文章目录
- 📑前言
- 一、分片(Shard)
- 1.1 分片的定义
- 1.2 分片的重要性
- 1.3 分片的类型
- 1.4 分片的分配
- 二、副本(Replica)
- 2.1 副本的定义
- 2.2 副本的重要性
- 2.3 副本的分配
- 三、分片和副本的机制
- 3.1 分片的创建和分配
- 3.2 数据写入过程
- 3.3 数据读取过程
- 四、分片和副本的配置
- 4.1 配置分片数量
- 4.2 配置副本数量
- 4.3 分片和副本的最佳实践
- 五、分片和副本的故障恢复
- 5.1 主分片故障恢复
- 5.2 副本分片故障恢复
- 5.3 故障恢复的配置
- 六、分片和副本的监控
- 6.1 监控分片状态
- 6.2 监控集群健康状态
- 6.3 监控指标
- 七、小结

📑前言
Elasticsearch是一种分布式搜索和分析引擎,它具有高扩展性和高可用性。为了实现这些特性,Elasticsearch引入了分片(Shard)和副本(Replica)的概念。本文将详细介绍Elasticsearch中的分片和副本机制,帮助读者理解它们的重要性及其实现方法。
一、分片(Shard)
1.1 分片的定义
分片是Elasticsearch中存储数据的基本单位。一个索引可以由多个分片组成,每个分片都是一个独立的Lucene索引。通过分片,Elasticsearch可以将数据分布到多个节点上,从而实现数据的分布式存储和并行处理。
1.2 分片的重要性
分片机制使Elasticsearch具有以下优势:
- 水平扩展:通过增加分片数量,可以水平扩展索引的存储容量和处理能力。
- 并行处理:分片可以分布在不同的节点上,允许多个节点并行处理查询和索引请求,提高系统的性能和吞吐量。
- 数据分布:分片机制使数据可以分布在集群的多个节点上,减少单点故障的风险,提高数据的可用性和可靠性。
1.3 分片的类型
Elasticsearch中的分片分为两种类型:
- 主分片(Primary Shard):主分片是原始的数据分片,所有的写操作(如索引和删除)都首先作用于主分片。
- 副本分片(Replica Shard):副本分片是主分片的复制品,用于提高数据的可用性和查询性能。副本分片接收来自主分片的数据更新,并在主分片不可用时提供冗余。
1.4 分片的分配
Elasticsearch在创建索引时,用户可以指定索引的分片数量。默认情况下,一个索引包含5个主分片。分片的数量一旦设置,主分片的数量是无法更改的(除非重新创建索引)。然而,副本分片的数量可以在索引创建后动态调整。
二、副本(Replica)
2.1 副本的定义
副本是主分片的完整复制品,它用于提高系统的容错能力和查询性能。每个主分片可以有多个副本分片,这些副本分片分布在集群的不同节点上。
2.2 副本的重要性
副本机制带来了以下好处:
- 高可用性:副本分片提供了数据冗余,当主分片所在节点出现故障时,副本分片可以提升为主分片,保证数据的可用性。
- 负载均衡:副本分片可以分担查询负载,减少主分片的压力,提高系统的查询性能和响应速度。
- 数据恢复:当节点发生故障时,副本分片可以用于快速恢复数据,减少系统的停机时间。
2.3 副本的分配
副本分片的数量可以在索引创建时指定,默认情况下,每个主分片有一个副本分片。与主分片不同,副本分片的数量可以在索引创建后动态调整。Elasticsearch会自动管理分片和副本的分配,确保它们分布在集群的不同节点上,以最大限度地提高系统的容错能力和性能。
三、分片和副本的机制
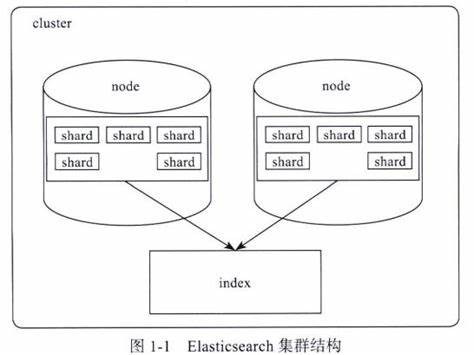
3.1 分片的创建和分配
当创建一个新索引时,Elasticsearch会根据用户指定的分片数量创建主分片,并将这些分片分配到集群中的不同节点上。分片的分配过程如下:
- 分片创建:Elasticsearch根据索引的分片设置,创建指定数量的主分片。
- 分片分配:Elasticsearch将主分片分配到集群中的不同节点上,确保分片均匀分布。
- 副本创建:Elasticsearch根据索引的副本设置,为每个主分片创建副本分片。
- 副本分配:Elasticsearch将副本分片分配到与主分片不同的节点上,确保数据冗余。
3.2 数据写入过程
在Elasticsearch中,数据的写入过程包括以下步骤:
- 写请求发送到主分片:所有的写操作(如索引和删除)首先发送到主分片。
- 主分片处理写请求:主分片处理写请求,将数据写入到分片中。
- 写请求同步到副本分片:主分片将写操作同步到所有的副本分片,确保数据的一致性。
