ChatGLM-6B
文章目录
- ChatGLM-6B
- 前言
- 一、原理
- 1.1 优势
- 1.2 实验
- 1.3 特点:
- 1.4 相关知识点
- 二、实验
- 2.1 环境基础
- 2.2 构建环境
- 2.3 安装依赖
- 2.4 运行
- 2.5 数据
- 2.6 构建前端页面
- 3 总结
前言
Github:https://github.com/THUDM/ChatGLM-6B
参考链接:
https://chatglm.cn/blog
一、原理
1.1 优势
开源
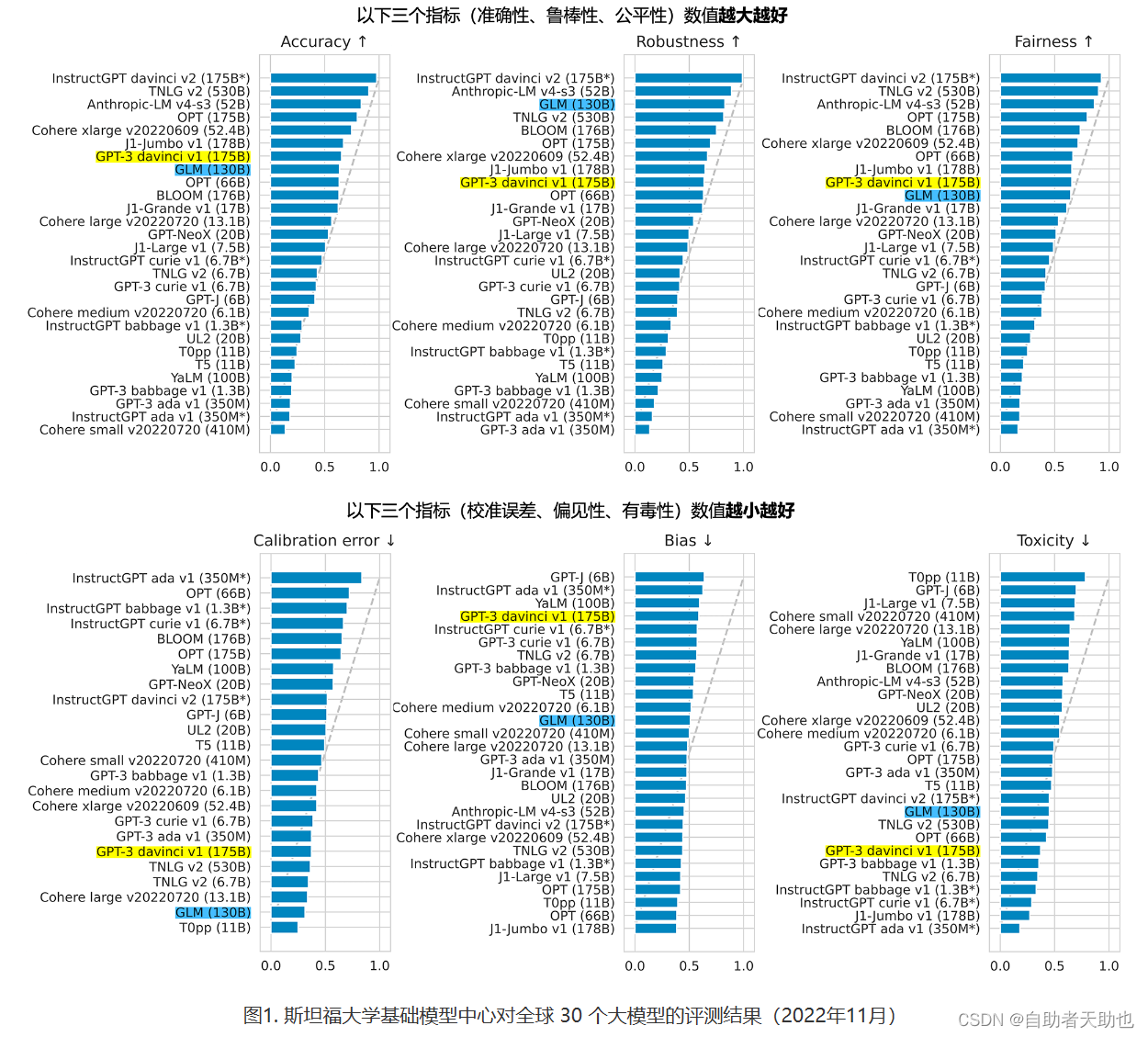
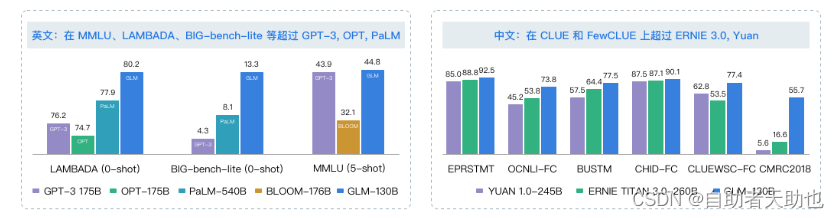
1.2 实验
1.3 特点:
优点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
缺点:
- 模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
- 可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
- 较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
- 英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
- 易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
1.4 相关知识点
P-tuning的原理, 论文的原理比较简单,
def enable_input_require_grads(self):"""Enables the gradients for the input embeddings. This is useful for fine-tuning adapter weights while keepingthe model weights fixed."""def make_inputs_require_grads(module, input, output):output.requires_grad_(True)self._require_grads_hook = self.get_input_embeddings().register_forward_hook(make_inputs_require_grads)
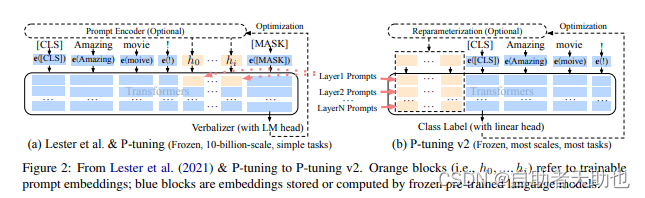
蓝色部分都是冻结的,橙色部分是可训练的参数。
核心代码展示:
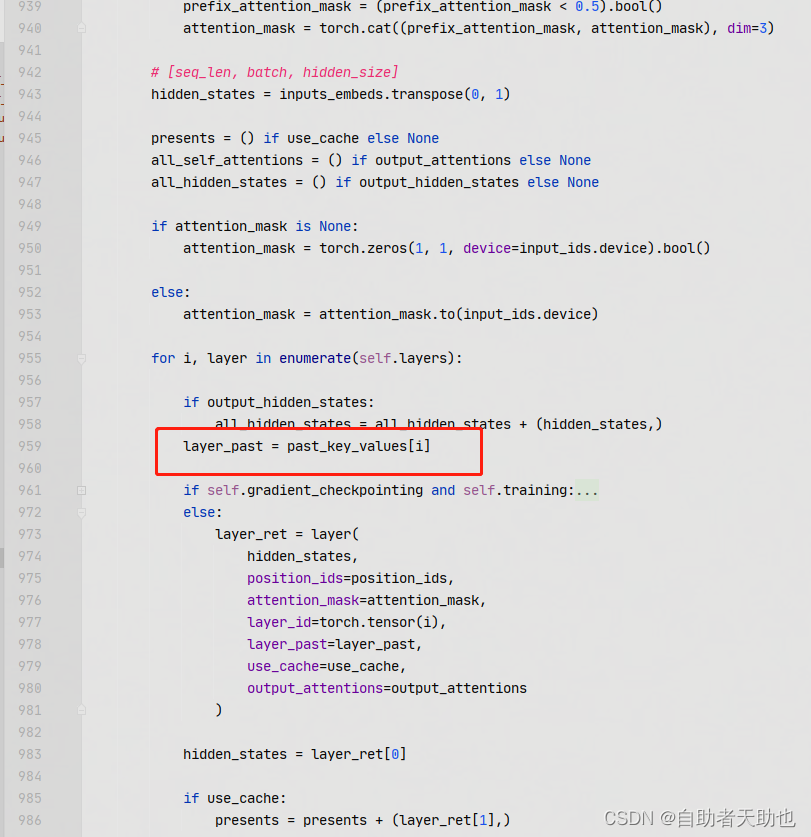
layer_past 是 paper中的layer prompt[i], 具体来说就是参与到content_vector的计算中了
其核心attention的计算如下:
def attention_fn(self,query_layer,key_layer,value_layer,attention_mask,hidden_size_per_partition,layer_id,layer_past=None, 就是layer prompt[i]scaling_attention_score=True,use_cache=False,
):if layer_past is not None:past_key, past_value = layer_past[0], layer_past[1]key_layer = torch.cat((past_key, key_layer), dim=0)value_layer = torch.cat((past_value, value_layer), dim=0)# seqlen, batch, num_attention_heads, hidden_size_per_attention_headseq_len, b, nh, hidden_size = key_layer.shapeif use_cache:present = (key_layer, value_layer)else:present = Nonequery_key_layer_scaling_coeff = float(layer_id + 1)if scaling_attention_score:query_layer = query_layer / (math.sqrt(hidden_size) * query_key_layer_scaling_coeff)# ===================================# Raw