大语言模型(LLM)文本预处理实战
文章目录
- 大语言模型(LLM)文本预处理实战
- 2.1 理解词嵌入
- 2.2 文本分词
- 2.3 将 token 转换为 token ID
- 2.4 添加特殊上下文 token
- 2.5 字节对编码 (BytePair Encoding, BPE)
- 2.6 使用滑动窗口进行数据采样
- 2.7 创建 token 嵌入 (Token Embeddings)
- 2.8 编码词汇的位置信息 (Encoding Word Positions)
本文中使用的软件包:
from importlib.metadata import versionprint("torch version:", version("torch"))
print("tiktoken version:", version("tiktoken"))
torch version: 2.4.0
tiktoken version: 0.7.0
- 本章涵盖数据准备和采样,以便为 LLM 输入数据做好准备

2.1 理解词嵌入
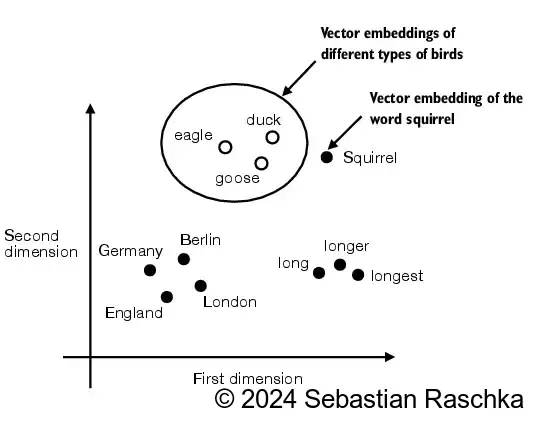
- 嵌入有多种形式,本文重点介绍文本嵌入:

- LLMs(大型语言模型)在高维空间中处理嵌入(即,数千个维度)
- 由于我们无法可视化如此高的维度空间(人类通常在1、2或3个维度上思考),下图展示了一个二维的嵌入空间。
2.2 文本分词
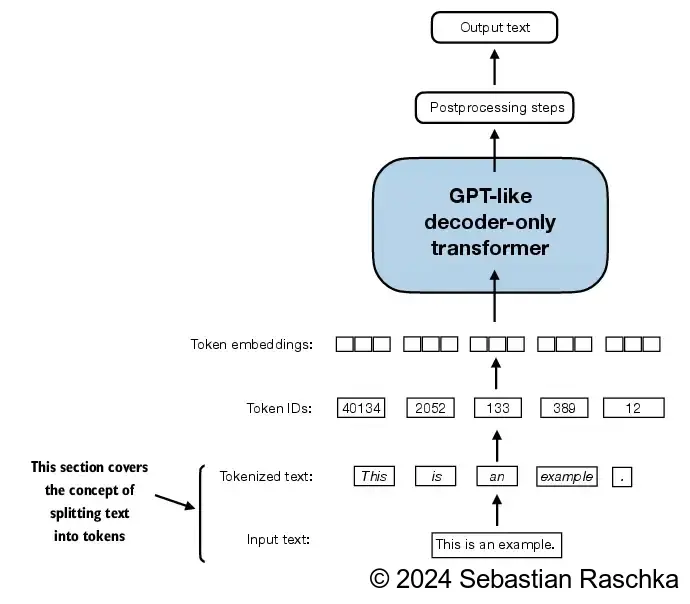
- 在这一节中,我们将对文本进行分词,这意味着将文本分解为更小的单位,如单个单词和标点符号。
- 加载我们想要处理的原始文本。
- The Verdict by Edith Wharton 是一篇公有领域的短篇小说。
import os
import urllib.request# 如果文件 "the-verdict.txt" 不存在,
if not os.path.exists("the-verdict.txt"):# 定义文件的 URL 地址url = ("https://raw.githubusercontent.com/rasbt/""LLMs-from-scratch/main/ch02/01_main-chapter-code/""the-verdict.txt")# 指定保存的本地文件路径file_path = "the-verdict.txt"# 使用 urllib 下载文件并保存到指定路径urllib.request.urlretrieve(url, file_path)
# 打开文件 "the-verdict.txt" 并读取其内容
with open("the-verdict.txt", "r", encoding="utf-8") as f:raw_text = f.read() # 读取文件中的所有文本# 输出文本的总字符数
print("Total number of characters:", len(raw_text))
# 输出文本的前99个字符
print(raw_text[:99])
Total number of character: 20479
I HAD always thought Jack Gisburn rather a cheap genius–though a good fellow enough–so it was no
- 目标是对这段文本进行分词和嵌入,以供大型语言模型使用。
- 我们先基于一些简单的示例文本开发一个简单的分词器,然后可以将其应用于上面的文本。
- 以下的正则表达式将会按空白符进行拆分。
import re # 导入正则表达式模块text = "Hello, world. This, is a test." # 定义待分词的文本
result = re.split(r'(\s)', text) # 使用正则表达式按空白符进行拆分,括号内的空白符会被保留print(result) # 输出分词结果
[‘Hello,’, ’ ', ‘world.’, ’ ', ‘This,’, ’ ', ‘is’, ’ ', ‘a’, ’ ', ‘test.’]
