PUMA: Efficient Continual Graph Learning with Graph Condensation
PUMA:通过图压缩进行高效的连续图学习
ABSTRACT
在处理流图时,现有的图表示学习模型会遇到灾难性的遗忘问题,当使用新传入的图进行学习时,先前学习的这些模型的知识很容易被覆盖。作为回应,持续图学习(CGL)作为一种新颖的范式出现,能够实现从静态图到流图的图表示学习。我们之前的工作 Condense and Train (CaT)是一个基于重放的 CGL 框架,具有平衡的持续学习过程,它设计了一个小而有效的内存库,用于通过压缩传入的图来重放数据。尽管CaT缓解了灾难性遗忘问题,但仍存在三个问题:(1)CaT中推导的图压缩算法仅关注标记节点,而忽略了未标记节点携带的丰富信息;(2)CaT的持续训练方案过分强调先前学到的知识,限制了模型从新添加的记忆中学习的能力;(3)CaT的压缩过程和重放过程都很耗时。 在本文中,我们提出了一种 PsUdo 标签引导记忆库(PUMA)CGL 框架,该框架从 CaT 扩展而来,通过克服上述弱点和限制来提高其效率和有效性。为了充分利用图中的信息,PUMA 在图压缩期间使用标记和未标记的节点扩展了节点的覆盖范围。此外,提出了一种从头开始的训练策略来升级之前的持续学习方案,以实现历史图和新图之间的平衡训练。此外,PUMA使用一次性prorogation和宽图编码器来加速训练阶段的图压缩和图编码过程,以提高整个框架的效率。 对四个数据集的广泛实验证明了现有方法的最先进的性能和效率。 代码已发布于https://github.com/superallen13/PUMA。
1 INTRODUCTION
首PUMA框架开发了一种伪标记来整合来自未标记节点的数据,增强了记忆库的信息量,解决了被忽视的未标记节点的问题。 其次,针对历史知识僵化的问题,设计了再培训策略。 这涉及在重放之前初始化整个模型,以平衡不同任务之间学到的知识,以获得更有效的决策边界,并确保更稳定的学习过程。最后,通过一次性传播方法简化了压缩过程中的重复消息传递计算,该方法一次性聚合整个传入图上相邻节点的消息,并且可以存储以供重复使用,从而显着减少了计算量。此外,还开发了包含更多神经元的宽图编码器来加速压缩过程中的收敛,从而提高压缩记忆的更新效率。最后,为了提高 CGL 模型的训练效率,提出了用多层感知器(MLP)来代替消息传递 GNN 的训练。由于其无边性质,PUMA 使 MLP 能够学习特征提取,并利用 GNN 来推断具有边缘的图。这些解决方案共同增强了基于图压缩的 CGL 框架的功效和效率。
本文提出了一种新颖的 PUMA框架,该框架是从 CaT 方法扩展而来的,具有以下实质性的新贡献:
-
提出了一种伪标签引导记忆库,不仅可以利用全图中的信息来压缩标记节点,还可以压缩未标记节点。
-
在重播阶段设计了再训练策略,以缓解所学知识不平衡的问题,从而获得有希望的整体表现。
-
由于新开发的一次性传播、宽图编码器和带无边缘存储器的 MLP 训练等创新技术,压缩和训练速度显着提高,而不会影响性能。
-
对四个数据集进行了广泛的实验和深入的分析,展示了PUMA 的有效性和效率。
CGL问题有两种不同的连续设置,任务增量学习(task-IL)和类增量学习(class-IL)。在task-IL中,模型只需要区分同一任务中的节点。 在 class-IL 中,模型需要对所有任务中的节点进行分类。
4 METHODOLOGY
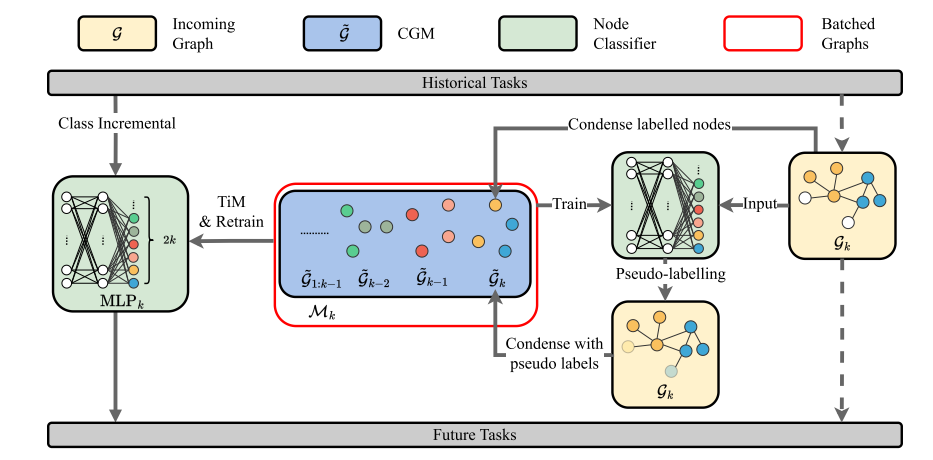
PUMA 首先考虑带有伪标签的未标记节点来压缩输入图。PUMA 更新后,模型将从头开始使用 PUMA 初始化所有权重和训练。