attention scores. [b, np, s, s]# ===================================# [b, np, sq, sk]output_size = (query_layer.size(1), query_layer.size(2), query_layer.size(0), key_layer.size(0))# [sq, b, np, hn] -> [sq, b * np, hn]query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)# [sk, b, np, hn] -> [sk, b * np, hn]key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)matmul_result = torch.empty(output_size[0] * output_size[1],output_size[2],output_size[3],dtype=query_layer.dtype,device=query_layer.device,)matmul_result = torch.baddbmm(matmul_result,query_layer.transpose(0, 1), # [b * np, sq, hn]key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]beta=0.0,alpha=1.0,)# change view to [b, np, sq, sk]attention_scores = matmul_result.view(*output_size)if self.scale_mask_softmax:self.scale_mask_softmax.scale = query_key_layer_scaling_coeffattention_probs = self.scale_mask_softmax(attention_scores, attention_mask.contiguous())else:if not (attention_mask == 0).all():# if auto-regressive, skipattention_scores.masked_fill_(attention_mask, -10000.0)dtype = attention_scores.dtypeattention_scores = attention_scores.float()attention_scores = attention_scores * query_key_layer_scaling_coeffattention_probs = F.softmax(attention_scores, dim=-1)attention_probs = attention_probs.type(dtype)# =========================# Context layer. [sq, b, hp]# =========================# value_layer -> context layer.# [sk, b, np, hn] --> [b, np, sq, hn]# context layer shape: [b, np, sq, hn]output_size = (value_layer.size(1), value_layer.size(2), query_layer.size(0), value_layer.size(3))# change view [sk, b * np, hn]value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)# change view [b * np, sq, sk]attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)# matmul: [b * np, sq, hn]context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))# change view [b, np, sq, hn]context_layer = context_layer.view(*output_size)# [b, np, sq, hn] --> [sq, b, np, hn]context_layer = context_layer.permute(2, 0, 1, 3).contiguous()# [sq, b, np, hn] --> [sq, b, hp]new_context_layer_shape = context_layer.size()[:-2] + (hidden_size_per_partition,)context_layer = context_layer.view(*new_context_layer_shape)outputs = (context_layer, present, attention_probs)return outputs