- 我们不仅希望按空白符进行拆分,还想按逗号和句点进行拆分,因此让我们修改正则表达式来实现这一点。
# 使用正则表达式按逗号、句点或空白符进行拆分
result = re.split(r'([,.]|\s)', text)# 输出分词结果
print(result)
[‘Hello’, ‘,’, ‘’, ’ ', ‘world’, ‘.’, ‘’, ’ ', ‘This’, ‘,’, ‘’, ’ ', ‘is’, ’ ', ‘a’, ’ ', ‘test’, ‘.’, ‘’]
- 如我们所见,这样会创建空字符串,让我们把它们去掉。
# 从每个项中移除空白符,并过滤掉任何空字符串
result = [item for item in result if item.strip()]# 输出处理后的分词结果
print(result)
[‘Hello’, ‘,’, ‘world’, ‘.’, ‘This’, ‘,’, ‘is’, ‘a’, ‘test’, ‘.’]
- 这看起来已经很不错了,但让我们也处理其他类型的标点符号,比如句点、问号等。
# 定义一段包含多种标点符号的文本
text = "Hello, world. Is this-- a test?"# 使用正则表达式按逗号、句点、冒号、分号、问号、下划线、感叹号、圆括号、引号、破折号以及空白符进行拆分
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)# 从每个项中移除空白符,并过滤掉任何空字符串
result = [item.strip() for item in result if item.strip()]# 输出处理后的分词结果
print(result)
[‘Hello’, ‘,’, ‘world’, ‘.’, ‘Is’, ‘this’, ‘–’, ‘a’, ‘test’, ‘?’]
- 这样就很好了,现在我们可以将这个分词方法应用到原始文本上了。
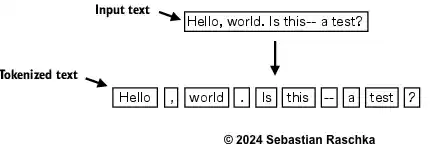
# 使用正则表达式按逗号、句点、冒号、分号、问号、下划线、感叹号、圆括号、引号、破折号以及空白符对原始文本进行分词
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)# 从每个项中移除空白符,并过滤掉任何空字符串
preprocessed = [item.strip() for item in preprocessed if item.strip()]# 输出处理后的前30个分词结果
print(preprocessed[:30])
[‘I’, ‘HAD’, ‘always’, ‘thought’, ‘Jack’, ‘Gisburn’, ‘rather’, ‘a’, ‘cheap’, ‘genius’, ‘–’, ‘though’, ‘a’, ‘good’, ‘fellow’, ‘enough’, ‘–’, ‘so’, ‘it’, ‘was’, ‘no’, ‘great’, ‘surprise’, ‘to’, ‘me’, ‘to’, ‘hear’, ‘that’, ‘,’, ‘in’]
- 让我们计算总共有多少个tokens。
print(len(preprocessed))
4690
