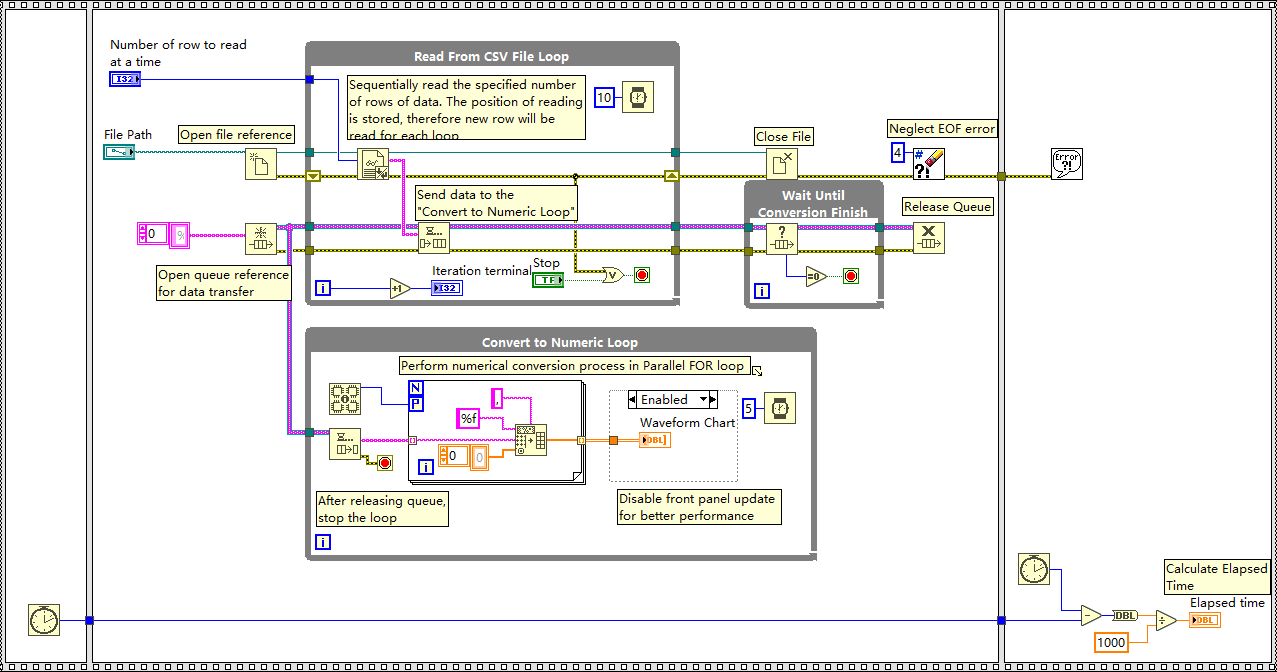
前言:目标检测 | yolov5 原理和介绍
后续:
1.简介
YOLOv6是由美团视觉智能部研发的一款目标检测框架,专注于工业应用,致力于提供极致的检测精度和推理效率。相较于YOLOv4和YOLOv5,YOLOv6在网络结构方面进行了深入优化,提升了模型的检测精度,并在处理复杂场景时更加稳健。同时,YOLOv6还在保持高效性的基础上,减少了模型的参数量,适合在移动端等计算资源有限的设备上运行。
YOLOv6的改进包括采用轻量级的卷积模块和引入注意力机制,更好地捕捉图像中的关键信息。它还针对小目标检测问题进行了优化,改进了锚框的生成方式,适应不同尺寸的目标。YOLOv6在实际应用中,如自动驾驶和安防监控领域,展现出强大的潜力。
此外,YOLOv6的设计考虑了硬件感知神经网络,采用了RepVGG-style结构,设计了EfficientRep Backbone和Rep-PAN Neck,以及Efficient Decoupled Head,进一步降低延时并提升精度
。它还引入了SimOTA算法动态分配正样本,以及SIoU边界框回归损失函数来提升检测精度。
YOLOv6的不同版本,如YOLOv6-nano、YOLOv6-tiny、YOLOv6-s、YOLOv6-m、YOLOv6-l和YOLOv6-l6,提供了不同精度和速度的平衡,满足不同计算需求和应用场景。例如,YOLOv6-nano在COCO数据集上达到35.0% AP的精度,同时在T4上推理速度可达1242 FPS。
YOLOv6的开源代码可在GitHub上找到,项目已经开源,方便社区成员使用和贡献代码。它的出现是对YOLO系列的一次重大更新,为实时应用提供了一个热门的选择,具有显著的架构增强功能,如双向串联(BiC)模块和锚点辅助训练(AAT)策略。
论文:https://arxiv.org/abs/2209.02976
代码:https://github.com/meituan/YOLOv6
1.1 引言
(1)来自RepVGG的重参数化是一种优越的技术,在检测(已有的yolo版本)中尚未得到很好的利用。同时,作者认为小型网络和大型网络的设计不一样,对大型网络来说,对RepVGG块进行简单地模型缩放不切实际
(2)基于重参数化的检测器的量化需要细致的处理
(3)以前的工作往往不太关注部署,其延迟通常在 V100 等高成本机器上进行比较。在实际服务环境方面存在硬件差距
(4)标签分配和损失函数设计,需要进一步验证考虑架构的差异
(5)对于部署,训练过程可以使用知识蒸馏等策略,但不增加推理成本
2. 方法
YOLOv6的重新设计由以下部分组成,网络设计、标签分配、损失函数、数据增强、适合工业界的改进,以及量化和部署:
