Puppeteer
Puppeteer是一个Node.js库,它提供了高级API来通过DevTools协议(Chrome DevTools Protocol https://devtools.chrome.com)控制Chrome或Chromium。 Puppeteer默认情况下无头运行(headless)。
可以配置为运行完整的Chrome或Chromium,运行效果如下
Puppeteer具备以下功能:
1、页面截图和生成PDF
2、抓取动态网页内容
3、自动化表单提交,UI测试,键盘输入等
4、测试Chrome扩展程序
Puppeteer项目地址:
GitHub - puppeteer/puppeteer: JavaScript API for Chrome and Firefox
在C#中调用,是使用了Puppeteer的移植版本,puppeteer-sharp,项目地址:
GitHub - hardkoded/puppeteer-sharp: Headless Chrome .NET API
Puppeteer-sharp是基于.Net Standard 2.0开发,所以可以运行于NET Framework 4.6.1+、 .NET Core 2.0+的版本上.
操作系统的要求是Windows 8+或Windows Server2012+。如果需要在Windows 7上运行Puppeteer-Sharp,则可以通过设置LaunchOptions.WebSocketFactory属性的值为System.Net.WebSockets.Client.Managed来实现。
对于前端开发人员来说,Puppeteer最大的用处应该就是自动化测试,而对于爬虫开发人员,Puppeteer最大的用处是可以很方便的抓取动态网页。Puppeteer就等于是一个人为操作的浏览器,你可以控制它抓取任何动态网页内容。
对比CEF
在前面的文章中,我使用了CEFSharp嵌入到界面中,来进行了动态页面的抓取(https://www.cnblogs.com/zhaotianff/p/9556270.html),
使用Puppeteer也可以达到同样的效果,但它用起来会更加方便, 因为它能以headless方式运行,不用显示在界面上。而且它封装了很多方便开发人员使用的函数。
本质 上来说,Puppeteer是通过Chrome DevTools Protocol来控制Chromium浏览器,而CEF提供了Chromium浏览器本身,它是一个Web Browser控件。
抓取动态页面
1 await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);
2 var browser = await Puppeteer.LaunchAsync(new LaunchOptions
3 {
4 Headless = true
5 });
6 var page = await browser.NewPageAsync();
7 await page.GoToAsync("https://www.baidu.com");
8 var html = await page.GetContentAsync();
网页截图
1 await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);2 browser = await Puppeteer.LaunchAsync(new LaunchOptions3 {4 Headless = true5 });6 var page = await browser.NewPageAsync(); //打开一个新标签7 await page.GoToAsync("https://www.baidu.com"); //访问页面8 9
10 //设置截图选项
11 ScreenshotOptions screenshotOptions = new ScreenshotOptions();
12 //screenshotOptions.Clip = new PuppeteerSharp.Media.Clip() { Height = 0, Width = 0, X = 0, Y = 0 };//设置截剪区域
13 screenshotOptions.FullPage = true; //是否截取整个页面
14 screenshotOptions.OmitBackground = false;//是否使用透明背景,而不是默认白色背景
15 screenshotOptions.Quality = 100; //截图质量 0-100(png不可用)