2.3 将 token 转换为 token ID
- 接下来,我们将文本 token 转换为 token ID,以便后续可以通过嵌入层进行处理。
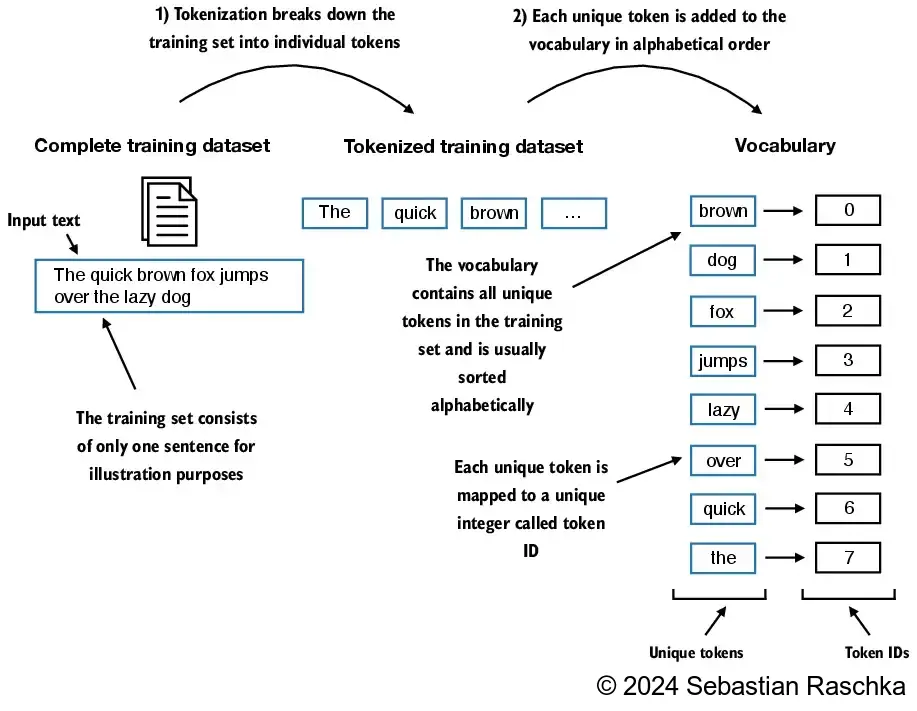
- 从这些 token 中,我们现在可以构建一个词汇表,该词汇表包含所有唯一的 token。
# 创建一个去重并排序后的词汇表
all_words = sorted(set(preprocessed))# 计算词汇表的大小
vocab_size = len(all_words)# 输出词汇表的大小
print(vocab_size)
1130
# 创建一个字典,将每个唯一的令牌映射到一个整数ID
vocab = {token: integer for integer, token in enumerate(all_words)}
- 以下是词汇表中的前50个条目:
# 遍历词汇表中的项,并打印前50个条目
for i, item in enumerate(vocab.items()):print(item)# 如果已经打印了50个条目,则停止循环if i >= 49: # 因为索引是从0开始的,所以这里应该是49break
(‘!’, 0)
(‘"’, 1)
(“'”, 2)
(‘(’, 3)
(‘)’, 4)
(‘,’, 5)
(‘–’, 6)
(‘.’, 7)
(‘:’, 8)
(‘;’, 9)
(‘?’, 10)
(‘A’, 11)
(‘Ah’, 12)
(‘Among’, 13)
(‘And’, 14)
(‘Are’, 15)
(‘Arrt’, 16)
(‘As’, 17)
(‘At’, 18)
(‘Be’, 19)
(‘Begin’, 20)
(‘Burlington’, 21)
(‘But’, 22)
(‘By’, 23)
(‘Carlo’, 24)
(‘Chicago’, 25)
(‘Claude’, 26)
(‘Come’, 27)
(‘Croft’, 28)
(‘Destroyed’, 29)
(‘Devonshire’, 30)
(‘Don’, 31)
(‘Dubarry’, 32)
(‘Emperors’, 33)
(‘Florence’, 34)
(‘For’, 35)
(‘Gallery’, 36)
(‘Gideon’, 37)
(‘Gisburn’, 38)
(‘Gisburns’, 39)
(‘Grafton’, 40)
(‘Greek’, 41)
(‘Grindle’, 42)
(‘Grindles’, 43)
(‘HAD’, 44)
(‘Had’, 45)
(‘Hang’, 46)
(‘Has’, 47)
(‘He’, 48)
(‘Her’, 49)
(‘Hermia’, 50)
- 下面,我们用一个小词汇表来说明对一段简短样本文本的分词过程:
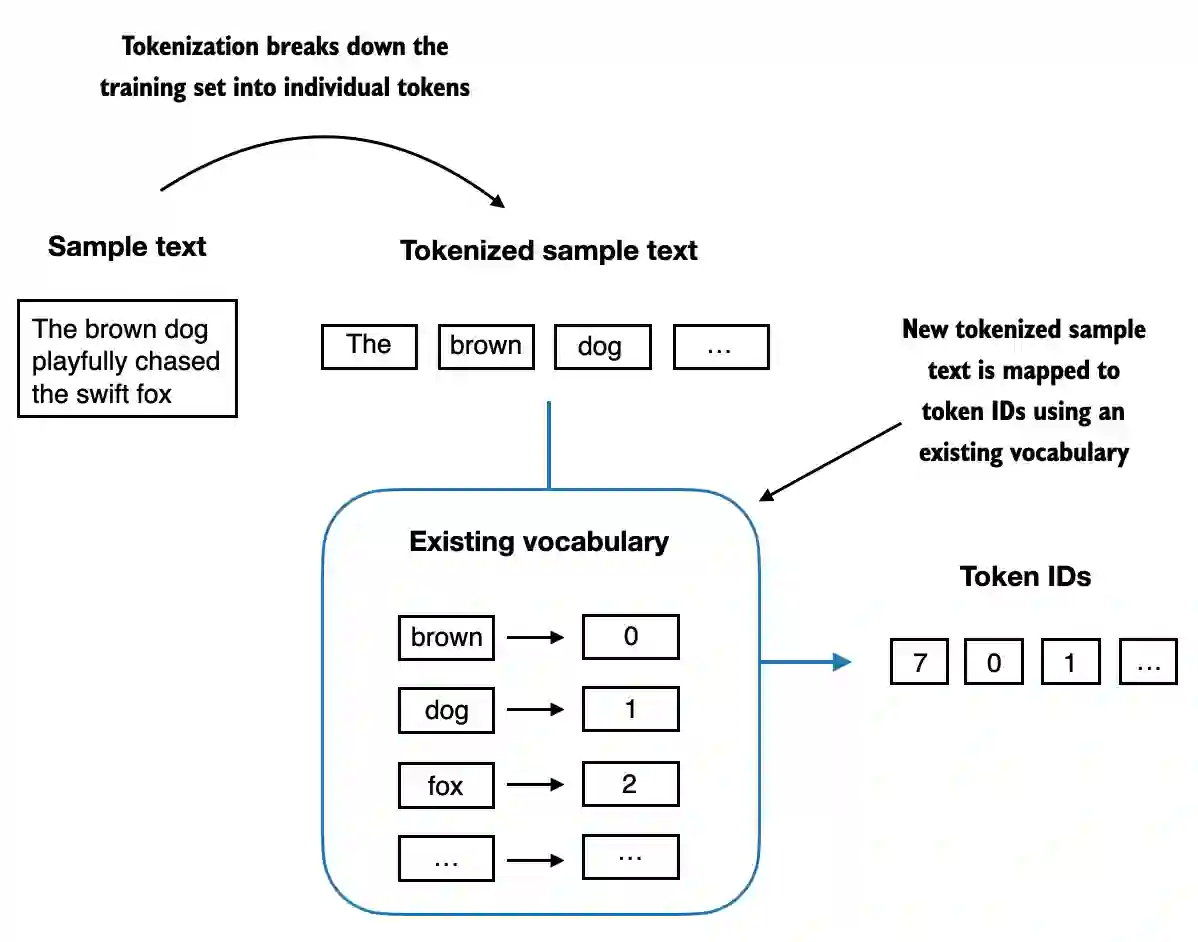
- 现在,我们将所有内容整合到一个分词器类中。
