什么是 Headlesschrome?
Headless?是的,这意味着这个浏览器没有图形用户界面 (GUI)。不用鼠标或触摸设备与视觉元素交互,你需要使用命令行界面 (CLI) 来执行自动化操作。
Headlesschrome 和 Puppeteer
很多网页抓取工具都可适用于 Headlesschrome,并且 Headlesschrome 通常可以消除很多麻烦。
你可能还喜欢:如何检测和反检测 Headlesschrome?
Puppeteer 是什么?它是一个 Node.js 库,提供了一个高级 API 来控制 Headlesschrome 或 Chromium,或与 DevTools 协议进行交互。
今天我们将通过 Puppeteer 深入探索 Headlesschrome。
使用 Puppeteer 进行网页抓取的优势是什么?
正如你所想象的,使用 Puppeteer 进行网页抓取有几个很大的优势:
- Puppeteer 抓取工具能够提取动态数据,因为 Headlesschrome 可以像普通浏览器一样渲染 JavaScript、图像等。
- Puppeteer 网页抓取脚本更难检测和阻止。由于连接配置看起来像普通用户的配置,因此难以将其识别为自动化操作。
如何使用 Puppeteer 和 Node.JS 进行网页抓取?
在以下示例中,我们将执行基本的网页抓取,帮助你快速入门 Puppeteer。我们选择抓取的页面是 Amazon 的 Apple AirPods Pro 评论区。
但别担心,在此之前,我们还需要做一些准备工作:
安装和配置 Puppeteer
- 步骤 1. 请确保你已经安装了 Node.js。
如果没有,请直接安装 Node.js (LST),然后通过 Node.js 的包管理器 npm 安装 Puppeteer。这个过程可能会有点长,因为 Puppeteer 还需要安装相应的 Chrome。
npm i puppeteer- 步骤 2. 安装后,你可以运行以下演示代码,确保你的安装是正确的。
你也可以使用此演示代码对 Puppeteer 有一个大致的了解。不要在这里卡住,因为我们稍后将详细介绍 Puppeteer 的用法和相关场景。
Puppeteer 默认启用了 headless 模式。在这里,通过 puppeteer.launch({ headless: false }) 关闭 headless 模式,以便你看到抓取过程。
import puppeteer from 'puppeteer';
// 启动浏览器并打开一个新标签页
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
// 导航到指定的 URL
await page.goto('https://developer.chrome.com/');
// 设置屏幕大小
await page.setViewport({width: 1080, height: 1024});
// 定位搜索框元素并在搜索框中输入内容
await page.locator('.devsite-search-field').fill('automate beyond recorder');
// 等待并点击第一个搜索结果
await page.locator('.devsite-result-item-link').click();
// 使用唯一字符串定位完整标题
const textSelector = await page.locator('text/Customize and automate').waitHandle();
const fullTitle = await textSelector?.evaluate(el => el.textContent);
// 打印完整标题
console.log('这篇博客文章的标题是 "%s".', fullTitle);
// 关闭浏览器实例
await browser.close();Puppeteer 是一个基于 Promise 的异步库,通过 async await 可以非常直观地展示其功能。以上演示和后续示例不需要异步函数。这是因为 package.json 中设置了 "type": "module",使其运行为 ES 模块。
