我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
第一课: 如何在 PyTorch 中 profile CUDA kernels
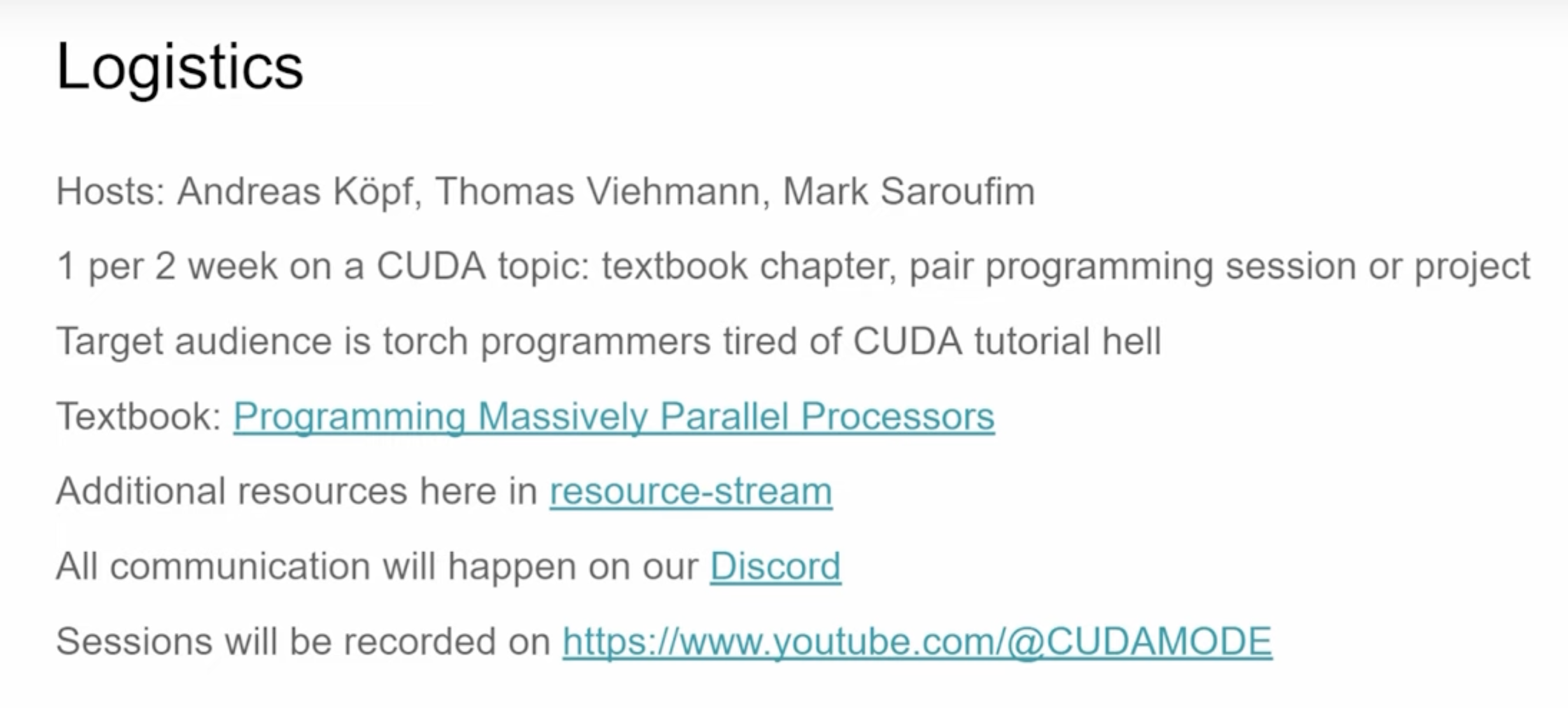
这里是课程规划,有三位讲师 Andreas, Thomas, Mark,然后大概2周出一个 CUDA 主题的讲解以及工程或者结对编程的视频。课程讨论的主题是根据 《Programming Massively Parallel Processors》这本书来的,Mark 也是在8分钟的时候强推了这本书。另外在6分钟左右 Mark 指出,学习 CUDA 的困难之处在于对于新手来说,可能会陷入不断循环查找文档的状态,非常痛苦。

这里是说Lecture 1的目标是如何把一个 CUDA kernel 嵌入到 PyTorch 里面,以及如何对它进行 Profile 。相关的代码都在:https://github.com/cuda-mode/lectures/tree/main/lecture_001 。Mark 还提到说这个课程相比于以前的纯教程更加关注的是我们可以利用 CUDA 做什么事情,而不是让读者陷入到 CUDA 专业术语的细节中,那会非常痛苦。

这一页 Slides 中的代码在 https://github.com/cuda-mode/lectures/blob/main/lecture_001/pytorch_square.py
import torcha = torch.tensor([1., 2., 3.])print(torch.square(a))
print(a ** 2)
print(a * a)def time_pytorch_function(func, input):# CUDA IS ASYNC so can't use python time module# CUDA是异步的,所以你不能使用python的时间模块,而应该使用CUDA Eventstart = torch.cuda.Event(enable_timing=True)end = torch.cuda.Event(enable_timing=True)# Warmup (防止CUDA Context初始化影响时间记录的准确性)for _ in range(5):func(input)start.record()func(input)end.record()# 程序完成之后需要做一次 CUDA 同步torch.cuda.synchronize()return start.elapsed_time(end)b = torch.randn(10000, 10000).cuda()def square_2(a):return a * adef square_3(a):return a ** 2time_pytorch_function(torch.square, b)
