代码的评判角度
代码的评判角度
常见的评判代码好坏的词汇:
灵活性(flexibility)、可扩展性(extensibility)、可维护性(maintainability)、可
读性(readability)、可理解性(understandability)、易修改性(changeability)、
可复用(reusability)、可测试性(testability)、模块化(modularity)、高内聚低耦
合(high cohesion loose coupling)、高效(high effciency)、高性能(high
performance)、安全性(security)、兼容性(compatibility)、易用性
(usability)、整洁(clean)、清晰(clarity)、简单(simple)、直接
(straightforward)、少即是多(less code is more)、文档详尽(well-
documented)、分层清晰(well-layered)、正确性(correctness、bug free)、健
壮性(robustness)、鲁棒性(robustness)、可用性(reliability)、可伸缩性
(scalability)、稳定性(stability)、优雅(elegant)、好(good)、坏(bad)
其最常用的几个评判标准:可维护性,可读性,可扩展性,灵活性,间接性,可复用性,可测试性。
可维护性
代码易维护:不破坏原有设计、不引入新bug的情况下,能够快速修改或者添加代码。
代码的可维护性是由多因素共同作用的结果:
- 代码可读性好、简洁、可扩展性好就会使得代码易维护
- 代码分层清晰、模块化好、高内聚、低耦合,遵循基于接口编程等原则
- 与项目代码量、复杂程度、文档等因素相关
可读性
是否符合编码规范,命名是否达意,注释是否详尽,函数长短是否合适,模块划分是否清晰,是否符合高内聚低耦合。
很直观的评判:如果一段代码很容易被读懂,说明可读性好,如果读完代码后有很多疑问,那就说明有问题。
可扩展性
代码可扩展性指的是:在不修改或者少量修改原有代码的情况下,通过扩展的方式添加新的功能代码。
多数的行为型设计模式都是用来解决这个问题的。
灵活性
灵活性的几个场景:
- 添加一个新的功能代码时,原有的代码已经预留好了扩展带你,不需要修改原有代码,只需要在扩展点上加代码,说明了灵活。
- 抽象出很多可复用的模块、类等代码,除了说可复用之外,代码很灵活
- 如果使用某组接口,接口可以应对很多种场景,满足不同的需求,说明接口设计或者代码写的灵活。
简洁性
写代码遵守KISS原则:“Keep It Simple Stupid”,尽量保持代码简单,逻辑清晰。
思从神而行从简,真正的高手能云淡风轻用最简单的方法解决复杂的问题。
可复用
减少重复代码的编写,复用现有的代码。例如,继承、多态的目的之一就是提高代码可复用性。
可测试性
主要是单测
封装、抽象、继承、多态分别可以解决哪些编程问题
1. 封装
封装也叫作信息隐藏或者数据访问保护,类通过暴露有限的访问接口,授权外部仅能使用类提供的方式(函数)来访问内部信息或者数据。
如果我们对类中属性的访问不做限制,那任何代码都可以访问、修改类中的属性,虽然这样看起来更加灵活,但从另一方面来说,过度灵活也意味着不可控,属性可以随意被以各种奇葩的方式修改,而且修改逻辑可能散落在代码中的各个角落,势必影响代码的可读性、可维护性。
除此之外,类仅仅通过有限的方法暴露必要的操作,也能提高类的易用性。如果我们把类属性都暴露给类的调用者,调用者想要正确地操作这些属性,就势必要对业务细节有足够的了解。而这对于调用者来说也是一种负担。相反,如果我们将属性封装起来,暴露少许的几个必要的方法给调用者使用,调用者就不需要了解太多背后的业务细节,用错的概率就减少很多。这就好比,如果一个冰箱有很多按钮,你就要研究很长时间,还不一定能操作正确。相反,如果只有几个必要的按钮,比如开、停、调节温度,你一眼就能知道该如何来操作,而且操作出错的概率也会降低很多。
2. 抽象
讲完了封装特性,我们再来看抽象特性。 封装主要讲的是如何隐藏信息、保护数据,而抽象讲的是如何隐藏方法的具体实现,让调用者只需要关心方法提供了哪些功能,并不需要知道这些功能是如何实现的。
抽象作为一个非常宽泛的设计思想,在代码设计中,起到非常重要的指导作用。很多设计原则都体现了抽象这种设计思想,比如基于接口而非实现编程、开闭原则(对扩展开放、对修改关闭)、代码解耦(降低代码的耦合性)等。
会具体来解释。换一个角度来考虑,我们在定义(或者叫命名)类的方法的时候,也要有抽象思维,不要在方法定义中,暴露太多的实现细节,以保证在某个时间点需要改变方法的实现逻辑的时候,不用去修改其定义。举个简单例子,比如 getAliyunPictureUrl() 就不是一个具有抽象思维的命名,因为某一天如果我们不再把图片存储在阿里云上,而是存储在私有云上,那这个命名也要随之被修改。相反,如果我们定义一个比较抽象的函数,比如叫作getPictureUrl(),那即便内部存储方式修改了,我们也不需要修改命名。
抽象充分的体现了自上而下编程的思想,定义函数、接口的时候要站在上帝视角想清楚这个模块需要具备的功能,不要将当前所做的需求细节过多体现在接口定义中。
3. 继承
继承最大的一个好处就是代码复用。假如两个类有一些相同的属性和方法,我们就可以将这些相同的部分,抽取到父类中,让两个子类继承父类。这样,两个子类就可以重用父类中的代码,避免代码重复写多遍。不过,这一点也并不是继承所独有的,我们也可以通过其他方式来解决这个代码复用的问题,比如利用组合关系而不是继承关系。
过度使用继承,继承层次过深过复杂,就会导致代码可读性、可维护性变差。为了了解一个类的功能,我们不仅需要查看这个类的代码,还需要按照继承关系一层一层地往上查看“父类、父类的父类……”的代码。还有,子类和父类高度耦合,修改父类的代码,会直接影响到子类。
4. 多态
多态:子类可以替换父类,在实际的代码运行过程中,调用子类的方法实现。
- 多态提高了代码的扩展性。
- 多态提供了代码的复用性
- 多态也是很多设计模式、设计原则、编程技巧的代码实现基础,比如策略模式、基于接口而非实现编程、依赖倒置原则、里式替换原则、利用多态去掉冗长的 if-else 语句等等
面向对象编程中常见的面向对象过程编程
1. 滥用getter和setter
在设计实现类的时候,除非真的需要,否则尽量不要给属性定义setter方法,除此之外尽管getter方法相对setter方法安全线,但是如果返回的是容器集合也要防范集合数据被修改的风险
2. Constants,Utils类的设计问题
对于这两种类的设计,我们尽量能做到职责单一,定义一些细化的小雷,比如RedisConstants,FileUtils,而不是定义一个大而全的Constants类,Utils类。除此之外,如果能将这些类中的属性和方法,划分并到其他业务类中,那是最好不过的,能极大提高类内聚性和可复用性
3. 基于贫血模型的开发模型
基于贫血模型开发模式是彻底的面向过程编程风格。这是因为数据和操作是分开定义在VO/BO/Entity和Controller/Service/Repository中。
抽象类和接口能解决哪些问题
1. 抽象类的作用
抽象类只能被继承,不能实例化,抽象类是为代码复用而生的。注意一个问题,既然继承不要求父类一定是抽象类,那不是用抽象类也能实现复用和继承。那从这个角度看,抽象类的意义是什么?
