是队首的元素。这个优先级可以通过元素的大小等进行定义。比如定义元素越大优先级越高,那么每次出队,都是将当前队列中最大的那个元素出队。

三、priority_queue的介绍
priority_queue是C++标准库中的一个容器适配器(container adapter),用于实现优先队列(priority queue)的数据结构。优先队列是一种特殊的队列,其中的元素按照一定的优先级进行排序,每次取出的元素都是优先级最高的。它的底层实现通常使用堆(heap)数据结构。
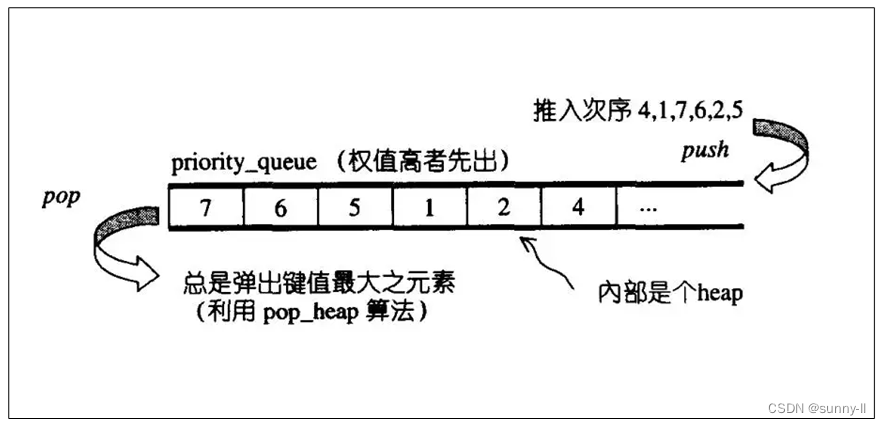
- 在C++中,
priority_queue模板类定义在<queue>头文件中,可以通过指定元素类型和比较函数来创建不同类型的优先队列。比较函数用于确定元素的优先级,可以是函数指针、函数对象或Lambda表达式。 -
priority_queue被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类。元素从特定容器的”尾部“弹出,其称为优先级队列的顶部

⭕需要注意的是,默认情况下,
priority_queue使用std::less作为比较函数,即元素的优先级按照从大到小的顺序排列。如果需要按照从小到大的顺序排列,可以使用std::greater作为比较函数。
四、priority_queue 的构造
优先级队列 默认使用 vector 作为底层存储数据的容器,在 vector 上又使用了 堆算法 将 vector 中的元素构造成堆的结构,因此 priority_queue 就是 ---- 堆,所以在需要用到 堆 的地方,都可以考虑使用 priority_queue
注意:默认情况下 priority_queue 是 大堆

优先级队列的构造方式有两种:直接构造一个空对象 和 通过迭代器区间进行构造
(1)直接构造一个空对象
#include <iostream>
#include <vector>
#include <queue> //注意:优先级队列包含在 queue 的头文件中using namespace std;int main()
{priority_queue<int> pq; //直接构造一个空对象,默认为大堆cout << typeid(pq).name() << endl; //查看类型return 0;
}
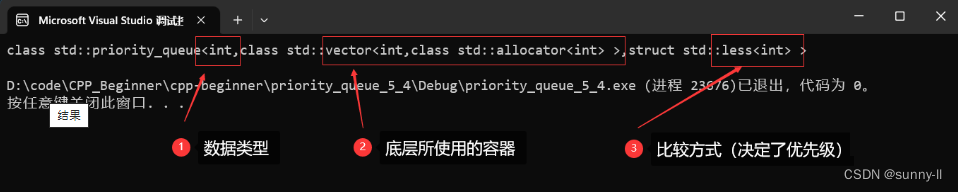
注意: 默认比较方式为 less,最终为 优先级高的值排在上面(大堆)
(2)通过迭代器区间构造对象
#include <iostream>
#include <vector>
#include <queue> //注意:优先级队列包含在 queue 的头文件中using namespace std;int main()
