ICLR2021
点云序列在空间维度上具有不规则性和无序性,但在时间维度上具有规律性和有序性。
现有的基于网格的卷积不能直接应用于原始点云序列的时空建模。
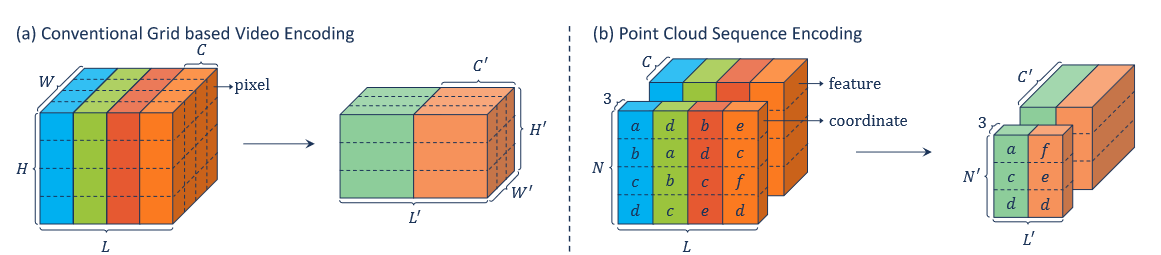
在时空序列下,基于网格和基于点的卷积对比。
创新点
1.首次尝试在原始点云序列建模中分解空间和时间信息。
2.提出一种基于点的卷积操作(PST),分别捕捉三维空间中点的局部结构和空间区域在时间维度上的动态。
3.提出PST转置卷积,通过插值时间动态和空间特征来解码原始点云序列。
下游任务:3D动作识别和4D语义分割性能。
缺点:除非增大邻域搜索半径,否则无法通过堆叠更多的层获得空间上更大的感受野。
Pipeline
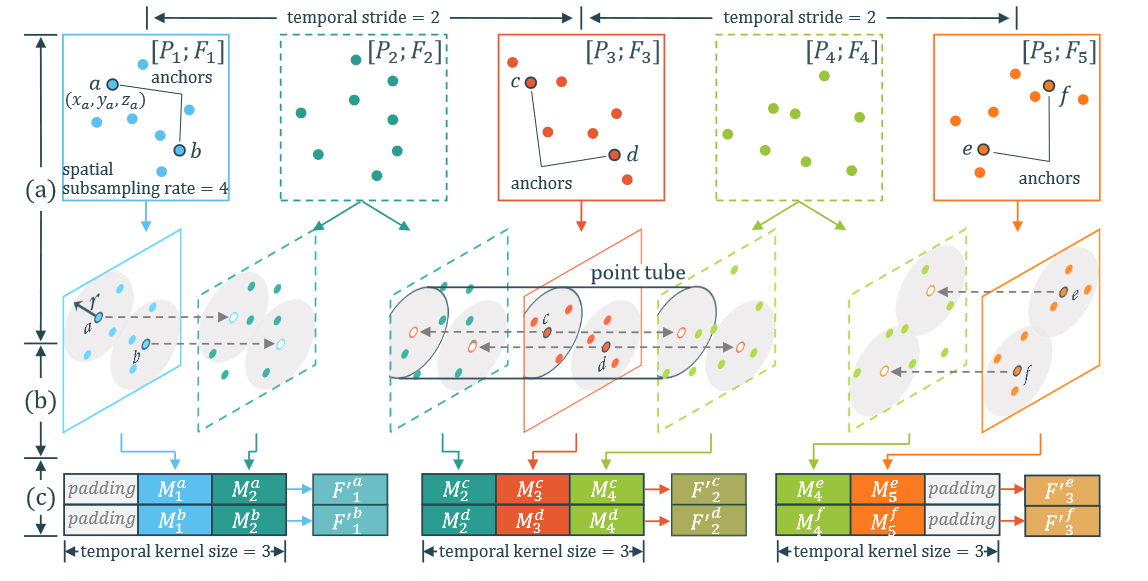
PST卷积
给定点云序列([P1;F1],[P2;F2], ···,[PL;FL]),提出PST卷积将序列编码为([P′1;F′1],[P′2;F′2],···,[P′L;F′L′])。
L和L′表示帧数,P′t∈R3×N′和F′t∈RC′×N′表示编码后的坐标和特征。
对时空进行解耦