- 网络设计:Backbone:与其他主流架构相比,我们发现RepVGG[3]骨干网络在推理速度相近的情况下,在小型网络中具备更多的特征表示能力,而由于参数和计算成本的爆炸性增长,它很难被扩展以获得更大的模型。在这方面,我们把RepBlock[3]作为我们小型网络的构建模块。对于大型模型,我们修改了一个更有效的CSP[43]块,名为CSPStackRep块。Neck:YOLOv6的颈部采用了YOLOv4和YOLOv5之后的PAN拓扑结构[24]。我们用RepBlocks或CSPStackRep Blocks来增强颈部,以实现Rep-PAN。Head:我们简化了解耦头,使其更加有效,称为高效解耦头。
- 标签的分配:我们通过大量的实验评估了最近在YOLOv6上的标签分配策略[5, 7, 18, 48, 51]的进展,结果表明TAL[5]更加有效和 训练友好。
- 损失函数:主流anchor-free目标检测器的损失函数包含分类损失、box回归损失和object损失。对于每个损失,我们用所有可用的技术进行了系统的实验,最后选择VariFocal损失[50]作为我们的分类损失,SIoU[8]/GIoU[35]损失作为我们的回归损失。
- 适合工业界的改进:我们引入了更多常见的做法和技巧来提高性能,包括自我蒸馏和更多的训练epoch。对于自蒸馏,分类和回归都分别由教师模型进行监督。回归的蒸馏是由于DFL[20]而实现的。此外,软标签和硬标签的信息比例通过余弦衰减动态下降,这有助于学生在训练过程中的不同阶段选择性地获取知识。此外,我们还遇到了在评估时不添加额外的灰边而导致性能受损的问题,对此我们提供了一些补救措施。我们提供了一些补救措施。
- 量化和部署:为了解决基于重新参数化的模型量化时的性能下降问题,我们用RepOptimizer[2]训练YOLOv6,以获得PTQ友好的权重。我们进一步采用QAT与信道精馏[36]和图优化来追求极致的性能。我们的量化YOLOv6-S以42.3%的AP和869 FPS的吞吐量(批次大小=32)达到了一个新的技术水平。
2.1 网络设计
一个单阶段目标检测器一般由以下部分组成:backbone、neck和head。主干部分主要决定了特征表示能力,同时,由于它承载了很大一部分计算成本,所以它的设计对推理效率有关键影响。neck用于将低层次的物理特征与高层次的语义特征聚合在一起,然后在各个层次建立金字塔特征图。头部由几个卷积层组成,它根据neck集合的多层次特征预测最终的检测结果。从结构上看,它可以分为 anchor-based 和 anchor-free的,或者说是参数耦合头和参数解耦头。
在YOLOv6中,基于硬件友好型网络设计的原则[3],我们提出了两个可扩展的可重新参数化的骨干和颈部,以适应不同规模的模型,以及一个高效的混合通道策略的解耦头。

