Raft
raft 会进入脑裂状态吗?描述下场景,怎么解决?
不会。raft通过选举安全性解决了这个问题:
- 一个任期内,follower 只会投票一次票,且先来先得;
- Candidate 存储的日志至少要和 follower 一样新;
- 只有获得超过半数投票才有机会成为 leader;
讲一下 raft 的 leader 选举流程
Leader 在任期内会周期性向其他 follower 节点发送心跳来维持地位。follower 如果发现心跳超时,就认为 leader 节点宕机或不存在。随机等待一定时间后,follower 会发起选举,变成 candidate,然后去竞选 leader。选举结果有三种情况:
- 获取超过半数投票,赢得选举:
- 当 Candidate 获得超过半数的投票时,化为 leader。会向其他节点发送请求,确认自己的 leader 地位,从而阻止新一轮的选举
- 投票原则:当多个 Candidate 竞选 Leader 时:
- 一个任期内,follower 只会投票一次票,且投票先来显得;
- Candidate 存储的日志至少要和 follower 一样新(安全性准则),否则拒绝投票;
- 投票未超过半数,选举失败:
- 当 Candidate 没有获得超过半数的投票时,说明多个 Candidate 竞争投票导致过于分散,或者出现了丢包现象。此时,认为当期任期选举失败,任期 TermId+1,然后发起新一轮选举;
- 收到其他 Leader 通信请求:
- 如果 Candidate 收到其他声称自己是 Leader 的请求的时候,通过任期 TermId 来判断是否处理;
- 如果请求的任期 TermId 不小于 Candidate 当前任期 TermId,那么 Candidate 会承认该 Leader 的合法地位并转化为 Follower;
- 否则,拒绝这次请求,并继续保持 Candidate;
如果主仲裁一致写入但是没有回复成功的时候挂了怎么办
加消息序列号,如果已经写入直接返回成功
时钟不准确问题
raft不依赖墙上时钟,而是使用逻辑日志解决
有多个 candidate 发起选举怎么解决?
选举时间设置为随机的150ms到300ms之间,为了尽量避免产生多个candidate的情况。
如果多个follower同时变为candidate,那么有可能出现票数<n/2+1的情况,导致选举失败,开始下一轮选举。
什么是幽灵复现问题?描述一下?raft会出现这些问题吗?raft如何解决?
第一种场景(raft不会出现,因为旧主的任期号和日志小于新主,不会被通过)
- 第一轮中A被选为Leader,写下了1-10号日志,其中1-5号日志形成了多数派,并且已给客户端应答,而对于6-10号日志,客户端超时未能得到应答。
- 第二轮,A宕机,B被选为Leader,由于B和C的最大的logID都是5,因此B不会去重确认6-10号日志,而是从6开始写新的日志,此时如果客户端来查询的话,是查询不到6-10号日志内容的,此后第二轮又写入了6-20号日志,但是只有6号和20号日志在多数派上持久化成功。
- 第三轮,A又被选为Leader,从多数派中可以得到最大logID为20,因此要将7-20号日志执行重确认,其中就包括了A上的7-10号日志,之后客户端再来查询的话,会发现上次查询不到的7-10号日志又像幽灵一样重新出现了。
第二种场景
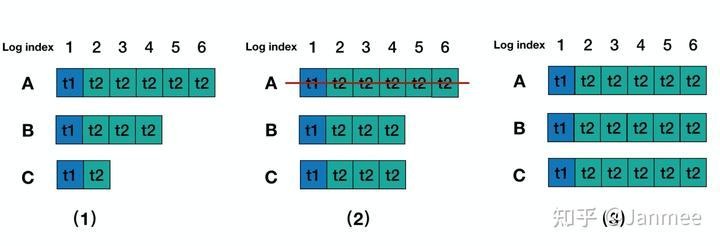
(1)Round 1,A节点为leader,Log entry 5,6内容还没有commit,A节点发生宕机。这个时候client 是查询不到 Log entry 5,6里面的内容
(2)Round 2,B成为Leader, B中Log entry 3, 4内容复制到C中, 并且在B为主的期间内没有写入任何内容。
(3)Round 3,A 恢复并且B、C发生重启,A又重新选为leader, 那么Log entry 5, 6内容又被复制到B和C中,这个时候client再查询就查询到Log entry 5, 6 里面的内容了。
对于之前Term的未Committed数据,修复到多数节点,且在新的Term下至少有一条新的Log Entry被复制或修复到多数节点之后,才能认为之前未Committed的Log Entry转为Committed。
选举超时的设置一般多久,为什么这么设置?