{vector<char> vc = { 'a','b','c','d','e' };priority_queue<char, deque<char>, greater<char>> pq(vc.begin(), vc.end()); //现在是小堆cout << typeid(pq).name() << endl; //查看类型cout << "==========================" << endl;while (!pq.empty()){//将小堆中的堆顶元素,依次打印cout << pq.top() << " ";pq.pop();}return 0;
}

注意: 将比较方式改为 greater 后,生成的是 小堆,并且如果想修改比较方式的话,需要指明模板参数2 底层容器,因为比较方式位于模板参数3,不能跳跃缺省(遵循缺省参数规则)
测试数据:【
27,15,19,18,28,34,65,49,25,37】分别生成 大堆 与 小堆
大堆 :
vector<int> v = { 27,15,19,18,28,34,65,49,25,37 };
priority_queue<int, vector<int>, less<int>> pq(v.begin(), v.end());
//priority_queue<int> pq(v.begin(), v.end()); //两种写法结果是一样的,默认为大堆

小堆:
vector<int> v = { 27,15,19,18,28,34,65,49,25,37 };
priority_queue<int, vector<int>, greater<int>> pq(v.begin(), v.end()); //生成小堆

五、priority_queue 的常用接口
优先级队列的接口也很简单,唯一需要注意的是,每插入一个元素,都会进行排序,主要看你构建的是大堆还是小堆。
💧push
在优先级队列的尾部插入 一个 新的元素,每次插入前调用 堆排序算法,将其重新排序在堆中的位置

void test_priority_queue()
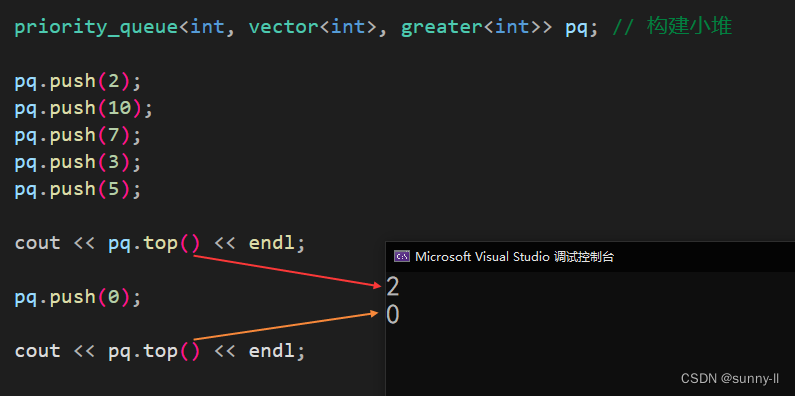
{priority_queue<int, vector<int>, greater<int>> pq; // 构建小堆pq.push(2);pq.push(10);pq.push(7);pq.push(3);pq.push(5);cout << pq.top() << endl;pq.push(0);cout << pq.top() << endl;
}
- 可以看到,我们构建的是小堆,排好序以后,队头(堆顶)的数据就是 2 ,重新插入一个 0 以后,会重新排序,此时队头(堆顶)的数据就是 0
💧pop
删除位于优先级队列顶部的元素,有效的将其大小减少 1,其实就是删除队头元素

void test_priority_queue()
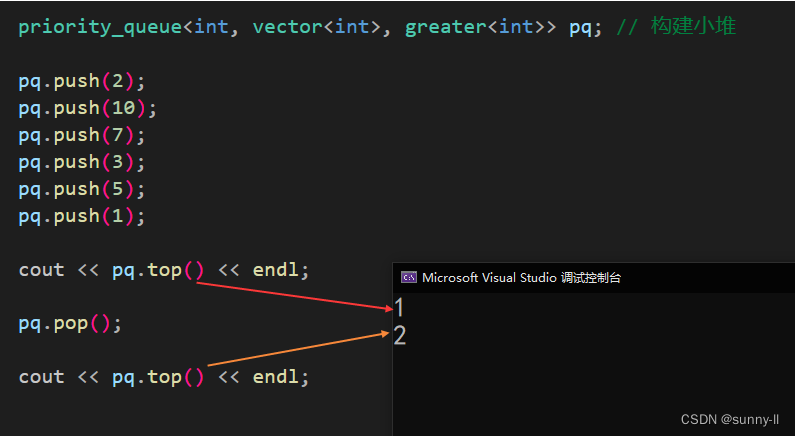