2.1.1 主干网络
如上所述,骨干网络的设计对检测模型的有效性和效率有很大影响。以前的研究表明,多分支网络[13, 14, 38, 39]往往能比单路径网络[15, 37]取得更好的分类性能,但往往伴随着并行性的降低,导致推理延迟的增加。相反,像VGG[37]这样的普通单路径网络具有高并行性和较少内存占用的优势,导致更高的推理效率。最近在RepVGG[3]中,提出了一种结构上的重新参数化方法,将训练时的多分支拓扑结构与推理时的普通结构解耦,以实现更好的速度-准确度权衡。
受上述工作的启发, 我们设计了一个高效的可重参数化骨干网, 命名为EfficientRep. 对于小型模型, 骨干网的主要组成部分是训练阶段的Rep-Block, 如图3(a)所示. 在推理阶段,每个RepBlock被转换为具有ReLU激活函数的 3 × 3 3×3 3×3卷积层(表示为RepConv),如图3(b)所示。通常情况下, 3 × 3 3×3 3×3卷积在主流的GPU和CPU上被高度优化,它享有更高的计算密度。因此,EfficientRep Backbone充分地利用了硬件的计算能力,使推理的延迟大大降低,同时提高了表示能力。
然而,我们注意到,随着模型容量的进一步扩大,单路径简单网络的计算成本和参数数量呈指数级增长。为了在计算负担和准确性之间实现更好的权衡,我们修改了一个CSPStackRep块来构建大中型网络的主干。如图3(c)所示,CSPStackRep Block由三个 1 × 1 1×1 1×1的卷积层和一个由两个RepVGG块[3]或RepConv(分别在训练或推理时)组成的堆栈子块与一个剩余连接组成。此外,还采用了跨阶段部分(CSP)连接来提高性能,而没有过多的计算成本。与CSPRepResStage[45]相比,它有一个更简洁的前景,并考虑了准确性和速度之间的平衡。
设计了一个高效的可重新参数化的骨干,称为EffificientRep
在小模型(n/t/s) 中,使用RepBlock
在大模型(m/l) 中,使用CSPStackRep Blocks
2.1.2 Neck 颈部
在实践中,多尺度的特征整合已被证明是目标检测的一个关键和有效的部分[9, 21, 24, 40]。我们采用YOLOv4[1]和YOLOv5[10]中修改的PAN拓扑结构[24]作为我们检测颈部的基础。此外,我们用RepBlock(用于小模型)或CSPStackRep Block(用于大模型)取代YOLOv5中使用的CSPBlock,并相应调整宽度和深度。YOLOv6的颈部被表示为Rep-PAN。