class SimpleTokenizerV1:def __init__(self, vocab):# 构造函数初始化分词器的词汇表self.str_to_int = vocab # 字符串到整数的映射self.int_to_str = {i: s for s, i in vocab.items()} # 整数到字符串的映射def encode(self, text):# 对输入文本进行预处理和分词preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)# 从每个项中移除空白符,并过滤掉任何空字符串preprocessed = [item.strip() for item in preprocessed if item.strip()]# 将每个分词映射到相应的整数IDids = [self.str_to_int[s] for s in preprocessed]return idsdef decode(self, ids):# 将整数ID列表转换回文本text = " ".join([self.int_to_str[i] for i in ids])# 替换特定标点符号前的多余空格text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)return text
encode函数将文本转换为 token ID。decode函数将 token ID转换回文本。
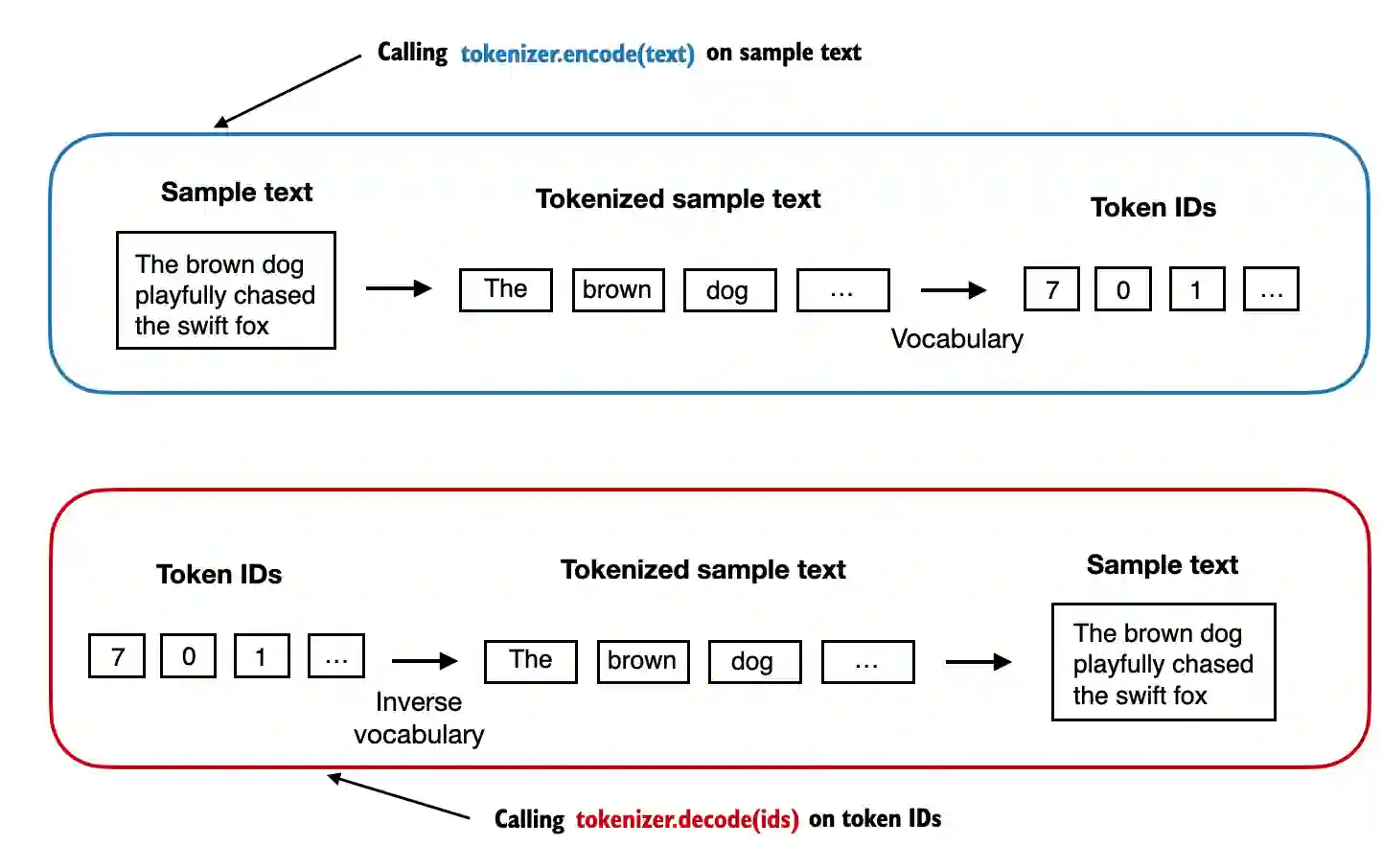
- 我们可以使用分词器将文本编码(即,进行分词)成整数。
- 这些整数随后可以被嵌入(稍后)作为大型语言模型的输入。
# 实例化分词器对象
tokenizer = SimpleTokenizerV1(vocab)# 定义一段文本
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""# 使用分词器将文本编码为整数ID列表
ids = tokenizer.encode(text)# 输出整数ID列表
print(ids)
[1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]
- 我们可以将这些整数再解码回文本。
tokenizer.decode(ids)
‘" It’ s the last he painted, you know," Mrs. Gisburn said with pardonable pride.’
tokenizer.decode(tokenizer.encode(text))
‘" It’ s the last he painted, you know," Mrs. Gisburn said with pardonable pride.’
2.4 添加特殊上下文 token
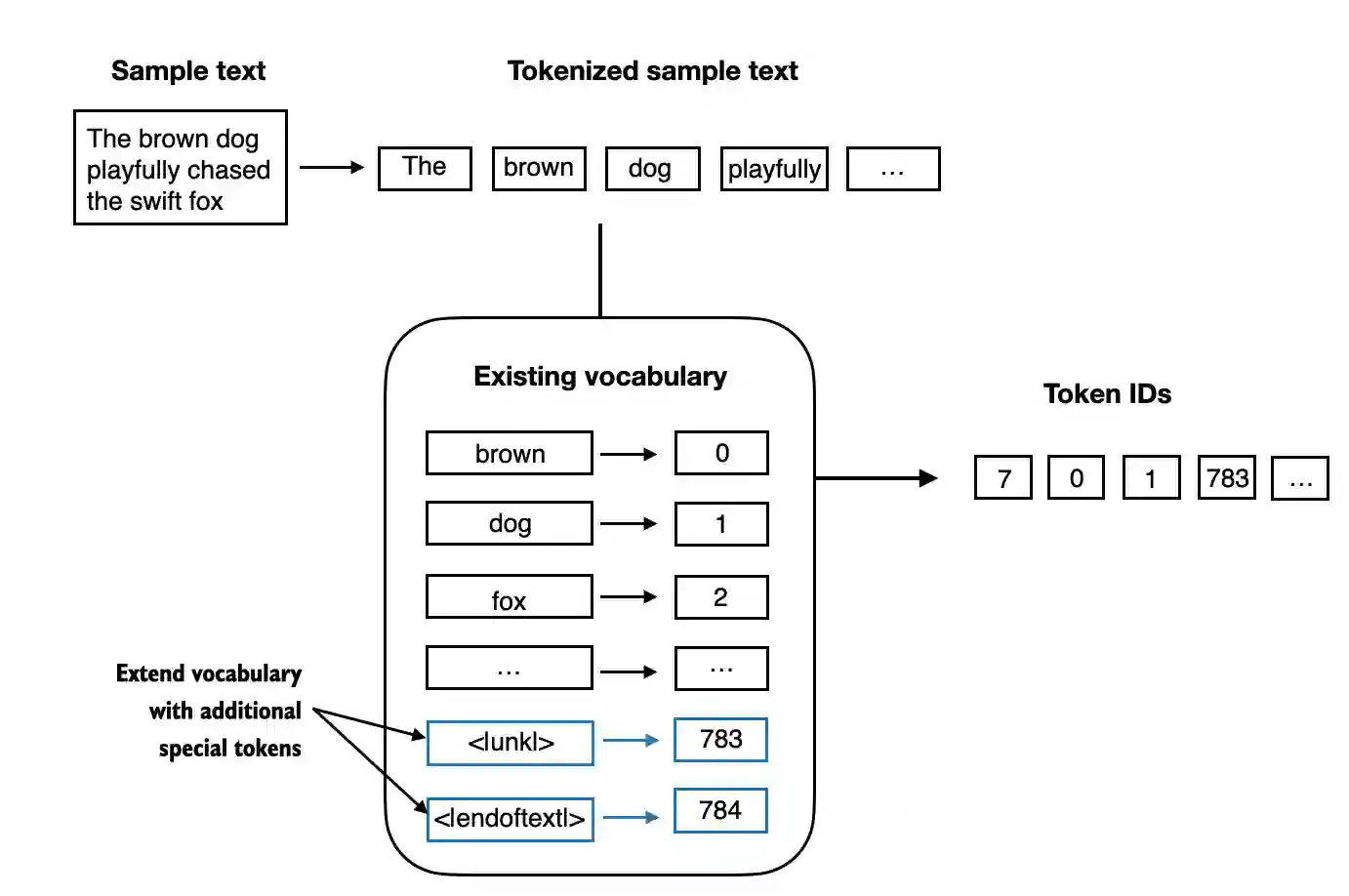
- 添加一些“特殊” token 对于未知词汇以及标记文本的结束是非常有用的。
-
一些分词器使用特殊 token 来为大型语言模型提供额外的上下文信息。
-
其中一些特殊 token 包括:
[BOS](序列开始)标记文本的起始位置。[EOS](序列结束)标记文本的结束位置(这通常用于连接多个不相关的文本,例如两篇不同的维基百科文章或两本不同的书等)。[PAD](填充)如果我们用大于1的批次大小训练大型语言模型(我们可能会包含长度不同的多个文本;通过填充 token,我们将较短的文本填充到最长文本的长度,从而使所有文本具有相同的长度)。