- 如果要使用非抽象类实现继承和复用,定义好父类后,需要强制提醒每个子类决定是否要重新实现需要覆盖的方法,如果方法少还好,如果方法一多,子类根本不清楚应该重写哪些方法,万一漏写了哪个方法,有可能会产生预期不到的影响。总结一下就是说,如果用非抽象类代替抽象类实现复用和继承,需要使用约定的方式实现,抽象类是使用语法强制的手段,约定有可能不被遵守,但是语法强制就不会被违反了。
2. 接口的意义和作用
抽象类是为了代码复用,而接口则侧重于解耦,接口是对行为的一种抽象,相当于一组协议或者契约,可以联想类比一下API接口。接口这只需要关注抽象的接口,而不需要了解具体的实现,具体的实现代码对调用着透明,接口实现了约定和实现体相分离,可以降低代码间的耦合,提高代码扩展性。
| 接口 | 抽象类 | |
|---|---|---|
| 语法 | 不能包含属性,只能声明方法,不能有代码实现,类实现接口必须实现所有生命方法。 | 不能被实例化,只能被继承,可以包含属性和方法,方法可以有代码实现也可能不实现代码。继承抽象类的子类必须实现所有抽象方法 |
| 意义 | 对行为的一种抽象,一组协议或契约 | 避免非继承类子类忘记重写的问题 |
| 选择 | 一种has-a关系,接口抽象 | 一种is-a关系,解决代码复用 |
| 设计思路 | 自上而下的设计思路,先设计接口,再考虑实现 | 自下而上,先有子类的代码重复,在抽象成上层父类 |
接口使用注意点
遵从基于接口而非实现编程的原则要做到三点:
- 函数的命名不能暴露任何实现细节。
- 封装具体的实现细节。定义函数并赋予语义功能后,所有相关功能不应该暴露给调用者,而是在函数中封装好。
- 为实现类定义抽象的接口,具体的实现类都依赖统一的接口定义,遵从一致的上传功能协议,使用者以来接口,而不是具体的实现类编程。
总结一下,我们在做软件开发的时候,一定要有抽象意识、封装意识、接口意识。在定义接口的时候,不要暴露任何实现细节。接口的定义只表明做什么,而不是怎么做。而且,在设计接口的时候,我们要多思考一下,这样的接口设计是否足够通用,是否能够做到在替换具体的接口实现的时候,不需要任何接口定义的改动。
面向接口编程,是将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低代码间的耦合性,提高代码的扩展性。
如果在我们的业务场景中,某个功能只有一种实现方式,未来也不可能被其他实现方式替换,那我们就没有必要为其设计接口,也没有必要基于接口编程,直接使用实现类就可以了。
除此之外,越是不稳定的系统,我们越是要在代码的扩展性、维护性上下功夫。相反,如果某个系统特别稳定,在开发完之后,基本上不需要做维护,那我们就没有必要为其扩展性,投入不必要的开发时间。
组合和继承的比较
原文全是干货。
面向对象分析(OOA),面向对象设计(OOD),面向对象编程(OOP)
面向对象分析过程:
- 第一轮基础分析
- 第二轮分析优化
- 第三轮分析优化
- 第四轮分析优化
- 最终确定需求
需求分析的过程实际上是一个不断迭代的过程,不要视图一下给出完美解决方案,而是先设计一个粗糙的基础的方案,有一个迭代基础,然后再慢慢优化。
面向对象设计
- 划分职责进而识别出有哪些类:
- 可以将需求描述中的名词罗列出来,作为可能得候选类,然后再进行筛选
- 根据需求描述,罗列出涉及的功能点,然后再看哪些功能点职责相近,操作同样的属性,可否应该归为同一个类
- 定义类极其属性和方法
- 识别出需求描述中的动词作为候选方法,找出功能点中涉及的名词作为候选属性,然后进一步过滤筛选。
- 定义类与类之间的交互关系:泛化、实现、关联、聚合、组合、依赖
- 将类组装起来并提供执行入口
系统设计过程中,为了避免业务知识的耦合,让上下游更通用,通常,不希望下层系统(也就是被调系统)包含过多上层系统(调用系统)的业务信息,但是,可以接受上层系统包含下层系统的业务信息。比如,订单系统、优惠卷系统、换购商城等作为调用积分系统的上层系统,可以包含一些积分相关的业务信息,但是反过来,积分系统中不要包含过多订单、优惠卷、换购相关的信息。
同层系统之间的调用通常用异步消息调用,上下游系统之间的调用一般使用同步接口调用。
七大原则
设计模式的主要任务是进行解耦合,七大原则如下
| 设计原则 | 解释 |
|---|---|
| 开闭原则 | 当应用的需求改变时,在不修改软件实体的源代码或者二进制代码的前提下,可以扩展模块的功能,使其满足新的需求。 |
| 当软件需要发生变化时,只需要根据需求重新派生一个实现类来扩展就可以了(至扩展不修改) | |
| 依赖倒置原则 | 高层模块不应该依赖低层模块,两者都应该依赖其抽象;抽象不应该依赖细节,细节应该依赖抽象,其核心思想是:要面向接口编程,不要面向实现编程。 |
- 每个类尽量提供接口或抽象类,或者两者都具备。
- 变量的声明类型尽量是接口或者是抽象类。
- 任何类都不应该从具体类派生。
- 使用继承时尽量遵循里氏替换原则。
|
| 单一职责 | 单一职责原则规定一个类应该有且仅有一个引起它变化的原因,否则类应该被拆分 |
| 接口隔离原则 | 要为各个类建立它们需要的专用接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用 |
| 迪米特法则 | 如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。 |
| 里氏替换原则 | 子类可以扩展父类的功能,但不能改变父类原本的功能 - 不能修改父类的非抽象类
- 重载父类时参数要比父类的方法更宽松
- 子类的方法实现父类的方法时(重写/重载或实现抽象方法),方法的后置条件(即方法的的输出/返回值)要比父类的方法更严格或相等
|
| 合成复用原则 | 尽量使用对象组合,聚合,而不用继承关系达到代码复用的目的 |
重载父类时参数要比父类的方法更宽松 解释:
public class Parents {public void getOrder(int a) {System.out.println("parents");}
}public class Child1 extends Parents{public void getOrder(Object o) {System.out.println("child");}
}public static void main(String[] args) { Parents p = new Parents();// 输出 parentsa.getOrder(2);// 输出 parentsChild1 a = new Child1();a.getOrder(2);}public class Parents {public void getOrder(Object a) {System.out.println("parents");}
}public class Child1 extends Parents{public void getOrder(int o) {System.out.println("child");}
}public static void main(String[] args) { Parents p = new Parents();// 输出 parentsa.getOrder(2);// 输出 childChild1 a = new Child1();a.getOrder(2);
}//根据里氏替换,父类出现的地方子类都能替换原则,
// 如果子类参数比父类严格 会有可能子类和父类方法输出不一样// 如果子类比父类宽泛,子类替换父类 功能一致接口隔离原则和单一职责都是为了提高类的内聚性、降低它们之间的耦合性,体现了封装的思想,但两者是不同的:
- 单一职责原则注重的是职责,而接口隔离原则注重的是对接口依赖的隔离。
- 单一职责原则主要是约束类,它针对的是程序中的实现和细节;接口隔离原则主要约束接口,主要针对抽象和程序整体框架的构建。
内聚
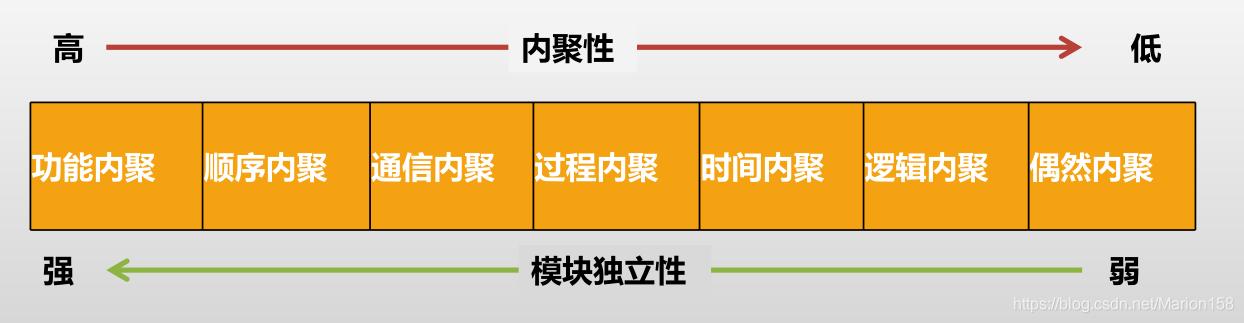
内聚是模块功能强度(一个模块内部各个元素彼此结合的紧密程度)的度量。一个内聚程度高的模块(在理想情况下)应当只做一件事。一般模块的内聚性分为七种类型。
巧合内聚(偶然内聚)
指一个模块内的各处理元素之间没有任何联系。 例如:三条不相关的语句( move O to R , read file F , move S toT ),模块B 和C需要都使用了这三条语句。于是将这三条语句提取出来形成 模块 A 。模块 A 中的语句就是偶然内聚。
逻辑内聚
这种模块把几种相关的功能组合在一起,每次被调用时,由传送给模块的控制型参数来确定该模块应执行哪一种功能。逻辑内聚模块比巧合内聚模块的内聚程度要高。因为它表明了各部分之间在功能上的相关关系。
如果模块完成的任务在逻辑上属于相同或相似的一类,称为逻辑内聚。
时间内聚
这种模块大多为多功能模块,但要求模块的各个功能必须在同一时间段内执行。例如初始化模块和终止模块。时间内聚模块比逻辑内聚模块的内聚程度又稍高一些。在一般情形下,各部分可以以任意的顺序执行,所以它的内部逻辑更简单。
过程内聚
指一个模块完成多个任务,这些任务必须按指定的过程执行。 例如:先写姓名 → 电话 → 家庭住址,先后顺序符合客户需求。
通信内聚
指模块内的所有处理元素都在同一个数据结构上操作,或者各处理使用相同的输入数据或者产生相同的输出数据。 例如:一个模块根据员工生日计算员工年龄和退休时间。
顺序内聚
指一个模块中的各个处理元素都密切相关于同一功能且必须顺序执行,前 一功能元素的输出就是下一功能元素的输入。例如:先计算员工的年龄再计算退休时间。
功能内聚
这是最强的内聚,指模块内的所有元素共同作用完成 一个功能 ,缺一不可。(一个调用规则引擎的模块: 无论是校验、构建请求、调用引擎还是解析结果, 这个模块中所有的代码都是为了实现一个功能:调用规则引擎并解析结果。)
耦合
耦合解释
https://blog.csdn.net/Marion158/article/details/115892451
单一职责
根本思想:一个类或者模块只负责完成一个职责(或者功能)
注意,这个原则描述的对象包含两个,一个是类(class),一个是模块(module)。