下图为Rep-PAN

2.1.3 Head部分
高效的解耦头 YOLOv5的检测头是一个耦合头,其参数在分类和定位分支之间共享,而其在FCOS[41]和YOLOX[7]中的同类产品则将这两个分支解耦,并且在每个分支中引入额外的两个 3 × 3 3×3 3×3卷积层以提高性能。在YOLOv6中,我们采用混合通道策略来建立一个更有效的解耦头。具体来说,我们将中间的 3 × 3 3×3 3×3卷积层的数量减少到只有一个。头部的宽度由骨干和颈部的宽度乘数共同缩放。这些修改进一步降低了计算成本,以实现更低的推理延迟。

Anchor-free
Anchor-free检测器因其更好的泛化能力和解码预测结果的简单性而脱颖而出。其后期处理的时间成本大大降低。有两种类型的Anchor-free检测器:基于锚点[7, 41]和基于关键点[16, 46, 53]。在YOLOv6中,我们采用了基于锚点的范式,其回归分支实际上预测了从锚点到box四边的距离。
point-base ( FCOS) ——YOLOv6使用的
keypoint-based ( CornerNet)
2.2 Label Assignment标签分配
- SimOTA
SimOTA OTA[6]认为物体检测中的标签分配是一个最优传输问题。它从全局的角度为每个ground-truth目标定义了正/负的训练样本。SimOTA[7]是OTA[6]的简化版本,它减少了额外的超参数并保持了性能。在YOLOv6的早期版本中,SimOTA被用作标签分配方法。然而,在实践中,我们发现引入SimOTA会减慢训练过程。而且,陷入不稳定的训练也并不罕见。因此,我们渴望有一个替代SimOTA的方法。
①计算成对预测框与真值框代价,由分类及回归loss构成
②计算真值框与前k个预测框IoU,其和为Dynamic k;因此对于不同真值框,其Dynamic k存在差异
③最后选择代价最小的前Dynamic k个预测框作为正样本
- Task alignment learning 任务对齐学习
任务对齐学习 任务对齐学习(TAL)最早是在TOOD[5]中提出的,其中设计了一个统一的分类分数和预测框质量的指标。IoU被这个度量所取代,用于分配对象标签。在一定程度上,任务(分类和箱体回归)不一致的问题得到了缓解。
TOOD的另一个主要贡献是关于任务对齐的头(T-head)。T-head堆叠卷积层以建立交互式特征,在此基础上使用任务对齐预测器(TAP)。PP-YOLOE[45]改进了T-head,用轻量级的ESE注意力取代了T-head中的层注意力,形成ET-head。然而,我们发现ET-head在我们的模型中会降低推理速度,而且没有准确性的提高。
因此,我们保留了Efficient解耦头的设计。此外,我们观察到TAL比SimOTA能带来更多的性能提升,并且能稳定训练。因此,我们在YOLOv6中采用TAL作为默认的标签分配策略。
①在各个特征层计算gt与预测框IoU及与分类得分乘积作为score,进行分类检测任务对齐
②对于每个gt选择top-k个最大的score对应bbox
③选取bbox所使用anchor的中心落在gt内的为正样本
④若一个anchor box对应多个gt,则选择gt与预测框IoU最大那个预测框对应anchor负责该gt
2.3 Loss Functions 损失函数
2.3.1 Classification Loss 分类损失
提高分类器的性能是优化检测器的一个关键部分。Focal Loss[22]修改了传统的交叉熵损失,以解决正负样本之间或难易样本之间类别不平衡的问题。为了解决训练和推理之间质量估计和分类的不一致使用问题,质量Focal Loss(QFL)[20]进一步扩展了Focal Loss,对分类分数和分类监督的定位质量进行联合表示。而VariFocal Loss(VFL)[50]则源于Focal Loss[22],但它对正负样本的处理是不对称的。通过考虑正负样本的不同重要程度,它平衡了来自两个样本的学习信号。Poly Loss[17]将常用的分类损失分解为一系列的加权多项式基数。它在不同的任务和数据集上调整多项式系数,通过实验证明它比交叉熵损失和Focal Loss更好。
我们在YOLOv6上评估了所有这些高级分类损失,最终采用了VFL[50]。
VariFocal Loss (VFL) :提出了非对称的加权操作
VariFocal Loss是从Focal Loss而来,所以我们要首先了解Focal Loss。Focal Loss提出来要解决的问题是训练数据中,正负样本不均衡的问题。 何为正负样本不均衡?比如说,我们训练的图片样本,尤其是包含很多小目标的图片样本,其实要检测的目标(也就是我们说的正样本)只占图片区域的少部分(综合来看),大部分的区域则为背景区域(也就是我们说的负样本);这就会导致训练数据负样本占多,而正样本相对来说占少数,模型的训练效果会变差,Focal Loss给难分、易分样本加上权重因子,提升难分样本的权重,降低易分样本的权重,从而控制正负样本均衡的问题,其中背景类一般为易分样本,而目标类为难分样本。 同时,Focal Loss适合检测密集型目标的图片样本,这个对小尺寸、拥挤、遮挡等特点的数据集会有不错的效果。
VariFocal Loss是在Focal Loss的基础上提出的,因为Focal Loss对正负样本的处理是均衡的,而varifocal loss仅减少了负样本的损失贡献,而不以同样的方式降低正样本的权重。
这里的IACS是IoU-aware classification score的缩写。VFL原文里面这个target socre也就是q,是一个和IOU有关的软标签。对于挑选出的正样本(也就是和GT相交的样本)的分类标签分数不再是0、1两个极端,而是与IOU有关的标签q,这样的好处在于:比如IOU很大,标签就是0.9,IOU很小,标签就是0.1,直觉上也更有道理。
当q>0时,VFL对于正样本没有超参,也就是没有任何衰减;而当q=0时,VFL对于负样本是有超参项的,gama会减少负样本贡献,alpha是为了防止过度抑制,总体来说是会减少负样本的贡献的。这就是和focal loss的不同之处,focal loss两项都有超参,正样本的质量也是会被降低的。

