继2023年4月首次推出SAM,实现对图像的精准分割后,Meta于北京时间2024年7月30日推出了能够分割视频的新模型SAM 2(Segment Anything Model 2)。SAM 2将图像分割和视频分割功能整合到一个模型中。所谓“分割”,是指区别视频中的特定对象与背景,并可以追踪目标。
SAM 2 可以分割任何视频或图像中的任何物体,即使从未见过,因而可以用于现实生活中的任意场景。相比于上一代模型,SAM 2 的图像分割更准确,且速度快了 6 倍。
要点
-
SAM 2 在 17 个零样本视频数据集的交互式视频分割方面表现明显优于以前的方法,并且所需的人机交互减少了大约三倍。
-
SAM 2 在 23 个数据集零样本基准测试套件上的表现优于 SAM,而且速度快了六倍。
-
与之前的最先进模型相比,SAM 2 在现有的视频对象分割基准(DAVIS、MOSE、LVOS、YouTube-VOS)上表现出色。
-
使用 SAM 2 进行推理感觉很实时,速度大约为每秒 44 帧。
-
循环中使用 SAM 2 进行视频分割注释的速度比使用 SAM 进行手动每帧注释快 8.4 倍。
SAM 2对特定人口群体的模型性能进行了评估。结果显示,该模型在感知性别的视频分割方面性能差异很小,在评估的三个感知年龄组(18-25 岁、26-50 岁和 50 岁以上)之间差异很小。

相关链接
论文地址:
-
SAM 2: https://ai.meta.com/blog/segment-anything-2/
-
SAM 1: https://arxiv.org/pdf/2304.02643
Meta官方介绍:https://ai.meta.com/blog/segment-anything-2/
SAM2网站:http://ai.meta.com/SAM2
数据集地址:https://ai.meta.com/datasets/segment-anything-video
模型地址:https://github.com/facebookresearch/segment-anything-2
方法介绍
Segment Anything Model 2 (SAM 2),这是Meta Segment Anything Model的下一代,现在支持视频和图像中的对象分割。SAM 2 是第一个用于实时、可提示的图像和视频对象分割的统一模型,它使视频分割体验发生了重大变化,并可在图像和视频应用程序中无缝使用。
SAM 2 在图像分割精度方面超越了之前的功能,并且实现了比现有工作更好的视频分割性能,同时所需的交互时间减少了三倍。SAM 2 还可以分割任何视频或图像中的任何对象(通常称为零样本泛化),这意味着它可以应用于以前从未见过的视觉内容,而无需进行自定义调整。
自推出 SAM 以来的一年里,该模型已在各个学科领域产生了巨大影响。它启发了 Meta 系列应用(例如Instagram 上的 Backdrop 和 Cutouts)中新的 AI 体验,并催化了科学、医学和众多其他行业的各种应用。许多最大的数据注释平台已将 SAM 集成为图像中对象分割注释的默认工具,节省了数百万小时的人工注释时间。SAM 还用于海洋科学中分割声纳图像和分析珊瑚礁、用于救灾的卫星图像分析以及医学领域中分割细胞图像和辅助检测皮肤癌。

SAM 2 是如何设计的
SAM 能够学习图像中物体的一般概念。然而,图像只是动态现实世界的静态快照,其中视觉片段可以表现出复杂的运动。许多重要的现实世界用例需要在视频数据中进行准确的对象分割,例如在混合现实、机器人、自动驾驶汽车和视频编辑中。我们相信通用分割模型应该适用于图像和视频。
图像可以看作是一段只有一帧的非常短的视频。基于这种观点来开发一个统一的模型,无缝支持图像和视频输入。处理视频的唯一区别是,模型需要依靠内存来回忆该视频之前处理过的信息,以便在当前时间步准确分割对象。
成功分割视频中的对象需要了解实体在空间和时间中的位置。与图像中的分割相比,视频带来了重大的新挑战。物体运动、变形、遮挡、光线变化和其他因素可能会在每一帧之间发生巨大变化。由于相机运动、模糊和分辨率较低,视频质量通常低于图像,这增加了难度。因此,现有的视频分割模型和数据集无法为视频提供类似的“分割任何内容”功能。在构建 SAM 2 和新 SA-V 数据集的工作中解决了许多这些挑战。
与用于 SAM 的方法类似,在实现视频分割功能方面的研究涉及设计新任务、模型和数据集。首先开发可提示的视觉分割任务,并设计一个能够执行此任务的模型 (SAM 2)。使用 SAM 2 来帮助创建视频对象分割数据集 (SA-V),该数据集比目前存在的任何数据集都要大一个数量级,并用它来训练 SAM 2 以实现最先进的性能。
可提示的视觉分割

