目录
- `🍑动静态库`
- `🐟动静态库的制作与使用`
- `🚀生成静态库`
- `🔒生成动态库`
- `🦌动态库的查找`
- `🐬动态库与静态库`
- `🐧动态库加载`
🍑动静态库
·
静态库 && 动态库
- 静态库(.a):程序在
编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库。 - 动态库(.so):程序在
运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
一个与动态库链接的可执行文件仅仅包含它用到的函数入口地址的一个表,而不是外部函数所在目标文件的整个机器码。 - 在可执行文件开始运行以前,外部函数的机器码由操作系统从磁盘上的该动态库中复制到内存中,这个过程称为
动态链接(dynamic linking)。 动态库的优点:可以在多个程序间共享,所以动态链接使得可执行文件更小,节省了磁盘空间。操作系统采用虚拟内存机制允许物理内存中的一份动态库被要用到该库的所有进程共用,节省了内存和磁盘空间。
云服务器默认安装的是的动态库,静态库是没有安装的。
链接的时候默认的是动态链接,如果想要静态链接,需要加-static 选项 ,如:gcc test.c -static 库文件名称和引入库的名称
如:libc.so -> c库,去掉前缀lib,去掉后缀.so或则.a,剩余的就是库名称。
🐟动静态库的制作与使用
·
为什么要有库?
- 提高开发效率
- 隐藏源代码
当不想暴露源文件的前提下,想让外部使用我们的方法,最朴素的做法就是我们将自己的同名源代码编译成.o文件,然后给外部提供.h与.o文件,外部使用者只需要编写main.c文件,编译为main.o,然后够将所有的.o文件进行链接即可。这个过程就有点库的身影了。

🚀生成静态库
.c文件编译形成.o使用的指令:gcc -c 目标文件 (不指定形成的.o的文件名,默认形成同名的.o文件)
- 示例:默认已经有了.h与.c文件

- 将.o与.h文件给用户:

用户编写main函数并形成.o文件,将.o文进行链接形成可执行文件:

当.o文件很多的时候,在传文件给用户与正在进行链接的时候,不方便,可以将.o文件进行打包,形成一个库:
打包所需要的指令:ar -rc 所形成的库的 .o文件(该指令形成的是静态库)
其中,ar是gnu归档工具,rc表示(replace and create)

链接的时候需要的指令及选项:gcc .c文件 -l库的名称 -L库所在路径
- -L 指定库路径
- -l 指定库名
目标文件生成后,静态库删掉,程序照样可以运行(很好理解,不赘诉)。

🔒生成动态库
- shared: 表示生成共享库格式
- fPIC:产生位置无关码(position independent code)
- 库名规则:libxxx.so

- 打包

当使用者拿到该库,编写main函数后直接编译时会发生如下图报错:链接时报错。
原因:因为使用gcc与g++编译的时候,默认可以识别C语言与C++的库与路径,而我们你所写的库是第三方库,所以不认识。

解决方法:在编译的时候,告诉编译器库的位置与名称
gcc编译的时候添加选项:gcc main.c -L. -lmyc

如果单纯在编译角度:不想设置 -L路径 选项 ,我们该怎么办。
我们只需要将我们所写的库拷贝到系统的默认搜索路径下。
库搜索路径
- 从左到右搜索-L指定的目录。
- 由环境变量指定的目录 (LIBRARY_PATH)
- 由系统指定的目录 /usr/lib /usr/local/lib
查看可执行程序链接的动态库
指令:ldd 可执行程序

发布自己所写的库:
将自己写的.h文件与形成的库放在一个目录中,就可以将该文件发布在网上或则给其他人了,如图:

其中头文件的查找默认在当前路径与系统中头文件查找路径下去查找,如果所写的头文件不在这两个路径下,需要-I指明头文件位置:

如下所示:

注意:虽然这时候有可以编译通过了,但是当我们运行的时候会报错,这里与程序运行时动态库的查找有关,后面会详细说明以及给出解决办法。

但是上述的解决方法太麻烦,有没有方法不需要带那么长的选项呢?
方法:将头文件与库拷贝到系统指定的目录(一般都是root目录,需要超级用户权限)中去。
示例:
系统默认头文件搜索路径:

库路径:

- 将我们写的头文件与库拷贝到系统中指定路径:

再编译运行就不会报错了,如下图:

什么是库?
- 所谓的库,以上面的例子来说,就是将所有的.o文件用特定的方式,进行打包,形成一个文件。后面只需要提供一堆头文件+一个库文件。
🦌动态库的查找
对于上面遗留的报错:(进行解释与给出解决办法)

对于静态库来讲,只要在编译后形成了可执行程序,就不需要使用静态库了(这个很多好理解,因为静态库就是编译时拷贝),但是对于动态库而言,编译过后,在运行的时候,还会使用到动态库,前面利用的gcc -I +后面的选项编译,只是告诉编译器,在运行的时候,与编译器就没有关系了,所以在程序运行时OS加载程序就找不到库位置。
对于动态库来讲:需要编译时的搜索路径与运行时的库搜索路径。其中,两个路径可以一样,如果是自定义的,既需要告诉编译器,也需要告诉OS。
解决方法(四种):
方法一:将库安装(拷贝)到系统中,这样既可以支持编译,也可以支持运行。
示例:

-
方法二:将不系统默认库搜索路径下的库路径,添加到LD_LIBRARY_PATH环境变量中。
该变量是系统运行程序的时候,动态库查找的辅助路径。 -
示例:注意:每次设置的时候都是内存级设置,重启系统就会消失。

-
方法三:通过软链接的方式

-
方法四:配置/etc/ld.so.conf.d/,ld config更新
在/etc/ld.so.conf.d/目录下了,用户可以新建文件名以.conf结尾的配置文件,在配置文件中只需要写入你所要使用的第三方库的库路径即可。

🐬动态库与静态库
- 如果我们同时提供静态库与动态库,gcc默认使用的是动态库;
- 如果非要静态链接,必须加-static选项;
- 如果只提供静态库,只能对该库进行静态链接,但是程序不一定整体是静态链接的;
- 如果只提供动态库,默认只能进行动态链接,非得静态链接,会发生链接报错;
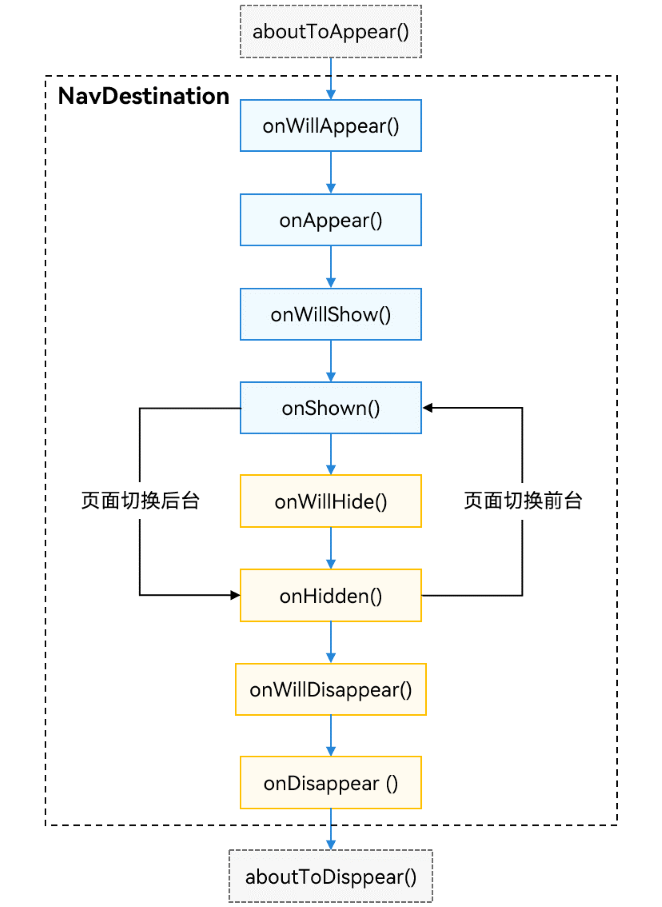
🐧动态库加载
根据下图理解下面内容:
进程运行起来,程序的代码与数据被加载到内存,初始化进程的PCB的数据(初始化,未初始化,正文代码等等),CPU读取正文代码开始执行指令,当执行的指令需要用库里面的函数实现的时候,如果库没有被加载到内存就会先加载到内存中,然后通过页表建立映射,映射到进程地址空间的共享区,如果库已经被加载到内存中了,则直接映射,所以当我们需要访问库里面的方法时,只需要在地址空间中跳转到共享区,执行库中的方法,再返回到正文代码,就完成了库函数调用。
库函数的调用依旧是在进程地址中进行的,动态库加载后,会被映射到共享区中。
当另外有程序也需要用到这个库的时候,只需要直接映射,不需要加载了,这样几个进程就可以共享一个被加载到内存中的库。所以,动态库也叫共享库。