不同的应用场景、不同阶段的需求背景下,对同一个类的职责是否单一的判定,可能都是不一样的。在某种应用场景或者当下的需求背景下,一个类的设计可能已经满足单一职责原则了,但如果换个应用场景或着在未来的某个需求背景下,可能就不满足了,需要继续拆分成粒度更细的类。
评价一个类的职责是否足够单一,我们并没有一个非常明确的、可以量化的标准,可以说,这是件非常主观、仁者见仁智者见智的事情。实际上,在真正的软件开发中,我们也没必要过于未雨绸缪,过度设计。所以,我们可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构
评价类是否是单一职责有几个可参考的指标:
- 类中的代码行数、函数或属性过多,会影响代码的可读性和可维护性,我们就需要考虑对类进行拆分;、
- 类依赖的其他类过多,或者依赖类的其他类过多,不符合高内聚、低耦合的设计思想,我们就需要考虑对类进行拆分
- 私有方法过多,我们就要考虑能否将私有方法独立到新的类中,设置为 public 方法,供更多的类使用,从而提高代码的复用性;
- 比较难给类起一个合适名字,很难用一个业务名词概括,或者只能用一些笼统的Manager、Context 之类的词语来命名,这就说明类的职责定义得可能不够清晰;
- 类中大量的方法都是集中操作类中的某几个属性,比如,在 UserInfo 例子中,如果一半的方法都是在操作 address 信息,那就可以考虑将这几个属性和对应的方法拆分出来。
类的职责并不是越单一越好:
单一职责原则通过避免设计大而全的类,避免将不相关的功能耦合在一起,来提高类的内聚
性。同时,类职责单一,类依赖的和被依赖的其他类也会变少,减少了代码的耦合性,以此
来实现代码的高内聚、低耦合。但是,如果拆分得过细,实际上会适得其反,反倒会降低内
聚性,也会影响代码的可维护性。
开闭原则
添加一个新的功能应该是,在已有代码基础上扩展代码(新增模块、类、方法等),而非修改已有代码(修改模块、类、方法等)。
- 如何理解”对扩展开发,对修改关闭“
添加一个新的功能,应该是通过在已有代码基础上扩展代码(新增模块、类、方法、属性
等),而非修改已有代码(修改模块、类、方法、属性等)的方式来完成。关于定义,我们
有两点要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的修改代码的代价
来完成新功能的开发。第二点是,同样的代码改动,在粗代码粒度下,可能被认定为“修
改”;在细代码粒度下,可能又被认定为“扩展”。
- 如何做到“对扩展开放,对修改关闭”
我们要时刻具备扩展意识、抽象意识、封装意识。在写代码的时候,我们要多花点时间思考
一下,这段代码未来可能有哪些需求变更,如何设计代码结构,事先留好扩展点,以便在未
来需求变更的时候,在不改动代码整体结构、做到最小代码改动的情况下,将新的代码灵活
地插入到扩展点上。
很多设计原则、设计思想、设计模式,都是以提高代码的扩展性为最终目的的。特别是 23
种经典设计模式,大部分都是为了解决代码的扩展性问题而总结出来的,都是以开闭原则为
指导原则的。最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编
程,以及大部分的设计模式(比如,装饰、策略、模板、职责链、状态)。
里氏替换
里式替换原则是用来指导,继承关系中子类该如何设计的一个原则。理解里式替换原则,最
核心的就是理解“design by contract,按照协议来设计”这几个字。父类定义了函数
的“约定”(或者叫协议),那子类可以改变函数的内部实现逻辑,但不能改变函数原有
的“约定”。这里的约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至
包括注释中所罗列的任何特殊说明。
理解这个原则,我们还要弄明白里式替换原则跟多态的区别。虽然从定义描述和代码实现上
来看,多态和里式替换有点类似,但它们关注的角度是不一样的。多态是面向对象编程的一
大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种
设计原则,用来指导继承关系中子类该如何设计,子类的设计要保证在替换父类的时候,不
改变原有程序的逻辑及不破坏原有程序的正确性。
依赖倒置
- 什么是控制反转:
实际上,控制反转是一个比较笼统的设计思想,并不是一种具体的实现方法,一般用来指导
框架层面的设计。这里所说的“控制”指的是对程序执行流程的控制,而“反转”指的是在
没有使用框架之前,程序员自己控制整个程序的执行。在使用框架之后,整个程序的执行流
程通过框架来控制。流程的控制权从程序员“反转”给了框架。
例如使用模版模式,抽象类中定义操作流程并预留扩展点,子类继承代码后只需重写扩展点即可,无需过度感知整个方法的执行流程。
- 什么是依赖注入
依赖注入和控制反转恰恰相反,它是一种具体的编码技巧。我们不通过 new 的方式在类内
部创建依赖类的对象,而是将依赖的类对象在外部创建好之后,通过构造函数、函数参数等
方式传递(或注入)给类来使用。
- 什么事依赖倒置
依赖反转原则也叫作依赖倒置原则。这条原则跟控制反转有点类似,主要用来指导框架层面
的设计。高层模块不依赖低层模块,它们共同依赖同一个抽象。抽象不要依赖具体实现细
节,具体实现细节依赖抽象。
KISS原则
KISS:尽量保持简单。有以下几种解释方式
Keep It Simple and Stupid
Keep It Short and Simple
Keep It Simple and Straightforward
KISS原则可以保持代码可读和可维护,因为代码编写足够简单,bug比较容易被发现,修复起来也简单。
如何写出满足KISS原则的代码
- 不要使用同事可能不懂得技术来实现代码,比如前面例子中的正则表达式,还有一些编程语言中的高级语法。
- 不要重复造轮子,要善于使用已经有的工具类库。
- 不要过度优化,不要过度使用一些奇技淫巧(比如,位运算代替算术运算,复杂的条件语句代替if-else,使用一些过于底层的函数等)优化代码,而牺牲代码可读性。
YAGNI原则
YAGNI原则全称:You Ain’t Gonna Need It。他的意思是不要去设计当前用不到的功能,不要编写用不到的代码,核心思想是不要做过度设计。
比如,我们的系统暂时只会用到Redis配置信息,以后可能会用到zk,那在未用到zk之前,我们没必要编写这部分代码。当然这并不是说我们不需要考虑代码的扩展性,要预留好扩展点,等到需要的时候再实现zk配置信息的代码。
1. 简单工厂模式
简单工厂适用于工厂类负责创建的对象较少的场景,且客户端只需传入工厂类的参数,如何创造对象的逻辑不关心。
假设现在有课程借口ICourse,具体课程有JavaCourse,PythonCourse
public interface ICourse { /** 录制视频 */public void record();
} public class JavaCourse implements ICourse {public void record() {System.out.println("录制 Java 课程"); }
}public class PythonCourse implements ICourse {public void record() {System.out.println("录制 python 课程"); }
}
正常情况下客户端调用的代码会这样写:
public static void main(String[] args) { ICourse course = new JavaCourse();ICourse course = new PythonCourse();course.record();course.record();
}
每个父亲接口指向具体的子类引用,随着子类越来越多,客户端以来会越来越复杂,因此需要将这些依赖隐藏起来,减弱依赖。目前代码并不复杂,但是从代码设计角度不易于扩展。
创建CourseFactory工厂
public class CourseFactory {public ICourse create(String name){if("java".equals(name)){return new JavaCourse();}else if("python".equals(name)){return new PythonCourse();}else {return null;} }}
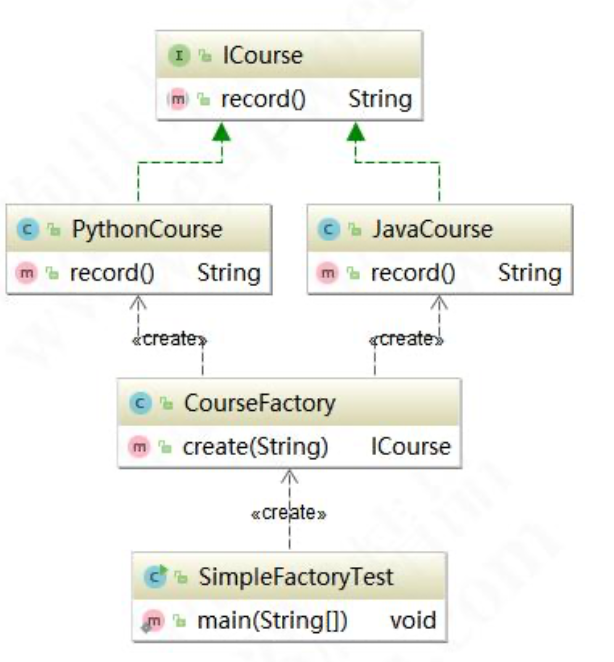
类图如上,客户端只需依赖工厂,降低了依赖复杂程度,但是依然存在问题,每次添加新课程的时候都要修改CourseFactory源码,这违背了开闭原则,因此使用反射机制对简单工厂进行优化。
class CourseFactory{public Icourse create(String classname){try{if(!(null==className||"".equals(className))){return (ICourse) Class.forName(className).newInstance());}}catch(Exception e){}return null;}
}public static void main(String[] args) {CourseFactory factory = new CourseFactory();ICourse course =factory.create("com.gupaoedu.vip.pattern.factory.simplefactory.JavaCourse"); course.record();
}
上面代码有个问题,方法参数是字符串,很有可能非法,很难控制类是否存在,可以再次修改。
public ICourse create(Class<? extends ICourse> clazz){ try {if (null != clazz) {return clazz.newInstance();}}catch (Exception e){e.printStackTrace(); }return null;
