点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

杨兆瑞
浙江大学CAD&CG全国重点实验室博士生
导师为陈为教授
概述
大型语言模型(LLMs)的兴起彻底改变了自然语言处理领域,但对它们进行特定任务的微调常常面临在平衡性能和保持一般指令遵循能力方面的挑战。在本文中,我们认为任务数据集与LLMs之间的分布差距是问题的主要根本原因。为解决这一问题,我们引入了自蒸馏微调(Self-Distillation Fine-Tuning,SDFT)方法。它引导模型对任务数据集进行改写,并在蒸馏生成的数据集上进行微调,从而弥合分布差距,并匹配模型的原始分布。我们使用Llama-2-chat模型在各种基准数据集上进行了实验,证明了SDFT能有效减轻灾难性遗忘,且在与普通微调相比时,在下游任务上实现了相当或更佳的性能。此外,SDFT表现出维持LLMs的有用性和安全对齐的潜力。
论文地址:https://arxiv.org/abs/2402.13669
代码地址:https://github.com/sail-sg/sdft
01
The Landscape of LLM Model Fine-tuning
在Hugging Face平台上,每天都有众多微调模型涌现,既有社区爱好者的贡献,也有大型研究机构的成果。例如,搜索基于Llama3的模型,便能找到超过9000个结果。

02
The Challenge of Enhancing Existing Models: Performance
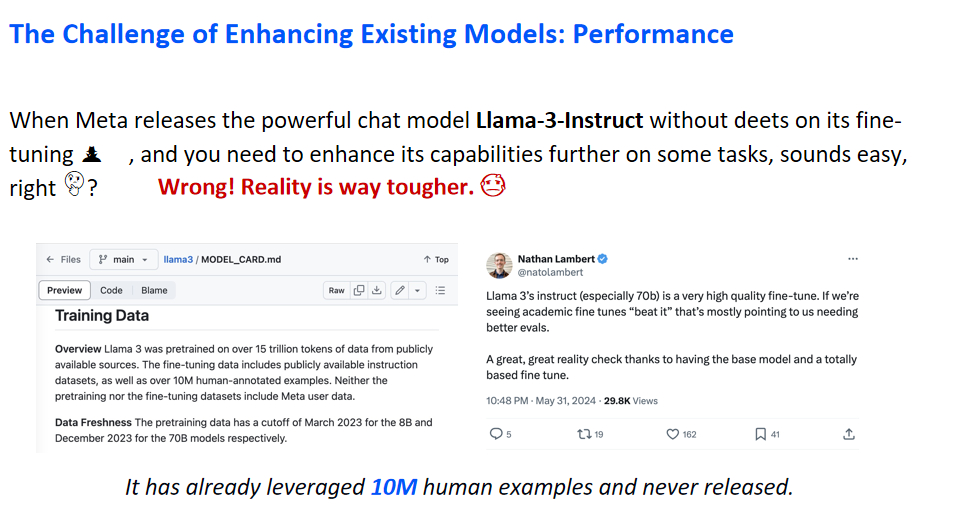
尽管微调模型以提升特定任务性能看似简单,但实际操作却面临挑战。以Meta发布的Llama3为例,其训练数据细节未公开,且模型已使用超过1000万个未公开标注示例。因此,收集模型未见过的私有数据并进行有效微调并非易事。
03
The Challenge of Enhancing Existing Models: Safety
微调大型语言模型可能削弱其安全性。根据ICLR 24的一篇文章,微调后的模型安全性可能大幅降低。尽管模型在通过RLHF对齐后与人类价值观一致,微调仍可能破坏这一安全保障。实验显示,即使是使用良性数据集进行微调,模型的安全性也会降低。

04
The Need for a Better Approach
前面提到了微调面临的两个挑战:性能和安全性。本文探讨是否存在一种更优的方法来进行微调,以便在提升下游任务能力的同时,仍能保持模型原有的安全性能。这涉及到对模型进行定制化与保持其通用性的平衡。

05
The Root Cause of Challenge
本文实验表明,微调的主要挑战在于原始模型数据分布与微调数据分布之间的差异。左图显示了Lama-3-Instruct模型的广泛能力,如代码生成、故事讲述和文本摘要,这些能力与人类价值观对齐,确保了模型的安全性。然而,微调特定任务时,所用数据往往来自狭窄分布,可能影响模型性能。