随机的150ms到300ms
优化raft读请求
假如我在当前 Leader 上读时,其它节点已经选出了一个新的 Leader,并且写入了新的内容,而当前旧 Leader 暂时没有感知到这个变化,而是正常执行了读操作,显然读取到的也不是最新的内容。
- breatheart方案 同步一个空 LogEntry 以更新 commit index,等待半数breatheart,如果通过,commit index为最新
- **lease方案 lease时间为 **“发出心跳的时间点”+ election timeout, 这个时候的读是ok的
如何从从节点读取保证线性一致?
从节点在收到读请求时,向主节点“索要”当前时间的最新 commit index 即可,主节点收到这个“索要”请求后,只需执行 1-3 步便可得到这个 commit index。
对于对称网络分区问题如何优化?
pre vote 为了防止网络恢复后断连的分区导致新的选举发生,某个节点 election timeout 时,**不改变 term **,而是直接发送 RequestVote 请求,进行 Pre Vote

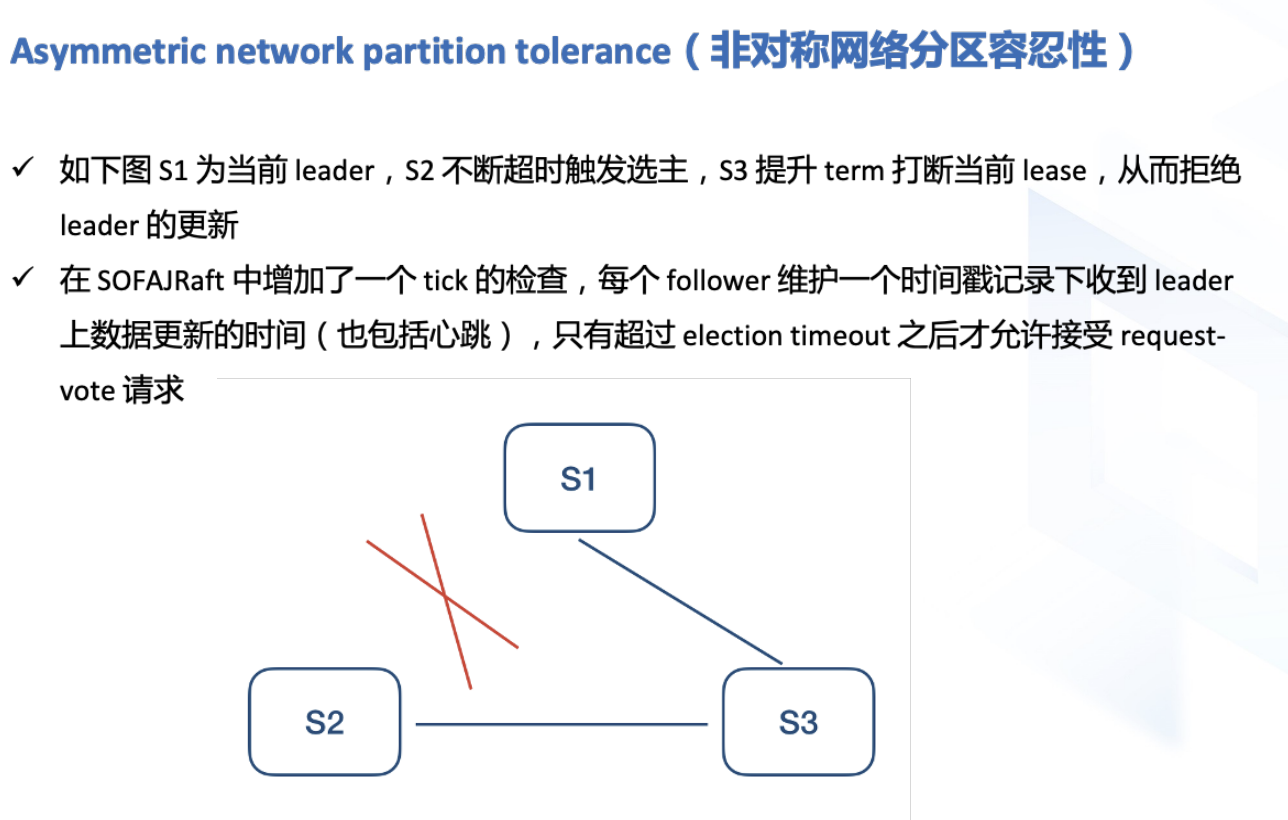
对于非对称网络分区问题如何优化?