{priority_queue<int, vector<int>, greater<int>> pq; // 构建小堆pq.push(2);pq.push(10);pq.push(7);pq.push(3);pq.push(5);pq.push(1);cout << pq.top() << endl;pq.pop();cout << pq.top() << endl;
}
💧size
返回优先级队列的元素数量

void test_priority_queue()
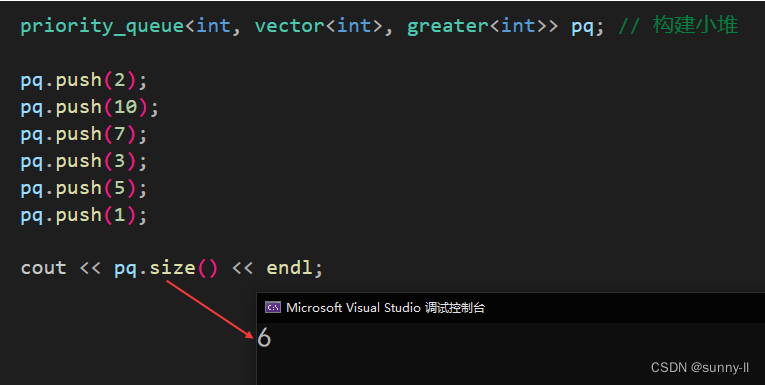
{priority_queue<int, vector<int>, greater<int>> pq; // 构建小堆pq.push(2);pq.push(10);pq.push(7);pq.push(3);pq.push(5);pq.push(1);cout << pq.size() << endl;}
💧top
返回 优先级队列中顶部元素的常量引用,顶部元素实在优先级队列中比较高的元素

void test_priority_queue()
{priority_queue<int, vector<int>, greater<int>> pq; // 构建小堆pq.push(2);pq.push(10);pq.push(7);pq.push(3);pq.push(5);pq.push(1);cout << pq.top() << endl;
}
💧empty
测试容器是否为空

优先级队列同样也不支持迭代器的遍历,所以可以使用 empty 配合 top 和 pop 来实现
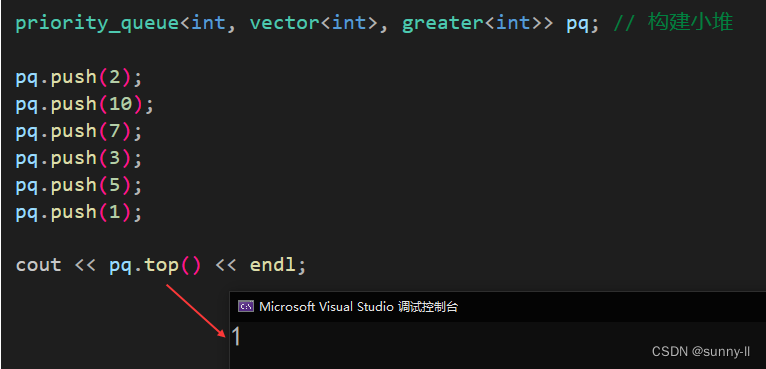
void test_priority_queue()
{priority_queue<int, vector<int>, greater<int>> pq; // 构建小堆pq.push(2);pq.push(10);pq.push(7);pq.push(3);pq.push(5);pq.push(1);while (!pq.empty()) {cout << pq.top() << " ";pq.pop();}
}
💧swap
交换两个优先级队列的内容

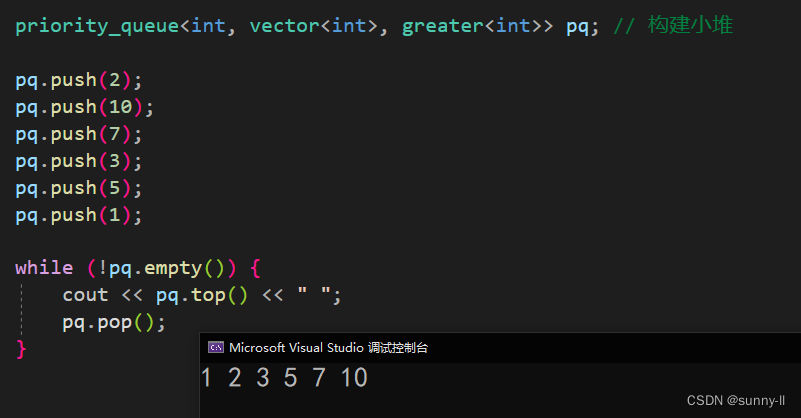
void test_priority_queue()
{priority_queue<int> pq1; // 构建小堆pq1.push(2);pq1.push(1);pq1.push(7);pq1.push(3);priority_queue<int> pq2;pq2.push(5);pq2.push(1);pq2.push(2);pq1.swap(pq2);while (!pq1.empty()) {cout << pq1.top() << " ";pq1.pop();}cout << endl;while (!pq2.empty()) {cout << pq2.top() << " ";pq2.pop();}