2.3.2 Box Regression Loss 回归框损失
回归损失提供了精确定位box边界的重要学习信号。L1损失是早期工作中最初的回归损失。逐渐地,各种精心设计的回归损失涌现出来,如IoU系列损失[8, 11, 35, 47, 52, 52] 和概率损失[20]。
IoU-系列损失 IoU损失[47]将预测框的四个边界作为一个整体单位进行回归。它被证明是有效的,因为它与评价指标一致。IoU有很多变体,如GIoU[35]、DIoU[52]、CIoU[52]、α-IoU[11]和SIoU[8]等,形成相关损失函数。在这项工作中,我们用GIoU、CIoU和SIoU进行实验。而SIoU被应用于YOLOv6-N和YOLOv6-T,而其他的则使用GIoU。
概率损失 Distribution Focal Loss(DFL)[20]将连续分布的box位置简化为离散的概率分布。它考虑了数据的模糊性和不确定性,而没有引入任何其他强的先验因素,这有助于提高box的定位精度,特别是当ground-truth boxes模糊时。在DFL的基础上,DFLv2[19]开发了一个轻量级的子网络,以利用分布统计和实际定位质量之间的密切关联,这进一步提高了检测性能。然而,DFL通常比一般的目标框回归多输出17倍的回归值,导致了大量的开销。额外的计算成本大大阻碍了小模型的训练。而DFLv2由于有了额外的子网络,进一步增加了计算负担。在我们的实验中,DFLv2在我们的模型上带来了与DFL相似的 在我们的模型上,DFLv2带来的性能增益与DFL相似。因此,我们 只在YOLOv6-M/L中采用DFL。实验细节可以在可在第3.3.3节中找到。
SIoU Loss在小模型上提升明显, GIoU Loss在大模型上提升明显,因此选择SIoU (for n/t/s) /GIoU (for m/l) 损失作为回归损失。
Distribution Focal Loss (DFL) 和 Distribution Focal Loss (DFL) v2可以带来一定的性能提升,但是对效率影响较大,因此弃用。
2.3.3 Object Loss 目标损失
物体损失最早是在FCOS[41]中提出的,用于降低低质量bounding boxes的得分,以便在后期处理中过滤掉它们。它也被用于YOLOX[7],以加速收敛并提高网络精度。作为一个像FCOS和YOLOX一样的anchor-free框架,我们已经在YOLOv6中尝试了object loss。不太幸运的是,它并没有带来很多好的效果。详细情况在第3节中给出。
2.4. Industry-handy improvements 工业界处理改进
2.4.1 More training epochs 更多的训练epoch
经验结果表明,随着训练时间的增加,检测器的性能也在不断进步。我们将训练时间从300 epochs延长到400 epochs,以达到一个更好的收敛性。
2.4.2 Self-distillation 自蒸馏
为了进一步提高模型的准确性,同时不引入太多的额外计算成本,我们应用经典的知识蒸馏技术,使教师和学生的预测之间的KL-散度最小。我们把老师限定为学生本身,但进行了预训练,因此我们称之为自我蒸馏。请注意,KL-散度通常被用来衡量数据分布之间的差异。然而,在目标检测中有两个子任务,其中只有分类任务可以直接利用基于KL-散度的知识提炼。由于DFL损失[20]的存在,我们也可以在box回归上执行它。知识提炼损失 可以被表述为:
L K D = K L ( p t c l s ∣ ∣ p s c l s ) + K L ( p t r e g ∣ ∣ p s r e g ) L_{KD} = KL(p^{cls}_t || p_s^{cls} ) + KL(p_t^{reg} || p_s^{reg} ) LKD=KL(ptcls∣∣pscls)+KL(ptreg∣∣psreg),
其中p cls t和p s分别是教师模型和学生模型的班级预测,相应地p reg t和p reg是盒式回归预测。现在,总体损失s函数被表述为:
L t o t a l = L d e t + α L K D L_{total} = L_{det} + αL_{KD} Ltotal=Ldet+αLKD ,
其中 L d e t L_{det} Ldet是用预测和标签计算的检测损失。引入超参数 α α α是为了平衡两种损失。在训练的早期阶段,教师的软标签更容易学习。随着训练的继续,学生的表现将与教师相匹配,因此硬标签将更多地帮助学生。在此基础上,我们对 α α α应用余弦权重衰减来动态调整来自硬标签和来自教师的软标签的信息。我们进行了详细的实验来验证YOLOv6的自我蒸馏的效果,这将在第3节讨论。
2.4.3 Gray border of images 图像灰色边界
我们注意到,在评价YOLOv5[10]和YOLOv7[42]的实现中的模型性能时,每个图像周围都有一个半截灰色的边框。虽然没有增加有用的信息,但它有助于检测图像边缘附近的物体。这个技巧也适用于YOLOv6。然而,额外的灰色像素显然会降低推理速度。没有灰色边界,YOLOv6的性能就会下降,这也是[10, 42]的情况。我们推测,这个问题与Mosaic增强中的灰边填充有关[1, 10]。为了验证,我们进行了在最后一个epoch中关闭马赛克增强的实验[7](又称淡化策略)。在这方面,我们改变了灰色边框的面积,并将带有灰色边框的图像直接调整为目标图像的大小。结合这两种策略,我们的模型可以在不降低推理速度的情况下保持甚至提高性能。推理速度。
2.5. Quantization and Deployment 量化和部署
RepOptimizer[2]在每个优化步骤中提出梯度重新参数化。该技术也能很好地解决了基于再参数化的模型的量化问题。因此,我们以这种方式重建了YOLOv6的重新参数化块,并使用重新优化器对其进行训练,以获得对PTQ友好的权值。特征图的分布很窄(如图4,B.1),这大大有利于量化过程,结果见第3.5.1节。