4.1 Fast Graph Condensation by Distribution Matching
基于压缩的内存库存储压缩的合成图以近似历史数据分布。开发了一种具有分布匹配的高效图压缩方法,旨在保持合成数据与原始数据相似的数据分布。该方法用作重放图生成。
对于任务 T K \mathcal{T}_{K} TK,输入图 G k = { A k , X k , Y k } \mathcal{G}_{k}=\{\mathbf{A}_{k},\mathbf{X}_{k},\mathbf{Y}_{k}\} Gk={Ak,Xk,Yk},通过图压缩生成无边压缩图 G ~ k = { X ~ k , Y ~ k } \tilde{\mathcal{G}}_{k}=\{\tilde{\boldsymbol{X}}_{k},\tilde{\boldsymbol{Y}}_{k}\} G~k={X~k,Y~k}。在分布匹配方案下,图压缩的目标函数:
G ~ k ∗ = arg min G ~ k D i s t ( G k , G ~ k ) , \tilde{\mathcal{G}}_k^*=\arg\min_{\tilde{\mathcal{G}}_k}\mathrm{Dist}(\mathcal{G}_k,\tilde{\mathcal{G}}_k), G~k∗=argG~kminDist(Gk,G~k),
为了有效地操作压缩过程,这里使用具有随机权重的特征编码器而无需训练。分布匹配的目标是最小化具有随机参数 θ p \theta_p θp 的 GNN 给出的不同嵌入空间中的嵌入距离:
min G ~ k ∑ θ p ∼ Θ ℓ M M D , θ p , \min_{{\tilde{\mathcal{G}}_{k}}}\sum_{{\theta_{p}\sim\Theta}}\ell_{{\mathrm{MMD},\theta_{p}}}, G~kminθp∼Θ∑ℓMMD,θp,
4.2 Pseudo Label-guided Edge-free Memory Bank
只有具有高置信度分数的伪标签才会被添加到分布匹配中。将来自分类器的节点 v v v 的 Logits 输入到 Softmax 函数中,以获得不同类的置信度分布:
c o n f i d e n c e ( v ) = max ( S o f t m a x ( A , X ) [ v , : ] ) ) . \mathrm{confidence}(v)=\max(\mathrm{Softmax}(\mathbf{A},\mathbf{X})_{[v,:]})). confidence(v)=max(Softmax(A,X)[v,:])).
在获得伪标签的置信度分数后,可以使用阈值来过滤掉更确定的伪标签以减少噪声标签。分布匹配算法可以利用扩大的训练集来精确浓缩。PUMA的整体流程如算法1所示。PUMA 包含无边图,可以有效地存储在内存中并由 MLP 模型进行训练。

4.3 Train in Memory from Scratch
在PUMA中,由于基于压缩的存储体能够在不影响性能的情况下减小图的大小,因此通过使用压缩的输入图而不是整个输入图来解决不平衡问题是合理的。当输入图 G k \mathcal G_k Gk到达时,首先生成压缩图 G ~ k \tilde{\mathcal G}_k G~k,然后用它来更新之前的记忆 M k − 1 \mathcal M_{k−1} Mk−1:
M k = M k − 1 ∪ G ~ k . \mathcal{M}_{k}=\mathcal{M}_{k-1}\cup\tilde{\mathcal{G}}_{k}. Mk=Mk−1∪G~k.