}
注意:交换的前提必须是 两个队列构建都是相同的类型的堆
六、priority_queue 的模拟实现
我们知道「priority_ queue」 的底层就是堆,所以在模拟实现之前,要先实现堆的调整算法。
🥝 堆的向上调整算法
假设我们现在已经有一个大堆, 我们需要在堆的末尾插入数据,然后对其进行调整,使其仍然保持大堆的结构。
堆的向上调整算法基本思想: (以建 大堆为例)
- 将要插入的数据与其父节点数据比较
- 若插入节点的数据大于父节点的数据,则交换位置,交换以后,插入的节点继续进行向上调整(此时该节点叔和上面的父节点比
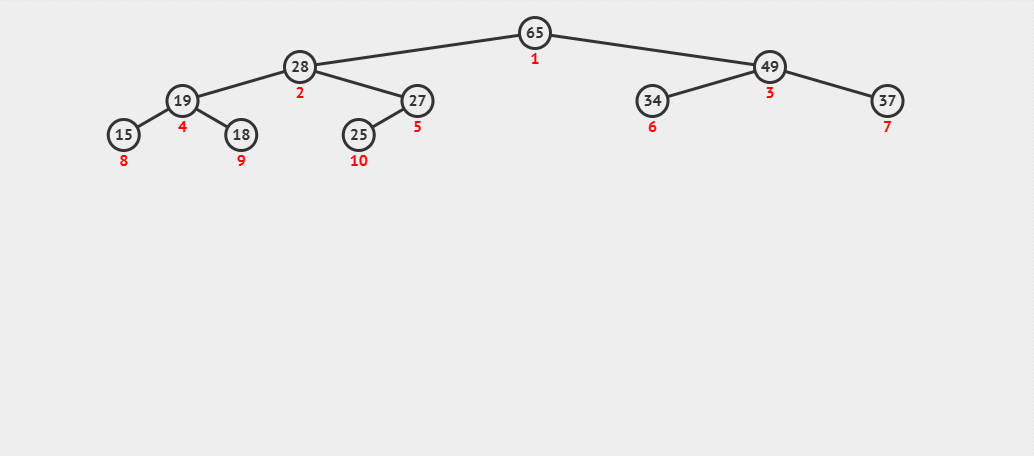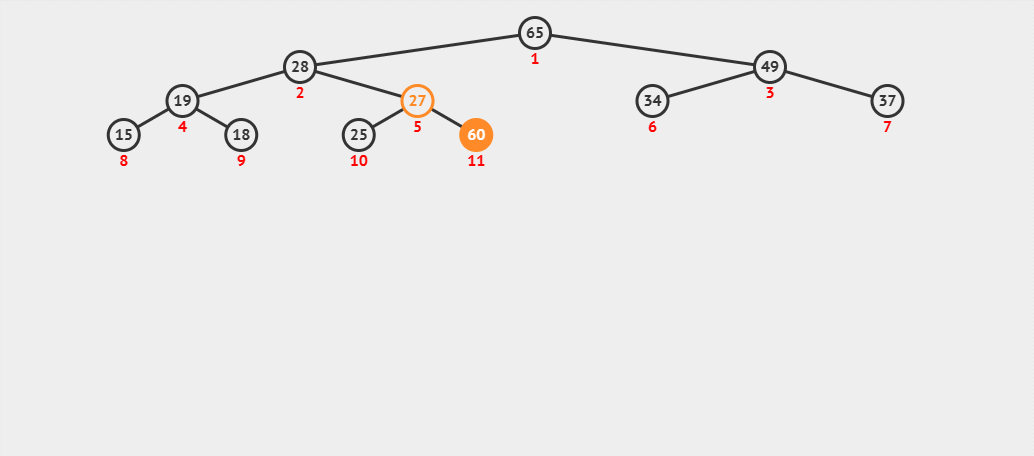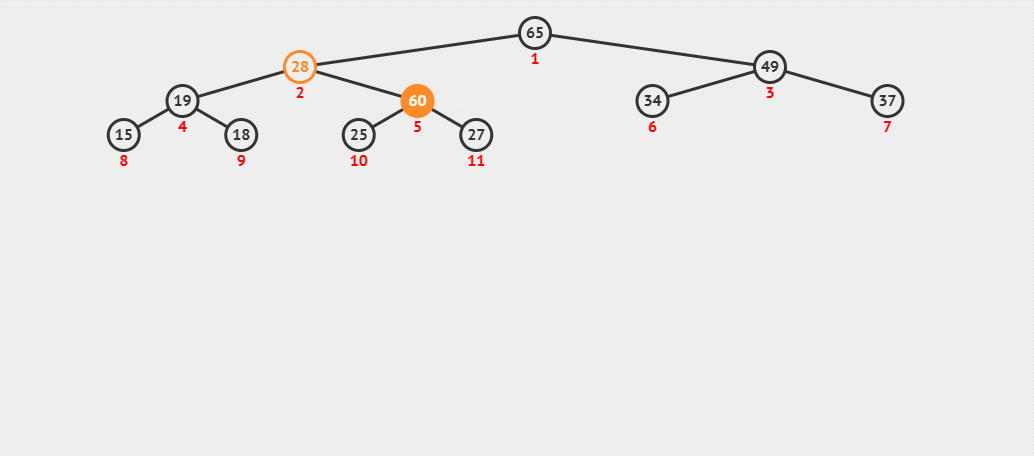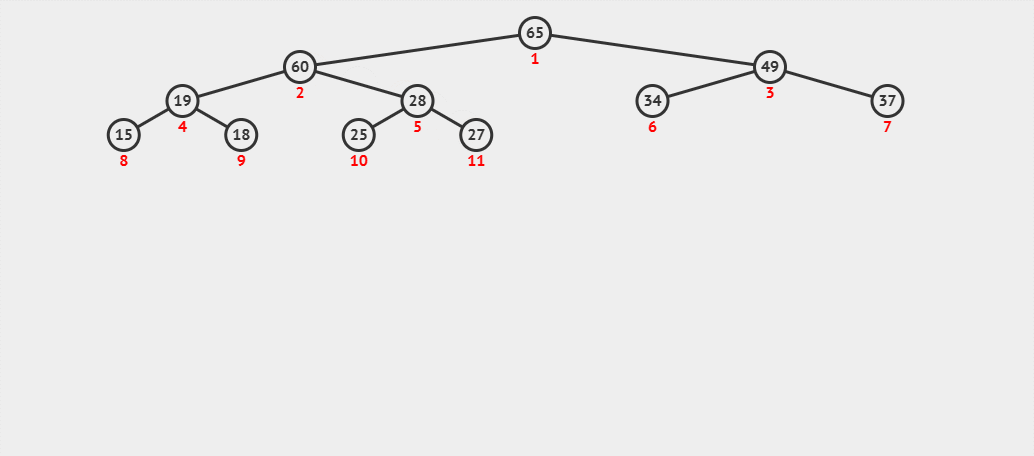
来看一个动图 :
- (1) 首先我们在该大堆的末尾插入数据 60。
- (2) 我们先将 60 与其父结点 27 进行比较,发现 60 比其父结点大,则交换父子结点的数据,并继续进行向.上调整。
- (3) 此时将 60 与其父结点 28 进行比较,发现 60 还是比父结点大,则继续交换父子结点的数据,并继续进行向上调整。
- (4) 这时再将 60 与其父结点 65 进行比较,发现 60 比其父结点小,则停止向上调整,此时该树已经就是大堆了。
堆 的向上调整代码:
void AdjustUp(vector<int>& v1, int child)
{int parent = ((child - 1) >> 1); // 通过child计算parent的下标while (child > 0) //调整到根结点的位置截止{if (v1[parent] < v1[parent]){// 父节点与子节点交换swap(v1[child], v1[parent]);// 继续向上调整child = parent;parent = ((child - 1) >> 1);}else {break;}}
}
🥝 堆的向下调整算法
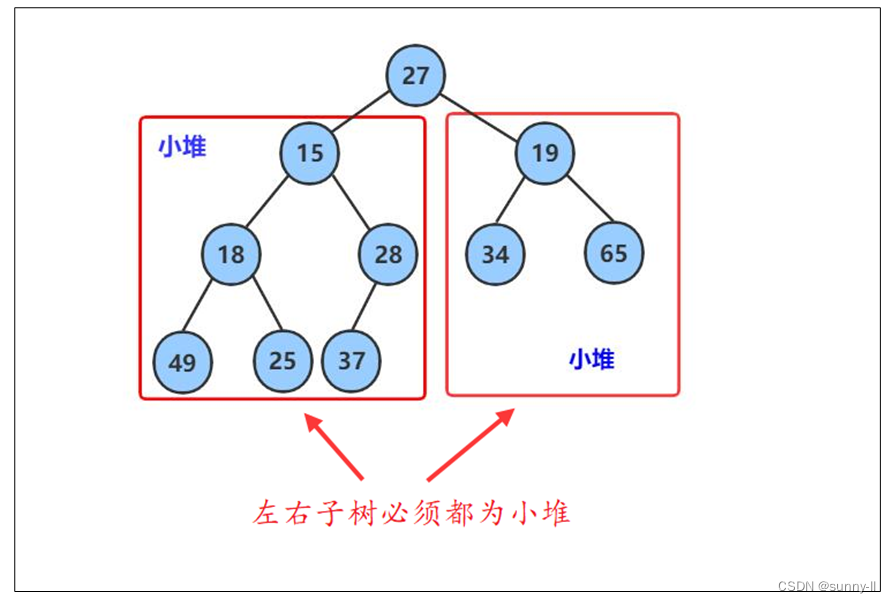
以小堆为例,向下调整算法有一个前提,就是待向下调整的结点的左子树和右子树必须都为小堆
堆的向下调整算法基本思想: (以建小堆为例)
- 从根节点开始,选出左右孩子节点中值较小的一个,让父亲与较小的孩子比较。
- 若父亲大于此孩子那么交换,交换以后,继续进行向下调整;若父亲小于此孩子,则不交换,停止向下调整,此时该树已经是小堆
如下图所示:将该二叉树从根结点开始进行向下调整。(此时根结点的左右子树已经是小堆)
将 27 与其较小的子结点 15 进行比较,发现 25 其较小的子结点大,则交换这两个结点的数据,并继续进行向下调整。
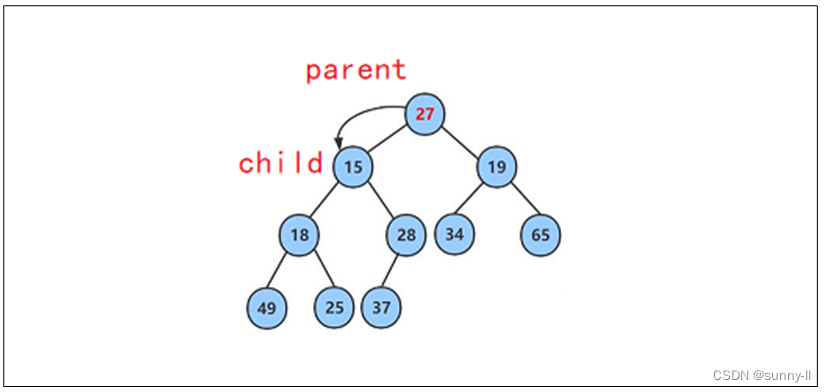