}
public static void main(String[] args) { CourseFactory factory = new CourseFactory(); ICourse course = factory.create(JavaCourse.class);course.record();
}
再看一下类图,依赖会减少很多,扩展起来也容易。但简单工厂优缺点:工厂职责相对过重,如果有1000门课程,那都要依赖这一个工厂。
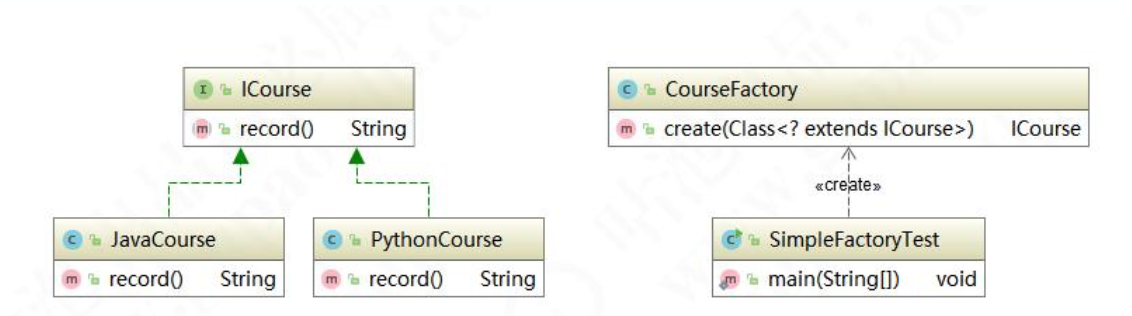
2. 工厂方法模式
工厂方法模式是指定义一个创建对象的接口,但让实现这个接口的类决定实例化哪个类。每个类别的物体都有自己的工厂,工厂方法中,用户只需要关心所需产品对应的工厂,无需关心创建细节,而且加入新的产品符合开闭原则。工厂方法模式主要解决产品扩展的问题,在简单工厂中,随着产品链的丰富,如果每个 课程的创建逻辑有区别的话,工厂的职责会变得越来越多,有点像万能工厂,并不便于 维护。根据单一职责原则我们将职能继续拆分,专人干专事。Java 课程由 Java 工厂创建, Python 课程由 Python 工厂创建,对工厂本身也做一个抽象。
创建ICourseFactory接口
public interface ICourseFactory { ICourse create();
}
分别创建java和python子工厂
public class JavaCourseFactory implements ICourseFactory { public ICourse create() {return new JavaCourse(); }
}public class PythonCourseFactory implements ICourseFactory { public ICourse create() {return new PythonCourse(); }
}
测试代码
public static void main(String[] args) { ICourseFactory factory = new PythonCourseFactory();ICourse course = factory.create();course.record();factory = new JavaCourseFactory();course = factory.create(); course.record();
}
看一下类图
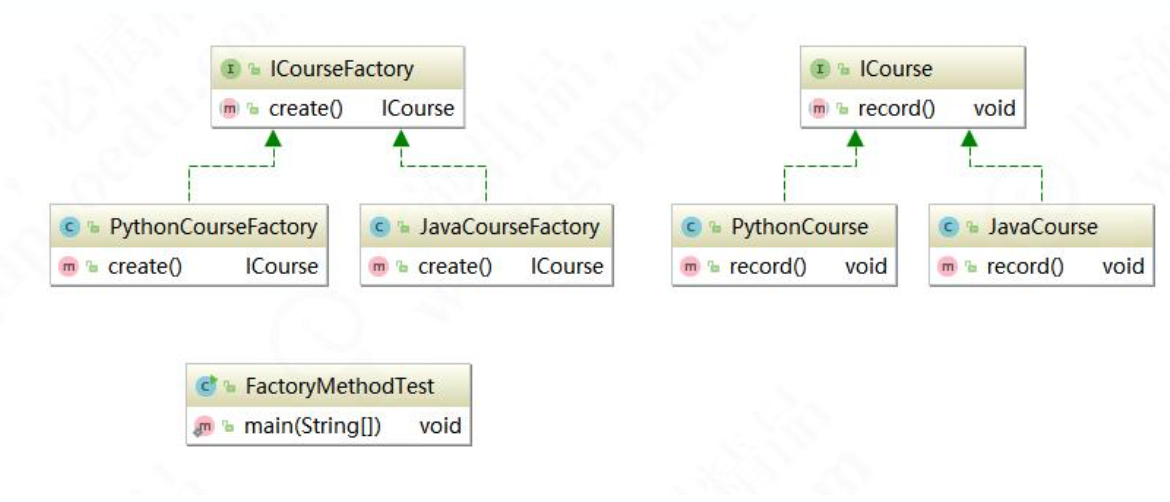
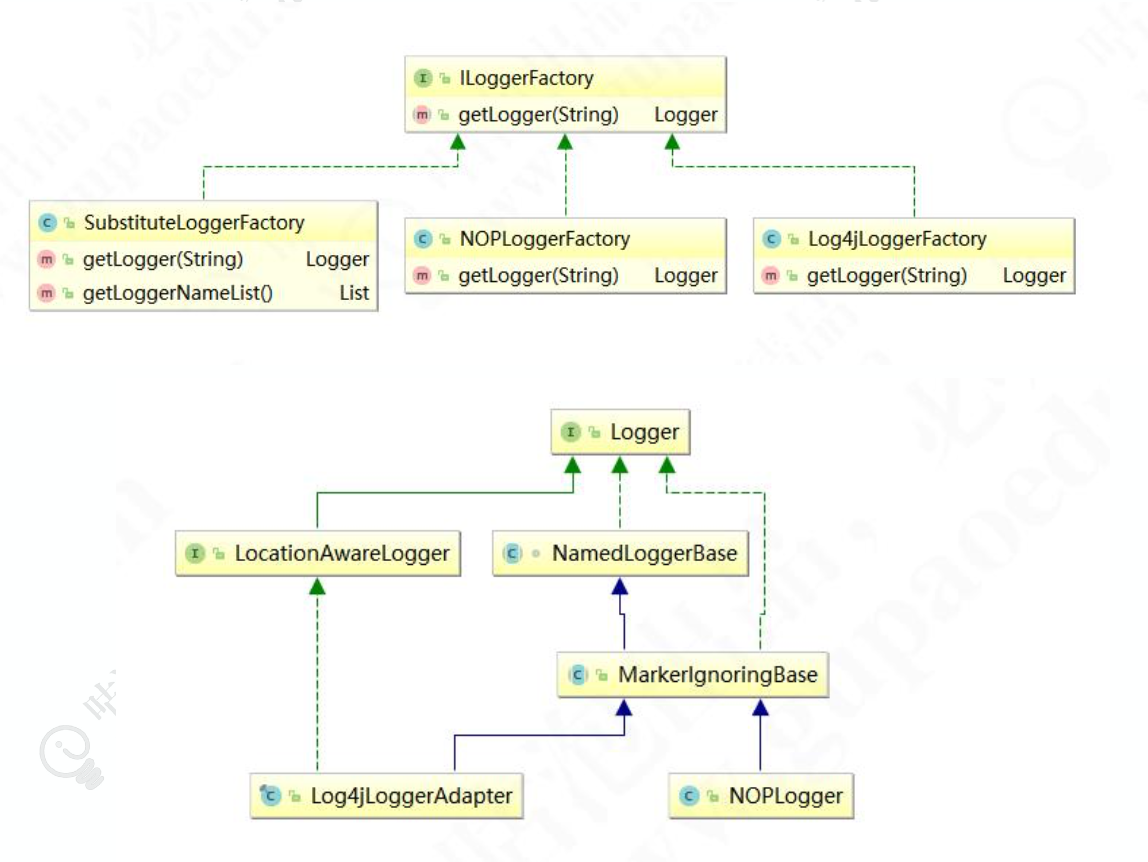
看一下工厂模式具体的应用,logback的类图,看起来很清晰。
工厂方法缺点:
- 很明显,如果类个数过多,那复杂度大大增加
- 增加了系统的抽象性和理解难度
3. 抽象工厂模式
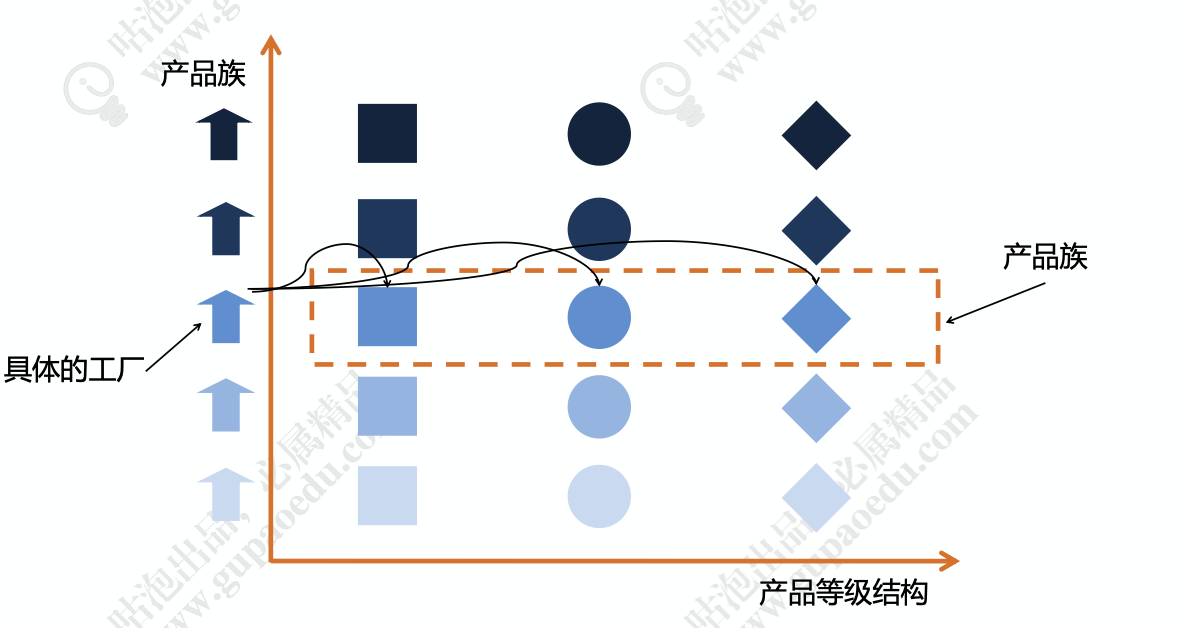
抽象工厂模式是指提供一个创建一系列相关或者相互依赖对象的接口,无需制定他们具体的类。这个工厂可以生产一个系列的产品,每个不同的品牌拥有一个一个继承接口的工厂,类似于方法工厂模式。需要了解一下产品等级结构和产品族。

上图中每一行可以代表一个工厂,每一列代表一个产品,,比如,美的电器生产 多种家用电器。那么上图中,颜色最深的正方形就代表美的洗衣机、颜色最深的圆形代 表美的空调、颜色最深的菱形代表美的热水器,颜色最深的一排都属于美的品牌,都是 美的电器这个产品族。再看最右侧的菱形,颜色最深的我们指定了代表美的热水器,那 么第二排颜色稍微浅一点的菱形,代表海信的热水器。同理,同一产品结构下还有格力 热水器,格力空调,格力洗衣机。再看下面的这张图,最左侧的小房子我们就认为具体的工厂,有美的工厂,有海信工厂, 有格力工厂。每个品牌的工厂都生产洗衣机、热水器和空调。
现在要建立一个工厂接口,可以生成视频也可以生成笔记,然后生成python和java两个具体工厂实例,由具体工厂产中对应的产品族的产品
public interface IVideo{void record();
}public interface INote{void edit();
}public interface CourseFactory{INote createNote();IVideo createVideo();
}
java工厂
public class JavaVideo implements IVideo {public void record() {System.out.println("录制 Java 视频"); }
}public class JavaNote implements INote { public void edit() {System.out.println("编写 Java 笔记"); }
}public class JavaCourseFactory implements CourseFactory {public INote createNote() {return new JavaNote();}public IVideo createVideo() { return new JavaVideo();}
}
同样可以创建Python工厂
public class PythonVideo implements IVideo { public void record() {System.out.println("录制 Python 视频"); }
}public class PythonNote implements INote {public void edit() {System.out.println("编写 Python 笔记"); }
}public class PythonCourseFactory implements CourseFactory {public INote createNote() {return new PythonNote(); }public IVideo createVideo() { return new PythonVideo();}
}
看一下客户端调用
public static void main(String[] args) {JavaCourseFactory factory = new JavaCourseFactory(); factory.createNote().edit(); factory.createVideo().record();
}
4. 单例模式
单例模式(Singleton Pattern)是指确保一个类在任何情况下都绝对只有一个实例,并 提供一个全局访问点。单例模式是创建型模式。单例模式在现实生活中应用也非常广泛。 例如,国家主席、公司 CEO、部门经理等。在 J2EE 标准中,ServletContext、 ServletContextConfig 等;在 Spring 框架应用中 ApplicationContext;数据库的连接 池也都是单例形式。单例模式结构图如下

4.1 饿汉模式
在类加载阶段就已经生成实例,在有线程之前就生成实例,绝对的线程安全。
public class SingleModel {private final static SingleModel singelModel = new SingleModel();private SingleModel(){}public static SingleModel getInstance(){return singelModel;}
}或者写在静态块中实例化
public class SingleModel {private final static SingleModel singelModel;static{singleModel = new SingleModel();}private SingleModel(){}public static SingleModel getInstance(){return singelModel;}
}4.2 懒汉模式
只有当外部类调用的时候才会加载,先看一种简单的懒汉模式,这种模式可以保证线程的安全,但是当有很多线程使用的话容易造成性能下降。
public class SingleSimpleLazy {private static SingleSimpleLazy single = null;private SingleSimpleLazy(){}public static synchronized SingleSimpleLazy getInstance(){if(single == null){single = new SingleSimpleLazy();}return single;}
}
双重检查锁的单例模式
public class SingleDoubleCheckLazy {private static volatile SingleDoubleCheckLazy singleDoubleCheckLazy = null;private SingleDoubleCheckLazy(){}public static SingleDoubleCheckLazy getInstance(){if(singleDoubleCheckLazy == null){synchronized (SingleDoubleCheckLazy.class){if(singleDoubleCheckLazy == null){singleDoubleCheckLazy = new SingleDoubleCheckLazy();}}}return singleDoubleCheckLazy;}
}
为什么需要volatile修饰?
new 实例背后的指令
这个被忽略的问题在于 Cache cache=new Cache() 这行代码并不是一个原子指令。使用 javap -c指令,可以快速查看字节码。
// 创建 Cache 对象实例,分配内存0: new #5 // class com/query/Cache// 复制栈顶地址,并再将其压入栈顶3: dup// 调用构造器方法,初始化 Cache 对象4: invokespecial #6 // Method "<init>":()V// 存入局部方法变量表7: astore_1