2.5.2 Sensitivity Analysis 敏感度
我们通过将量化敏感操作部分转换为浮点计算,进一步提高了PTQ的性能。为了获得灵敏度分布,我们常用了几个指标,即均方误差(MSE)、信噪比(SNR)和余弦相似度。通常,为了进行比较,可以选择输出特征映射(在激活某一层之后)来计算有量化和没有量化的这些度量。作为一种替代方法,它也可以通过开关特定层[29]的量化来计算验证AP。
我们在使用重新优化器训练的YOLOv6-S模型上计算所有这些指标,并选择前6个敏感层,以浮动形式运行。敏感性分析的完整图表见B.2。

2.5.3 Quantization-aware Training with Channel-wise Distillation 基于通道蒸馏的量化感知训练
在PTQ不足的情况下,我们建议涉及量化感知训练(QAT)来提高量化性能。为了解决在训练和推理过程中假量化器的不一致性问题,有必要在重新优化器上建立QAT。此外,在YOLOv6框架内采用了通道蒸馏[36](后来称为CW蒸馏),如图5所示。这也是一种自蒸馏的方法,其中教师网络是在fp32精度上的学生模型。参见第3.5.1节中的实验。

3. 实验
3.1 Implementation Details 实施细节
我们使用与YOLOv5 [10]相同的优化器和学习时间表,i.即具有动量和学习率余弦衰减的随机梯度下降(SGD)。还利用了预热、分组权重衰减策略和指数移动平均(EMA)。我们采用了两个强数据增强(Mosaic [1,10]和Mixup [49])[1,7,10]。超参数设置的完整列表可以在我们发布的代码中找到。我们在COCO 2017 [23]训练集上训练我们的模型,并在COCO 2017验证集上评估准确性。我们所有的模型都在8个NVIDIA A100 GPU上进行训练,速度性能在配备TensorRT版本7的NVIDIA Tesla T4 GPU上进行测量。2除非另有说明。还有速度使用其他TensorRT版本或其他设备测量的性能在附录A中演示。
3.2 Comparisons 对照实验
考虑到这项工作的目标是为工业应用构建网络,我们主要关注部署后所有模型的速度性能,包括吞吐量(批量大小为1或32的FPS)和GPU延迟,而不是FLOPs或参数数量。我们将YOLOv 6与YOLO系列的其他最先进的探测器进行了比较,包括YOLOv 5 [10],YOLOX [7],PPYOLOE [45]和YOLOv 7 [42]。请注意,我们使用TensorRT在相同的Tesla T4 GPU上测试了所有官方型号的FP 16精度的速度性能[28]。YOLOv 7-Tiny的性能根据其开源代码和输入大小为416和640的权重进行重新评估。结果示于表1和图2中。1.与YOLOv 5-N/YOLOv 7-Tiny(输入大小=416)相比,我们的YOLOv 6-N显著提高了7。9%/2.6%。在吞吐量和延迟方面,它还具有最佳的速度性能。与YOLOX-S/PPYOLOE-S相比,YOLOv 6-S可使AP提高3.0%/0.4%,速度更快。我们将YOLOv 5-S和YOLOv 7-Tiny(输入大小=640)与YOLOv 6-T进行比较,我们的方法是2。精度提高9%,批处理大小为1时,速度提高73/25 FPS。YOLOv 6-M的性能比YOLOv 5-M高4倍。2%的AP,在相同的速度下,实现了2.在更高的速度下,AP比YOLOX-M/PPYOLOE-M高7%/0.6%。此外,它比YOLOv 5-L更准确,更快。YOLOv 6-L为2。在相同的延迟限制下,比YOLOX-L/PPYLOE-L准确8%/1.1%。我们还通过用ReLU替换SiLU(表示为YOLOv 6-L-ReLU)来提供YOLOv 6-L的更快版本。达到51。7%AP,延迟为8.8 ms,在精度和速度上均优于YOLOX-L/PPYOLOE-L/YOLOv 7。