time_pytorch_function(square_2, b)
time_pytorch_function(square_3, b)print("=============")
print("Profiling torch.square")
print("=============")# Now profile each function using pytorch profiler
with torch.autograd.profiler.profile(use_cuda=True) as prof:torch.square(b)print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))print("=============")
print("Profiling a * a")
print("=============")with torch.autograd.profiler.profile(use_cuda=True) as prof:square_2(b)print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))print("=============")
print("Profiling a ** 2")
print("=============")with torch.autograd.profiler.profile(use_cuda=True) as prof:square_3(b)print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
这里通过在 PyTorch 中实现平方和立方函数并使用 autograd profiler 工具进行 profile 。time_pytorch_function 这个函数的计时功能和 torch.autograd.profiler.profile 类似,第三页 Slides 里面我们可以通过 PyTorch Profiler 的结果看到当前被 torch.autograd.profiler.profile context manager 包起来的 PyTorch 程序 cuda kernel 在 cpu, cuda 上的执行时间以及占比以及 kernel 的调用次数,当前 kernel 的执行时间占总时间的比例。

这一页Slides是对 https://github.com/cuda-mode/lectures/blob/main/lecture_001/pt_profiler.py 这个文件进行讲解,之前我也翻译过PyTorch Profiler TensorBoard 插件教程,地址在 https://zhuanlan.zhihu.com/p/692749819
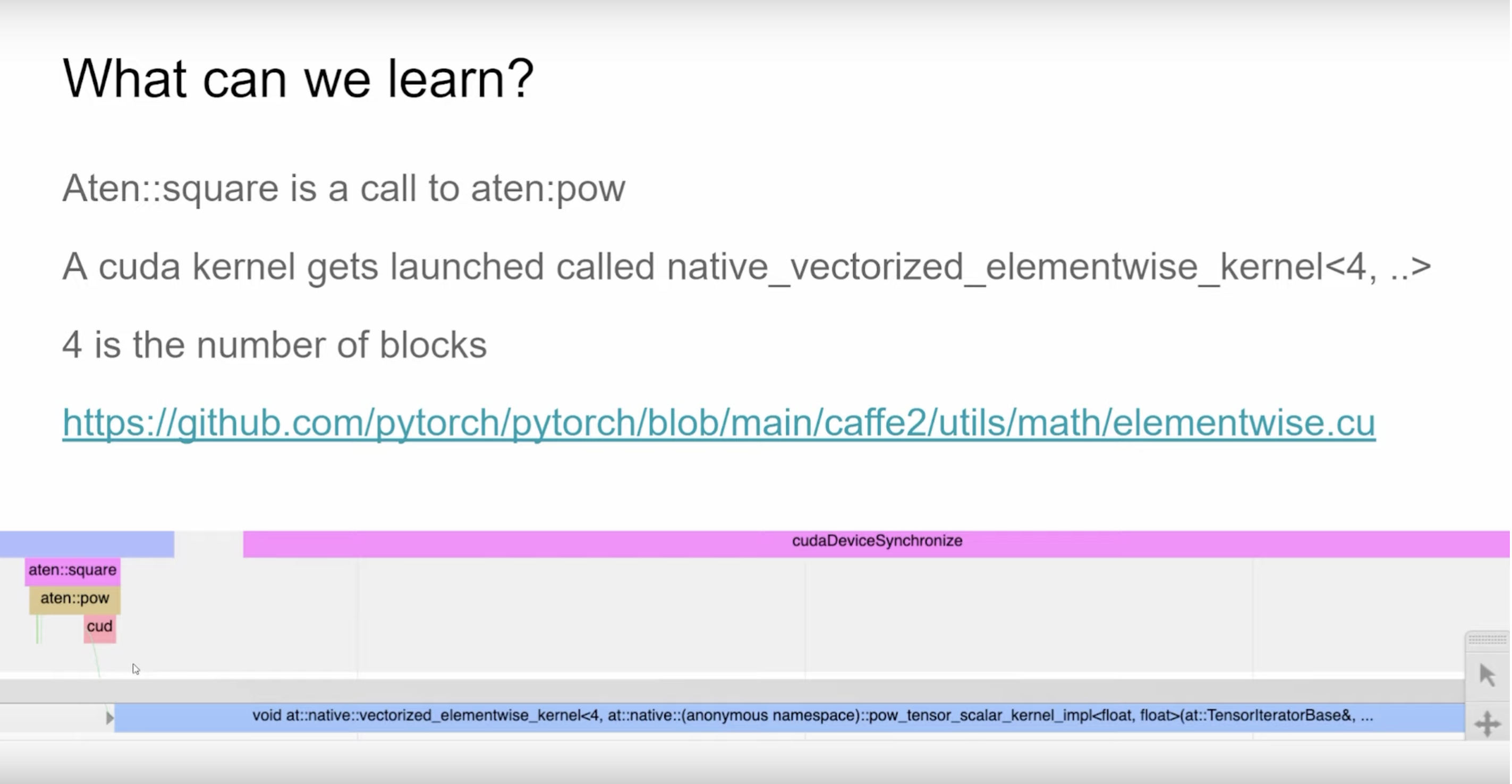
可以看到aten::square实际上是调用的aten::pow,然后aten::pow下方的cud指的是cuda kernel dispatch也就是启动CUDA kernel,我们还可以看到这个CUDA kernel的名字是naive_vectorized_elementwise_kernel<4, ..>,其中4表示Block的数量。但是这里的问题是,我们只能看到kernel的名称,无法知道它运行得多快。然后up主推荐去了解和学习PyTorch的.cu实现,这些实现是一个很好的工具。

PyTorch的load_inline可以把c/c++源码以函数的方式加载到模块中。接着作则还展示了一下怎么使用load_inline
加载cuda的源代码:https://github.com/cuda-mode/lectures/blob/main/lecture_001/load_inline.py 。
# Look at this test for inspiration
# https://github.com/pytorch/pytorch/blob/main/test/test_cpp_extensions_jit.pyimport torch
from torch.utils.cpp_extension import load_inline# Define the CUDA kernel and C++ wrapper
cuda_source = '''
__global__ void square_matrix_kernel(const float* matrix, float* result, int width, int height) {int row = blockIdx.y * blockDim.y + threadIdx.y;int col = blockIdx.x * blockDim.x + threadIdx.x;if (row < height && col < width) {int idx = row * width + col;result[idx] = matrix[idx] * matrix[idx];}
}torch::Tensor square_matrix(torch::Tensor matrix) {const auto height = matrix.size(0);const auto width = matrix.size(1);auto result = torch::empty_like(matrix);dim3 threads_per_block(16, 16);dim3 number_of_blocks((width + threads_per_block.x - 1) / threads_per_block.x,(height + threads_per_block.y - 1) / threads_per_block.y);square_matrix_kernel<<<number_of_blocks, threads_per_block>>>(matrix.data_ptr<float>(), result.data_ptr<float>(), width, height);return result;}
'''cpp_source = "torch::Tensor square_matrix(torch::Tensor matrix);"# Load the CUDA kernel as a PyTorch extension
square_matrix_extension = load_inline(name='square_matrix_extension',cpp_sources=cpp_source,cuda_sources=cuda_source,functions=['square_matrix'],with_cuda=True,extra_cuda_cflags=["-O2"],build_directory='./load_inline_cuda',# extra_cuda_cflags=['--expt-relaxed-constexpr']
)a = torch.tensor([[1., 2., 3.], [4., 5., 6.]], device='cuda')
print(square_matrix_extension.square_matrix(a))# (cudamode) ubuntu@ip-172-31-9-217:~/cudamode/cudamodelecture1$ python load_inline.py