CaT 将基于 M k \mathcal M_k Mk 更新模型,而不是使用 M k − 1 \mathcal M_{k−1} Mk−1 和 G k \mathcal G_k Gk 进行训练来处理不平衡问题:
ℓ C a T = L ( M k ; θ k ) = L ( G ~ k ; θ k ) + L ( M k − 1 ; θ k ) . \begin{aligned}\ell_{\mathrm{CaT}}&=\mathcal{L}(\mathcal{M}_{k};\theta_{k})\\&=\mathcal{L}(\tilde{\mathcal{G}}_{k};\theta_{k})+\mathcal{L}(\mathcal{M}_{k-1};\theta_{k}).\end{aligned} ℓCaT=L(Mk;θk)=L(G~k;θk)+L(Mk−1;θk).
这个过程被称为内存训练(TiM),因为该模型仅使用内存库中重放的图进行训练。
另一方面,基于重播的持续学习模型通常会在新传入的图到达时不断更新其权重,而不是从头开始重新训练。这种训练方案可能会遇到损失不平衡的挑战,即新压缩图上的损失大于历史压缩图上的损失。
为了更好的优化,在学习形成新的记忆之前,每层的模型权重都会被重新初始化。CGL骨干模型的架构保持不变,例如在持续训练过程中隐藏层的数量和隐藏层的维度。
综上所述,所提出的CaT框架使用图压缩来生成小而有效的重放图,并应用TiM方案来解决CGL中的不平衡学习问题。PUMA的整体流程如算法2所示。

5 EXPERIMENTS
5.1 Setup
5.1.1 Datasets
使用了四个用于节点分类任务的数据集:CoraFull、Arxiv、Reddit 和Products。每个数据集被分为一系列专注于节点分类问题的任务。每个任务都包含两个唯一类的节点作为传入图。在每个任务中,选择 60% 的节点作为训练节点,20% 的节点用于验证,20% 的节点用于测试。
平均性能(AP)平均性能平均值(mAP)、后向迁移(BWT)