点云序列在空间上不规则且无序但在时间上有序,这促使我们将这两个维度解耦,以减少点的空间不规则性对时间建模的影响。
且点云序列的空间位移和时间差异的尺度可能不兼容。将两者同等对待,不利于网络优化。
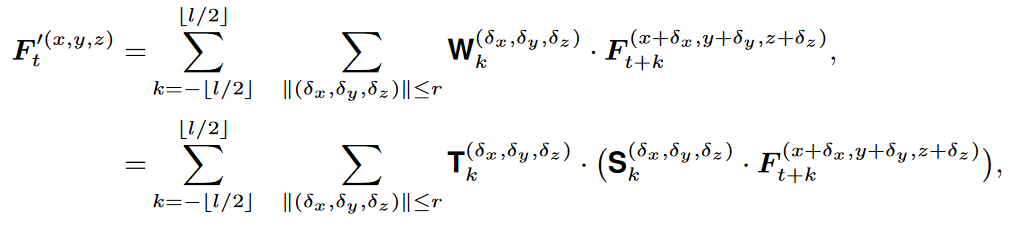
将卷积核W分解为空间卷积核S和时间卷积核T,其中Cm为中间特征的维数。
由于空间和时间是正交且相互独立的,进一步将空间和时间建模分解为: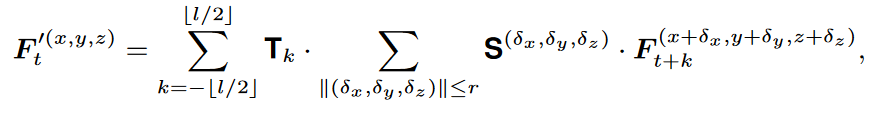
然而这样需要通过点跟踪来捕捉点运动,难以实现精确的点轨迹,且跟踪点通常依赖于点的颜色,可能无法处理无色的点云。选择先对不规则点的空间结构进行建模,然后从空间区域中捕获时间信息。
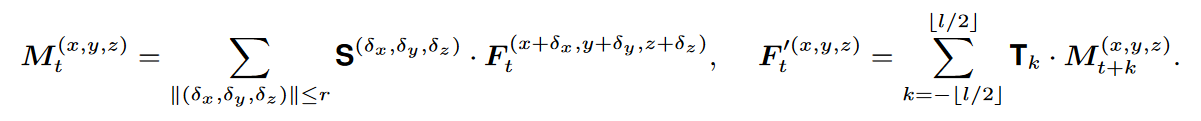
对所有邻域共享一个卷积核S这是不合理的,因为点位移不是离散的。将核函数转换为位移的函数,
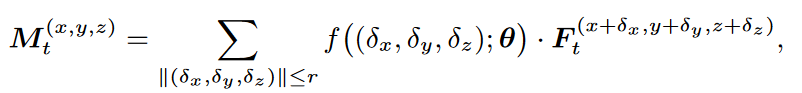
f:R1×3→RCm×C是以θ为参数的(δx,δy,δz)的函数,根据不同的位移生成不同的RCm×C。
POINT TUBE