- 写操作完成:当所有副本分片确认写操作后,Elasticsearch返回写操作的结果。
3.3 数据读取过程
在Elasticsearch中,数据的读取过程包括以下步骤:
- 读请求发送到协调节点:客户端将查询请求发送到Elasticsearch集群中的任意节点,该节点作为协调节点处理请求。
- 协调节点路由请求:协调节点将查询请求路由到相关的主分片和副本分片。
- 分片并行处理查询:主分片和副本分片并行处理查询请求,返回查询结果。
- 协调节点汇总结果:协调节点汇总所有分片的查询结果,并返回给客户端。
四、分片和副本的配置
4.1 配置分片数量
在创建索引时,可以通过number_of_shards参数指定分片数量。例如:
PUT /my_index
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}
上述配置将创建一个包含3个主分片和每个主分片有1个副本分片的索引。
4.2 配置副本数量
副本数量可以在索引创建后动态调整。例如:
PUT /my_index/_settings
{"number_of_replicas": 2
}
上述配置将my_index索引的副本数量调整为2。
4.3 分片和副本的最佳实践
为了优化Elasticsearch的性能和可用性,建议遵循以下最佳实践:
- 合理设置分片数量:分片数量应根据数据量和集群节点数量进行设置,避免分片过多导致管理开销过大。
- 均匀分布分片:确保分片和副本均匀分布在集群的不同节点上,避免单点故障。
- 监控和调整:定期监控分片和副本的状态,根据需要调整配置,确保系统的稳定性和性能。
五、分片和副本的故障恢复
5.1 主分片故障恢复
当主分片所在节点发生故障时,Elasticsearch会自动将对应的副本分片提升为主分片,确保数据的可用性。故障恢复过程如下:
- 节点故障检测:Elasticsearch检测到节点故障,标记节点上的分片为不可用。
- 副本提升为主分片:Elasticsearch将副本分片提升为主分片,确保数据的可用性。
- 重新分配副本分片:Elasticsearch在集群中的其他节点上创建新的副本分片,恢复数据冗余。
5.2 副本分片故障恢复
当副本分片所在节点发生故障时,Elasticsearch会在集群中的其他节点上重新创建副本分片,确保数据的冗余。故障恢复过程如下:
- 节点故障检测:Elasticsearch检测到节点故障,标记节点上的副本分片为不可用。
- 重新创建副本分片:Elasticsearch在集群中的其他节点上创建新的副本分片,恢复数据冗余。
5.3 故障恢复的配置
Elasticsearch允许用户配置故障恢复的行为,以满足不同的应用需求。例如,可以通过index.unassigned.node_left.delayed_timeout参数设置节点故障后重新分配分片的延迟时间:
PUT /my_index/_settings
{"index.unassigned.node_left.delayed_timeout": "5m"
}
上述配置将设置在节点故障后延迟5分钟重新分配分片,以防止短暂的网络问题导致不必要的分片重新分配。
六、分片和副本的监控
6.1 监控分片状态
Elasticsearch提供了多种工具和API来监控分片和副本的状态。例如,可以使用_cat/shards API查看索引的分片分配情况:
GET /_cat/shards/my_index?v
该命令将显示my_index索引的所有分片及其所在节点的信息。
6.2 监控集群健康状态
Elasticsearch的_cluster/health API可以用于监控集群的健康状态,包括分片和副本的状态:
GET /_cluster/health
该命令将返回集群的健康状态,包括分片和副本的数量、状态和分配情况。
6.3 监控指标
为了更全面地监控Elasticsearch的性能和健康状态,可以使用开源的监控工具,如Elasticsearch自身的监控插件(X-Pack Monitoring)、Prometheus和Grafana。这些工具可以帮助用户实时监控集群的各种性能指标,包括分片分配、查询性能、节点资源使用情况等。
七、小结
Elasticsearch的分片和副本机制是其实现高扩展性和高可用性的核心。通过合理配置分片和副本,Elasticsearch能够在大规模数据处理和高并发访问的场景下提供稳定高效的性能。同时,分片和副本机制也为系统提供了容错能力和数据冗余,确保在节点故障时数据的可用性。