06
Introducing Self-Distillation Fine-Tuning
基于上述发现,本研究提出了一种新的微调策略,名为自蒸馏微调(Self-Distillation Fine-Tuning,简称SDFT)。该方法旨在对齐任务数据集与语言模型的原始数据集,以减少两者之间的分布差异,同时保留数据集中的监督信息。SDFT通过语言模型对目标标签进行重写,实现新知识与模型原有知识体系的整合。
本文进一步提供了一个示意图,清晰展示了两种微调方法的差异。图的上半部分展示了传统微调(Vanilla Fine-Tuning),即直接在特定数据集上对语言模型进行微调,以增强其在特定任务上的表现。然而,此方法可能导致模型在其他能力上的损失,形成所谓的折衷语言模型。相对而言,图的下半部分介绍了SDFT方法。该方法首先通过蒸馏技术生成精炼数据集,随后在该数据集上执行微调,旨在提升模型在特定任务上的性能,同时避免对原始能力的损害。
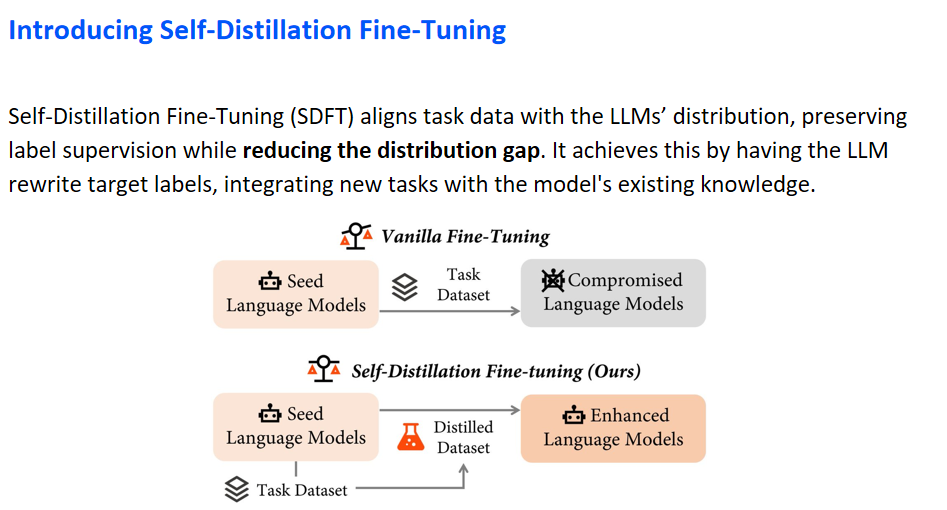
07
Method: Self-Distillation Fine-tuning
本文提出的SDFT方法通过从选定的对话模型开始,如Llama-3-Instruct或Llama-2-Chat,筛选并重写特定下游任务中表现不佳的数据集,生成与原始模型分布对齐的精炼数据集,进而在该数据集上进行微调,以实现在提升新技能的同时保持模型原有能力的目标。示意图展示了将原始数据集分布向模型原始分布的转变过程,从而确保微调后的数据集分布(橙色区域)与模型的初始分布更为接近。

下图中呈现了一个用于知识蒸馏的模板及其应用实例。该模板是在Alpaca模板的基础上经过调整形成的,它包含了原始的指令和响应,旨在引导模型基于这些信息生成创新的响应。演示的右侧部分具体展示了一个示例,其中包含了指令和原始响应,以及模型经过改写得到的蒸馏响应。原始响应仅对问题进行了简要回答,而蒸馏响应则在此基础上进行了扩展,融入了模型自有的知识体系,以提供更全面的答复。

08
Experiments: SDFT vs. Vanilla Fine-tuning
实验阶段,本表格详细对比了传统的Fine-tuning方法与本研究所提出方法的性能差异。
实验主要聚焦于三个具有代表性的下游任务数据集:GSM8K(数学问题集)、HumanEval(代码生成能力评估)以及OpenFunctions(函数调用能力评估)。表格中列出了各模型在经过微调后,在不同数据集上的性能表现。
数据显示,在经过传统微调之后,模型在特定微调数据集上的性能有所增强。例如,原始的语言模型在OpenFunctions数据集上的准确率从19.6提升至34.8。然而,这种提升往往伴随着在其他数据集上性能的下降,如在OpenFunctions数据集上微调后,GSM8K数据集上的准确率从29.4下降至21.5。这一对比凸显了传统微调方法的局限性。相对地,采用本研究提出的自我蒸馏微调方法,观察到了不同的结果,表明该方法可以在维持模型原有能力的同时,有效提升特定任务的性能。
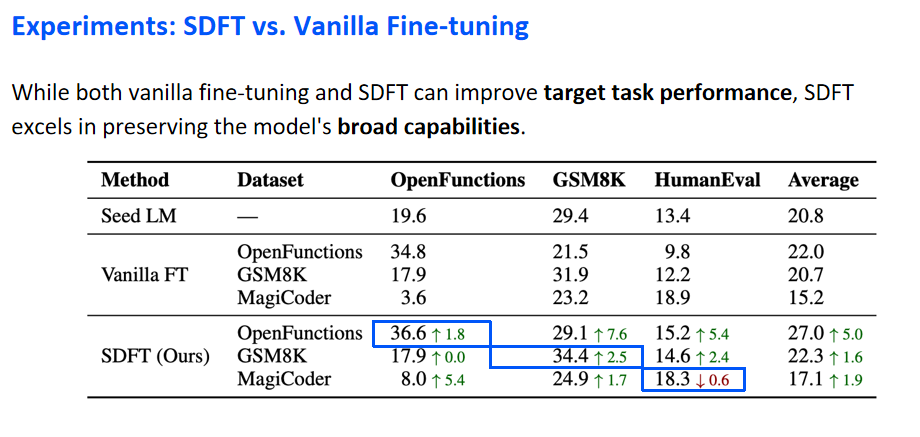
在针对特定任务数据集的微调过程中,本研究所采用的方法不仅在目标数据集上实现了性能提升,其准确率达到了36.6,这一结果与采用传统微调所取得的提升相当或更优,如蓝框所示区域所展示。值得注意的是,在经过本方法的微调后,模型在其他数据集上的性能下降幅度较小。以GSM8K数据集为例,在传统微调后性能下降至21.5,而通过自我蒸馏微调后,性能仅略微下降至29.1。这一现象表明,尽管两种微调方法均能有效提升模型在目标任务上的性能,但本研究所提出的方法在保持模型原有广泛能力方面表现更佳。
本部分深入探讨了模型在安全性和帮助性方面的表现。实验对比了两种微调技术:传统微调与自我蒸馏微调。图表中,左侧展示了传统微调的结果,而右侧则展示了SDFT的效果。实验结果表明,经过传统微调后,模型在安全性和帮助性方面的性能出现了显著下降。相比之下,采用SDFT方法的模型在微调后能够更有效地维持其原有的安全性和帮助性水平,从而在保持性能的同时,也确保了模型的可靠性和实用性。