引入点管来保持时空局部结构。与3D卷积中像素呈规则分布的像素立方体不同,点管是根据输入序列动态生成的,因此密集区域比稀疏区域拥有更多的点管。
时间锚点
根据时间核大小(l)、时间步长(st)和时间填充§自动选择点云序列中的时间锚框,其中l设置为奇数,使得锚框位于点管的中间。此外设置l/2≥p,以避免选择填充框作为锚框。
空间锚点
给定一个采样率ss,在将N个点降采样到N′=N/ss个点。使用FPS进行采样。根据采样的锚点生成POINT TUBE。
在POINT TUBE上执行PST卷积,能够捕获局部区域的动态变化。时间核大小l和空间搜索半径r可以分别捕获时间和空间局部结构。帧下采样(st)和点下采样(ss)使得网络在时间和空间上都具有层次性。全局运动可以通过将信息以时空分层的方式进行合并概括。
PST反卷积
对于point-level的预测任务,需要为所有的原始点提供特征。因此发展了PST反卷积。
设([P′1;F′1],[P′2;F′2],···,[P′L′;F′L′])是原始序列([P1;F1],[P2;F2],···,[PL;FL])的编码序列。PST反卷积将特征(F′1,F′2,···,F′L′)传播到原坐标(P1,P2,···,PL),输出新特征(F′′1,F′′2,···,F′′L),其中F′′t∈RC′′× N。