此时再将27与其较小的子结点18进行比较,发现27其较大的子结点大,则再交换这两个结点的数据,并继续进行向下调整。
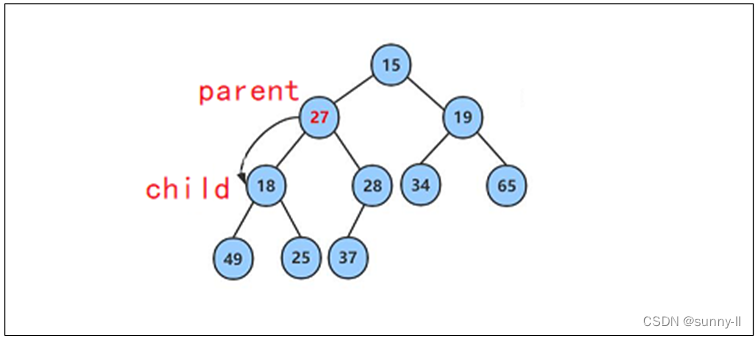
此时再将27与其较小的子结点25进行比较,发现27其较小的子结点大,则再交换这两个结点的数据,并继续进行向下调整。
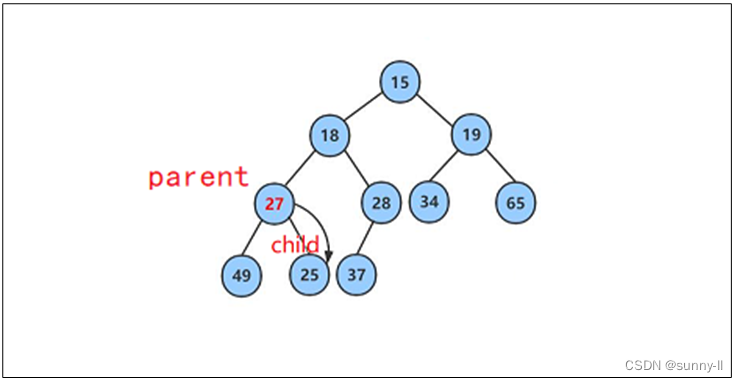
此时该树,就因该是小堆啦
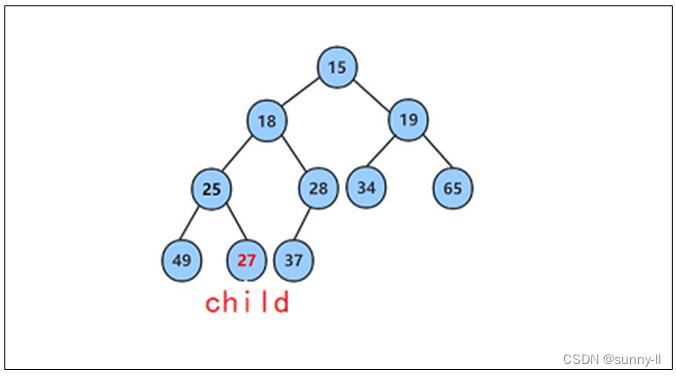
堆的向下调整代码:
//堆的向下调整(小堆)
void AdjustDown(vector<int>& v1, int n, int parent)
{//child记录左右孩子中值较大的孩子的下标int child = 2 * parent + 1;//先默认其左孩子的值较小while (child < n){if (child + 1 < n && v1[child + 1] < v1[child])//右孩子存在并且右孩子比左孩子小{child++;//较小的孩子改为右孩子}if (v1[child] < v1[parent])//左右孩子中较小孩子的值比父结点还小{//将父结点与较小的子结点交换swap(v1[child], v1[parent]);//继续向下进行调整parent = child;child = 2 * parent + 1;}else{break;}}
}
🥝 priority_queue 的实现
通过对「priority_ _queue」 的了 解其底层结构就是堆,此处只需对堆的调整算法和常用接口进行通用的封装即可。
namespace xas
{// 比较方式(使内部结构为大堆)template<class T>struct less{bool operator()(const T& x, const T& y) const{return x < y;}};// 比较方式(使内部结构为小堆)template<class T>struct greater{bool operator()(const T& x, const T& y) const{return x > y;}};// 优先级队列 --- 大堆 < --- 小堆 >template<class T, class Container = vector<T>, class Compare = less<T>>class priority_queue{Compare _comFunc; // 比较方式public:// 创造空的优先级队列priority_queue(const Compare& comFunc = Compare()):_comFunc(comFunc){}// 以迭代器区间来建堆template <class InputIterator>priority_queue(InputIterator first, InputIterator