前言
如果按照本系列第一篇博客那样交叉编译了opencv,那本文有些步骤就不用了,比如交叉编译工具链的下载,所以自己斟酌步骤。
本系列第一篇:https://blog.csdn.net/m0_71523511/article/details/139636367
本系列第二篇:https://blog.csdn.net/m0_71523511/article/details/140583609
本系列第三篇:本文
瑞芯微有很多部署的例子在官方的git仓库里,如下图所示:

部署官方的这些模型只需要在rknn_model_zoo目录下执行类似: ./build-linux.sh -t rv1126 -a armhf -d yolov8 ,编译生成可执行文件,再加上rknn模型就可以上板运行。由于瑞芯微的onnx模型都是对原模型的优化,所以类似yolo官网训练出来的模型就不能直接用它们demo的推理代码,有两种方法比较省力:一是更改自己的模型结构使其适配瑞芯微的demo推理代码;二是不修改自己的模型结构,更改瑞芯微的demo推理代码使其适配自己的模型。这里选择第一种方法。
要完成对自己训练的yolov8-seg模型进行部署主要是:
①训练自己的模型,得到pt文件
②对模型进行转换得到rknn模型,对推理代码进行编译生成可执行文件
③上板运行
④模型预编译(加快模型初始化速度)
这里面最难且最核心的就是第二步。本文训练模型是在windows环境下,使用anaconda进行环境管理;转换模型是在ubuntu20.04环境下,也使用了anaconda管理环境。
一、训练yolov8-seg模型(windows)
关于windows-下搭建深度学习环境的文章,网上一搜一堆,这里不赘述,只需要能够训练就行,可以参考:
csdn博客
b站视频
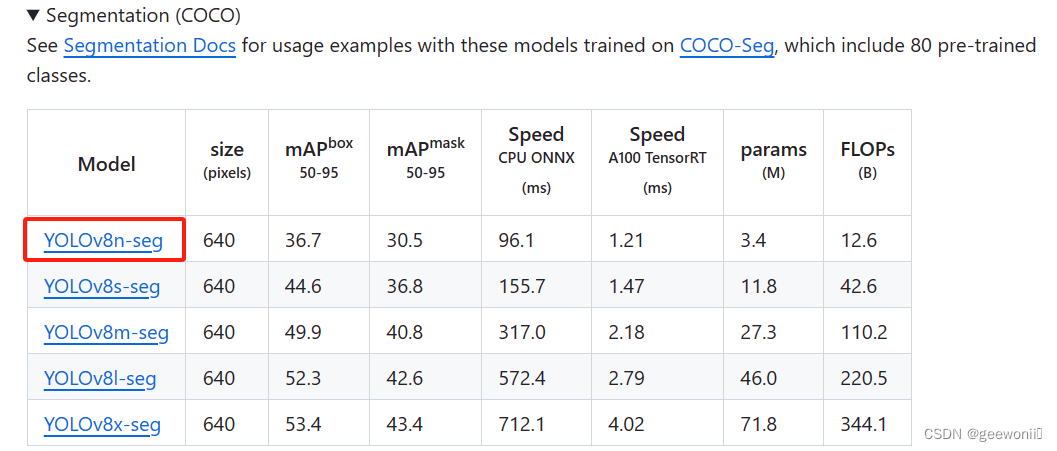
预训练模型在官网下载,选择yolov8n-seg:
下面是我的windows工程目录结构,供参考:
训练完成之后可以在/runs/segment/train/weights下看到模型文件,这里的best.pt就是后续要用到的模型。