先通过一个时间转置卷积恢复时间长度: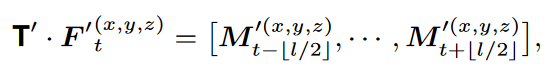
特征通过原始点与邻近锚点之间的反距离进行插值加权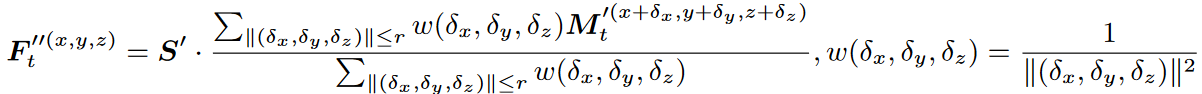
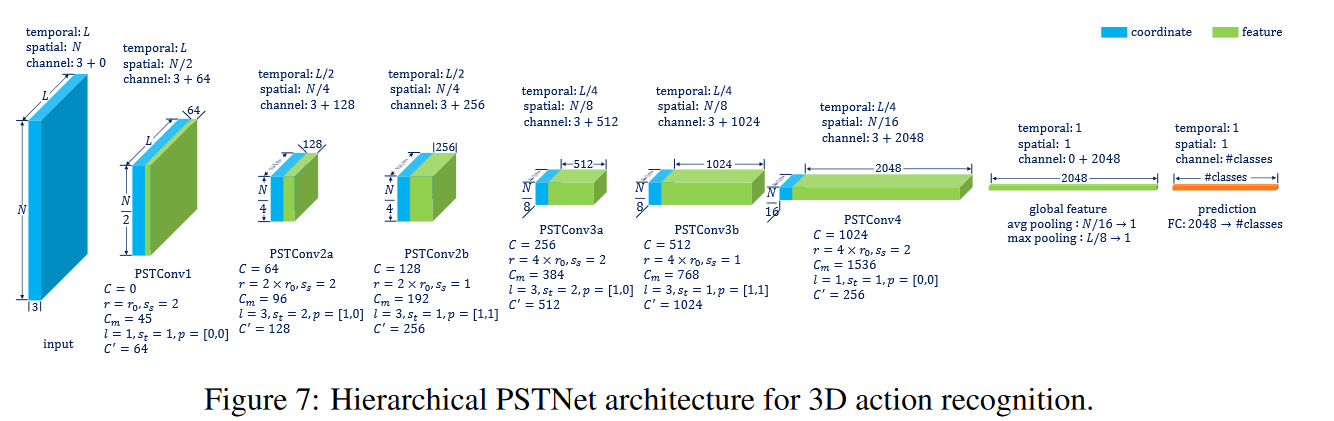
Net Architecture
三维动作识别网络
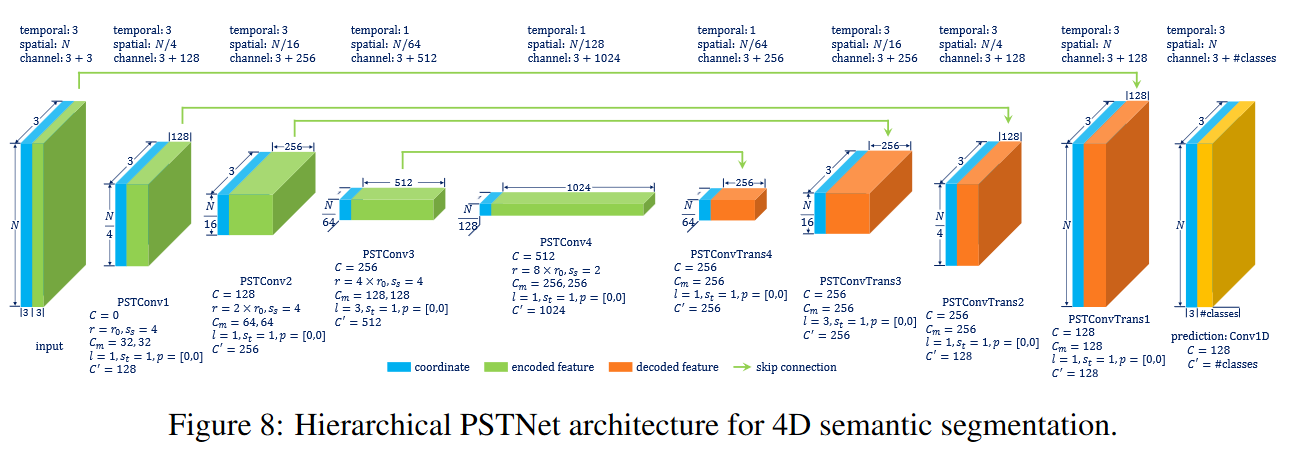
四维语义分割网络
实验
三维动作识别
为每一帧采样2048个点。点云序列被分割成多个片段(用固定的帧数)作为输入。
采用MSR-ACTION3D和NTU RGB+D数据集。
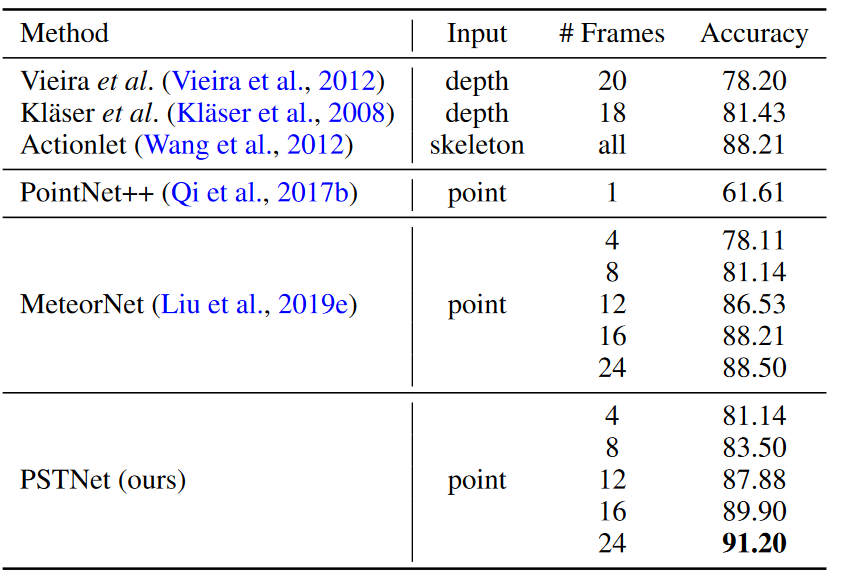
MSR-Action3D上动作识别的准确率。
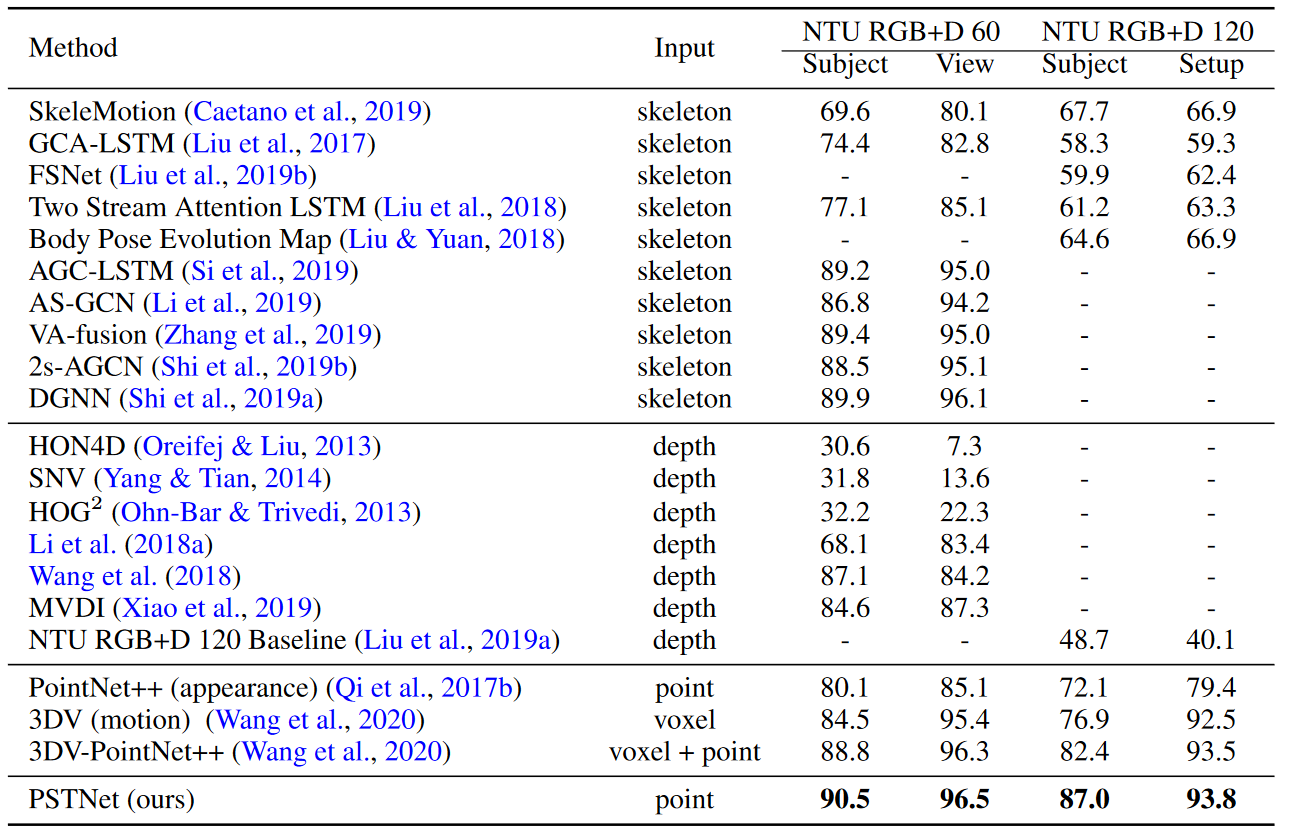
NTU RGB+D数据集上动作识别的准确率。