二、实验
2.1 环境基础

2.2 构建环境
conda create -n py310_chat python=3.10 # 创建新环境
source activate py310_chat # 激活环境git clone https://github.com/THUDM/ChatGLM-6B.git
cd ChatGLM-6B
2.3 安装依赖
pip install -r requirements.txt
pip install rouge_chinese nltk jieba datasets
2.4 运行
$ cd ptuning/$ sed -i 's/\r//' train.sh$ bash train.sh
train.sh 参数
--do_train
--train_file
AdvertiseGen/train.json
--validation_file
AdvertiseGen/dev.json
--prompt_column
content
--response_column
summary
--overwrite_cache
--model_name_or_path
../chatglm-6b
--output_dir
output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR
--max_source_length
64
--max_target_length
64
--per_device_train_batch_size
16
--per_device_eval_batch_size
1
--gradient_accumulation_steps
2
--predict_with_generate
--max_steps
3000
--logging_steps
10
--save_steps
1000
--learning_rate
1e-2
--pre_seq_len
512
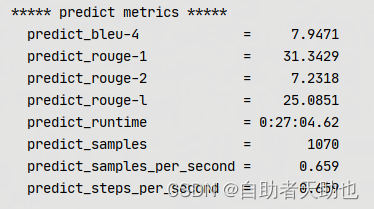
复现结果:
2.5 数据
单轮问答的构建
prompt = ‘类型#裤版型#宽松风格#性感图案#线条裤型#阔腿裤’
answer = ‘宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。’
多轮问答的构建
prompt=
'[Round 0]
问:长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线
答:用电脑能读数据流吗?水温多少
[Round 1]
问:95
答:上下水管温差怎么样啊?空气是不是都排干净了呢?
[Round 2]
问:是的。上下水管都好的
答:'answer='那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!'
输入到模型的input_ids是
input_ids = prompt+answer
因此多轮对话的设计就是
'[Round {}]\n问:{}\n答:{}\n' 的不断叠加来进行生成
2.6 构建前端页面
首先安装 Gradio:pip install gradio,然后运行仓库中的 web_demo.py:
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True,server_name="0.0.0.0", server_port=1902) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。
3 总结
p-tuning-v2, 只训练prefix embedding,其余的都fixed住。数据还只是单轮的对话。虽然多轮可以直接使用concate上下文进行,这也只是暂时的猜想,后续RLHF如何加入。这里解决的是:
- glm的架构图
- transformer.trainer
- ptuning
- gradio前端界面
- FP4、8、16量化