# tensor([[ 1., 4., 9.],
# [16., 25., 36.]], device='cuda:0')注意到这里的build_directory='./load_inline_cuda', 表示构建过程生成的代码一集编译的中间产物都会保存到 https://github.com/cuda-mode/lectures/tree/main/lecture_001/load_inline_cuda 这个文件夹中。

如果想避免这种编译过程,可以考虑使用Triton,它是一个Python程序。

这个是用Triton写的square kernel,下面展示了 torch.compile, naive torch, Triton 实现的kernel在A10的性能对比:
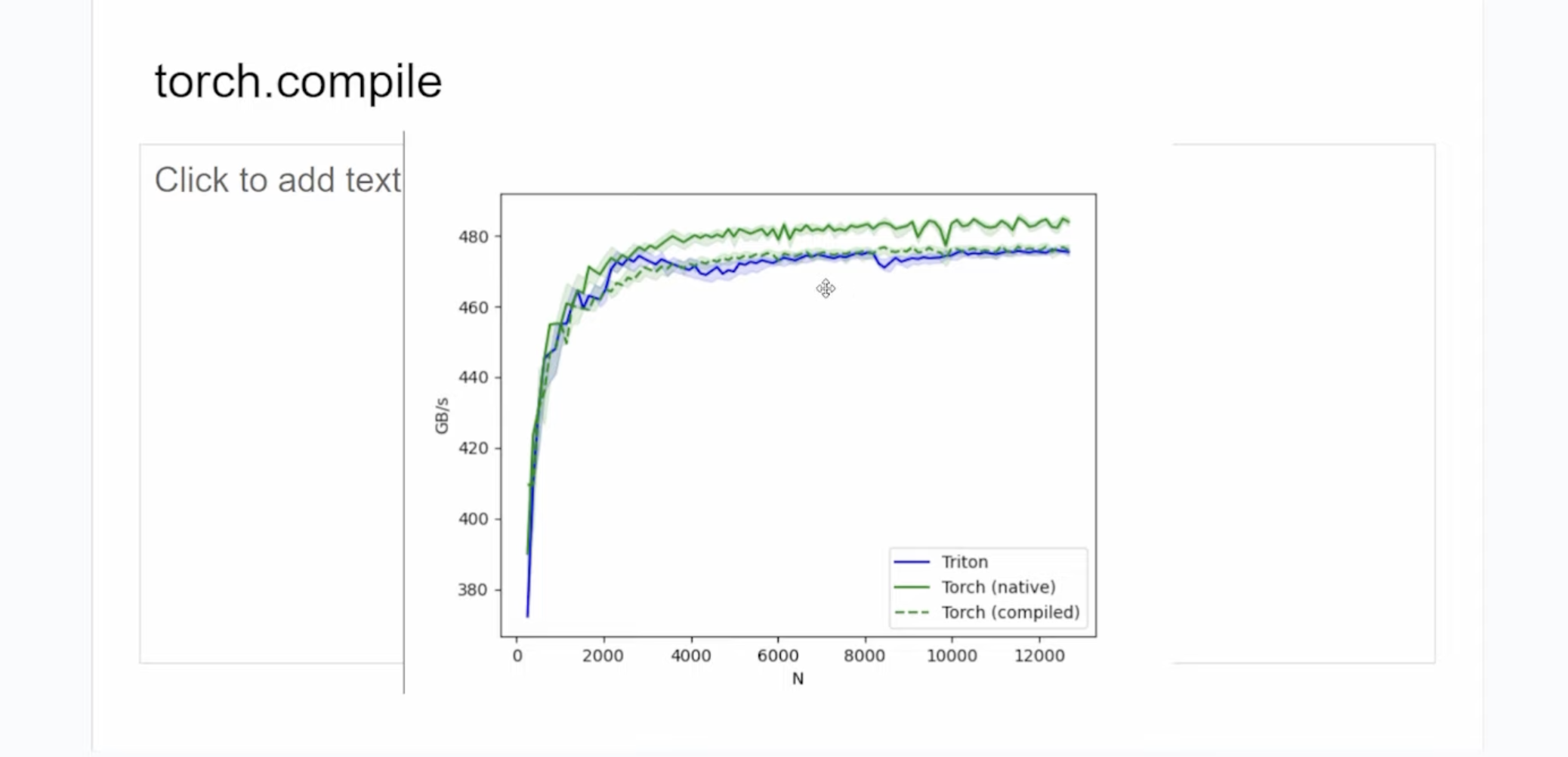
可以看到naive torch的kernel比Triton和torch.compile生产的kernel都更快一点。接着又在4090上做了实验,得到了类似的结果。作者写的kernel在:https://github.com/cuda-mode/lectures/blob/main/lecture_001/triton_square.py

Triton kernel为:
# Adapted straight from https://triton-lang.org/main/getting-started/tutorials/02-fused-softmax.html
import triton
import triton.language as tl
import torch# if @triton.jit(interpret=True) does not work, please use the following two lines to enable interpret mode
# import os
# os.environ["TRITON_INTERPRET"] = "1"@triton.jit
def square_kernel(output_ptr, input_ptr, input_row_stride, output_row_stride, n_cols, BLOCK_SIZE: tl.constexpr):# The rows of the softmax are independent, so we parallelize