二、onnx模型转成rknn模型并编译推理代码(虚拟机ubuntu)
2.1 模型转换环境的配置:
到ubantu官网下载20.04版本的ubuntu,其他版本应该也可以,我这里是在虚拟机安装,当然也可以双系统,这里的安装教程都很多。
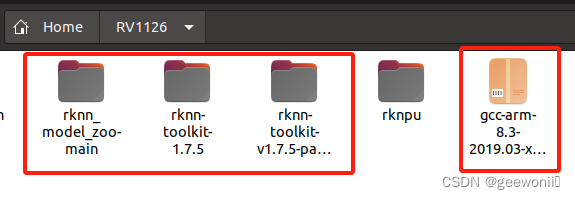
ubantu安装完成之后,需要到瑞芯微的git仓库下载必须的一些文件:
2.1.1、https://github.com/rockchip-linux/rknn-toolkit
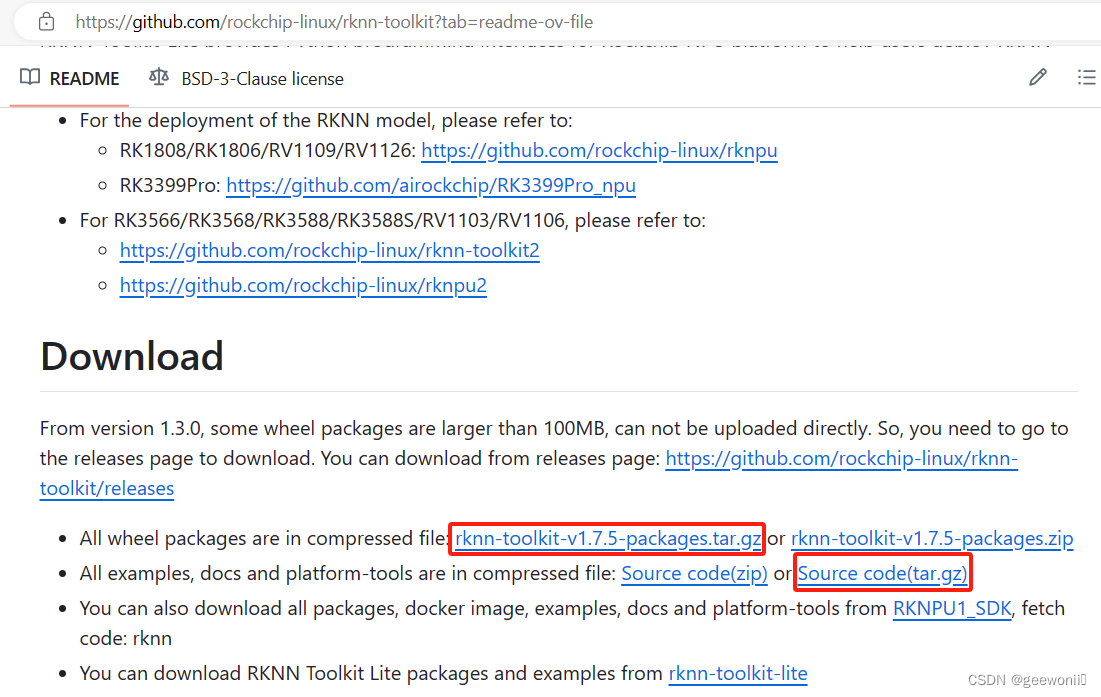
第一个是rknn官方安装包压缩文件,whl文件在这里面。第二个是rknn官方压缩文件,这里没用到也可以不下载。
2.1.2、https://github.com/airockchip/rknn_model_zoo
RKNN Model Zoo是基于 RKNPU SDK 工具链开发的, 提供了目前主流算法的部署例程. 例程包含导出RKNN模型, 使用 Python API, C API 推理 RKNN 模型的流程。

2.1.3、arm交叉编译工具链,后续编译时需要用到。不懂这是干嘛用的可以网上搜,简单来说就是在虚拟机ubuntu的系统架构下(x86)编译出开发板架构(arm)下能运行的文件。
上面这些都下好之后放入同一个文件夹下即可:
2.1.4、anaconda安装、rknn-toolkit安装
进入anaconda官网,下载linux版本:
可以在虚拟机里下载,也可以windows下载之后拷贝到ubantu里。
进入放置这个sh文件的目录下打开终端,执行:bash anaconda安装包名:
这个安装需要阅读协议,可以一直输入yes和回车,会比按enter键更快。
安装完成之后进行配置才能正常使用:source ~/.bashrc
①按照如下指令激活python环境:
conda create -n py3.6-rknn-1.7.5 python=3.6 //创建虚拟环境conda activate py3.6-rknn-1.7.5 //激活虚拟环境在安装rknn-tooltik之前先升级一下系统的cmake:

安装的tensorflow和pytorch版本最好适配rknn-tooltik的版本,否则可能会有问题,在rknn-toolkit-package里的txt里面有给出建议安装的版本。
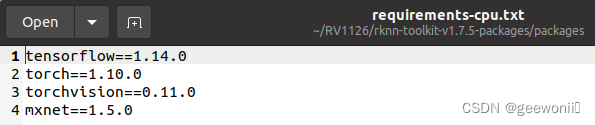
②安装rknn-toolkit及其部分依赖包(确保激活了虚拟环境):
这里安装cpu版本是因为,虚拟机里的ubantu无法调用物理机的gpu,所以只能安装cpu版本,对于双系统的可以安装gpu版本,但需要注意cuda的版本对应。