同样,非对称分区也会出发follower选主,拒绝更新请求,解决方法是follower维护一个tick值,只有这个值小于当前时间-选举时间才会投票。(不是说选主就选主,而是根据心跳来决定)
Kafka
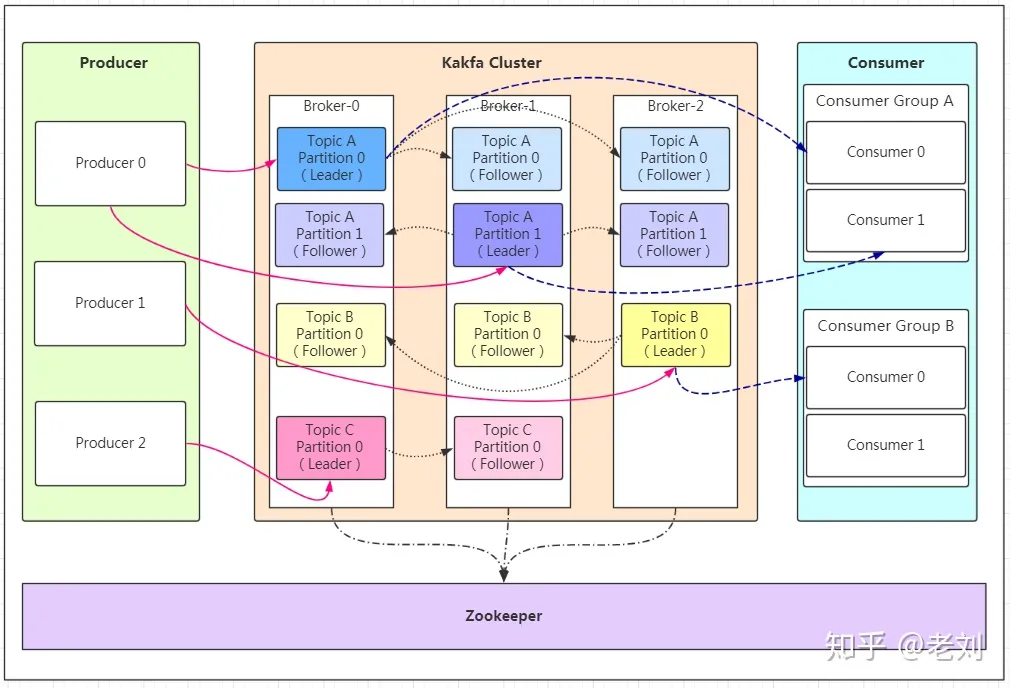
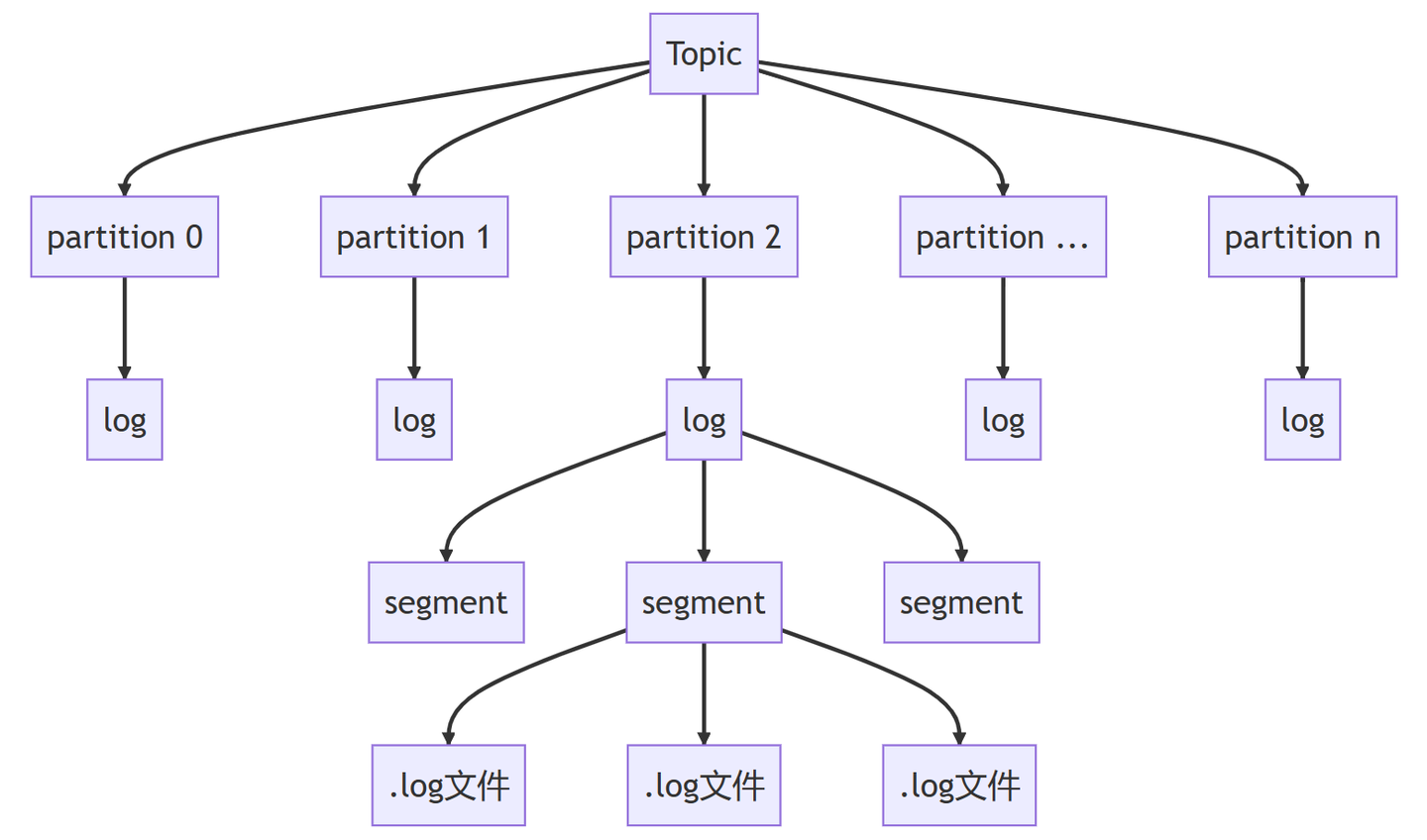
kafka集群架构
kafka的架构如下所示(消息在partiiton分区内部有序,不能保证全局有序)
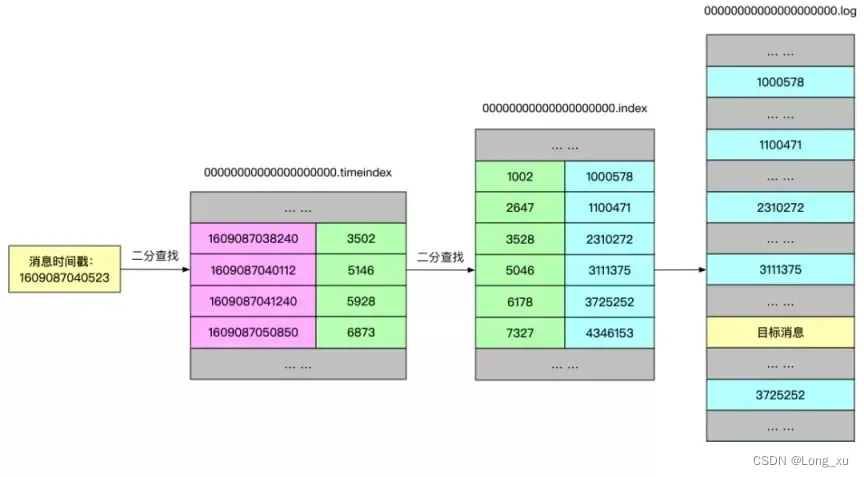
每个 Segment 对应两个文件:“.index” 索引文件(包括timeindex和index)和 “.log” 数据文件。**同时kafka还会在内部维护偏移量的跳表,拿到偏移量后加载index二分查找。 **
zookeeper的作用如下:
- 在每个broker都会有一个topic的partition,kafka在这里会充当选主的作用
- 集群成员身份,kafka会保留brokers的身份列表
- ACL 线性一致的鉴权
- 保存topic信息
如何做kafka水平扩展?
可以扩展partition replica,也可以扩展broker节点,也可扩展partition
kafka怎么删除过期数据的?数据清理的过程是什么样的?
- 根据timeindex判断 kafka默认保留7天内的数据,对于超过7天的数据,会被清理掉,这里的清理逻辑主要根据timeindex时间索引文件里最大的时间来判断的,如果最大时间与当前时间差值超过7天,那么对应的数据段就会被清理掉。
- 根据日志文件大小判断 如果log文件(所有的数据段总和)大于我们设定的阈值,那么就会从第一个数据段开始清理,直至满足条件。对于日志起始偏移量,如果日志段的起始偏移量小于等于我们设定的阈值,那么对应的数据段就会被清理掉。
为什么使用kafaka?和其它的消息队列相比有什么优劣?