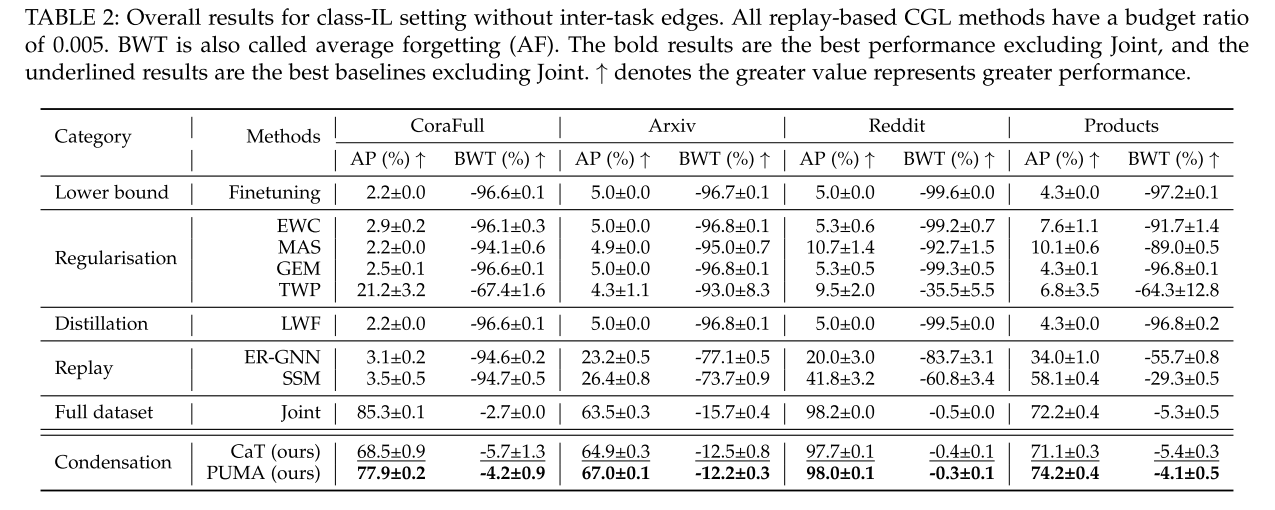
5.2 Overall Results
基于压缩的 CGL 方法与 class-IL 和 task-IL设置中的所有基线进行比较。AP用于评估任务流结束时所有学习任务的平均模型性能,BWT 暗示模型在持续学习过程中的遗忘问题。 表 2 显示了所有基线和 PUMA 在 class-IL设置中的整体性能。与所有其他 CGL 基线相比,CaT 实现了最先进的性能。此外,结果表明,基于压缩的记忆库具有较小的BWT,这意味着压缩不仅可以保留模型的历史知识,还可以在训练当前任务的同时减少对先前任务的负面影响,从而缓解灾难性遗忘问题。
5.3 Ablation Study
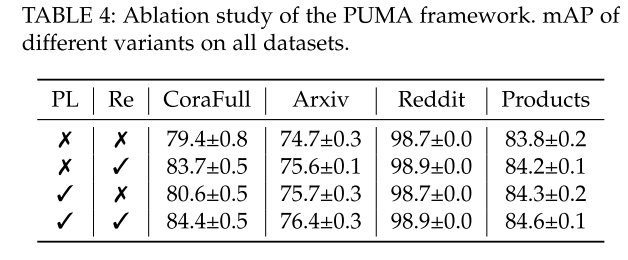
PUMA 框架有两个关键组件:伪标签引导记忆库和再训练。不带 PL 的变体表示在压缩过程中仅使用标记节点,不带 Re 的变体表示 CGL 模型根据先前任务的学习知识更新其权重。根据表 4,与没有这两种组件的变体相比,使用 PL 的变体提高了 AP 和 mAP。经过重新训练的变体也能提高整体性能。
5.4 Effectiveness and Efficiency of Condensation-based Memory Banks
5.4.1 Different Memory Banks
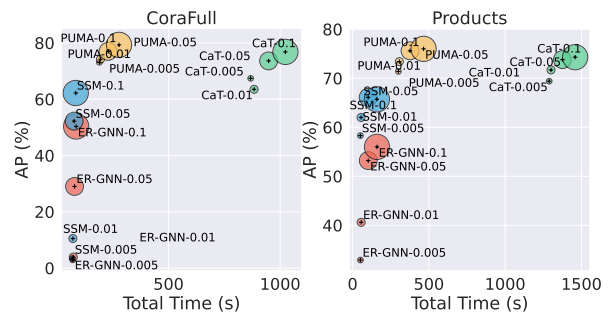
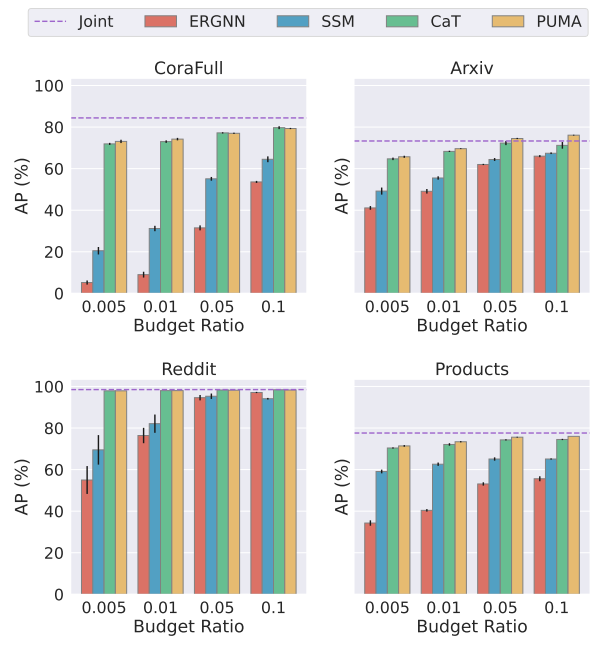
图 3 表明 PUMA 比现有的基于采样的存储体更有效。PUMA 更快地达到最佳性能。PUMA 在所有评估案例中均获得最佳表现。当预算比率相对较小(例如 0.005、0.01)时,PUMA 的性能显着优于其他基于采样的存储体。一方面,CaT和PUMA使用较少的内存空间来准确地近似历史数据分布。另一方面,在训练阶段,模型需要在记忆库中传播消息。因此,小的存储体可以提高存储和计算效率。