页面分析
好了,我们开始吧。
请先打开 Apple AirPods Pro 的评论区,然后我们需要识别要抓取内容的元素。你可以通过按 Ctrl + Shift + I (Windows/Linux) 或 Cmd + Option + I (Mac) 打开 Devtools。
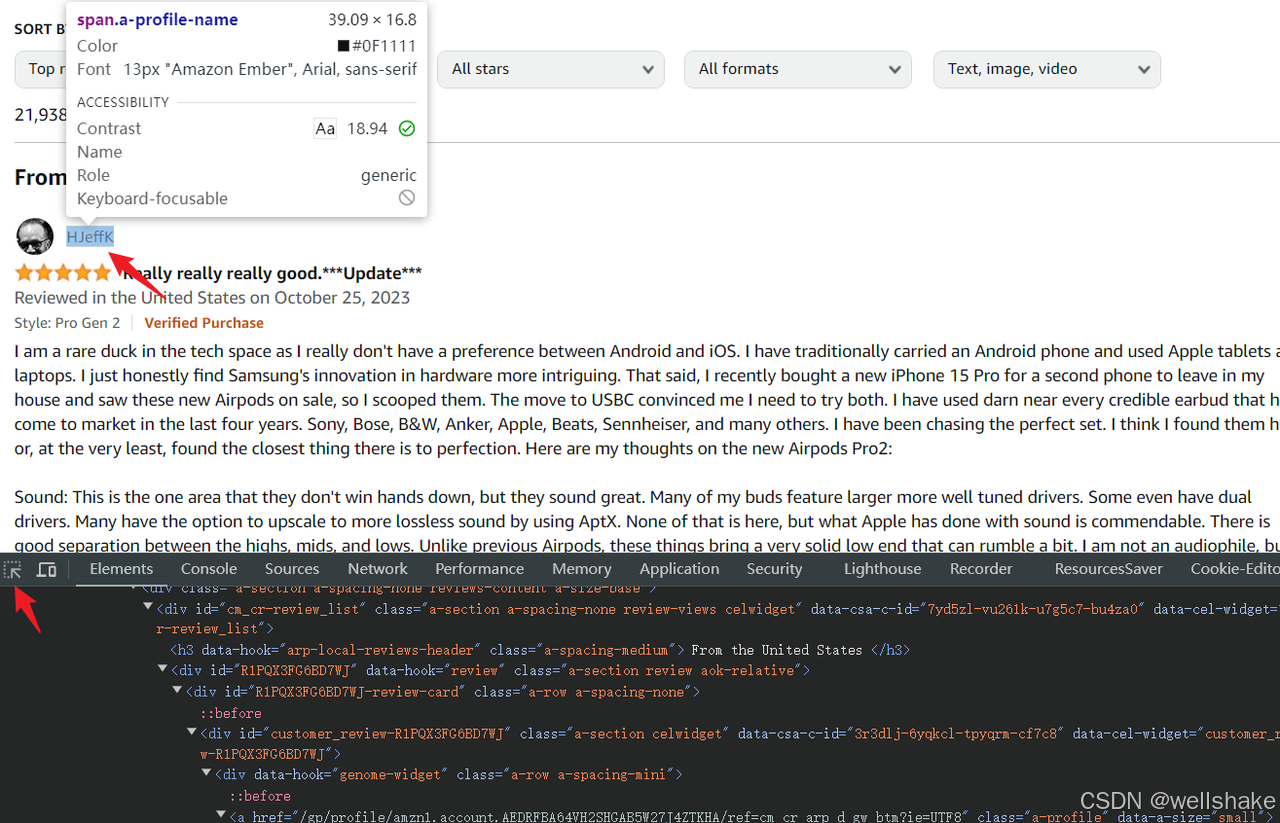
- 步骤 1. 点击控制台左上角的元素选择器
- 步骤 2. 使用鼠标悬停并选择你想要抓取的元素节点。控制台还会突出显示与此元素对应的 HTML 代码
Puppeteer 支持多种元素选择方法(puppeteer 选择器),但最推荐入门使用简单的 CSS 选择器。上面使用的 .devsite-search-field 也是一个 CSS 选择器。
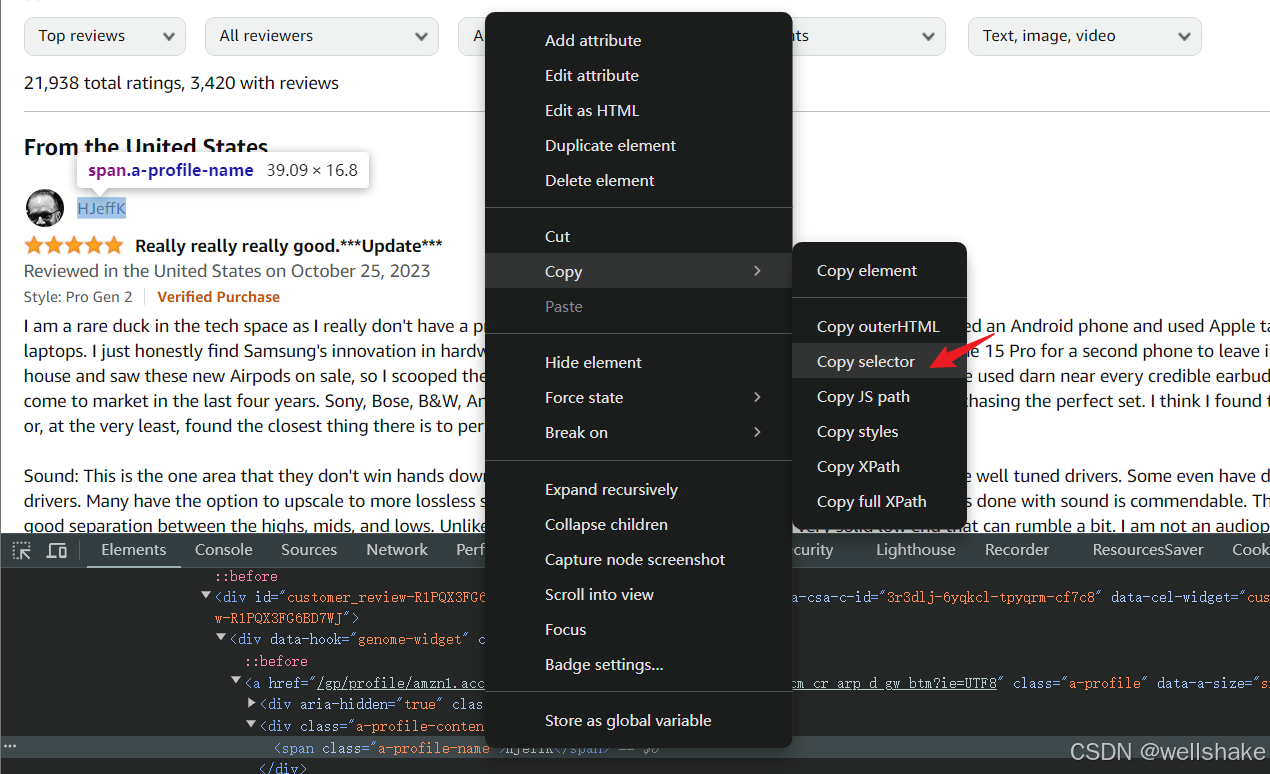
对于复杂的 CSS 结构,调试控制台可以直接复制 CSS 选择器。右键单击需要抓取的元素 HTML,打开 菜单 > 复制 > 复制选择器。
但不建议你这样做,因为从复杂结构复制的选择器可读性非常差,不利于代码维护。当然,对于一些简单的选择和个人测试学习,完全没问题。
现在,元素选择器已经确定。我们可以使用 Puppeteer 尝试抓取我上面选择的用户名。
import puppeteer from 'puppeteer';const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent)console.log('[username]===>', username);如你所见,上面的代码使用 page.goto 跳转到指定页面。然后 page.$eval 可以获取第一个匹配的元素节点,并通过回调函数获取元素节点的具体属性。
如果你足够幸运,没有触发亚马逊的验证页面,你可以成功获取到值。然而,一个稳定的脚本不能仅仅依靠运气,所以我们接下来还需要进行一些优化。
等待页面加载
尽管我们已经通过上述方法获取了元素节点的信息,但我们必须考虑其他因素:如网络加载速度,页面是否滚动到目标元素以正确加载元素,是否触发了验证页面并需要手动处理。
因此,在加载完成之前,我们必须耐心等待。当然,Puppeteer 还为我们提供了相应的 API 供我们使用。
常用的 waitForSelector 是一个等待元素出现的 API。我们可以使用它来优化上面的代码,以确保脚本的稳定性。在调用 page.$eval 之前,只需使用 waitForSelector API。
这样,Puppeteer 将在页面加载元素 div[data-hook="genome-widget"] .a-profile-name 后再执行后续代码。
await page.waitForSelector('div[data-hook="genome-widget"] .a-profile-name');
const username = await page.$eval('div[data-hook="genome-widget"] .a-profile-name', node => node.textContent)还有一些其他的等待 API 适用于不同场景。让我们看看一些常用的:
page.waitForFunction(pageFunction, options, ...args):等待页面上下文中的指定函数返回 true。
import puppeteer from 'puppeteer'const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');// 等待页面的 `window.title` 改变为 "Example Domain"
await page.waitForFunction('document.title === "Example Domain"');
