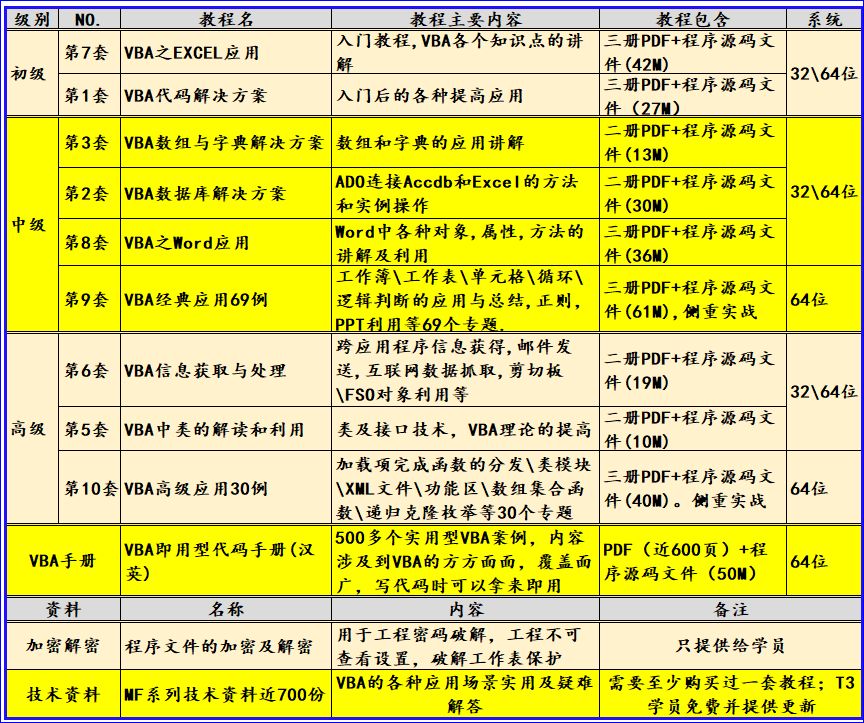
流编程思想
程序可以看作流,任何程序执行的过程都可以看成是流动的过程。基于这个思想,我们可以将程序划分为数据流与控制流。
数据流是数据实现的过程,对于相同的任务需求,最终数据流都会流向相同的地方,笔者进行举例,以数组操作为例:

为了更方便抽象出流的概念,笔者决定将其转化为汇编,这样操作尺度更小,更容易观察程序流。
数组每个成员加一既是结果,也是过程的必然,但是考虑一下两种情况:
f2就是常量1,x1就是数组地址起始处。
第一种

耗费的时钟周期计算:(1+2)*4 + 12个指令 = 24个时钟周期
第二种

耗费的时钟周期计算:0 + 12个指令 = 12个时钟周期。
从上面可以看出,两种情况的数据移动操作流向是相同的,但是第二种操作明显优于第一种,它的并行性明显更好,可读性也更好。
数据流,就是固定的三个指令,完成加载、相加、存储的这三个指令,所以说从流向来看,数据流是固定的。虽然可能使用的寄存器不同,但过程是相同的,它一定会流向固定的过程和结果。
控制流就是控制指令执行顺序,可以看出,第二种明显优于第一种,这就是控制流调度的结果。
结论
从以上可以看出,两种方法的数据流都是相同的,因为它们流向的结果是一致的。如果不考虑可读性等因素,只考虑性能,对于所有完成相同任务的程序员来说,他们的水平差距其实只体现在控制流。
综上,程序流可以被划分为数据流和控制流。数据流的流向相同,因此数据流的优化方向是将其划分为更小的尺度,程序的架构可以被划分为无数个更细的数据流的组合。
控制流的优化方向是调度数据流,它决定了程序执行的顺序,不同的数据流顺序对程序的性能影响天差地别。
分离控制流与数据流
下面笔者以c语言为例,讲解如何分离控制流与数据流,
原程序:

现在的这种形式经常被我们采用,但是大量的if循环很明显没有完成对控制流和数据流的分离,再看看这个程序:

消除了大量的if判断,并且使得控制部分更加简洁明了,程序的解耦合性和可扩展性明显更好。
流编程的思想就像笔者所说的那样,分离控制流与数据流,对数据流不断进行分割,对控制流的策略不断进行优化,使程序具备更好的性能和可维护性。根据笔者的认知,可能流编程更适合微架构和高并发的场景,例如微内核。在这里,程序的复杂性和策略性大大提高,这是对控制流的要求,程序执行的尺度需要不断细化从而提高资源利用率和性能,这又是对数据流的要求。
以上就是是笔者的随笔,just for fun,写着玩的,切莫当真。