首先,可执行程序本身是有自己的格式信息的;
可执行程序在没有被加载到内存中,被编译号的可执行程序本来就有地址(很好理解)!

可执行程序在加载之前基本上都按照类别(比如权限,访问属性等等)已经将可执行程序划分为各个区域了,方便在运行时初始化地址空间的数据(比如地址空间中各数据段的起始地址)。
其中,可以使用指令:size 可执行程序 查看划分的区域
我们之前所说的进程地址空间中有很多地址数据(比如初始化数据区的起始地址与结束地址),都是从可执行程序中来的,下面会详细讲解到。
编址分为绝对编址(平坦模式)与相对地址(逻辑地址)。
现在大多都是使用绝对地址编址。
其中所说的地址,就是页表的虚拟地址。
所以当在加载可执行程序的时候,就可以根据可执行程序的相关内容去初始化进程地址空间与页表
所以,虚拟地址空间本身不仅OS要遵守,编译器在编译的时候也要遵守。
Linux系统在编译的时候采用的是平坦模式编址方式,在Linux可执行程序中的 虚拟地址=逻辑地址 。解释:虽然逻辑地址对应的是相对地址(起始地址+偏移量),但是平坦模式也可以看成是起始地址+偏移量,只不过起始地址为0而已。

- 可执行程序在加载的时候会用可执行程序的
表头数据来初始化进程的地址空间,所以不同的可执行程序有不同的数据段的大小。 - 可执行程序加载到内存后,每一行代码都有自己的虚拟地址与物理地址的映射,图中只化了main函数第一条指令的映射示例。
在CPU中有一个cr3寄存器,保存页表的起始地址,还有一个pc指针(程序计数器),里面保存的是当在执行的指令的下一条指令的地址。程序被加载的时候,就会用可执行程序表头记录的入口地址(虚拟地址)将pc指针初始化,当准备工作都做完后,CPU就开始寻址,查页表,然后经过虚拟地址与物理地址转换(CPU内部完成),就可以依次有序的取指令,解析指令,执行指令。
所谓的地址空间,本质是由OS+编译器+CPU三者共同配合完成的。
当加入动态库
动态库在磁盘中是以库的起始地址+偏移量编址的(如下图));
当可执行程序被加载到内存中时如果需要使用到库里面的函数时,都会将该位置改为库起始地址+该函数在库中的偏移量;
所以当执行我们的程序时候,访问到图中的printf方法时,只需要将_start换成进程地址空间中库的起始地址,如图的0xFFF1111,然后再根据偏移量,在共享区确定该函数的虚拟地址,然后根据虚拟地址找到内存中该函数。

库数据和方法的访问,都是可以通过库地址在地址空间起始地址+我们程序内部的偏移量即可!