16 screenshotOptions.Type = ScreenshotType.Jpeg; //截图格式
17
18 await page.ScreenshotAsync("D:\\a.jpg",screenshotOptions);
截图效果如下:
保存网页为PDF
1 await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);2 browser = await Puppeteer.LaunchAsync(new LaunchOptions3 {4 Headless = true5 });6 var page = await browser.NewPageAsync(); //打开一个新标签7 await page.GoToAsync("https://www.baidu.com"); //访问页面8 9 //设置PDF选项
10 PdfOptions pdfOptions = new PdfOptions();
11 pdfOptions.DisplayHeaderFooter = false; //是否显示页眉页脚
12 pdfOptions.FooterTemplate = ""; //页脚文本
13 pdfOptions.Format = new PuppeteerSharp.Media.PaperFormat(8.27m,11.69m); //pdf纸张格式 英寸为单位
14 pdfOptions.HeaderTemplate = ""; //页眉文本
15 pdfOptions.Landscape = false; //纸张方向 false-垂直 true-水平
16 pdfOptions.MarginOptions = new PuppeteerSharp.Media.MarginOptions() { Bottom = "0px", Left = "0px", Right = "0px", Top = "0px" }; //纸张边距,需要设置带单位的值,默认值是None
17 pdfOptions.Scale = 1m; //PDF缩放,从0-1
18 await page.PdfAsync(path, pdfOptions);
保存出来的PDF效果并不怎么好,应该是文档宽高没控制好的原因。

重要说明:
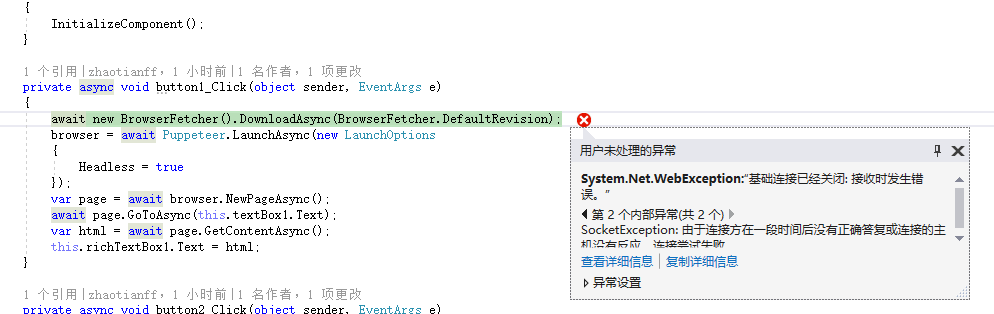
Puppeteer需要先下载Chromium浏览器的相关文件,也就是下面这句代码执行的操作
1 await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);
可能会出现下载失败的情况,如下图:
可以从这里下载 ,并解压到程序运行目录。(推荐这种方式,因为出现了上面的异常,第二种方式中的链接你也访问不了
![]()
)
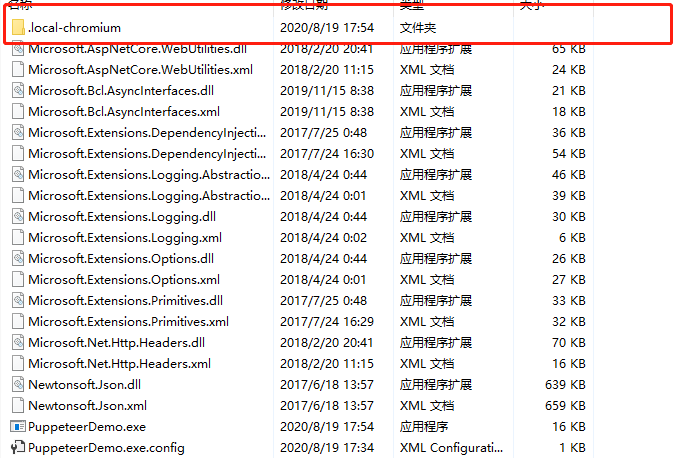
也可以通过以下方式:
访问google chromium开源镜像网站,下载Chromium浏览器
https://commondatastorage.googleapis.com/chromium-browser-snapshots/index.html?prefix=Win_x64/
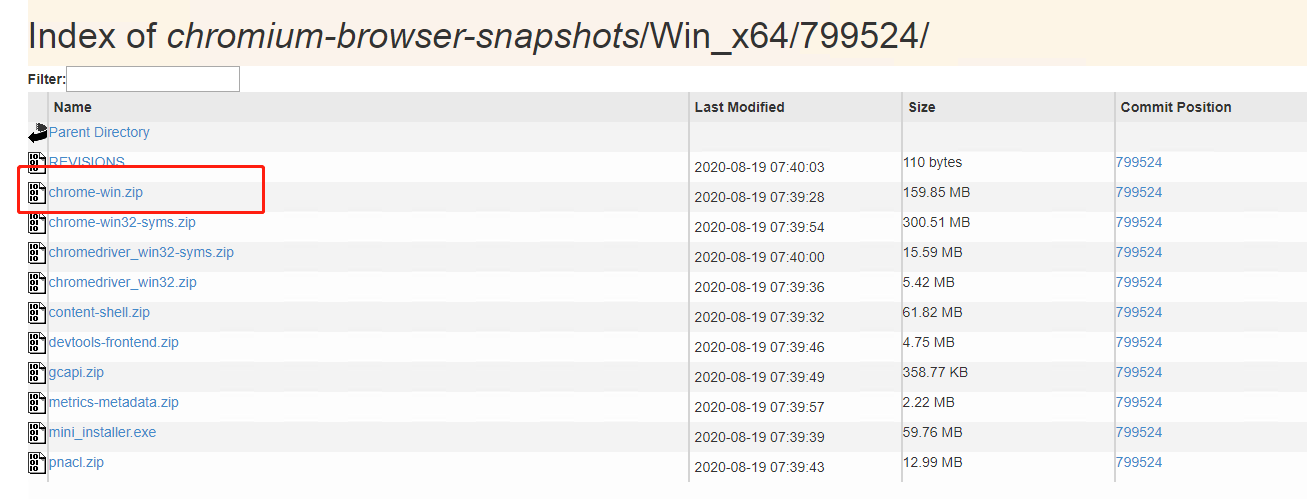
下载后解压到相应位置,然后通过指定Chromium路径来进行初始化
1 LaunchOptions options = new LaunchOptions();2 options.Headless = true;3 options.DefaultViewport = null;4 //忽略证书错误5 options.IgnoreHTTPSErrors = true;6 7 //chromePath就是下载的Chromium浏览器解压的位置 11 options.ExecutablePath = chromePath; 12 13 browser = await Puppeteer.LaunchAsync(options);
本文示例代码
GitHub - zhaotianff/PuppeteerDemo: 博客园Puppeteer-Sharp使用示例代码
如果在使用过程中,遇到了问题,可以提个issue给我。
更加详细的Puppeteer使用教程以及爬虫相关知识,可以访问我的github












![【upload]-ini-[SUCTF 2019]CheckIn-笔记](https://i-blog.csdnimg.cn/direct/fe715a6b2f60466db9f1c2dad99c36c7.png)