console.log('标题已更改为 "Example Domain"');await browser.close();page.waitForNavigation(options):等待页面导航完成。导航可以是点击链接、提交表单、调用window.location等。
import puppeteer from 'puppeteer';const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');// 点击链接并等待导航完成
await Promise.all([page.click('a'),page.waitForNavigation()
])console.log('导航完成');
await browser.close();page.waitForRequest(urlOrPredicate, options):等待匹配指定 URL 或条件函数的请求。
import puppeteer from "puppeteer";const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com');// 该请求需要你监控实际页面的请求 URL。这只是一个示例。
// 你可以手动在浏览器地址栏中输入 https://example.com/resolve 来触发请求并验证此演示
const Request = await page.waitForRequest('https://example.com/resolve');console.log('request-url:', Request.url());
await browser.close()page.waitForResponse(urlOrPredicate, options):等待匹配指定 URL 或条件函数的响应。
import puppeteer from "puppeteer";const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://example.com');// 该响应需要你监控实际页面的响应 URL。这只是一个示例。
// 你可以手动在浏览器地址栏中输入 https://example.com/resolve 来触发响应并验证此演示
const response = await page.waitForResponse('https://example.com/resolve');console.log('response-status:', response.status());
await browser.close();page.waitForNetworkIdle(options):等待页面上的网络活动变为空闲状态。此方法用于确保页面已加载完成。
import puppeteer from "puppeteer";const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');await page.waitForNetworkIdle({timeout: 30000, // 最大等待时间 30 秒idleTime: 500 // 即在 500 毫秒的空闲时间内没有网络活动
});console.log('Network is idle.');// 保存截图以验证页面是否完全加载
await page.screenshot({ path: 'example.png' });
await browser.close();setTimeout:直接使用 JavaScript API 也是一个不错的选择。经过一些包装后,可以在页面上下文中运行。
// 等待两秒后执行后续脚本
await new Promise(resolve => setTimeout(resolve, 2000))
await page.click('.devsite-result-item-link'); // 点击该元素你对网络爬虫和无头浏览器有任何精彩的想法或疑问吗?
让我们看看其他开发者在 Discord 和 Telegram 上分享了什么吧!