解耦、异步、削峰、保证消费
kafka和rocketmq的比较
高吞吐量的时候主要是RocketMQ和Kafka,RocketMQ在topic比较多的时候吞吐量不会受到影响。其它场景下kafaka的吞吐量更大。kafka是一个分区多个分段文件,当topic过多,分区的总量也会增加,kafka中存在过多的文件,当对消息刷盘时,就会出现文件竞争磁盘,出现性能的下降。
实效性在ms以内。kafka采用异步发送的机制,当发送一条消息时,消息并没有发送到broker而是缓存起来,然后直接向业务返回成功,当缓存的消息达到一定数量时再批量发送。此时减少了网络io,从而提高了消息发送的性能,但是如果消息发送者宕机,会导致消息丢失,业务出错,所以理论上kafka利用此机制提高了io性能却降低了可靠性。
ISR是什么?解决了什么问题?
ISR全称是 in-sync replica,它是一个集合列表,里面保存的是和Leader Parition节点数据最接近的Follower Partition
如果某个Follower Partition里面的数据落后Leader太多,就会被剔除ISR列表。
简单来说,ISR列表里面的节点,同步的数据一定是最新的,所以后续的Leader选举,只需要从ISR列表里面筛选就行了。
所以,我认为引入ISR这个方案的原因有两个
- 尽可能的保证数据同步的效率,因为同步效率不高的节点都会被踢出ISR列表。
- 避免数据的丢失,因为ISR里面的节点数据是和Leader副本最接近的。
Kafka的leader是如何选举的?
leader在每个topic都有一个。
在kafka中有这样几个概念:
- AR:所有副本集合
- ISR:所有符合选举条件的副本集合
- OSR:落后太多或者挂掉的副本集合
AR = ISR + OSR,在正常情况下,AR应该是和ISR一样的,但是当某个Follower副本落后太多或者某个Follower副本节点挂掉了,那么它会被移出ISR放入OSR中,kafka的选举也比较简单,就是把ISR中的第一个副本选举成新的Leader节点。
Kafka 会产生消息丢失吗?如何保证可靠性?

producer -> broker ,broker->broker之间同步,以及broker->磁盘保证消息不丢失
**生产者 **保证消费端消息不丢失 必须使用手动提交offset。ACK = 1
**broker 刷盘和同步 **min.insync.replicas设置为至少写到n个ISR
消费者 手动offset
kafka生产数据时候的应答机制?
ACK = 0:生产者发送完数据,不用考虑数据是否已到达kafka服务器,然后紧接着就发下一条数据,这样,效率会非常高。但是存在一个问题:数据的丢失可能性比较大。
ACK = 1:生产者发送数据,是需要等待leader的应答,如果应答完成,才能发送下一条message,是不关心follower是否pull完成,是否接收成功的。这样,虽说性能会慢些,但是数据会比较安全。可但是,在leader保存完数据后,突然leader所在的broker down掉了,此时的follower还没来得及从leader那儿pull数据,那么这个数据就会丢失。
ACK = -1:可以理解为最耗时的选项。当生产者发送数据后,需要等待所有的副本的应答,包括leader+follower,这种方式是最安全的,但同时也是性能最差的。**
如何做消息去重?producer幂等足够了吗?
- 去重包括MySQL 去重、Redis 去重、假如场景量极大且允许误判,布隆过滤器也可以
消息处理过程如下:
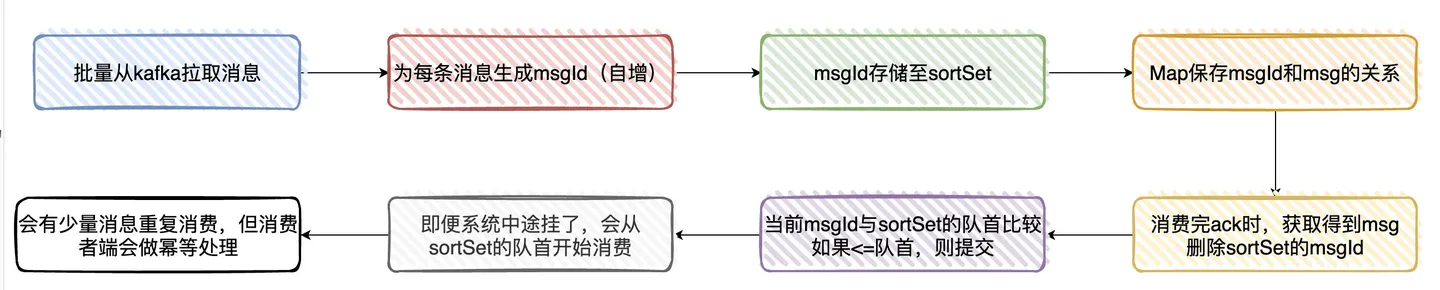
做幂等如下(无论是手动提交还是自动提交必须做幂等):
通过Redis做前置处理,DB唯一索引做最终保证来实现幂等性的。
- kafka自带的producer幂等在producer重启或者跨topic和partition时是保证不了的
kafka是有序的吗?如何保证kafka消息读取的有序性?