last, const Compare& comFunc = Compare()): _comFunc(comFunc){while (first != last){_con.push_back(*first);++first;}// 建堆for (int i = (_con.size() - 1 - 1) / 2; i >= 0; --i){AdjustDown(i);}}// 堆的向上调整void AdjustUp(int child){int parent = (child - 1) / 2; // 通过child计算parent的下标while (child > 0){if (_comFunc(_con[parent], _con[child])) // 通过所给比较方式确定是否需要交换结点位置{swap(_con[parent], _con[child]); // 将父结点与孩子结点交换child = parent; //继续向上进行调整parent = (child - 1) / 2;}else{break;}}}// 插入元素到队尾(并排序)// 在容器尾部插入元素后进行一次向上调整算法void push(const T& x){_con.push_back(x);AdjustUp(_con.size() - 1);}// 堆的向下调整void AdjustDown(int parent){size_t child = parent * 2 + 1;while (child < _con.size()){if (child + 1 < _con.size() && _comFunc(_con[child], _con[child + 1])){++child;}if (_comFunc(_con[parent], _con[child])) //通过所给比较方式确定是否需要交换结点位置{swap(_con[parent], _con[child]); //将父结点与孩子结点交换parent = child; //继续向下进行调整child = parent * 2 + 1;}else{break;}}}// 删除队头元素(堆顶元素)// 将容器头部和尾部元素交换,再将尾部元素删除,最后从根结点开始进行一次向下调整算法void pop(){assert(!_con.empty());swap(_con[0], _con[_con.size() - 1]);_con.pop_back();AdjustDown(0);}// 访问队头元素(堆顶元素)const T& top(){return _con[0];}// 获取队列中有效元素个数size_t size(){return _con.size();}// 判断队列是否为空bool empty(){return _con.empty();}private:Container _con;};// 测试函数void test_priority_queue1(){priority_queue<int> pq1; // 