-
[UNK]代表不在词汇表中的词汇。 -
注意,GPT-2并不需要上述提及的任何特殊 token,而是仅使用
<|endoftext|>token 来简化复杂度。 -
<|endoftext|>类似于上述提到的[EOS]token。 -
GPT 同样使用
<|endoftext|>进行填充(因为在批量输入训练时通常使用掩码,我们无论如何都不会关注填充的 token,所以这些 token 具体是什么并不重要)。 -
GPT-2 不使用
<UNK>token 来表示词汇表外的词汇;相反,GPT-2 使用字节对编码(BPE)分词器,它将词汇分解为子词单元,我们将在后面的章节中讨论这一点。 -
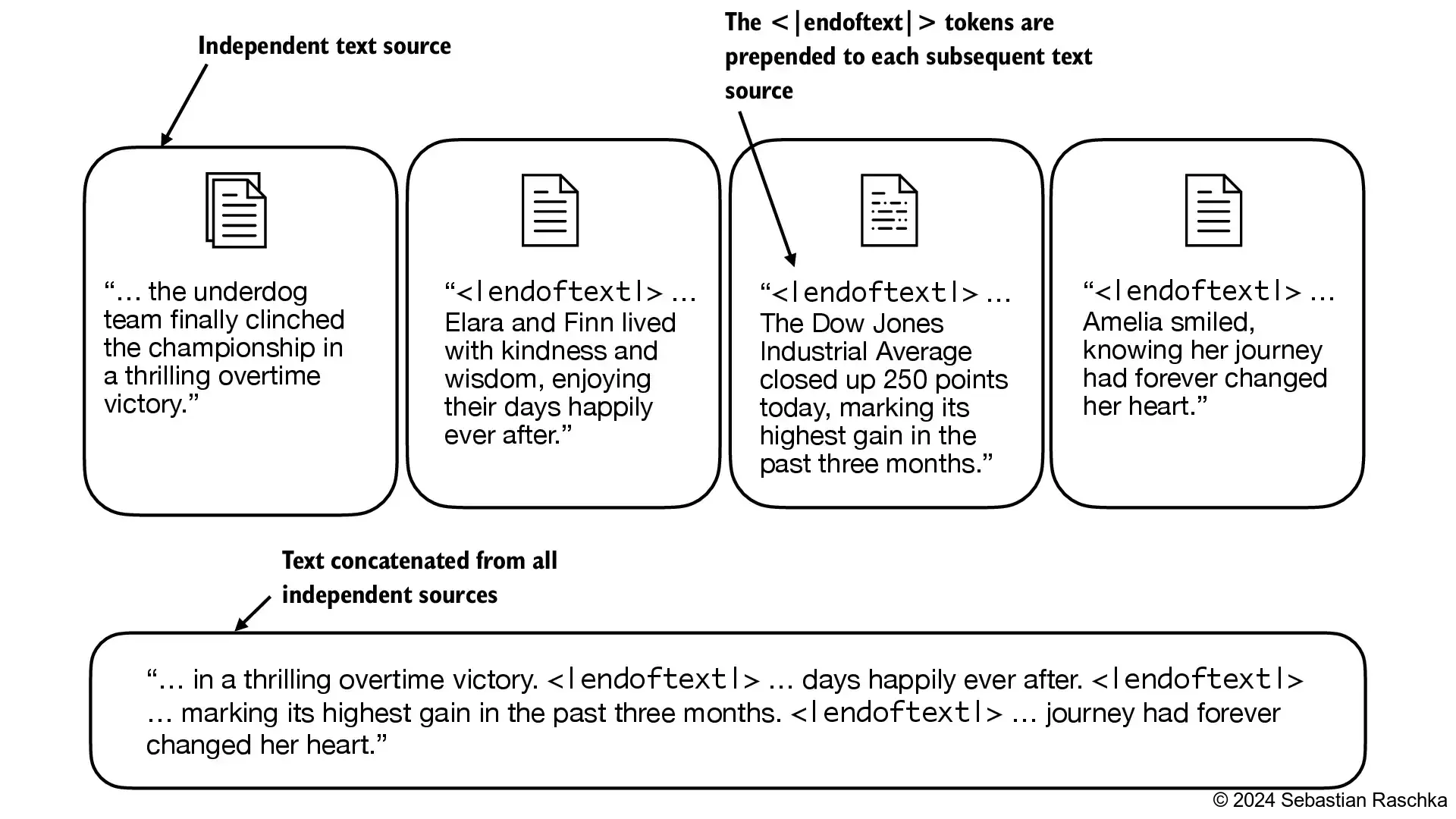
我们在两个独立的文本来源之间使用
<|endoftext|>令牌:
- 让我们看看对以下文本进行分词会发生什么:
tokenizer = SimpleTokenizerV1(vocab)text = "Hello, do you like tea. Is this-- a test?"tokenizer.encode(text)
Traceback (most recent call last):
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\interactiveshell.py”, line 3577, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File “C:\Users\Tang\AppData\Local\Temp\ipykernel_27700\2162118319.py”, line 5, in
tokenizer.encode(text)
File “C:\Users\Tang\AppData\Local\Temp\ipykernel_27700\2118097954.py”, line 12, in encode
ids = [self.str_to_int[s] for s in preprocessed]
File “C:\Users\Tang\AppData\Local\Temp\ipykernel_27700\2118097954.py”, line 12, in
ids = [self.str_to_int[s] for s in preprocessed]
KeyError: ‘Hello’During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\interactiveshell.py”, line 2168, in showtraceback
stb = self.InteractiveTB.structured_traceback(
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\ultratb.py”, line 1454, in structured_traceback
return FormattedTB.structured_traceback(