kafka在partition中有序,partition之间无序。也就是顺序一致。
有序性可以指定partition投递和消费。
kafka中一个broker故障,会怎么办
- 通过注册zk的监听器实现的监听节点下线功能
- controller计算一个存活broker列表
- 更新broker的元数据,启动broker上的分区和副本;挂掉的broker执行offline操作
Kafka通过哪些机制实现了高吞吐量?
- 生产者异步、压缩、批量发送、批量拉取
- 网络模型I/O多路复用 Epoll
- pageCache(producer写和broker读过程) + sendfile
- 顺序I/O
- baseOffset 跳表
kafka多消费者模型怎么实现的?
多消费者模型通过设计一套offset来实现一个topic被多个消费者消费,
offset被保存在_consumer_offset这个topic中,其中key是group-topic-partition,value是offset
kafka重平衡怎么实现的?
触发条件:1. topic数量变化 2. broker数量变化 3. partition数量变化 4. consumer数量变化
消费者端处理的流程:1. 加入组 2. 等待consumer leader(第一个和coordinator通信的节点)分配
针对partition数过多的场景设计page cache
- 调大文件描述符范围
- 调整pdflush行为
// 当脏页大小达到这个参数设定的值时将触发刷磁盘操作
vm.dirty_background_bytes = 0
// 当脏页占总内存的比例达到这个参数设定的值时将触发刷磁盘操作
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
// 数据存在的时间超过这个值触发刷盘
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
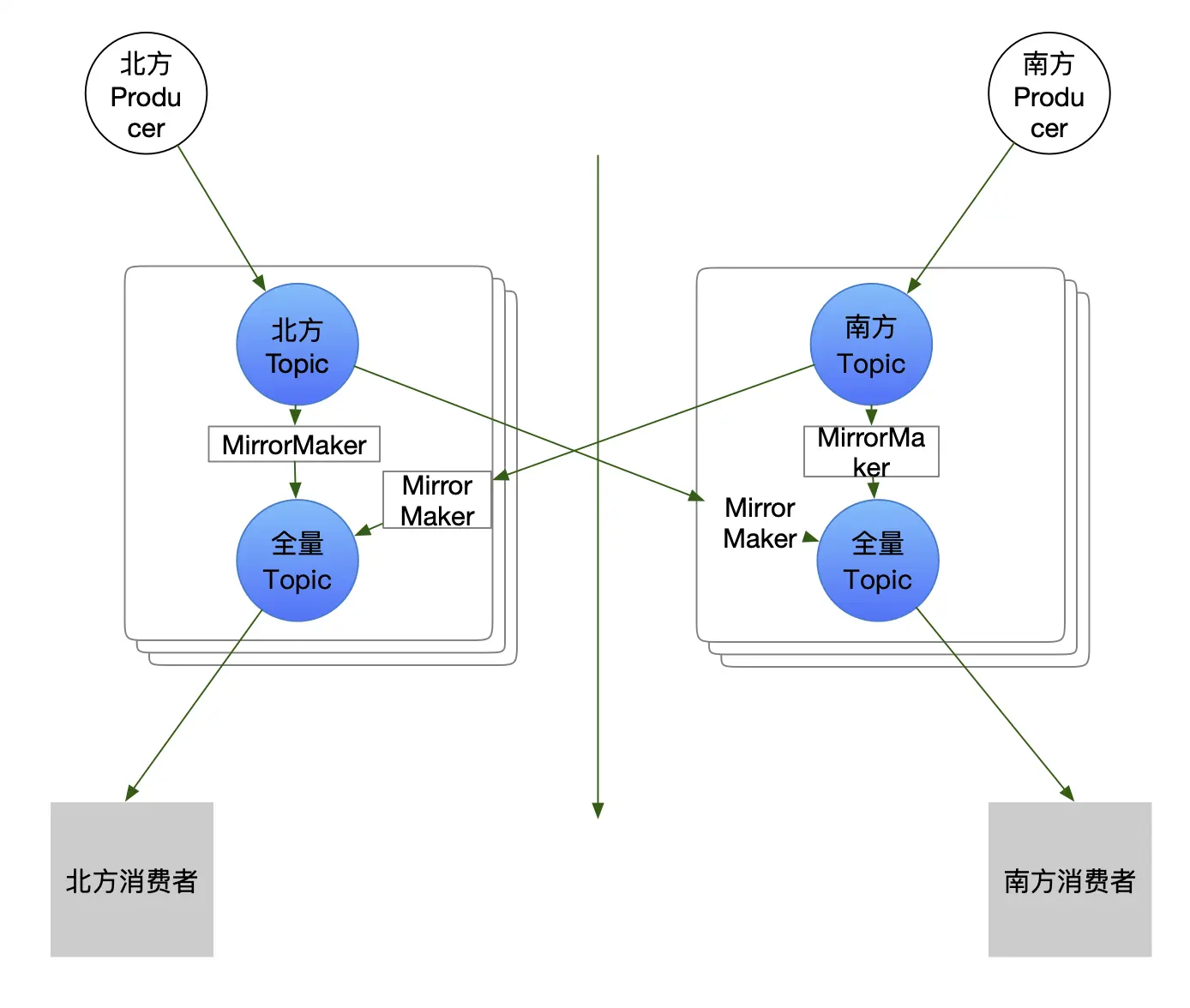
kafka异地多活怎么实现
MirrorMaker