从字节码可以看到创建一个对象实例,可以分为三步:
- 分配对象内存
- 调用构造器方法,执行初始化
- 将对象引用赋值给变量。
虚拟机实际运行时,以上指令可能发生重排序。以上代码 2,3 可能发生重排序,但是并不会重排序 1 的顺序。也就是说 1 这个指令都需要先执行,因为 2,3 指令需要依托 1 指令执行结果。
Java 语言规规定了线程执行程序时需要遵守 intra-thread semantics。**intra-thread semantics ** 保证重排序不会改变单线程内的程序执行结果。这个重排序在没有改变单线程程序的执行结果的前提下,可以提高程序的执行性能。
虽然重排序并不影响单线程内的执行结果,但是在多线程的环境就带来一些问题。
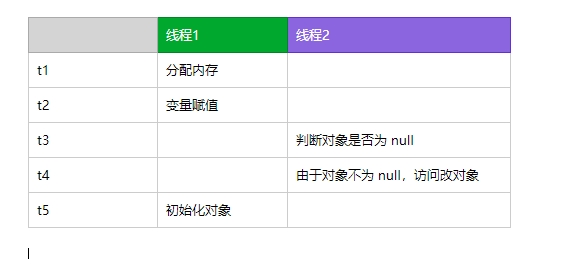
上面错误双重检查锁定的示例代码中,如果线程 1 获取到锁进入创建对象实例,这个时候发生了指令重排序。当线程1 执行到 t3 时刻,线程 2 刚好进入,由于此时对象已经不为 Null,所以线程 2 可以自由访问该对象。然后该对象还未初始化,所以线程 2 访问时将会发生异常。
上述的单例模式都存在一个问题,通过反射机制可以破坏单例模式,生成多个实例,如下代码。
public static void main(String[] args) throws NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {Logger logger = Logger.getLogger("test");Class clazz = SingleDoubleCheckLazy.class;Constructor constructor = clazz.getDeclaredConstructor(null);constructor.setAccessible(true);SingleDoubleCheckLazy singleDoubleCheckLazy1 = (SingleDoubleCheckLazy)constructor.newInstance();SingleDoubleCheckLazy singleDoubleCheckLazy2 = SingleDoubleCheckLazy.getInstance();logger.info("singleDoubleCheckLazy1 == singleDoubleCheckLazy2 " + String.valueOf(singleDoubleCheckLazy1 == singleDoubleCheckLazy2));}//信息: singleDoubleCheckLazy1 == singleDoubleCheckLazy2 false
不会被反射破坏掉的单例模式
public class LazyInnerClassSingleton {//默认使用 LazyInnerClassGeneral 的时候,会先初始化内部类 //如果没使用的话,内部类是不加载的private LazyInnerClassSingleton() {if (LazyHolder.LAZY != null) {throw new RuntimeException("不允许创建多个实例");}}//每一个关键字都不是多余的
//static 是为了使单例的空间共享
//保证这个方法不会被重写,重载public static final LazyInnerClassSingleton getInstance() {
//在返回结果以前,一定会先加载内部类return LazyHolder.LAZY;}//默认不加载private static class LazyHolder {private static final LazyInnerClassSingleton LAZY = new LazyInnerClassSingleton();}
}
序列化会破坏单例模式,如下所示
public class SingleHungrySerializable implements Serializable {private final static SingleHungrySerializable singleHungrySerializable = new SingleHungrySerializable();private SingleHungrySerializable(){}public static SingleHungrySerializable getInstance(){return singleHungrySerializable;}public static void main(String[] args) throws IOException, ClassNotFoundException {SingleHungrySerializable s1 = SingleHungrySerializable.getInstance();SingleHungrySerializable s2 = null;FileOutputStream fos = new FileOutputStream("SeriableSingleton.obj");ObjectOutputStream oos = new ObjectOutputStream(fos);oos.writeObject(s1);oos.flush();oos.close();FileInputStream fis = new FileInputStream("SeriableSingleton.obj");ObjectInputStream ois = new ObjectInputStream(fis);s2 = (SingleHungrySerializable) ois.readObject();ois.close();System.out.println(s1);System.out.println(s2);System.out.println(s1 == s2);}
}
运行结果中,可以看出,反序列化后的对象和手动创建的对象是不一致的,实例化了两 次,违背了单例的设计初衷。那么,我们如何保证序列化的情况下也能够实现单例?其实很简单,只需要增加 readResolve()方法即可。来看优化代码
public class SingleHungrySerializable implements Serializable {private final static SingleHungrySerializable singleHungrySerializable = new SingleHungrySerializable();private SingleHungrySerializable(){}public static SingleHungrySerializable getInstance(){return singleHungrySerializable;}private Object readResolve(){return singleHungrySerializable;}public static void main(String[] args) throws IOException, ClassNotFoundException {SingleHungrySerializable s1 = SingleHungrySerializable.getInstance();SingleHungrySerializable s2 = null;FileOutputStream fos = new FileOutputStream("SeriableSingleton.obj");ObjectOutputStream oos = new ObjectOutputStream(fos);oos.writeObject(s1);oos.flush();oos.close();FileInputStream fis = new FileInputStream("SeriableSingleton.obj");ObjectInputStream ois = new ObjectInputStream(fis);s2 = (SingleHungrySerializable) ois.readObject();ois.close();System.out.println(s1);System.out.println(s2);System.out.println(s1 == s2);}
}
注册式单例
注册式单例有两种,一种为容器缓存,一种为枚举类登记。
5. 原型模式
原型模式是指通过某实例进行拷贝赋值。
适用场景:
1、类初始化消耗资源较多。
2、new 产生的一个对象需要非常繁琐的过程(数据准备、访问权限等)
3、构造函数比较复杂。
4、循环体中生产大量对象时。
在spring中的应用是scope=“prototype”原型模式
5.1 浅拷贝例子
public interface Prototype{Prototype clone();
}public class ConcretePrototypeA implements Prototype { private int age;private String name;private List hobbies;public int getAge() {return age;}public void setAge(int age) {this.age = age; }public String getName() { return name;}public void setName(String name) { this.name = name;