across thoserow_idx = tl.program_id(0)# The stride represents how much we need to increase the pointer to advance 1 rowrow_start_ptr = input_ptr + row_idx * input_row_stride# The block size is the next power of two greater than n_cols, so we can fit each# row in a single blockcol_offsets = tl.arange(0, BLOCK_SIZE)input_ptrs = row_start_ptr + col_offsets# Load the row into SRAM, using a mask since BLOCK_SIZE may be > than n_colsrow = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf'))square_output = row * row# Write back output to DRAMoutput_row_start_ptr = output_ptr + row_idx * output_row_strideoutput_ptrs = output_row_start_ptr + col_offsetstl.store(output_ptrs, square_output, mask=col_offsets < n_cols)def square(x):n_rows, n_cols = x.shape# The block size is the smallest power of two greater than the number of columns in `x`BLOCK_SIZE = triton.next_power_of_2(n_cols)# Another trick we can use is to ask the compiler to use more threads per row by# increasing the number of warps (`num_warps`) over which each row is distributed.# You will see in the next tutorial how to auto-tune this value in a more natural# way so you don't have to come up with manual heuristics yourself.num_warps = 4if BLOCK_SIZE >= 2048:num_warps = 8if BLOCK_SIZE >= 4096:num_warps = 16# Allocate outputy = torch.empty_like(x)# Enqueue kernel. The 1D launch grid is simple: we have one kernel instance per row o# f the input matrixsquare_kernel[(n_rows, )](y,x,x.stride(0),y.stride(0),n_cols,num_warps=num_warps,BLOCK_SIZE=BLOCK_SIZE,)return y
这个kernel是Triton的fused softmax 教程改过来的,在那个教程里 Triton 的速度比 PyTorch 和 torch.compile 都要快,所以这里的性能表现似乎有点奇怪,因为两者都是element-wise操作。接着作者把上面的BLOCK_SIZE固定为1024,观察到性能有很大提升
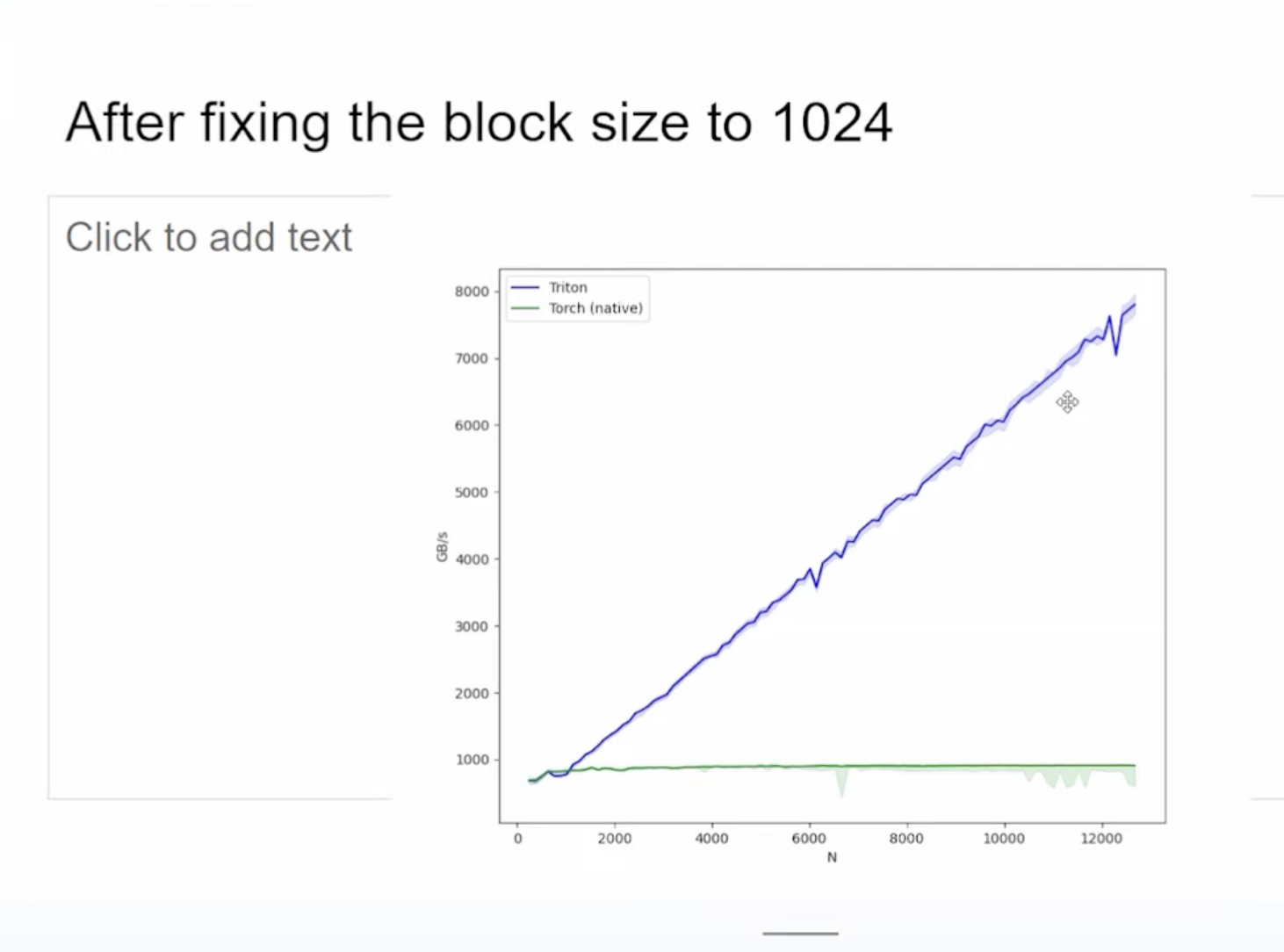
这里如果固定了BLOCK_SIZE,那上面的Kernel也要做对应的修改比如以BLOCK_SIZE的步长来循环加载列方向的数据。
下一页Slides提到Triton现在提供了一个debugger:

开启debugger模式之后你就可以在Triton kernel里的任意一行打断点一行行检查代码,几乎所有的变量都是Tensor,你可以使用var_name.tensor来打印。
这个功能真的非常棒。
接着,up主提到可以观察Triton的PTX来发现一些有效的信息。比如上面的矩阵平方运算的Triton kernel 产生的PTX文件为:https://github.com/cuda-mode/lectures/blob/main/lecture_001/square_kernel.ptx

我们可以看到每次计算 Triton 使用了8个寄存器来对输入做平方运算,另外使用了8个寄存器来存输出。此外,通过查看PTX kernel,你可以看到对global memory和shared memory的直接操作。
你可以把PTX粘贴到ChatGPT,让它为你添加注释。