kafka读写调优
- 磁盘 顺序写 ssd和hdd性能差不多,可以用机械硬盘节省成本
- JVM 调大堆内存
- broker 调整线程量
- 调整回收水位看有没有直接内存规整
- 生产者 主要调整发送缓冲区参数
- 消费者 主要是调整一次拉取的数据数量和大小
容错的种类:
At most once:最多交付一次,数据存在丢失的风险;
At least once:最少交付一次,数据存在重复的可能;
Exactly once:交付且仅交付一次,数据不重不漏。
一致性hash
哈希算法的问题在哪里?
哈希算法的基数改变,导致整体的映射关系改变引起节点的大量迁移。
如何解决一致性哈希的均匀性问题?
使用虚拟节点
分布式ID生成
分布式ID生成算法有哪一些
全局的线性一致模型
uuid
基于时间的UUID通过计算当前时间戳、随机数和机器MAC地址得到。由于在算法中使用了MAC地址,这个版本的UUID可以保证在全球范围的唯一性。
优点:
性能非常高:本地生成,没有网络消耗。
缺点:
1)不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用;
2)信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
snowflake

► 优点:
- 1)毫秒数在高位,自增序列在低位,整个ID都是趋势递增的;
- 2)不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的;
- 3)可以根据自身业务特性分配bit位,非常灵活。
► 缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
数据库自增id
leaf-segment方案
主库和从库半同步,双buffer优化
缺点是会暴露信息

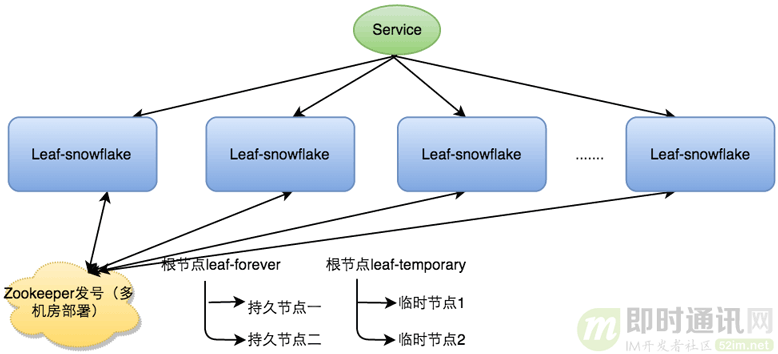
leaf-snowflake
- 弱依赖zk,本机文件系统上缓存一个workerID文件
- 通过zk存储机器时间解决时间回拨问题
限流
我现在要做一个限流功能, 怎么做?