设计了一个可提示的视觉分割任务,将图像分割任务推广到视频领域。SAM 经过训练,可以将图像中的点、框或蒙版作为输入,以定义目标对象并预测分割蒙版。借助 SAM 2,我们训练它接受视频任意帧中的输入提示,以定义要预测的时空蒙版(即“蒙版小片”)。SAM 2 根据输入提示立即预测当前帧上的蒙版,并将其在时间上传播以生成所有视频帧中的目标对象的蒙版小片。一旦预测了初始蒙版小片,就可以通过在任意帧中向 SAM 2 提供额外提示来迭代细化它。这可以根据需要重复多次,直到获得所需的蒙版小片。
统一架构中的图像和视频分割
从 SAM 到 SAM 2 的架构演变。
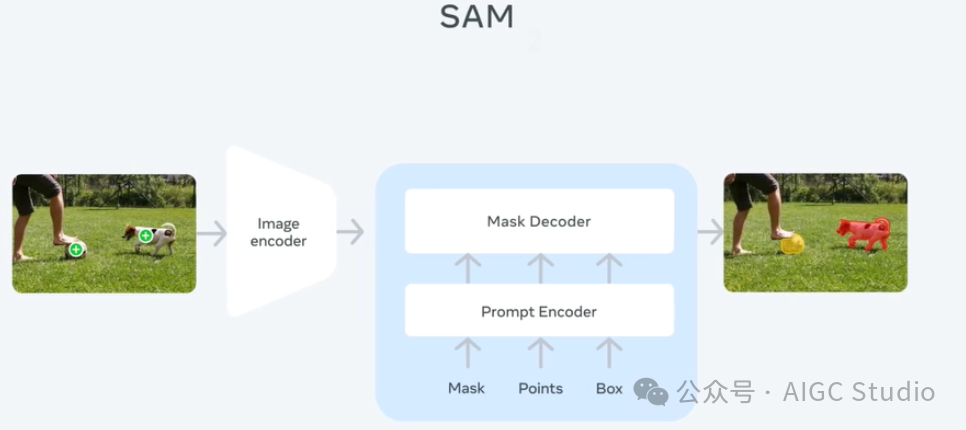
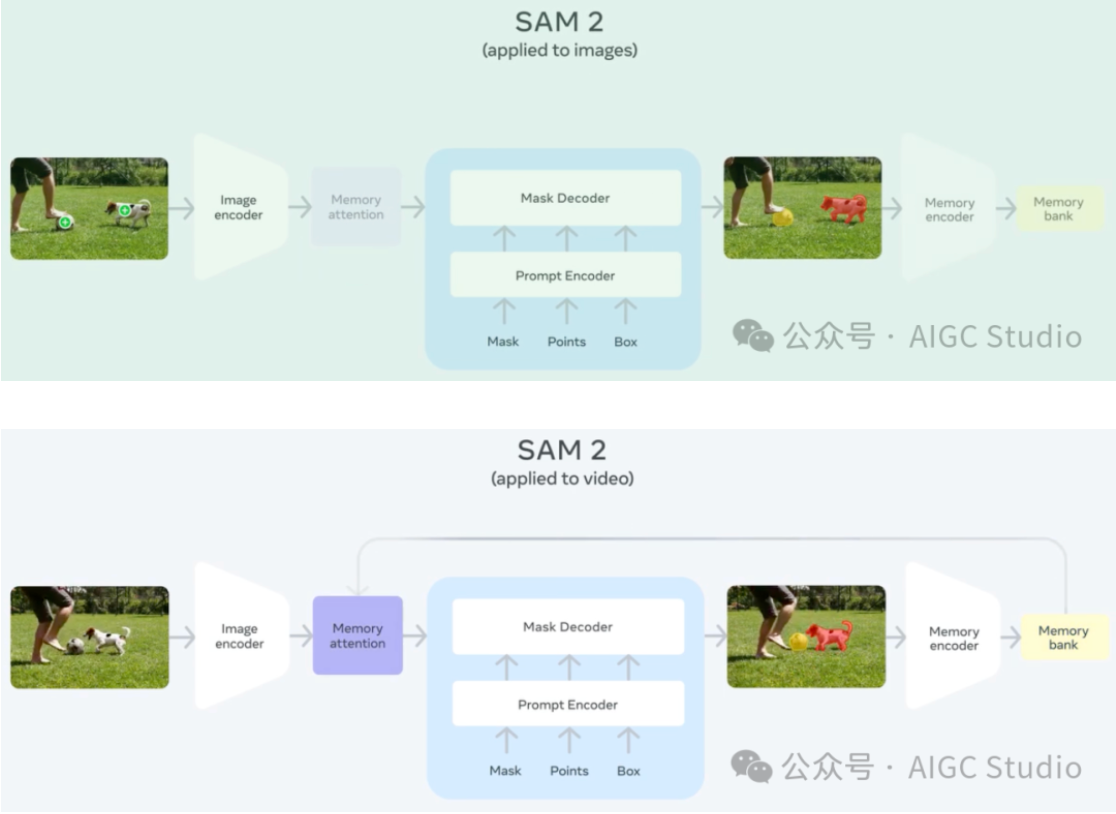
SAM 2 架构可视为 SAM 从图像到视频领域的推广。SAM 2 可通过点击(正或负)、边界框或掩码来提示,以定义给定帧中对象的范围。轻量级掩码解码器采用当前帧的图像嵌入和编码提示来输出该帧的分割掩码。在视频设置中,SAM 2 将此掩码预测传播到所有视频帧以生成掩码。然后可以在任何后续帧上迭代添加提示以优化掩码预测。
为了在所有视频帧中准确预测掩码,引入了一种记忆机制,由记忆编码器、记忆库和记忆注意模块组成。当应用于图像时,记忆组件为空,模型的行为类似于 SAM。对于视频,记忆组件可以存储有关该会话中对象和先前用户交互的信息,从而使 SAM 2 能够在整个视频中生成掩码预测。如果在其他帧上提供了其他提示,SAM 2 可以根据存储的对象记忆上下文有效地纠正其预测。
记忆编码器根据当前掩码预测创建帧记忆,并将其放置在记忆库中,用于分割后续帧。记忆库由来自前一帧和提示帧的记忆组成。记忆注意操作从图像编码器获取每帧嵌入,并在记忆库上对其进行条件处理以生成嵌入,然后将其传递给掩码解码器以生成该帧的掩码预测。对所有后续帧重复此操作。
我们采用流式架构,这是 SAM 在视频领域的自然推广,一次处理一个视频帧并将有关分割对象的信息存储在内存中。在每个新处理的帧上,SAM 2 使用记忆注意模块来关注目标对象的先前记忆。这种设计允许实时处理任意长的视频,这不仅对于收集 SA-V 数据集的注释效率很重要,而且对于现实世界的应用(例如机器人技术)也很重要。
SAM 引入了在图像中分割对象存在歧义时输出多个有效掩码的功能。例如,当一个人点击自行车轮胎时,模型可以将这次点击解释为仅指轮胎或整辆自行车,并输出多个预测。在视频中,这种歧义可以扩展到视频帧中。例如,如果在一帧中只有轮胎可见,则点击轮胎可能只与轮胎有关,或者随着自行车的更多部分在后续帧中变得可见,这次点击可能是针对整辆自行车的。为了处理这种歧义,SAM 2 在视频的每个步骤中创建多个掩码。如果进一步的提示不能解决歧义,模型将选择置信度最高的掩码在视频中进一步传播。
SA-V:构建最大的视频分割数据集