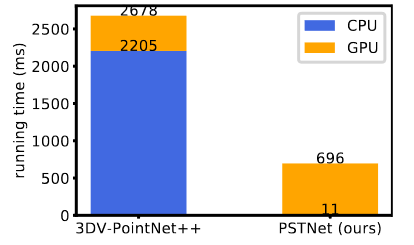
NTU RGB+D数据集上的运行时间。与3DV-Point Net++相比,减少了约2s的时间,说明了PSTNet的高效。
四维语义分割
PSTNet (l=3)利用了时态信息,性能优于当前最先进的方法。
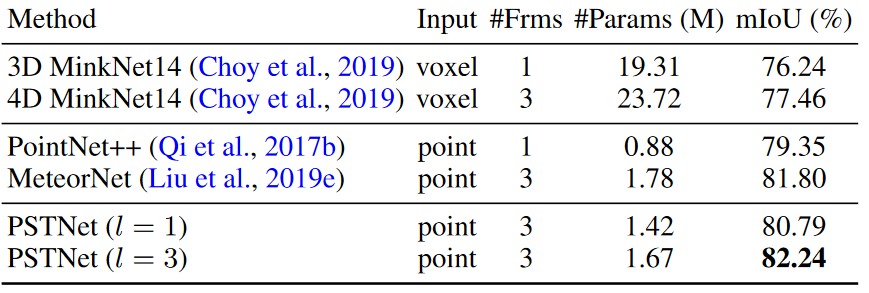
Synthia 4D数据上语义分割的结果。
消融实验
帧数
通常情况下,信息在时间序列上并不是均匀分布的。短的点云片段可能会错过关键帧,从而将模型混淆为噪声。因此,增加帧数有利于动作识别模型。
时间核大小
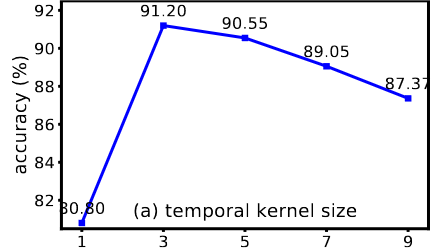
当l大于1时,PSTNet对时间动态进行建模,从而提高推理的动作准确性。
当l大于3时,准确率下降。这是由于MSR - Action3D中的大多数动作都是快速的,使用较小的时间核尺寸有利于捕获快速运动,并且在高层会捕获长距离的时间依赖。
空间半径
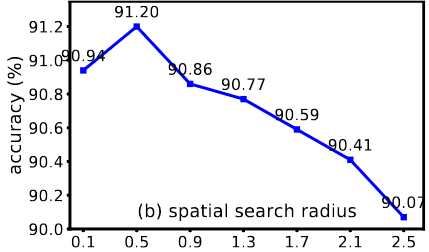
使用过小的r不能捕获足够的结构信息,而使用较大的r会降低空间局部结构对建模的判别性。