09
Analysis: Distribution Gap
在本研究的分析阶段,探讨了微调后模型与原始模型之间分布差异的问题。通过对数据集进行模型推理,评估了微调后模型与原始模型在嵌入空间的相似度,以此衡量模型分布的变化。图表中,红色区域代表传统微调后模型与原始模型的嵌入相似度,而绿色区域则显示了采用自我蒸馏微调方法后的嵌入相似度。结果表明,自我蒸馏微调方法处理后的模型在嵌入相似度上具有明显提升,这表明该方法能够有效地减少分布变化,减轻微调过程中的模型遗忘问题。

10
Analysis: Effective across Models
在进一步的分析中,研究旨在验证所提方法在不同模型和规模上的普适性。先前的表格主要关注了Llama-2-7b-chat模型在LoRA微调上的表现。为补充这一分析,本研究扩展了考察范围,包括以下三种不同场景:首先是在Llama-2-7b-chat模型上实施全参数微调,结果表明了显著的性能提升;其次是在Llama-2-13b-chat模型上应用LoRA微调;最后是在最新发布的Llama-3-8B-Instruct模型上执行LoRA微调。实验结果显示,在所有这三种场景中,所提方法相较于传统微调均展现出更优的性能。综合这些发现,可以得出结论,该方法在不同模型尺寸和架构上均表现出良好的效果和适用性。
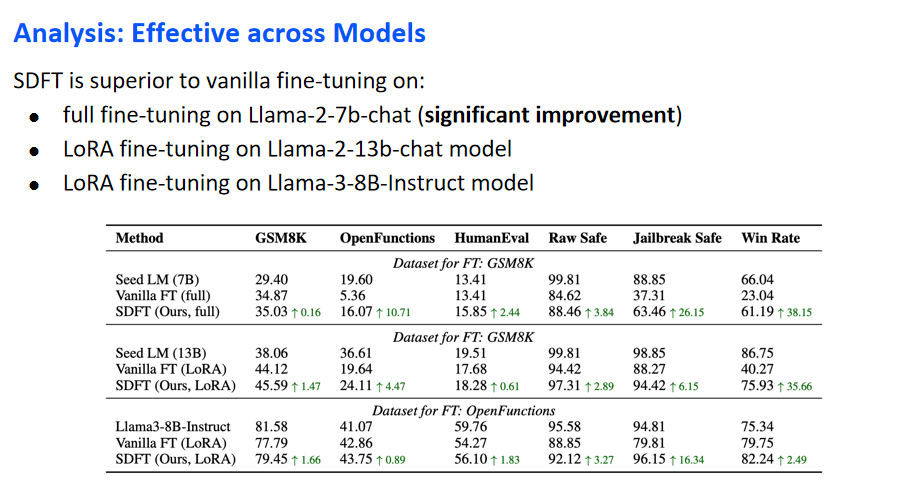
11
Take Away
本研究的核心发现指出,分布偏移是导致微调过程中灾难性遗忘的关键因素。为应对这一挑战,提出的方法采用自蒸馏技术来减少分布差距,有效缓解了遗忘问题。实验结果进一步证实,该方法不仅提升了模型在目标任务上的性能,还成功保留了模型的原始能力。
本篇文章由陈研整理

https://www.bilibili.com/video/BV1gb421779t/?share_source=copy_web&vd_source=46fea0c86812502b4bd703eca52de309&t=5489
往期精彩文章推荐

ACL 2024 | BPO:灵活的 Prompt 对齐优化技术
记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 观看作者直播讲解回放!