论文链接:https://aclanthology.org/D19-5008.pdf
目录
摘要
引言
1.1谣言检测
1.2 问题陈述
1.3 用户立场
2 数据集和评估指标
2.1 数据集
2.2 评价指标
3 特点和方法
3.1使用内容信息的方法
3.2 利用用户信息的方法
3.3 基于传播路径和网络的方法
3.4 用户立场和谣言检测的联合学习
3.5 谣言辨别比赛
4 未来研究方向
4.1知识库
4.2 用户响应的目标
4.3跨域、跨语言
4.4解释性检测
4.5将用户立场和用户可信度整合在一起
4.6 利用外部文本信息
4.7多任务学习
4.8 谣言早期发现
4.9一个真实谣言检测系统的框架
摘要
社交媒体平台已用于信息和新闻收集,它们在许多应用程序中都非常有价值。然而,它们也导致谣言和假新闻的传播。通过使用机器学习技术分析社交媒体的内容和社交环境,已经做出了许多努力来检测和揭穿社交媒体上的谣言。
本文概述了谣言检测领域的最新研究。它提供了用于谣言检测的数据集的全面列表,并根据他们利用的信息类型和采取的方法来审查重要的研究。更重要的是,我们还提出了几个未来研究的新方向。
引言
谣言有时可能会在社交媒体平台上迅速传播,最近,谣言检测在学术界和工业界都引起了极大的兴趣。政府当局和社交媒体平台也在努力克服谣言的负面影响。在以下小节中,我们首先介绍了谣言检测的定义,问题陈述和用户立场,这是本文其余部分的重要概念。
1.1谣言检测
不同的出版物对谣言可能有不同的定义。由于缺乏一致性,很难在现有方法之间进行面对面的比较。在这项调查中,谣言被定义为真实值为真、未经核实或虚假的陈述(Qazvian等人,2011年)。当谣言的真实性值为假时,一些研究称其为“虚假谣言”或“假新闻”。然而,许多以前的研究给 “假新闻” 一个更严格的定义: 假新闻是由新闻媒体发布的新闻文章,故意和可证实是虚假的 (vosoghi等人,2018; Shu等人。)这项研究的重点是社交媒体上的谣言,而不是假新闻。对于谣言侦测也有不同的定义。
在一些研究中,谣言检测被定义为确定一个故事或在线帖子是谣言还是非谣言 (即真实的故事、新闻文章),以及确定谣言真实性的任务 (真实的,错误或未验证) 被定义为谣言验证 (Zubiaga等人,2016; Kochkina等人,2018)。但在这篇调查论文中,以及 (马等人,2016; Cao等人,2018; Shu等人,2017; Zhou等人,2018),谣言检测被定义为确定谣言的真实性值。这意味着它与其他一些研究中定义的谣言验证相同。
1.2 问题陈述
谣言检测问题定义如下: 故事x定义为n条相关消息的集合M = {m1,m2,...,mn}。m1是启动消息链的源消息 (post),它可以是具有多个分支的树结构。对于每个消息mi,它具有表示其内容的属性,例如文本和图像。每条消息也与发布它的用户相关联。用户还具有一组属性,包括名称,描述,头像图像,过去的帖子等。
然后将谣言检测任务定义为: 给定具有其消息集M和用户集U的故事x,谣言检测任务旨在确定该故事是真实的、虚假的还是未经验证的 (或者对于仅具有两个标签的数据集仅是真实的还是虚假的)。此定义将谣言检测任务公式化为真实性分类任务。该定义与许多研究中使用的定义相同 (Cao等,2018; Shu等,2017b; 马等,2016; Zhou等,2018)
1.3 用户立场
在一些谣言检测模型中,用户对源帖子(第一条消息)的反应已经被利用。大多数研究使用四个立场类别:支持、否认、查询和评论。一些研究在他们的谣言检测模型中明确使用了立场信息,并显示出巨大的性能改进 (Liu等人,2015; Enayet和El-Beltagy,2017; 马等人,2018a; Kochkina等人,2018),包括这两个系统,(Enayet和El-Beltagy,2017) 和 (Li等人,2019a),分别在SemEval 2017和SemEval 2019谣言检测任务中排名第一。立场检测不是本文的重点,但立场信息已经在许多谣言检测模型中被显式或隐式地使用,在下一节我们还将讨论一些多任务学习方法,这些方法共同学习立场检测和谣言检测模型。