构建大堆pq1.push(2);pq1.push(1);pq1.push(7);pq1.push(5);pq1.push(3);pq1.push(10);pq1.push(4);while (!pq1.empty()) {cout << pq1.top() << " ";pq1.pop();}}// 测试函数void test_priority_queue2(){priority_queue<int, vector<int>, greater<int>> pq2; // 构建小堆pq2.push(2);pq2.push(1);pq2.push(7);pq2.push(5);pq2.push(3);pq2.push(10);pq2.push(4);while (!pq2.empty()) {cout << pq2.top() << " ";pq2.pop();}}
}

七、priority_ququq 中的仿函数
在
priority_queue中,仿函数用于比较元素的优先级,并根据其返回值确定它们在队列中的位置。默认情况下,priority_queue使用std::less作为仿函数,也就是将元素按照从大到小的顺序进行排序。
你可以使用不同的仿函数来改变元素的排序方式。以下是一些常见的仿函数:
std::less<T>:对于基本数据类型和自定义类型,默认使用<运算符进行比较,按照从大到小的顺序排序。std::greater<T>:对于基本数据类型和自定义类型,默认使用>运算符进行比较,按照从小到大的顺序排序。
除了上述默认提供的仿函数外,你还可以自定义仿函数来实现自定义的元素比较规则。自定义仿函数需要满足严格弱排序(Strict Weak Ordering)的要求,即:
- 比较关系必须是可传递的(transitive):对于任意元素a、b和c,如果a与b比较相等,b与c比较相等,则a与c比较也相等。
- 比较关系不能是部分顺序(partial order):对于任意元素a和b,它们不能同时大于、小于或等于彼此。
- 比较关系必须是可比较的(comparable):比较关系的结果必须对所有元素定义明确的大小关系。
以下这段代码,演示了如何自定义一个仿函数来实现元素的自定义排序方式:
// 创建一个 身份结构体
struct Person
{string name;int age;// 构造函数Person(const string& n, int a):name(n), age(a){}
};// 自定义仿函数
struct Compare
{// 函数重载()bool operator()(const Person& p1, const Person& p2)const{//按照年龄从下到大排序return p1.age > p2.age;}
};int main()