(1)相比 YOLOv5-N/YOLOv7-Tiny (input size=416) ,YOLOv6-N 分别提升了 7.9% 和2.6% ,也达到了最高的速度
(2)相比 YOLOX-S/PPYOLOE-S, YOLOv6-S 分别提升了 3.0% 和 0.4%
(3)相比 YOLOv5-S 和 YOLOv7-Tiny (input size=640) ,YOLOv6-M 在同等速度的情况下高了4.2% AP
(4)相比 YOLOX-M/PPYOLOE-M ,YOLOv6-M 更快,且分别高了 2.7% 和 0.6% AP
(5)相比 YOLOX-L/PPYOLOE-L/YOLOv7 ,YOLOv6-L-Relu 达到了 51.7% AP,超越了前面几个方法

3.3 Ablation Study 消融实验
3.3.1 Network
- Backbone and neck
主干和颈部我们探讨了单路径结构和多分支结构对主干和颈部的影响,以及CSPStackRep Block的信道系数(表示为CC)。本部分描述的所有模型均采用TAL作为标签分配策略,VFL作为分类损失,GIoU和DFL作为回归损失。结果示于表2中。我们发现,在不同规模的模型的最佳网络结构应该拿出不同的解决方案。对于YOLOv 6-N,单路径结构在精度和速度方面优于多分支结构。
由于相对较低的存储器占用和较高的并行度,因此运行得更快。对于YOLOv 6-S,两种块样式带来相似的性能。当涉及到较大的模型,多分支结构实现更好的性能,在准确性和速度。并且我们最终选择多分支,其中对于YOLOv 6-M具有2/3的信道系数,并且对于YOLOv 6-L具有1/2的信道系数。此外,我们研究了颈部的宽度和深度对YOLOv 6-L的影响。表3中的结果显示细长颈部执行0.2%,比宽浅颈在相同的速度。

不同网络结构适用不同策略
- Combinations of convolutional layers and activation 卷积层和激活函数组合
YOLO系列采用了广泛的激活函数,ReLU [27],LReLU [25],Swish [31],SiLU [4],Mish [26]等。在这些激活函数中,SiLU是使用最多的。一般来说,SiLU具有更好的准确性,并且不会导致太多额外的计算成本。然而,当涉及到工业应用时,特别是部署具有TensorRT [28]加速的模型时,ReLU由于融合到卷积中而具有更大的速度优势。此外,我们进一步验证了RepConv/普通卷积(表示为Conv)和ReLU/SiLU/LReLU在不同规模的网络中的组合的有效性,以实现更好的权衡。如表4所示,具有SiLU的Conv在准确性方面表现最好,而RepConv和ReLU的组合实现了更好的折衷。我们建议用户在延迟敏感的应用程序中采用ReLU的RepConv。我们选择使用RepConv/ReLU组合.

(1)Conv+SiLU性能最佳,但RepConv+ReLU达到性能与速度均衡
(2)在YOLOv6-N/T/S/M中使用RepConv/ReLU组合来获得更高的推理速度
(3)在大型模型YOLOv6-L中使用Conv/SiLU组合来加速训练和提高性能。
- Miscellaneous design 其余设计
我们还对第2节中提到的其他网络部分进行了一系列消融。1基于YOLOv 6-N。我们选择YOLOv 5-N作为基线,并逐步添加其他组件。结果示于表5中。首先,对于解耦头(表示为DH),我们的模型是1。精确度提高4%,时间成本增加5%。其次,我们验证了无锚范式比基于锚的范式快51%,因为它的3倍少的预定义锚,这导致输出的维数更少。此外,表示为EB+RN的骨架(EfficientRep骨架)和颈部(Rep-PAN颈部)的统一修饰带来3。6%的AP改进,运行速度提高21%。最后,优化的解耦头(混合通道,HC)带来0。2%AP和6.FPS的准确性和速度分别提高了8%。