爬取和存储数据
好的,让我们开始爬取页面评论列表中的完整数据。
- 第 1 步。 数据爬取
我们可以重写上述代码,不再仅仅爬取单个用户名,而是关注整个评论列表。
以下代码也使用 page.waitForSelector 等待评论元素加载,并使用 page.$$ 获取所有与元素选择器匹配的元素节点:
await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');接下来,我们需要循环遍历评论元素列表,并从每个评论元素中获取所需的信息。
在以下代码中,我们可以获取标题、评分、用户名和内容的 textContent,并获取头像元素节点中 data-src 的属性值,该属性值为头像的 URL 地址。
for (const review of reviewList) {const title = await review.$eval('a[data-hook="review-title"] .cr-original-review-content',node => node.textContent,);const rate = await review.$eval('i[data-hook="review-star-rating"] .a-icon-alt',node => node.textContent,);const username = await review.$eval('div[data-hook="genome-widget"] .a-profile-name',node => node.textContent,);const avatar = await review.$eval('div[data-hook="genome-widget"] .a-profile-avatar img',node => node.getAttribute('data-src'),);const content = await review.$eval('span[data-hook="review-body"] span',node => node.textContent,);console.log('[log]===>', { title, rate, username, avatar, content });
}- 第 2 步。 存储数据
运行上述代码后,你应该能够在终端中看到打印的日志信息。
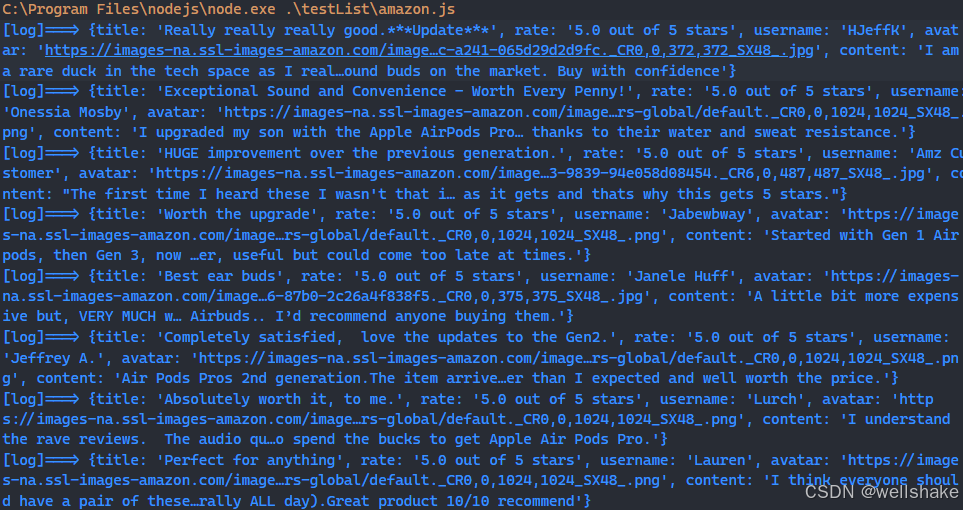
如果你想进一步存储这些数据,可以使用基本的 nodejs 模块 fs 将数据写入 json 进行后续的数据分析。
以下是一个简单的工具函数:
import fs from 'fs';function saveObjectToJson(obj, filename) {const jsonString = JSON.stringify(obj, null, 2)fs.writeFile(filename, jsonString, 'utf8', (err) => {err ? console.error(err) : console.log(`文件已成功保存: ${filename}`);});
}完整代码如下。运行后,你可以在当前脚本执行路径中找到 amazon_reviews_log.json 文件,该文件记录了所有的爬取结果!
import puppeteer from 'puppeteer';
import fs from 'fs';const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(`https://www.amazon.com/Apple-Generation-Cancelling-Transparency-Personalized/product-reviews/B0CHWRXH8B/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews`
);await page.waitForSelector('div[data-hook="review"]');
const reviewList = await page.$$('div[data-hook="review"]');const reviewLog = []for (const review of reviewList) {const title = await review.$eval('a[data-hook="review-title"] .cr-original-review-content',node => node.textContent,);const rate = await review.$eval('i[data-hook="review-star-rating"] .a-icon-alt',node => node.textContent,);const username = await review.$eval('div[data-hook="genome-widget"] .a-profile-name',node => node.textContent,);const avatar = await review.$eval('div[data-hook="genome-widget"] .a-profile-avatar img',node => node.getAttribute('data-src'),);const content = await review.$eval('span[data-hook="review-body"] span',node => node.textContent,);console.log('[log]===>', { title, rate, username, avatar, content });reviewLog.push({ title, rate, username, avatar, content })
}function saveObjectToJson(obj, filename) {const jsonString = JSON.stringify(obj, null, 2)fs.writeFile(filename, jsonString, 'utf8', (err) => {err ? console.error(err) : console.log(`文件已成功保存: ${filename}`);});
}saveObjectToJson(reviewLog, 'amazon_reviews_log.json')
await browser.close()Puppeteer 的其他功能示例
了解了基本用法之后?现在,我们可以继续了解 Puppeteer 的强大功能。运行以下示例后,我相信你会对这个工具有新的认识。
1. 模拟鼠标移动
使用 page.mouse.move 来操作鼠标移动。
为了让你感受到光标确实在页面上移动,以下演示是一个无限循环,将使鼠标随机移动以触发页面的悬停样式。
需要注意的是,触发悬停的前提是鼠标移动不能太快。move 方法中的 steps: 10 配置了移动速率。这个步骤也可以降低网站被检测到的概率。
Page.evaluate 是一个非常有用的 API,允许你在页面上下文中执行仅在浏览器环境中运行的 JavaScript 代码,例如使用 window API。这里的目的是将页面滚动到底部,以便页面评论会完全加载。
import puppeteer from 'puppeteer';const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto('https://www.google.com');// 获取屏幕的宽度和高度
const { width, height } = await page.evaluate(() => {return { width: window.innerWidth, height: window.innerHeight };
});// 无限循环,模拟随机的鼠标移动
while (true) {const x = Math.floor(Math.random() * width);const y = Math.floor(Math.random() * height);await page.mouse.move(x, y, { steps: 10 });console.log(`鼠标位置: (${x}, ${y})`);await new Promise(resolve => setTimeout(resolve, 200)); // 每 0.2 秒移动一次
}2. 点击按钮并填写表单
我们在初始演示中也遇到过这个。如何改变写法并使用其他 API 实现它?