{priority_queue<Person, vector<Person>, Compare> pq;pq.push(Person("Alice", 25));pq.push(Person("Bob", 30));pq.push(Person("Charlie", 20));while (!pq.empty()) {Person p = pq.top();pq.pop();cout << p.name << " - " << p.age << endl;}return 0;
}输出结果为:
Charlie - 20
Alice - 25
Bob - 30
在上面的代码中,我们定义了一个名为Compare的结构体,重载了函数调用运算符operator(),按照Person对象的age成员进行比较。然后,我们将Compare作为优先队列的仿函数类型,并插入3个Person对象到优先队列中。最后,我们按照自定义的排序方式依次取出元素并输出。
八、priority_queue 的常考面试
优先级队列(堆)可以用来进行排序和解决
Top-K问题,比如查找第 k 个最大的值就比较适合使用优先级队列
215. 数组中的第K个最大元素 - 力扣(LeetCode)

思路:利用数组建立大堆,数组从大到小排序,删除前k-1个元素,选出队头即可
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {// 将数组中的元素 放入 优先级队列--堆priority_queue<int> p(nums.begin(),nums.end());// 将优先级队列 中的前K-1 个元素删除掉for(int i = 0;i< k-1;i++){p.pop();}return p.top();}
};九、总结
优先队列是一种特殊的队列,其中存储的元素按照一定的优先级进行排列。在priority_queue中,优先级最高的元素能够快速被访问和删除。
- 首先,我们介绍了priority_queue的概念和特点。它是基于堆(heap)这种数据结构实现的,通常使用最大堆来进行内部排序。最大堆保证了根节点的值最大,并且任意节点的值大于或等于其子节点的值。这种特性使得优先队列能够高效地访问和删除具有最高优先级的元素。
- 接着,我们深入探讨了priority_queue的使用方法。基本操作包括插入元素、删除元素、访问元素和检查队列是否为空。
- 底层结构是priority_queue的关键部分,它通常使用堆来实现。在堆中,通过使用数组的索引来表示节点之间的关系,能够快速定位和操作元素。
- 最后,我们探讨了在priority_queue中使用的仿函数。仿函数用于确定元素之间的优先级,决定元素在队列中的位置。默认情况下,priority_queue使用std::less仿函数进行比较,对元素进行降序排列。你还可以选择其他仿函数或自定义仿函数来实现不同的排序方式。
十、共勉
以下就是我对 【priority_queue优先级队列】 的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对 C++STL 的理解,请持续关注我哦!!!