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\ultratb.py”, line 1345, in structured_traceback
return VerboseTB.structured_traceback(
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\ultratb.py”, line 1192, in structured_traceback
formatted_exception = self.format_exception_as_a_whole(etype, evalue, etb, number_of_lines_of_context,
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\ultratb.py”, line 1107, in format_exception_as_a_whole
frames.append(self.format_record(record))
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\ultratb.py”, line 989, in format_record
frame_info.lines, Colors, self.has_colors, lvals
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\IPython\core\ultratb.py”, line 801, in lines
return self._sd.lines
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\utils.py”, line 145, in cached_property_wrapper
value = obj.dict[self.func.name] = self.func(obj)
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\core.py”, line 734, in lines
pieces = self.included_pieces
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\utils.py”, line 145, in cached_property_wrapper
value = obj.dict[self.func.name] = self.func(obj)
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\core.py”, line 677, in included_pieces
scope_pieces = self.scope_pieces
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\utils.py”, line 145, in cached_property_wrapper
value = obj.dict[self.func.name] = self.func(obj)
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\core.py”, line 614, in scope_pieces
scope_start, scope_end = self.source.line_range(self.scope)
File “c:\Users\Tang.conda\envs\llm\lib\site-packages\stack_data\core.py”, line 178, in line_range
return line_range(self.asttext(), node)
AttributeError: ‘Source’ object has no attribute ‘asttext’
- 上述情况产生了错误,因为词汇表中不包含单词 “Hello”。
- 为了处理这种情况,我们可以在词汇表中添加特殊的 token,如
"<|unk|>",来代表未知词汇。 - 既然我们已经在扩展词汇表,让我们再添加一个叫做
"<|endoftext|>"的 token,这个令牌在 GPT-2 的训练中用于标记文本的结束(同时它也被用于连接的文本之间,比如我们的训练数据集由多篇文章、书籍等组成时)。
# 创建一个去重并排序后的所有唯一 token 列表
all_tokens = sorted(list(set(preprocessed)))# 扩展词汇表,添加特殊 token <|endoftext|>
all_tokens.extend(["<|endoftext|>", "<|unk|>"])# 创建一个字典,将每个唯一的 token 映射到一个整数ID
vocab = {token: integer for integer, token in enumerate(all_tokens)}
print(len(vocab.items()))
1132
for i, item in enumerate(list(vocab.items())[-5:]):print(item)
(‘younger’, 1127)
(‘your’, 1128)
(‘yourself’, 1129)
(‘<|endoftext|>’, 1130)
(‘<|unk|>’, 1131)
- 我们还需要相应地调整分词器,以便它知道何时以及如何使用新的
<unk>token。
class SimpleTokenizerV2:def __init__(self, vocab):# 初始化分词器,包括词汇表的字符串到整数的映射和整数到字符串的映射self.str_to_int = vocabself.int_to_str = {i: s for s, i in vocab.items()}def encode(self, text):# 对文本进行预处理,包括分词preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)# 移除空白符,并过滤掉任何空字符串preprocessed = [item.strip() for item in preprocessed if item.strip()]# 将不在词汇表中的 token 替换为 `<|unk|>` tokenpreprocessed = [item if item in self.str_to_int else "<|unk|>" for item in preprocessed]# 将每个分词映射到相应的整数IDids = [self.str_to_int[s] for s in preprocessed]return idsdef decode(self, ids):# 将整数ID列表转换回文本text = " ".join([self.int_to_str[i] for i in ids])# 替换特定标点符号前的多余空格text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)return text
- 让我们尝试使用修改后的分词器来对文本进行分词:
# 实例化分词器对象
tokenizer = SimpleTokenizerV2(vocab)# 定义两段文本
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."# 使用特殊 token " <|endoftext|> " 连接两段文本
text = " <|endoftext|> ".join((text1, text2))# 输出连接后的文本
print(text)
Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.
tokenizer.encode(text)
[1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]
tokenizer.decode(tokenizer.encode(text))
‘<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.’
2.5 字节对编码 (BytePair Encoding, BPE)
- GPT-2 使用了字节对编码 (BytePair Encoding, BPE) 作为其分词器。
- 这种方法允许模型将不在预定义词汇表中的词汇分解为更小的子词单位甚至是单个字符,从而能够处理词汇表外的词汇。
- 例如,如果 GPT-2 的词汇表中没有单词 “unfamiliarword”,它可能会将其分词为 [“unfam”, “iliar”, “word”] 或其他一些子词分解,这取决于其训练得到的 BPE 合并规则。
- 原始的 BPE 分词器可以在以下地址找到:https://github.com/openai/gpt-2/blob/master/src/encoder.py
- 在这本文中,我们使用了来自 OpenAI 开源库 tiktoken 的 BPE 分词器,该库使用 Rust 实现了其核心算法以提高计算性能。
- 我比较了这两种实现,结果显示 tiktoken 在样本文本上的运行速度大约快 5 倍。
待更新,最近一个星期内更完。。。
2.6 使用滑动窗口进行数据采样
待更新,最近一个星期内更完。。。
2.7 创建 token 嵌入 (Token Embeddings)
待更新,最近一个星期内更完。。。
2.8 编码词汇的位置信息 (Encoding Word Positions)
待更新,最近一个星期内更完。。。