DH: 以YOLOv5-N为基线,验证YOLOv6-N中不同部件影响,使用解耦头(DH)性能提升1.4%,耗时增加5%
AF: Anchor-free方案耗时降低51%
EB+RN: 主干网络EfficientRep +颈部Rep-PAN 使得性能提升3.6%,耗时降低21%
HC: Head中混合通道策略,使得性能提升0.2%,耗时降低6.8%
3.3.2 Label Assignment 标签分配
在表6中,我们分析了主流标签分配策略的有效性。在YOLOv6N上进行实验。如预期的,我们观察到SimOTA和TAL是最好的两个策略与ATSS相比,SimOTA可以提高AP 2.0%,TAL带来AP比SimOTA高0.5%。考虑到TAL的稳定训练和更好的准确性能,我们采用TAL作为我们的标签分配策略。此外,TOOD [5]的实现采用ATSS [51]作为早期训练时期的预热标签分配策略。我们还保留了热身策略,并对其进行了进一步的探索。详细信息如表7所示,我们可以发现,在没有预热或通过其他策略预热的情况下(即:例如,SimOTA)也可以实现类似的性能.
3.3.3 Loss functions 损失函数
在目标检测框架中,损失函数是由分类损失、Box回归损失和可选对象损失,其公式如下
L d e t = L c l s + λ L r e g + μ L o b j L_{det} = L_{cls} + λL_{reg}+μL_{obj} Ldet=Lcls+λLreg+μLobj
其中 L c l s L_{cls} Lcls、 L r e g L_{reg} Lreg和 L o b j L_{obj} Lobj是分类损失、回归损失和物体损失。 λ λ λ和 µ µ µ是超参数。
- Classification Loss 分类损失
分类损失:我们在YOLOv 6-N/S/M上实验了Focal Loss [22]、Poly loss [17]、QFL [20]和VFL [50]。从表8中可以看出,VFL带来0。与局灶性丢失相比,YOLOv 6-N/S/M的AP改善分别为2%/0.3%/0.1%。我们选择VFL作为分类损失函数。

- Regression Loss— 回归损失
在YOLOv 6-N/S/M上对回归损失IoU序列和概率损失函数进行了实验。YOLOv 6 N/S/M采用了最新的IoU系列损耗。表9中的实验结果显示,对于YOLOv 6-N和YOLOv 6-T,SIoU损失优于其他损失,而CIoU损失在YOLOv 6-M上表现更好。对于概率损失,如表10所列,引入DFL可以获得0。YOLOv 6-N/S/M的性能增益分别为2%/0.1%/0.2%。然而,对于小模型,推理速度受到很大影响。因此,仅在YOLOv 6-M/L中引入DFL。

(1)关于IoU系列损失:YOLOv6-N及YOLOv6-T使用SIoU损失,其余使用GIoU损失
(2)关于概率损失:YOLOv6-M/L使用DFL,其余未使用 - Object Loss 目标损失
如表11所示,还用YOLOv 6实验物体损失。从表11中,我们可以看到对象丢失对YOLOv 6-N/S/M网络有负面影响,其中最大减少为1。YOLOv 6-N上的1% AP。负增益可能来自目标分支与TAL中的其他两个分支之间的冲突。具体来说,在训练阶段,预测框和地面实况框之间的IoU以及分类得分用于联合构建度量作为分配标签的标准。但是,引入的对象分支将要对齐的任务数量从两个扩展到三个,这显然增加了难度。基于实验结果和该分析,然后在YOLOv6中丢弃对象丢失。

YOLOv6-N/S/M中目标损失都降低了效果;作者选择丢弃
原因:负增益可能来自于TAL中对象分支和其他两个分支之间的冲突,TAL中将IoU与分类联合作为,额外引入一分支导致两分支对齐变为三分支,增加对齐难度
3.4 Industry-handy improvements
省略
3.5. Quantization Results
3.5.1 PTQ
当使用RepOptimizer训练模型时,平均性能得到了显著提高,请参见表15。RepOptimizer通常更快,几乎相同

3.5.2 QAT
对于v1.0,我们将伪量化器应用于从第2.5.2节获得的非敏感层,以执行量化感知训练,并将其称为部分QAT。我们将结果与表16中的完整QAT进行了比较。部分QAT可以提高精度,但吞吐量略有降低。
由于在2.0版本中移除了量化敏感层,我们直接在YOLOv6-S上使用了完整的QAT。

使用RepOptimizer进行培训。我们通过图优化来消除插入的量化器,以获得更高的精度和更快的速度。我们在表17中比较了PaddleSlim[30]的基于蒸馏的量化结果。请注意,YOLOv6-S的量化版本是最快、最准确的,也见图1。

4 Conclusion 结论
简而言之,考虑到持续的工业要求,我们提出了YOLOv6的当前形式,仔细检查了迄今为止物体探测器组件的所有进步,同时灌输了我们的思想和实践。该结果在精度和速度上都超过了其他可用的实时探测器。为了便于工业部署,我们还为YOLOv6提供了一种定制的量化方法,使探测器开箱即用。我们衷心感谢学术界和工业界的精彩想法和努力。未来,我们将继续扩大这个项目,以满足更高的标准和更苛刻的场景。