}public List getHobbies() {return hobbies;}public void setHobbies(List hobbies) {this.hobbies = hobbies;}@Overridepublic ConcretePrototypeA clone() {ConcretePrototypeA concretePrototype = new ConcretePrototypeA(); concretePrototype.setAge(this.age); concretePrototype.setName(this.name); concretePrototype.setHobbies(this.hobbies);return concretePrototype;}
}
创建Client对象
public class Client {private Prototype prototype; public Client(Prototype prototype){this.prototype = prototype; }public Prototype startClone(Prototype concretePrototype){ return (Prototype)concretePrototype.clone();}
}
测试代码
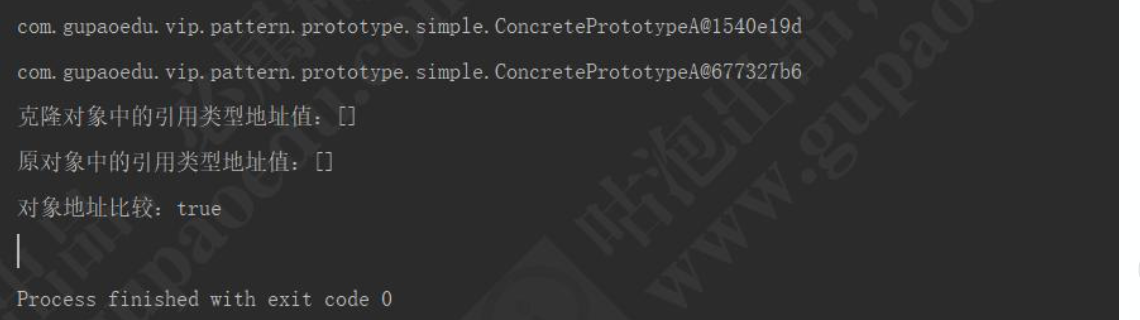
public class PrototypeTest {public static void main(String[] args) {
// 创建一个具体的需要克隆的对象ConcretePrototypeA concretePrototype = new ConcretePrototypeA(); // 填充属性,方便测试concretePrototype.setAge(18); concretePrototype.setName("prototype");List hobbies = new ArrayList<String>(); concretePrototype.setHobbies(hobbies); System.out.println(concretePrototype);Client client = new Client(concretePrototype); ConcretePrototypeA concretePrototypeClone = (ConcretePrototypeA)client.startClone(concretePrototype); System.out.println(concretePrototypeClone);System.out.println("克隆对象中的引用类型地址值:" + concretePrototypeClone.getHobbies());System.out.println("原对象中的引用类型地址值:" + concretePrototype.getHobbies());System.out.println("对象地址比较:"+(concretePrototypeClone.getHobbies() ==
concretePrototype.getHobbies())); }
5.2 深拷贝
参见链接https://www.yuque.com/qujundong/fw93k6/ldf9on
6. 委派模式
委派模式作用:消除程序中大量的if…else…和swtich语句
委派模式和代理模式很像,或者说是一种特殊情况下的代理模式。例子:老板(boss)给项目经理(leader)下达任务,再由经理汇报工作进度和结果给老板。
创建IEmployee接口
public interface IEmployee {public void doing(String command);
}
再创建员工EmployeeA和EmployeeB
public class EmployeeA implements IEmployee {@Overridepublic void doing(String command) {System.out.println("我是员工 A,我现在开始干" + command + "工作");}
}public class EmployeeB implements IEmployee {@Overridepublic void doing(String command) {System.out.println("我是员工 B,我现在开始干" + command + "工作");}
}
创建项目经理Leader类
public class Leader implements IEmployee {private Map<String,IEmployee> targets = new HashMap<String,IEmployee>();public Leader() {targets.put("加密",new EmployeeA());targets.put("登录",new EmployeeB());}
//项目经理自己不干活public void doing(String command){targets.get(command).doing(command);}
}
Boss类中下达命令
public class Boss {public void command(String command,Leader leader){leader.doing(command);}
}
测试代码
public class DelegateTest {
public static void main(String[] args) {//客户请求(Boss)、委派者(Leader)、被被委派者(Target) //委派者要持有被委派者的引用//代理模式注重的是过程, 委派模式注重的是结果 //策略模式注重是可扩展(外部扩展),委派模式注重内部的灵活和复用 //委派的核心:就是分发、调度、派遣//委派模式:就是静态代理和策略模式一种特殊的组合new Boss().command("登录",new Leader()); }
}
6.2 源码体现
Spring 中的DispatcherServlet
7. 策略模式
7.1 详解
策略模式是指定义了算法家族,分别封装起来,让他们之间互相替换,此模式让算法的变化不会影响到使用算法的用户。
应用场景
- 假如系统中有很多类,而他们的区别仅仅在于行为不同
- 一个系统中需要动态的在几种算法中选择一种
用策略模式实现选择支付方式的业务场景
商场常常有优惠活动,优惠策略可能有很多种,例如领取优惠卷抵扣,反现促销,拼团优惠。创建一个促销策略的的抽象类PromotionStrategy
public interface PromotionStrategy { void doPromotion();
}
然后创建优惠卷抵扣策略CouponStrategy类,反现促销策略CashbackStrategy类,拼团优惠策略GroupbuyStrategy类和无优惠策略EmptyStrategy类:
public class CouponStrategy implements PromotionStrategy {public void doPromotion() {System.out.println("领取优惠券,课程的价格直接减优惠券面值抵扣"); }
}public class CashbackStrategy implements PromotionStrategy {public void doPromotion() {System.out.println("返现促销,返回的金额转到支付宝账号"); }
}public class GroupbuyStrategy implements PromotionStrategy{ public void doPromotion() {System.out.println("拼团,满 20 人成团,全团享受团购价"); }
}创建促销活动类PromotionActivity
public class EmptyStrategy implements PromotionStrategy { public void doPromotion() {System.out.println("无促销活动"); }
}public class PromotionActivity {private PromotionStrategy promotionStrategy;public PromotionActivity(PromotionStrategy promotionStrategy) { this.promotionStrategy = promotionStrategy;}public void execute(){promotionStrategy.doPromotion();}
}
编写客户端测试类
public static void main(String[] args) {PromotionActivity activity618 = new PromotionActivity(new CouponStrategy()); PromotionActivity activity1111 = new PromotionActivity(new CashbackStrategy());activity618.execute();activity1111.execute();
}
通常会选择一种优惠策略,因此上述代码不实用
public static void main(String[] args) { PromotionActivity promotionActivity = null;String promotionKey = "COUPON";if(StringUtils.equals(promotionKey,"COUPON")){promotionActivity = new PromotionActivity(new CouponStrategy());}else if(StringUtils.equals(promotionKey,"CASHBACK")){ promotionActivity = new PromotionActivity(new CashbackStrategy());
}//......