下面这张Slides提到怎么查看PyTorch的编译器生成的Triton Kernel:

这样甚至你都不需要编写Triton kernel,只编写PyTorch程序就可以了。或者以这个Triton Kernel为起点来修改,优化,学习,等等。
下一页Slides:

up主介绍了一下nsight compute profile工具,例子为:https://github.com/cuda-mode/lectures/blob/main/lecture_001/ncu_logs ,我们可以从 ncu 的profile结果得到一些性能,带宽相关的指标或者一些粗浅的调优建议。
此外,当ncu指定--set full参数后,我们可以从ncu的可视化软件中查看profile结果,就像:

我们可以直观的看到每个kernel的grid_size,block_size,计算吞吐和内存带宽吞吐等指标。另外下方白色字体后面都是根据目前kernel的指标给出的粗浅调优建议,比如这里第一条就是因为活跃wave太低给出的调整grid_size和block_size的建议。第二条是计算的理论occupancy(100.0%)和实测的实际occupancy占用(72.0%)之间的差异可能是由于 kernel 执行期间的warp调度开销或工作负载不平衡导致的。在同一kernel 的不同块之间以及块内的不同 warps 之间都可能发生负载不平衡。 第三条则是需要验证内存访问模式是否最优,是否需要使用Shared memoy。
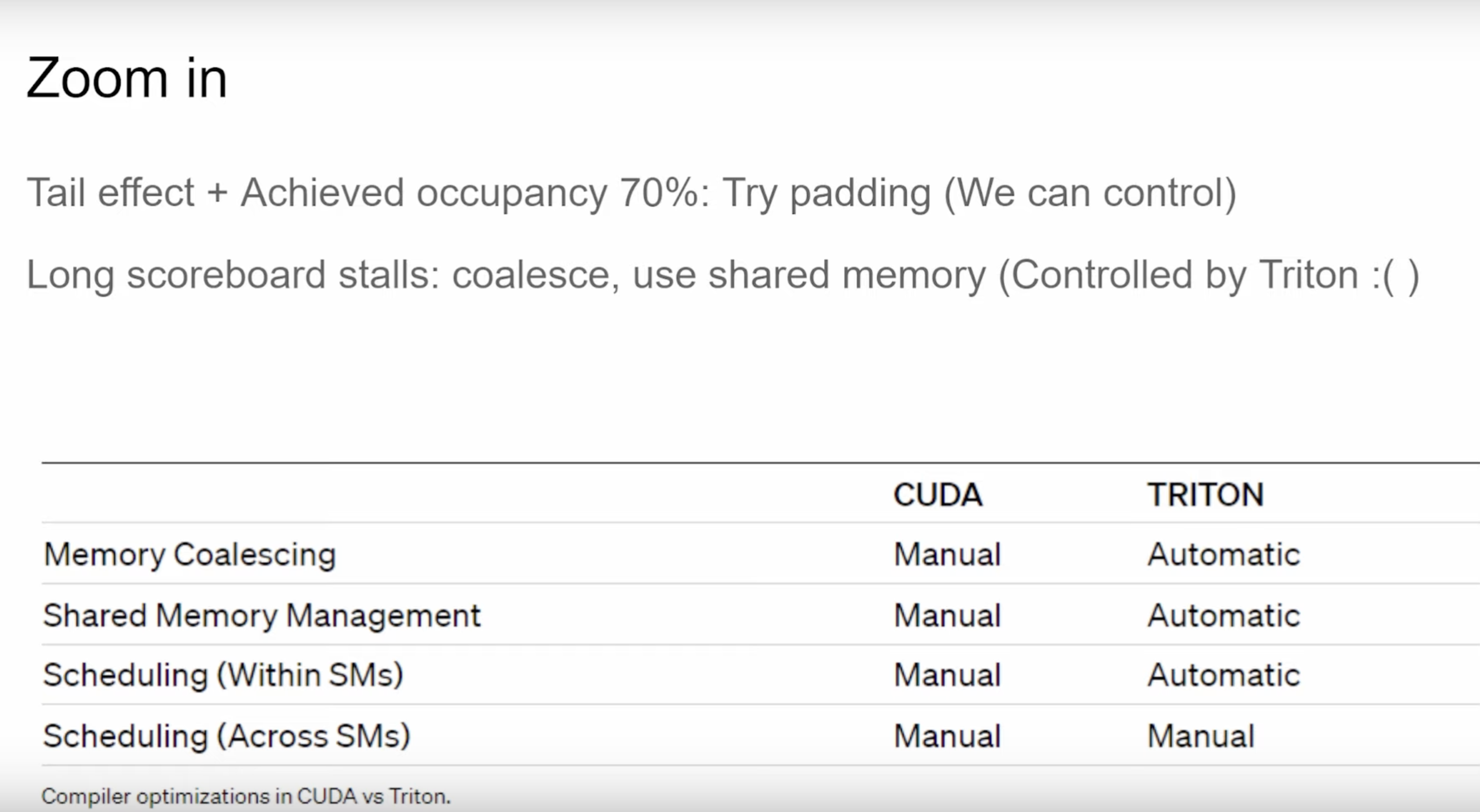
下面一页Slides说的是,我们可以通过ncu profile的结果决定是否要处理一些尾部的需求,比如通过我们可以控制的Padding方式,或者合并内存读写,使用Shared Memory(不过Shared Memory是Triton控制的)来提升kernel性能。这页Slides还展示了使用CUDA和Triton分别可以操作哪些优化,可以看到手写Kernel可以操作任何优化,而Triton只能操作跨SM的调度。
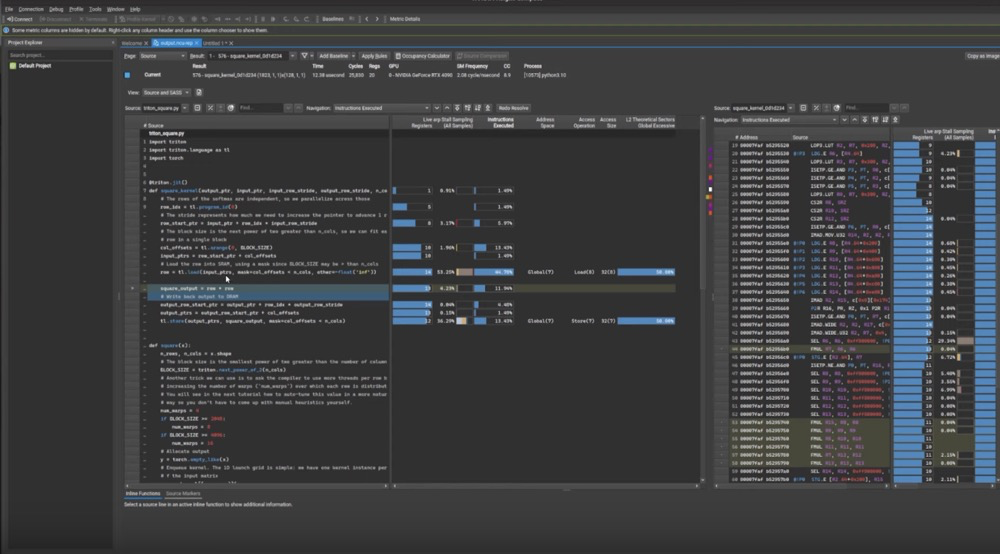
下面一页Slides是Nsight Compute的source pages,它会展示源代码,CUDA PTX代码,代码对应的的寄存器占用情况比如全局内存读取操作。
最后总结一下这节课就是,让PyTorch集成 CUDA kernel 很容易,接着我们应该利用 torch.autograd.profiler 和 Nsight Compute 来做 profile 和性能优化。