你会看到一些选择器前面带有 >>>,这是 Puppeteer 提供的 Shadow DOM selector。大多数操作都是通过 delay 进行延迟触发,这可以很好地模拟真实用户的行为,使你的脚本更稳定,避免触发某些网站的反爬虫机制。
import puppeteer from 'puppeteer';const browser = await puppeteer.launch({headless: false,// defaultView 设置宽度和高度为 0,这意味着网页内容填充整个窗口。defaultViewport: { width: 0, height: 0 }
});
const page = await browser.newPage();await page.goto('https://developer.chrome.com/docs/css-ui?hl=de');await page.click('>>> button[aria-controls="language-menu"]', { delay: 500 });// 跳转到新页面并等待跳转成功
await Promise.all([page.click('>>> li[role="presentation"]', { delay: 500 }),page.waitForNavigation(),
])// 使用 setTimeout 作为延迟器,等待 2 秒加载页面
await new Promise(resolve => setTimeout(resolve, 2000))// 聚焦输入框
await page.focus('input.devsite-search-query', { delay: 500 });// 通过键盘输入文本
await page.keyboard.type('puppeteer', { delay: 200 });// 触发键盘回车键并提交表单
await page.keyboard.press('Enter')console.log('form submit successfully');
await page.close()3. 使用 Puppeteer 截取屏幕截图
Puppeteer 提供了方便的截图 API,这是一个非常实用的功能,我们在上面的示例中已经看到过。
截图文件的质量可以通过 quality 进行很好的控制,clip 用于裁剪图片。如果你对截图比例有要求,也可以设置 defaultViewport 来实现。
import puppeteer from 'puppeteer';const browser = await puppeteer.launch({ defaultViewport: { width: 1920, height: 1080 } });
const page = await browser.newPage();await page.goto('https://www.youtube.com/');await page.screenshot({ path: 'screenshot1.png' });
await page.screenshot({ path: 'screenshot2.jpeg', quality: 50 });
await page.screenshot({ path: 'screenshot3.jpeg', clip: { x: 0, y: 0, width: 150, height: 150 } });console.log('screenshot saved');
await browser.close();4. 在 Puppeteer 中拦截或阻止请求
要拦截请求,首先需要使用 setRequestInterception 激活请求拦截。运行以下示例,你会惊讶地发现页面样式消失了,图片和图标也不见了。
这是因为通过页面监控了请求,并且使用 interceptedRequest 的 resourceType 和 url 来判断是否取消或重写相应的请求。
我们需要注意的是,在处理请求拦截之前,应该调用 isInterceptResolutionHandled 方法,以避免重复处理请求或发生冲突。
import puppeteer from 'puppeteer';const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();// 激活请求拦截
await page.setRequestInterception(true);
page.on('request', interceptedRequest => {// 避免请求被重复处理if (interceptedRequest.isInterceptResolutionHandled()) return;// 拦截请求并重写响应if (interceptedRequest.url().includes('https://fonts.gstatic.com/')) {interceptedRequest.respond({status: 404,contentType: 'image/x-icon',})console.log('icons request blocked');// 阻止样式请求} else if (interceptedRequest.resourceType() === 'stylesheet') {interceptedRequest.abort();console.log('Stylesheet request blocked');// 阻止图片请求} else if (interceptedRequest.resourceType() === 'image') {interceptedRequest.abort();console.log('Image request blocked');} else {interceptedRequest.continue();}
});await page.goto('https://www.youtube.com/');当然,上述功能也可以借助一些工具实现,例如使用 Nstbrowser RPA 来加速你的爬虫!