promotionActivity.execute(); }
这样当有很多策略的时候会积累大量的if else,使用单例模式和工厂模式进行优化
public class PromotionStrategyFactory {private static Map<String,PromotionStrategy> PROMOTION_STRATEGY_MAP = new HashMap<String,PromotionStrategy>();static {PROMOTION_STRATEGY_MAP.put(PromotionKey.COUPON,new CouponStrategy()); PROMOTION_STRATEGY_MAP.put(PromotionKey.CASHBACK,new CashbackStrategy());PROMOTION_STRATEGY_MAP.put(PromotionKey.GROUPBUY,new GroupbuyStrategy());}private static final PromotionStrategy NON_PROMOTION = new EmptyStrategy();private PromotionStrategyFactory(){}public static PromotionStrategy getPromotionStrategy(String promotionKey){ PromotionStrategy promotionStrategy = PROMOTION_STRATEGY_MAP.get(promotionKey); return promotionStrategy == null ? NON_PROMOTION : promotionStrategy;}private interface PromotionKey{ String COUPON = "COUPON"; String CASHBACK = "CASHBACK"; String GROUPBUY = "GROUPBUY";}
}
7.2 源码中的体现
- 比较器的Comparator接口,Comparator有很多实现类,经常会把Comparator作为参数传入作为排序策略
7.3 策略模式优缺点
优点:
- 策略模式符合开闭原则。
- 避免使用多重条件转移语句,如 if…else…语句、switch 语句
- 使用策略模式可以提高算法的保密性和安全性。
缺点:
- 客户端必须知道所有的策略,并且自行决定使用哪一个策略类。
- 代码中会产生非常多策略类,增加维护难度。
8. 模版模式
8.1 模版模式应用
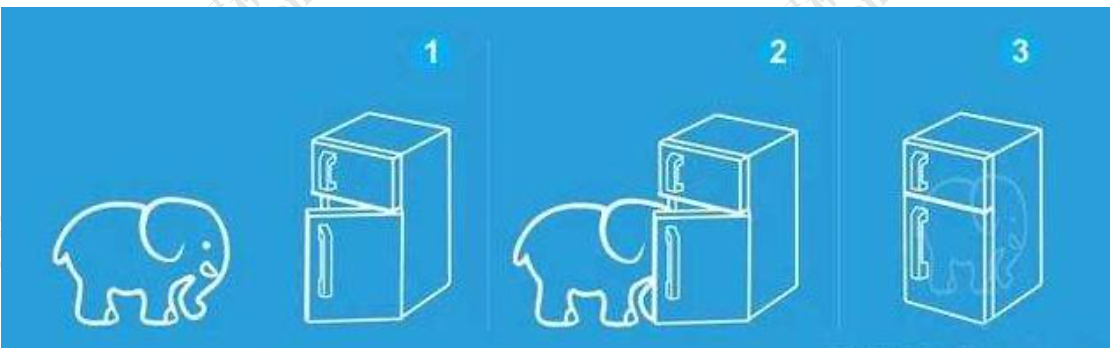
我们平时办理入职流程填写入职登记表–>打印简历–>复印学历–>复印身份证–>签订 劳动合同–>建立花名册–>办理工牌–>安排工位等;再比如,我平时在家里炒菜:洗锅 -->点火–>热锅–>上油–>下原料–>翻炒–>放调料–>出锅;再比如赵本山问宋丹丹: “如何把大象放进冰箱?”宋丹丹回答:“第一步:打开冰箱门,第二步:把大象塞进 冰箱,第三步:关闭冰箱门”。赵本山再问:“怎么把长劲鹿放进冰箱?”宋丹丹答: “第一步:打开冰箱门,第二步:把大象拿出来,第三步:把长劲鹿塞进去,第四步: 关闭冰箱门”(如下图所示),这些都是模板模式的体现。
模板模式通常又叫模板方法模式(Template Method Pattern)是指定义一个算法的骨 架,并允许子类为一个或者多个步骤提供实现。模板方法使得子类可以在不改变算法结 构的情况下,重新定义算法的某些步骤,属于行为性设计模式。模板方法适用于以下应 用场景:
1、一次性实现一个算法的不变的部分,并将可变的行为留给子类来实现。 2、各子类中公共的行为被提取出来并集中到一个公共的父类中,从而避免代码重复。 我们还是以咕泡学院的课程创建流程为例:发布预习资料–>制作课件 PPT–>在线直播 -->提交课堂笔记–>提交源码–>布置作业–>检查作业。首先我们来创建NetworkCourse抽象类
public abstract class NetworkCourse {protected final void createCourse(){ //1、发布预习资料 this.postPreResource();//2、制作 PPT 课件 this.createPPT();//3、在线直播 this.liveVideo();//4、提交课件、课堂笔记 this.postNote();//5、提交源码 this.postSource();//6、布置作业,有些课是没有作业,有些课是有作业的 //如果有作业的话,检查作业,如果没作业,完成了 if(needHomework()){checkHomework();}abstract void checkHomework();//钩子方法:实现流程的微调protected boolean needHomework(){return false;}final void postSource(){ System.out.println("提交源代码");}final void postNote(){System.out.println("提交课件和笔记");}final void liveVideo(){ System.out.println("直播授课");}final void createPPT(){ System.out.println("创建备课 PPT");}final void postPreResource(){System.out.println("分发预习资料");}}
}
钩子方法的主要目的是用来干预执行流程,使得我们控制行为流程更加灵活,更符合实际业 务的需求。钩子方法的返回值一般为适合条件分支语句的返回值(如 boolean、int 等)。 小伙伴们可以根据自己的业务场景来决定是否需要使用钩子方法。接下来创建 JavaCourse 类:
public class JavaCourse extends NetworkCourse {void checkHomework() {System.out.println("检查 Java 的架构课件"); }
}
创建BigDataCourse类
public class BigDataCourse extends NetworkCourse {private boolean needHomeworkFlag = false;public BigDataCourse(boolean needHomeworkFlag) { this.needHomeworkFlag = needHomeworkFlag;}void checkHomework() { System.out.println("检查大数据的课后作业");}@Overrideprotected boolean needHomework() {return this.needHomeworkFlag;}
}
测试代码
public class NetworkCourseTest {public static void main(String[] args) {System.out.println("---Java 架构师课程---"); NetworkCourse javaCourse = new JavaCourse(); javaCourse.createCourse();System.out.println("---大数据课程---");NetworkCourse bigDataCourse = new BigDataCourse(true); bigDataCourse.createCourse();}
}
8.2 模版模式优缺点
优点:
- 利用模板方法将相同处理逻辑的代码放到抽象父类中,可以提高代码的复用性。
- 将不同的代码不同的子类中,通过对子类的扩展增加新的行为,提高代码的扩展性。
- 把不变的行为写在父类上,去除子类的重复代码,提供了一个很好的代码复用平台, 符合开闭原则。
**缺点: **
- 类数目的增加,每一个抽象类都需要一个子类来实现,这样导致类的个数增加。
- 类数量的增加,间接地增加了系统实现的复杂度。
- 继承关系自身缺点,如果父类添加新的抽象方法,所有子类都要改一遍。
9. 适配器模式
9.1 适配器模式应用场景
适配器模式(Adapter Pattern)是指将一个类的接口转换成客户期望的另一个接口,使 原本的接口不兼容的类可以一起工作,属于结构型设计模式。 适配器适用于以下几种业务场景:
- 已经存在的类,它的方法和需求不匹配(方法结果相同或相似)的情况。
- 适配器模式不是软件设计阶段考虑的设计模式,是随着软件维护,由于不同产品、不 同厂家造成功能类似而接口不相同情况下的解决方案。有点亡羊补牢的感觉。 生活中也非常的应用场景,例如电源插转换头、手机充电转换头、显示器转接头。
创建AC220表示220V交流电
public class AC220 {public int outputAC220V(){int output = 220; System.out.println("输出交流电"+output+"V"); return output;}
}
转换成5V交流电
public interface DC5 { int outputDC5V();
}public class PowerAdapter implements DC5{ private AC220 ac220;public PowerAdapter(AC220 ac220){this.ac220 = ac220; }public int outputDC5V() {int adapterInput = ac220.outputAC220V();//变压器...int adapterOutput = adapterInput/44;System.out.println("使用 PowerAdapter 输入 AC:"+adapterInput+"V"+"输出DC:"+adapterOutput+"V"); return adapterOutput;}
}//客户端测试代码public class ObjectAdapterTest {public static void main(String[] args) {DC5 dc5 = new PowerAdapter(new AC220());dc5.outputDC5V(); }
}
9.2 适配器模式的优缺点
优点:
1、能提高类的透明性和复用,现有的类复用但不需要改变。
2、目标类和适配器类解耦,提高程序的扩展性。
3、在很多业务场景中符合开闭原则。
缺点:
1、适配器编写过程需要全面考虑,可能会增加系统的复杂性。 2、增加代码阅读难度,降低代码可读性,过多使用适配器会使系统代码变得凌乱。
10 装饰者模式
10.1 原理
装饰者模式(Decorator Pattern)是指在不改变原有对象的基础之上,将功能附加到对 象上,提供了比继承更有弹性的替代方案(扩展原有对象的功能),属于结构型模式。 装饰者模式在我们生活中应用也比较多如给煎饼加鸡蛋;给蛋糕加上一些水果;给房子 装修等,为对象扩展一些额外的职责。装饰者在代码程序中适用于以下场景:
1、用于扩展一个类的功能或给一个类添加附加职责。
2、动态的给一个对象添加功能,这些功能可以再动态的撤销。
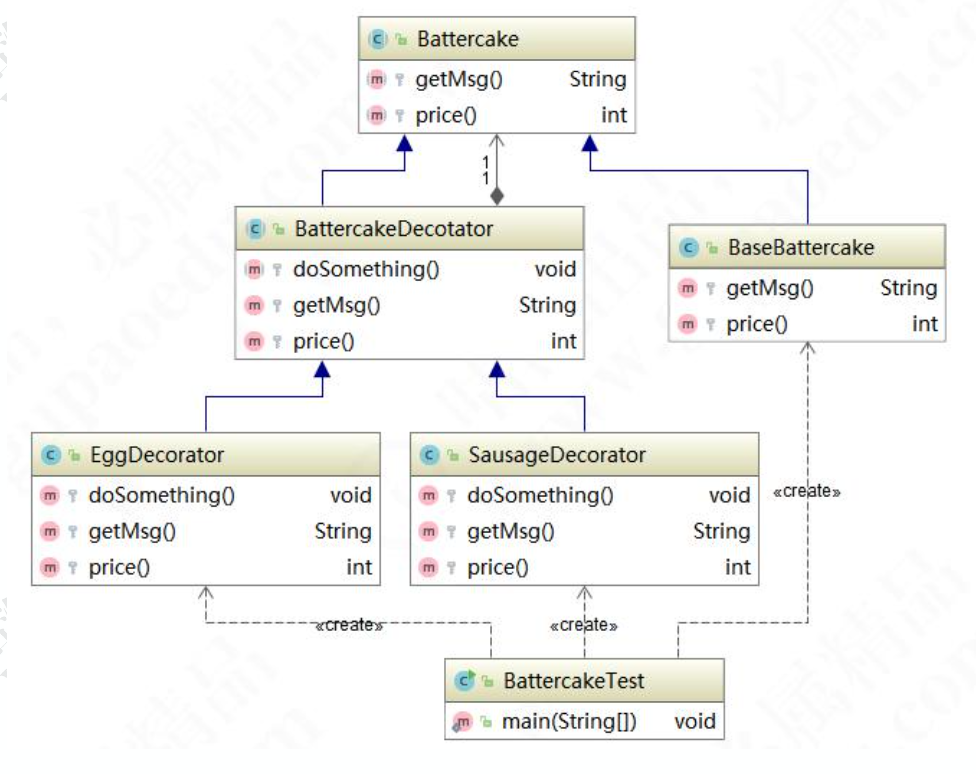
举个鸡蛋饼的例子,首先创建一个煎饼抽象类Battercake
public class abstract Battercake {protected abstract String getMsg();public abstract int getPrice();
}
创建基本的煎饼BaseBattercake
public class BaseBattercake extends Battercake { protected String getMsg(){return "煎饼";}public int getPrice(){ return 5;}