上面的步骤结束之后,可以进行测试看安装是否成功:from rknn.api import RKNN

③配置交叉编译环境
xz -d gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf.tar.xz
tar -xvf gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf.tar
解压完成后将解压目录设置到bash里,设置环境变量:
sudo gedit ~/.bashrc
export PATH=/home/ss/RV1126/gcc-arm-8.3-2019.03-x86_64-arm-linux-gnueabihf/bin:$PATH
# 上面这句修改为自己的目录,加到最末尾即可
source ~/.bashrc
上述设置全部成功之后,环境配置就到此结束。
2.2 模型转换:
①https://github.com/airockchip/ultralytics_yolov8/blob/main/RKOPT_README.zh-CN.md
此工程用于将使用官方yolov8-seg训练出来的模型转换成适配瑞芯微推理demo的onnx模型,将这个工程下载之后,按照网站里的去操作,即可得到onnx模型(注意使用自己训练出的pt模型)。
# 调整 ./ultralytics/cfg/default.yaml 中 model 文件路径,默认为 yolov8n.pt,若自己训练模型,请调接至对应的路径。支持检测、分割模型。
# 如填入 yolov8n.pt 导出检测模型
# 如填入 yolov8-seg.pt 导出分割模型export PYTHONPATH=./
python ./ultralytics/engine/exporter.py# 执行完毕后,会生成 ONNX 模型. 假如原始模型为 yolov8-seg.pt,则生成 yolov8_seg.onnx 模型。
②进入rknn_model_zoo/example/yolov8-seg/python中,将前面导出的onnx模型放到这个目录,然后执行:
python3 convert.py yolov8_seg.onnx rv1126
即可在model中得到rknn模型。
这里穿插说明,可以先使用python文件夹下的推理代码推理onnx模型,这一步不需要连接开发板,就是测试一下onnx模型是否可用,如果这一步可以用的话大概率转成rknn也是没问题的。
③进入rknn_model_zoo-main目录:
运行如下命令进行编译:
./build-linux.sh -t rv1126 -a armhf -d yolov8_seg
编译后在如下目录得到 可执行文件

此时在model_zoo目录的install中可以看到一个文件夹,后续会用到:
三、上板运行
将上面得到的rknn_yolov8_seg_demo文件夹送入板子即可,可以使用adb,也可也使用nfs挂载,也可以使用ssh远程登录。
在板子里进入到rknn_yolov8_seg_demo文件夹中:
chmod 777 rknn_yolov8_seg_demo //给予权限./rknn_yolov8_demo yolov8_seg.rknn bus.jpg //执行推理
这里由于没有进行预编译,所以初始化需要很久,实际推理速度很快,最终结果保存为rknn_yolov8_seg_demo目录下的out.png:

四、模型预编译(虚拟机ubantu)
直接按照example中的指令转换得到的rknn模型在rv1126板子上加载速度非常慢,也就是上面说的那样,所以进行在线预编译来加快加载速度。在线预编译的代码路径如下:

这里需要使用adb连接开发板才能运行这个py文件,开发板和电脑通过usb线连接,ubantu里执行:
sudo apt install adb
安装完成之后可以执行adb devices,看是否能看到板子的id,如果报错,那就百度,一般就是删除重装adb或者重启adb。如果能看到板子id就可以运行程序,首先把模型转换步骤中生成的rknn模型放到这个路径下:

执行:
python export_rknn_precompile_model.py yolov8_seg.rknn yolov8_seg_precompile.rknn rv1126
板子连接没有问题的话就会生成一个预编译后的模型:

此时可以用这个模型替换掉第三步上班运行中的rknn模型,可以看到推理时不用等很长时间初始化了。
五、板端按键控制摄像头拍照,送入深度学习模型进行推理实现足型检测
这个之所以写在后面是因为之前这部分是待改进的,还未完成的部分,现在完成了,懒得修改前面的内容,所以最好前面的内容都先做一遍,这样才能熟悉流程,这部分还需要修改推理及后处理的代码。由于此项目是一个课设,所以代码部分暂不给出,这里给出大致流程:
①、首先需要在虚拟机中,按照这个博客的教程:https://blog.csdn.net/m0_71523511/article/details/139636367搭建出在rv1126开发板上可以使用opencv的高级函数的环境。当然也可以像本系列第二篇博客一样,使用v4l2来实现摄像头数据的读取,这里面还给出了板端按键检测和lcd显示的代码。
②、修改cpp中的main.cc,这个文件默认是读取图像进行推理的,上一步已经搭建好了opencv交叉编译环境,此时可以直接修改代码,使用capture函数直接抓取usb摄像头的图像,可以再添加一些其它的功能,比如使用按键按下进行拍照并推理,将将结果显示到lcd屏幕上,这里我就是这样实现的,代码部分自己摸索。
③、编译修改完的代码,将得到的模型文件和第一篇文章最后面得到的动态库全都放到开发板端,即可运行。


对推理结果再进行图像处理即可得到足型。
六、待改进
一、用QT做一个界面,来控制拍照和显示。
二、增加网络编程,将数据保存和展示在云端,以app、web、微信小程序其中一个方式来显示。









![[MRCTF2020]套娃1](https://i-blog.csdnimg.cn/direct/3058e12a995e46ebbf61426c9920b095.png)