步骤 1. 进入 Nstbrowser 的首页,点击 RPA/Workflow > 创建工作流。
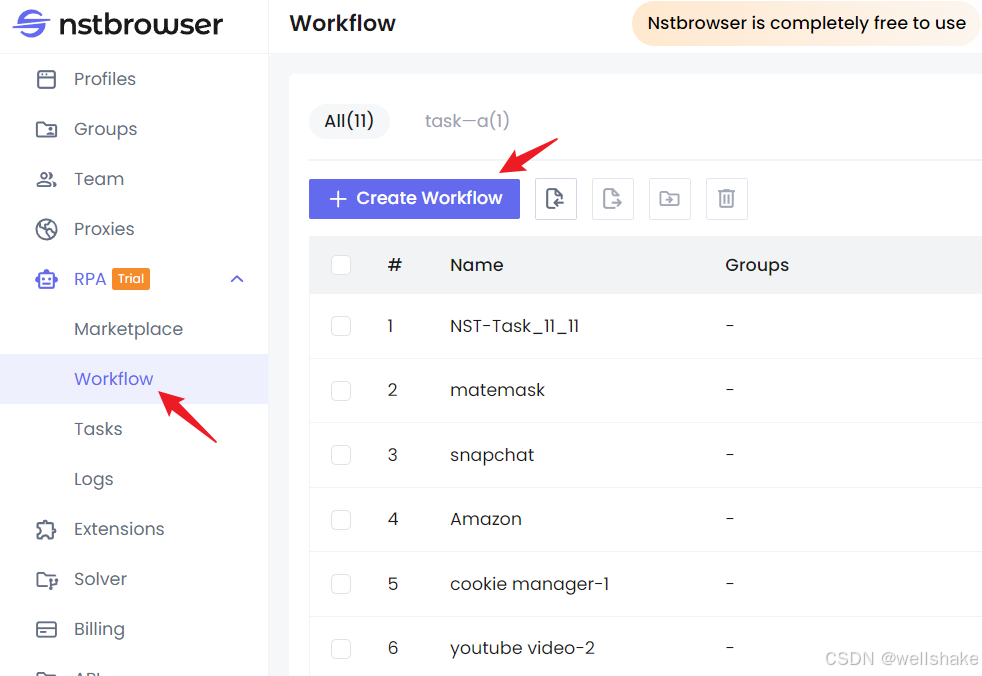
步骤 2. 进入工作流编辑页面后,你可以直接通过拖拽鼠标复现上述功能。
左侧的 Node 几乎可以满足你所有的爬虫或自动化需求,这些节点与 Puppeteer API 高度一致。
你可以通过连接这些节点来校准执行顺序,就像执行 JavaScript 异步代码一样。如果你了解 Puppeteer,你可以快速上手 Nstbrowser RPA 功能,它就是你所见即所得。
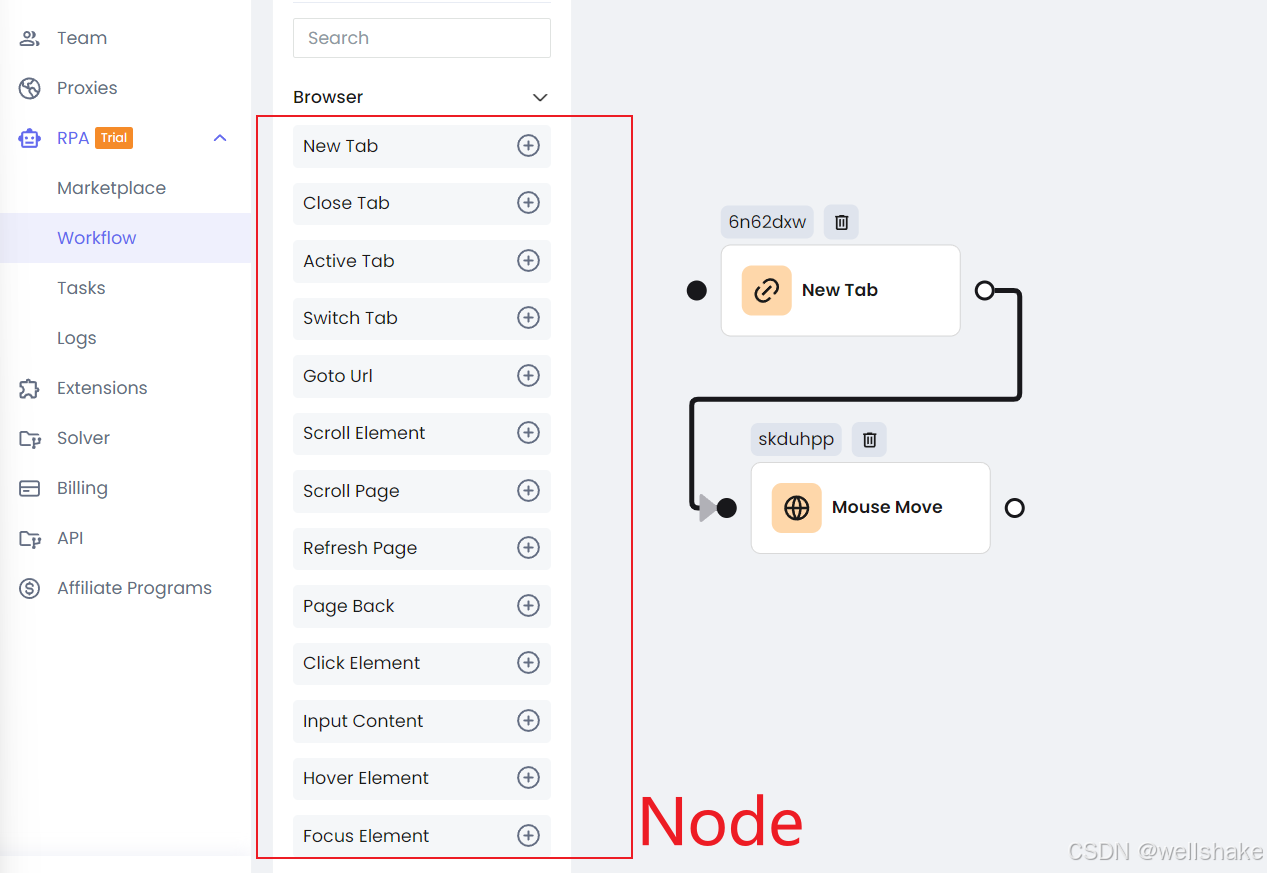
步骤 3. 每个 Node 都可以单独配置,配置的信息几乎与 Puppeteer 的配置相对应。
a. 鼠标移动
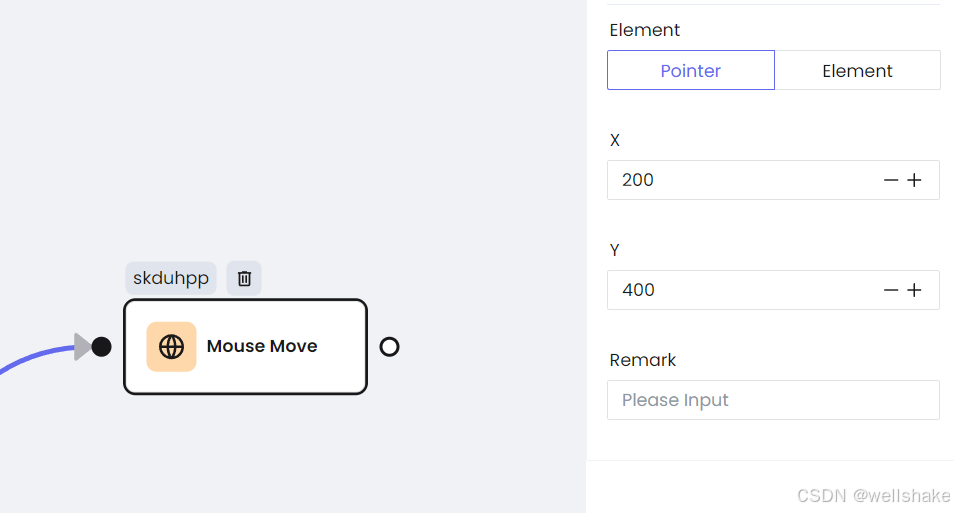
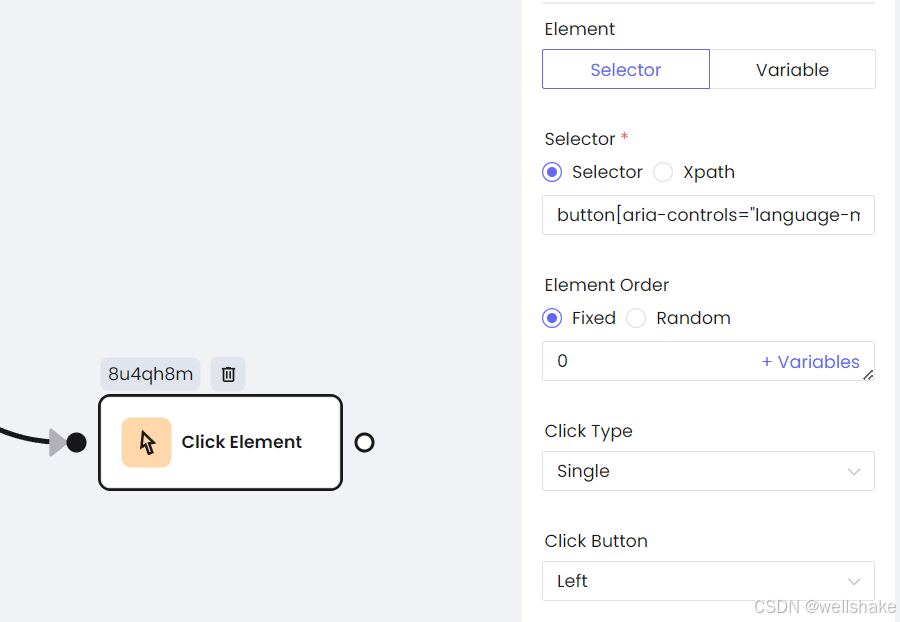
b. 点击按钮
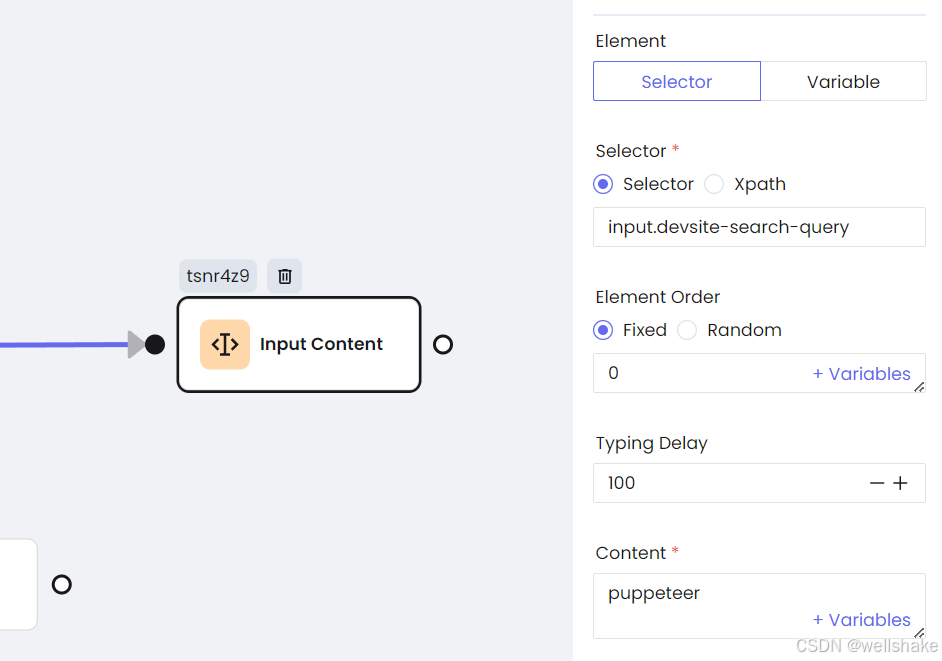
c. 输入
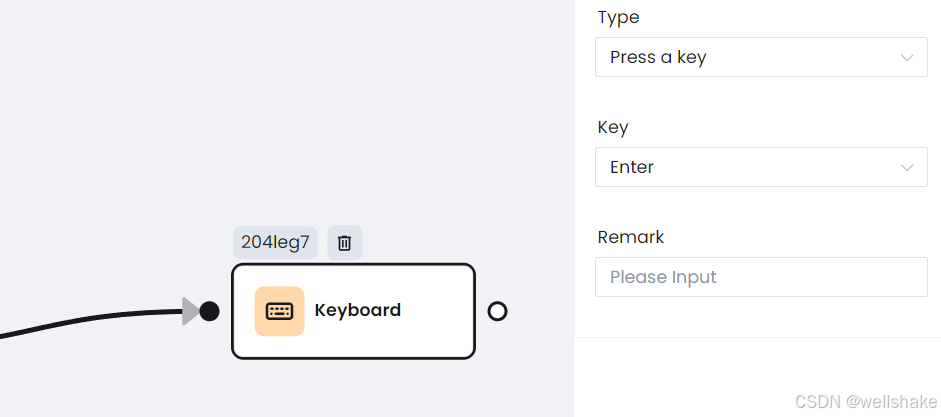
d. 键盘按键
e. 等待响应
f. 截图
此外,Nstbrowser RPA 还有更多常见和独特的节点。你可以通过简单的拖拽完成常见的爬虫操作。
设置 HTTP Headers 以避免机器人检测
HTTP headers 是在客户端(浏览器)和服务器之间交换的附加信息。它们包含请求和响应的元数据,例如内容类型、用户代理、语言设置等。
常见的 HTTP headers 包括:
User-Agent:标识客户端应用程序类型、操作系统、软件版本及其他信息。Accept-Language:指示客户端可以理解的语言及其优先级。Referer:指示请求的来源页面。