将“分割任何内容”功能扩展到视频的挑战之一是用于训练模型的注释数据有限。当前的视频分割数据集很小,缺乏对各种对象的充分覆盖。现有的数据集注释通常覆盖整个对象(例如人),但缺少对象部分(例如人的夹克、帽子、鞋子),并且数据集通常以特定对象类别为中心,例如人、车辆和动物。
为了收集大量多样化的视频分割数据集,构建了一个数据引擎,利用带有人工注释者的交互式模型在环设置。注释者使用 SAM 2 以交互方式注释视频中的 masklet,然后使用新注释的数据依次更新 SAM 2。多次重复此循环,以迭代方式改进模型和数据集。与 SAM 类似,不对注释的 masklet 施加语义约束,而是同时关注整个对象(例如,一个人)和对象部分(例如,一个人的帽子)。
使用 SAM 2,收集新的视频对象分割掩码的速度比以往更快。使用我们的工具和 SAM 2 在循环中进行注释的速度比使用 SAM 每帧的速度快约 8.4 倍,也比将 SAM 与现成的跟踪器相结合的速度快得多。
发布的 SA-V 数据集比现有的视频对象分割数据集包含多一个数量级的注释和大约 4.5 倍的视频。
SA-V 数据集的亮点包括:
-
约 51,000 个视频上有超过 600,000 个 masklet 注释。
-
视频展现了来自 47 个国家/地区的不同地理区域的真实场景。
-
注释涵盖整个对象、对象部分以及对象被遮挡、消失和重新出现的困难实例。
限制
虽然 SAM 2 在图像和短视频中分割对象方面表现出强大的性能,但模型性能还可以进一步提高——尤其是在具有挑战性的场景中。
SAM 2 可能会在摄像机视点发生剧烈变化、长时间遮挡、场景拥挤或视频过长时丢失对物体的跟踪。我们在实践中缓解了这个问题,方法是将模型设计为交互式的,并允许在任何帧中通过单击校正进行手动干预,以便恢复目标物体。


![[独家原创]基于分位数回归的Bayes-GRU多变量时序预测【区间预测】 (多输入单输出)Matlab代码](https://i-blog.csdnimg.cn/direct/078f65f2ac11472bbd2d758087f12b30.png)