QPS和令牌桶算法
QPS 限流算法
QPS 限流算法通过限制单位时间内允许通过的请求数来限流。
优点:
- 计算简单,是否限流只跟请求数相关,放过的请求数是可预知的(令牌桶算法放过的请求数还依赖于流量是否均匀),比较符合用户直觉和预期。
- 可以通过拉长限流周期来应对突发流量。如 1 秒限流 10 个,想要放过瞬间 20 个请求,可以把限流配置改成 3 秒限流 30 个。拉长限流周期会有一定风险,用户可以自主决定承担多少风险。
缺点:
- 没有很好的处理单位时间的边界。比如在前一秒的最后一毫秒和下一秒的第一毫秒都触发了最大的请求数,就看到在两毫秒内发生了两倍的 QPS。
- 放过的请求不均匀。突发流量时,请求总在限流周期的前一部分放过。如 10 秒限 100 个,高流量时放过的请求总是在限流周期的第一秒。
令牌桶算法
令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
优点:
- 放过的流量比较均匀,有利于保护系统。
- 存量令牌能应对突发流量,很多时候,我们希望能放过脉冲流量。而对于持续的高流量,后面又能均匀地放过不超过限流值的请求数。
缺点:
- 存量令牌没有过期时间,突发流量时第一个周期会多放过一些请求,可解释性差。即在突发流量的第一个周期,默认最多会放过 2 倍限流值的请求数。
- 实际限流数难以预知,跟请求数和流量分布有关。
存量桶系数
多余的令牌数量怎么设置?
令牌桶算法中,多余的令牌会放到桶里。这个桶的容量是有上限的,决定这个容量的就是存量桶系数,默认为 1.0,即默认存量桶的容量是 1.0 倍的限流值。推荐设置 0.6~1.5 之间。
存量桶系数的影响有两方面:
- 突发流量第一个周期放过的请求数。如存量桶系数等于 0.6,第一个周期最多放过 1.6 倍限流值的请求数。
- 影响误杀率。存量桶系数越大,越能容忍流量不均衡问题。误杀率:服务限流是对单机进行限流,线上场景经常会用单机限流模拟集群限流。由于机器之间的秒级流量不够均衡,所以很容易出现误限。例如两台服务器,总限流值 20,每台限流 10,某一秒两台服务器的流量分别是 5、15,这时其中一台就限流了 5 个请求。减小误杀率的两个办法:
- 拉长限流周期。
- 使用令牌桶算法,并且调出较好的存量桶系数
固定窗口的限流算法的问题?
两个相邻的0.5s无法控制限流。
CAS
你说的操作和事务视角的一致性-可用性模型是什么?可以介绍一下吗?
high available Transactions
它将可用性分为总可用、粘性可用、和没有完全可用性保障三种情况,
总可用在操作视角上包括:单调写、单调读、写跟随读;在事务视角上包括读已提交、读未提交
粘性可用在操作视角上包括写后读、因果一致
没用完全可用性保障在操作视角上包括:顺序一致、线性一致;在事务视角上包括可重复读、快照隔离、串形化
说一下为什么在总可用系统里面能够做到读已提交、读未提交、单调写、单调读和写跟随读
RC可以通过服务器仅仅给客户暴露已经提交的数据来实现。
负载均衡
- 轮询(Round Robin):轮询策略按照顺序将每个新的请求分发给后端服务器,依次循环。这是一种最简单的负载均衡策略,适用于后端服务器的性能相近,且每个请求的处理时间大致相同的情况。
- 随机选择(Random):随机选择策略随机选择一个后端服务器来处理每个新的请求。这种策略适用于后端服务器性能相似,且每个请求的处理时间相近的情况,但不保证请求的分发是均匀的。
- 最少连接(Least Connections):最少连接策略将请求分发给当前连接数最少的后端服务器。这可以确保负载均衡在后端服务器的连接负载上均衡,但需要维护连接计数。
- IP 哈希(IP Hash):IP 哈希策略使用客户端的 IP 地址来计算哈希值,然后将请求发送到与哈希值对应的后端服务器。这种策略可用于确保来自同一客户端的请求都被发送到同一台后端服务器,适用于需要会话保持的情况。
- 加权轮询(Weighted Round Robin):加权轮询策略给每个后端服务器分配一个权重值,然后按照权重值比例来分发请求。这可以用来处理后端服务器性能不均衡的情况,将更多的请求分发给性能更高的服务器。
- 加权随机选择(Weighted Random):加权随机选择策略与加权轮询类似,但是按照权重值来随机选择后端服务器。这也可以用来处理后端服务器性能不均衡的情况,但是分发更随机。
- 最短响应时间(Least Response Time):最短响应时间策略会测量每个后端服务器的响应时间,并将请求发送到响应时间最短的服务器。这种策略可以确保客户端获得最快的响应,适用于要求低延迟的应用。