通过修改这些 headers,你可以将自己伪装成不同的浏览器或操作系统,从而降低被检测为机器人的风险。
在使用 Puppeteer 时,你可以使用 page.setExtraHTTPHeaders 方法在跳转到网页之前设置 headers:
import puppeteer from 'puppeteer';const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();// 设置自定义 HTTP headers
await page.setExtraHTTPHeaders({'Accept-Language': 'en-US,en;q=0.9','Referer': 'https://www.google.com','MyHeader': 'hello puppeteer'
});await page.goto('https://www.httpbin.org/headers');但如果你想修改 User-Agent,则不能使用上述方法。因为浏览器中的 User-Agent 有一个默认值。如果你确实想更改它,可以使用 page.setUserAgent。
import puppeteer from "puppeteer";const browser = await puppeteer.launch();
const page = await browser.newPage();await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.5790.98 Safari/537.36');await page.goto('https://example.com/');
const navigator = await page.evaluate(_ => window.navigator.userAgent)
const platform = await page.evaluate(_ => window.navigator.platform)
console.log('userAgent: ', navigator);
console.log('platform: ', platform);
await browser.close();
但这一步还不够。从上面打印的信息来看,paltform 仍然设置为 win32,并没有被真正修改。
大多数网站通过 window.navigator 进行检测。因此有必要对 navigator 进行深入修改。在使用 page.goto 之前,我们可以在 page.evaluateOnNewDocument 中深入修改 navigator。
下面是 page.evaluateOnNewDocument 和 page.evaluate 之间区别的简要说明:
- 如果你需要修改浏览器环境或在每个页面加载前执行一些操作,请使用
evaluateOnNewDocument。 - 如果你只需要与当前加载的页面进行交互或提取数据,请使用
evaluate。
await page.evaluateOnNewDocument(() => {Object.defineProperties(navigator, {platform: {get: () => 'Mac'},});
});
结论
本文中的每一行都在描述最详细的指南,涵盖了以下内容:
- 什么是 headlesschrome?
- 什么是 Puppeteer?
- 如何使用 headlesschrome 进行网页爬取?
想轻松进行网页爬取和自动化操作吗?Nstbrowser RPA 帮助你简化所有任务。