5.5 Balanced Learning with TiM
5.5.1 Different Methods with TiM
TiM 是一种即插即用的训练方案,适用于所有现有的基于重放的 CGL 方法。表 5 显示了使用和不使用 TiM 的不同基于重放的 CGL 方法的 mAP。TiM可以确保CGL模型的训练图具有相似的大小来处理不平衡问题,从而可以解决灾难性遗忘问题。

5.6 Effectiveness of Retraining
虽然TiM有效缓解了类训练样本不平衡的问题,但它在持续训练过程中引入了新的挑战:任务损失的不平衡。发生这种情况是因为之前添加到记忆库的记忆已经被充分学习,与后来添加的记忆相比,损失更小。为了缓解这个问题,提出了重新训练策略,从头开始训练内存中的 CGL 模型。
5.6.1 Effectiveness
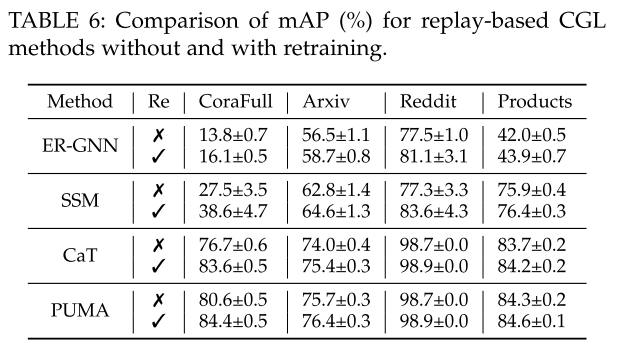
再训练有助于重新校准模型的知识和对新数据和现有数据的适应性,从而提高其整体性能。表 6 展示了没有和有重新训练的不同基于重放的方法的 mAP。
5.7 Condense More by Pseudo-Labelling
本研究评估了伪标签对基于重放的 CGL 方法(例如 ER-GNN、SSM、CaT 和 PUMA)准确性的影响。 比较涉及在记忆阶段有和没有整合伪标签的场景。表 7 显示了两种条件下不同 CGL 方法的 mAP。
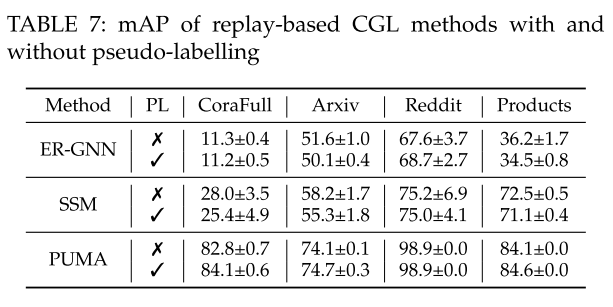
对于基于压缩的图存储器,结合伪标记被证明是有效的。但是伪标记技术对于当前基于采样的存储体并没有产生类似的好处。
5.8 Wide Graph Encoder
宽图编码器包含更多具有随机初始化权重的神经元,可以随机提取非线性特征。图 6 显示,减小由窄编码器生成的原始图嵌入和压缩图嵌入之间的距离是不够的,因为一旦编码器重新初始化,它们之间仍然存在明显的分布间隙。更宽的图形编码器可以缩小这一差距。