}
在创建一个套餐扩展抽象装饰者BattercakeDecotator类
public abstract class BattercakeDecorator extends Battercake { //静态代理,委派private Battercake battercake;public BattercakeDecorator(Battercake battercake) {this.battercake = battercake;}protected abstract void doSomething();@Overrideprotected String getMsg() {return this.battercake.getMsg();}@Overrideprotected int getPrice() {return this.battercake.getPrice();}
}
创建鸡蛋装饰类
public class EggDecorator extends BattercakeDecorator { public EggDecorator(Battercake battercake) {super(battercake);}protected void doSomething() {}@Overrideprotected String getMsg() {return super.getMsg() + "+1 个鸡蛋";}@Overrideprotected int getPrice() { return super.getPrice() + 1;}
}
创建香肠装饰者SausageDecorator
public class SausageDecorator extends BattercakeDecorator { public SausageDecorator(Battercake battercake) {super(battercake);}protected void doSomething() {}@Overrideprotected String getMsg() {return super.getMsg() + "+1 根香肠";}@Overrideprotected int getPrice() { return super.getPrice() + 2;}
}
创建测试类
public class BattercakeTest {public static void main(String[] args) {Battercake battercake;//路边摊买一个煎饼battercake = new BaseBattercake(); //煎饼有点小,想再加一个鸡蛋battercake = new EggDecorator(battercake); //再加一个鸡蛋battercake = new EggDecorator(battercake); //很饿,再加根香肠battercake = new SausageDecorator(battercake);//跟静态代理最大区别就是职责不同 //静态代理不一定要满足 is-a 的关系//静态代理会做功能增强,同一个职责变得不一样//装饰器更多考虑是扩展System.out.println(battercake.getMsg() + ",总价:" + battercake.getPrice()); }
}
10.2 优缺点
优点:
- 装饰者是继承的有力补充,比继承灵活,不改变原有对象的情况下动态地给一个对象 扩展功能,即插即用。
- 通过使用不同装饰类以及这些装饰类的排列组合,可以实现不同效果。
- 装饰者完全遵守开闭原则。
缺点:
- 会出现更多的代码,更多的类,增加程序复杂性。
- 动态装饰时,多层装饰时会更复杂。
11.桥接模式
理解桥接模式,重点需要理解如何将抽象化(Abstraction)与实现化(Implementation)脱耦,使得二者可以独立地变化。
• 抽象化:抽象化就是忽略一些信息,把不同的实体当作同样的实体对待。在面向对象中,将对象的共同性质抽取出来形成类的过程即为抽象化的过程。
• 实现化:针对抽象化给出的具体实现,就是实现化,抽象化与实现化是一对互逆的概念,实现化产生的对象比抽象化更具体,是对抽象化事物的进一步具体化的产物。
• 脱耦:脱耦就是将抽象化和实现化之间的耦合解脱开,或者说是将它们之间的强关联改换成弱关联,将两个角色之间的继承关系改为关联关系。桥接模式中的所谓脱耦,就是指在一个软件系统的抽象化和实现化之间使用关联关系(组合或者聚合关系)而不是继承关系,从而使两者可以相对独立地变化,这就是桥接模式的用意。
实例1:模拟毛笔
现需要提供大中小3种型号的画笔,能够绘制5种不同颜色,如果使用蜡笔,我们需要准备3*5=15支蜡笔,也就是说必须准备15个具体的蜡笔类。而如果使用毛笔的话,只需要3种型号的毛笔,外加5个颜料盒,用3+5=8个类就可以实现15支蜡笔的功能。本实例使用桥接模式来模拟毛笔的使用过程。
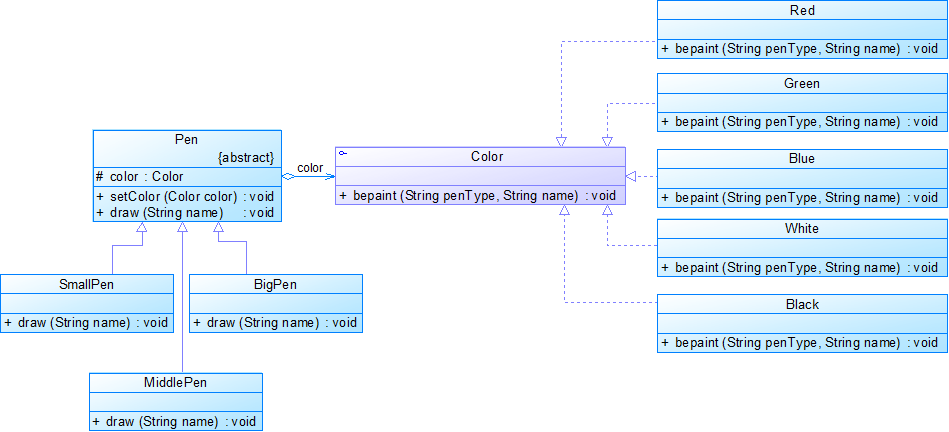
//抽象类
public abstract class Pen
{protected Color color;public void setColor(Color color){this.color=color;}public abstract void draw(String name);
}//扩充抽象类
public class SmallPen extends Pen
{public void draw(String name){String penType="小号毛笔绘制";this.color.bepaint(penType,name);}
}//扩充抽象类
public class MiddlePen extends Pen
{public void draw(String name){String penType="中号毛笔绘制";this.color.bepaint(penType,name);}
}//扩充抽象类
public class BigPen extends Pen
{public void draw(String name){String penType="大号毛笔绘制";this.color.bepaint(penType,name);}
}//实现类接口
public interface Color
{void bepaint(String penType,String name);
}//扩充实现类
public class Red implements Color
{public void bepaint(String penType,String name){System.out.println(penType + "红色的"+ name + ".");}
}//扩充实现类
public class Green implements Color
{public void bepaint(String penType,String name){System.out.println(penType + "绿色的"+ name + ".");}
}//扩充实现类
public class Blue implements Color
{public void bepaint(String penType,String name){System.out.println(penType + "蓝色的"+ name + ".");}
}//扩充实现类
public class White implements Color
{public void bepaint(String penType,String name){System.out.println(penType + "白色的"+ name + ".");}
}//扩充实现类
public class Black implements Color
{public void bepaint(String penType,String name){System.out.println(penType + "黑色的"+ name + ".");}
}//配置文件configPen.xml
<?xml version="1.0"?>
<config><className>Blue</className><className>SmallPen</className>
</config>//使用java反射创建具体的颜色和画笔
import javax.xml.parsers.*;
import org.w3c.dom.*;
import org.xml.sax.SAXException;
import java.io.*;
public class XMLUtilPen
{
//该方法用于从XML配置文件中提取具体类类名,并返回一个实例对象public static Object getBean(String args){try{//创建文档对象DocumentBuilderFactory dFactory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = dFactory.newDocumentBuilder();Document doc;doc = builder.parse(new File("configPen.xml"));NodeList nl=null;Node classNode=null;String cName=null;nl = doc.getElementsByTagName("className");if(args.equals("color")){//获取包含类名的文本节点classNode=nl.item(0).getFirstChild();}else if(args.equals("pen")){//获取包含类名的文本节点classNode=nl.item(1).getFirstChild();}cName=classNode.getNodeValue();//通过类名生成实例对象并将其返回Class c=Class.forName(cName);Object obj=c.newInstance();return obj;}catch(Exception e){e.printStackTrace();return null;}}
}//客户端
public class Client
{public static void main(String a[]){Color color;Pen pen;color=(Color)XMLUtilPen.getBean("color");pen=(Pen)XMLUtilPen.getBean("pen");pen.setColor(color);pen.draw("鲜花");}
}
实例2:跨平台视频播放器
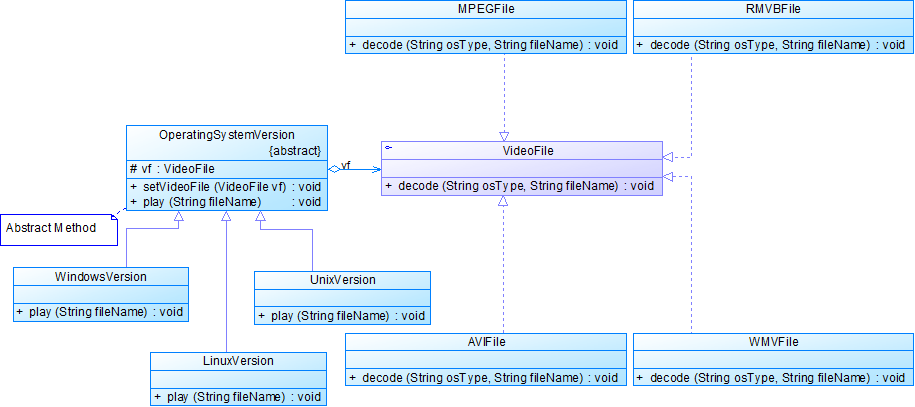
• 如果需要开发一个跨平台视频播放器,可以在不同操作系统平台(如Windows、Linux、Unix等)上播放多种格式的视频文件,常见的视频格式包括MPEG、RMVB、AVI、WMV等。现使用桥接模式设计该播放器。
模式优缺点
优点
• 分离抽象接口及其实现部分。
• 桥接模式有时类似于多继承方案,但是多继承方案违背了类的单一职责原则(即一个类只有一个变化的原因),复用性比较差,而且多继承结构中类的个数非常庞大,桥接模式是比多继承方案更好的解决方法。
• 桥接模式提高了系统的可扩充性,在两个变化维度中任意扩展一个维度,都不需要修改原有系统。
• 实现细节对客户透明,可以对用户隐藏实现细节。
缺点
• 桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计与编程。
• 桥接模式要求正确识别出系统中两个独立变化的维度,因此其使用范围具有一定的局限性。