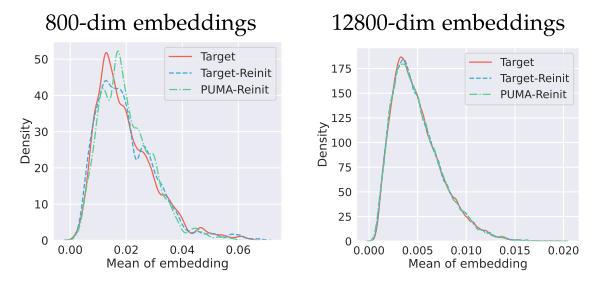
一次可以获得的神经元越多,原始数据在初始化空间中的潜在变换就越清晰,也就越容易通过不同的网络拟合数据的分布。数据的准确分布是必要的,因为在持续学习中,新的类不断出现,并且在回放过程中,模型需要重新学习不同类之间的决策边界。然而,更多的神经元花费更多的计算资源,实际中使用多个随机编码器。
5.9 Parameter Sensitivity
5.9.1 Different Dimensional Graph Encoders
该实验探索了图编码器的足够维度来优化 MMD 损失。图7显示了在持续学习过程中处理每个传入任务后,由各种维度图编码器生成的PUMA训练的模型的AP(%)。
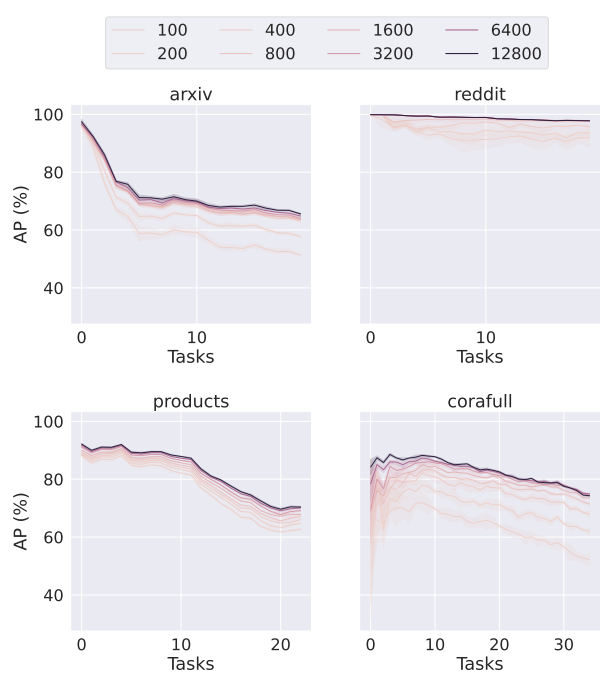
当编码器维度由于计算资源有限而受到限制时,由于模型的参数初始化空间不完整,模型性能会下降。随着图编码器维度的增加,CGL模型的性能得到了显着的提高。它表明,为了更好地覆盖模型参数的初始化空间,宽编码器是必不可少的。当计算资源有限时,使用更多随机的相对较小的图编码器也可以获得匹配的性能,但需要更多的压缩时间。
5.9.2 Neuron Activation
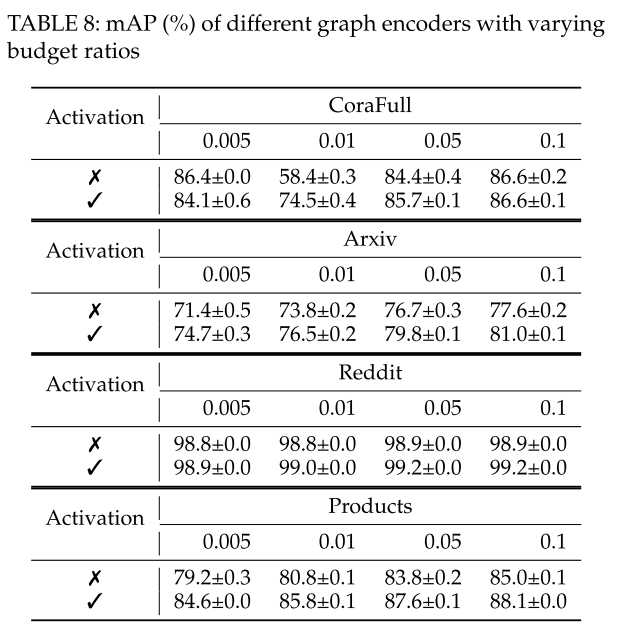
CGL 的标准节点分类仍将使用具有激活函数的编码器。mAP 用于衡量有效性。表 8 说明,对于不同的预算比率,具有激活函数的编码器对于整体图编码来说是更具竞争力的选择。
5.10 Time Efficiency
对于基于重放的 CGL 方法,内存生成和模型训练是需要计算资源的两个主要部分。对于基于采样的方法(例如 ER-GNN 和 SSM),内存生成过程非常高效。虽然基于采样的方法不能忽略图压缩时间,但模型精度比基于采样的方法要好得多。对于CaT,内存生成的主要计算成本是原始图中的特征聚合。PUMA的存储体是无边的,可以忽略训练阶段的特征聚合操作,每层的权重可以通过MLP模型来学习。