在以下各节中,我们将1.介绍用于谣言检测的数据集的全面列表; 2.讨论按其使用的信息和方法分类的研究工作; 3.提出未来研究的几个方向;
2 数据集和评估指标
2.1 数据集
数据集可能会有所不同,具体取决于从哪些平台收集数据,包括哪些类型的内容,是否记录了传播信息等。表1列出了用于谣言检测的数据集。还有许多假新闻检测其他数据集。因为本文主要关注社交媒体上的谣言检测,而那些数据集仅用于假新闻检测,没有社交上下文信息 (如用户响应、用户数据和传播信息),所以我们没有在这里列出。
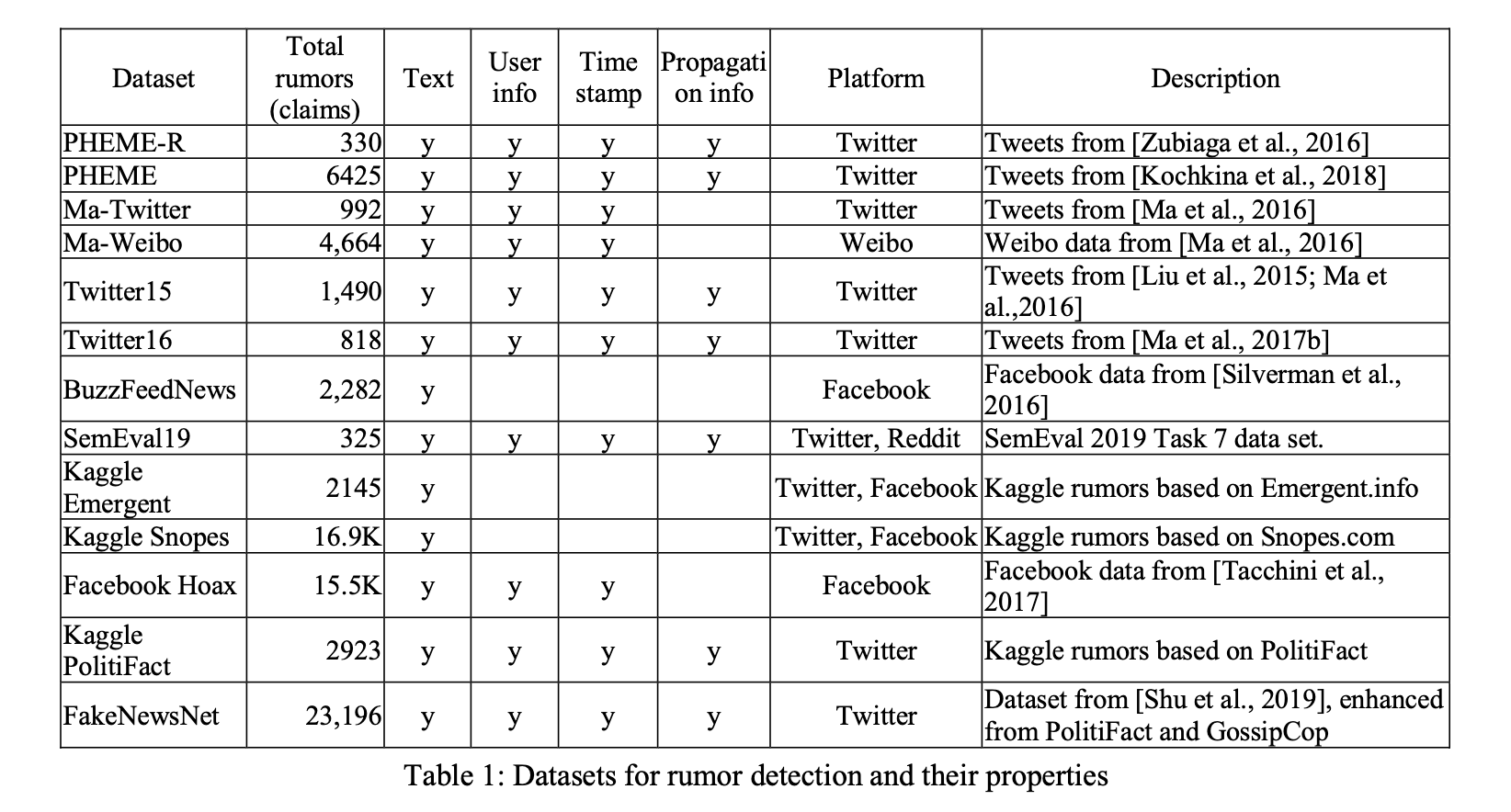
表1中的数据集数据是从四个社交媒体平台收集的: Twitter,Facebook,Reddit和微博。微博是中国的社交媒体平台,拥有超过4亿个用户,与Twitter非常相似。这些数据集中有一半以上具有三个准确性标签: true,false和未验证。其他只有两个标签: 真假。在这些数据集中,PHEME-R已被SemEval 2017谣言检测任务使用,SemEval19已被SemEval 2019谣言检测任务使用 (Gorrell等,2019)。数据集链接如下:
PHEME-R:
https://figshare.com/articles/PHEME_rumour_scheme_dataset_journalism_use_case/2068650
PHEME:
https://figshare.com/articles/PHEME_dataset_for_Rumour_Detection_and_Veracity_Classification/6392078、
Ma-Twitter: http://alt.qcri.org/~wgao/data/rumdect.zip
Ma-Weibo: http://alt.qcri.org/~wgao/data/rumdect.zip
Twitter15:
https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0
Twitter16:
https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0
BuzzFeedNews: https://github.com/BuzzFeedNews/2016-10-fac\ebook-fact-check
SemEval19:
https://competitions.codalab.org/competitions/19938#learn_the_details-overview
Kaggle Emergent:
https://www.kaggle.com/arminehn/rumor-citation
Kaggle Snopes:
https://www.kaggle.com/arminehn/rumor-citation
Facebook Hoax: https://github.com/gabll/some-like-it-hoax/tree/master/dataset
Kaggle PolitiFact:
https://www.kaggle.com/arminehn/rumor-citation
FakeNewsNet:
https://github.com/KaiDMML/FakeNewsNet
2.2 评价指标
大多数现有方法都将谣言检测视为分类问题。通常它要么是二进制 (真或假),要么是多类 (真、假或未验证) 分类问题。使用最多的评估指标是精度,召回率,F1和准确性度量。由于某些数据集存在偏差,因此宏F1度量将为所有类的算法性能提供更好的视图。在这里,我们简要描述它们。对于每个C类,我们计算其精度 (p),召回率 (r) 和F1得分如下:

一起考虑所有的类,那么宏F1的分数是:
![]()
其中n为类数,F1i为类i的分数。所有谣言类型的总体准确性为:
![]()
3 特点和方法
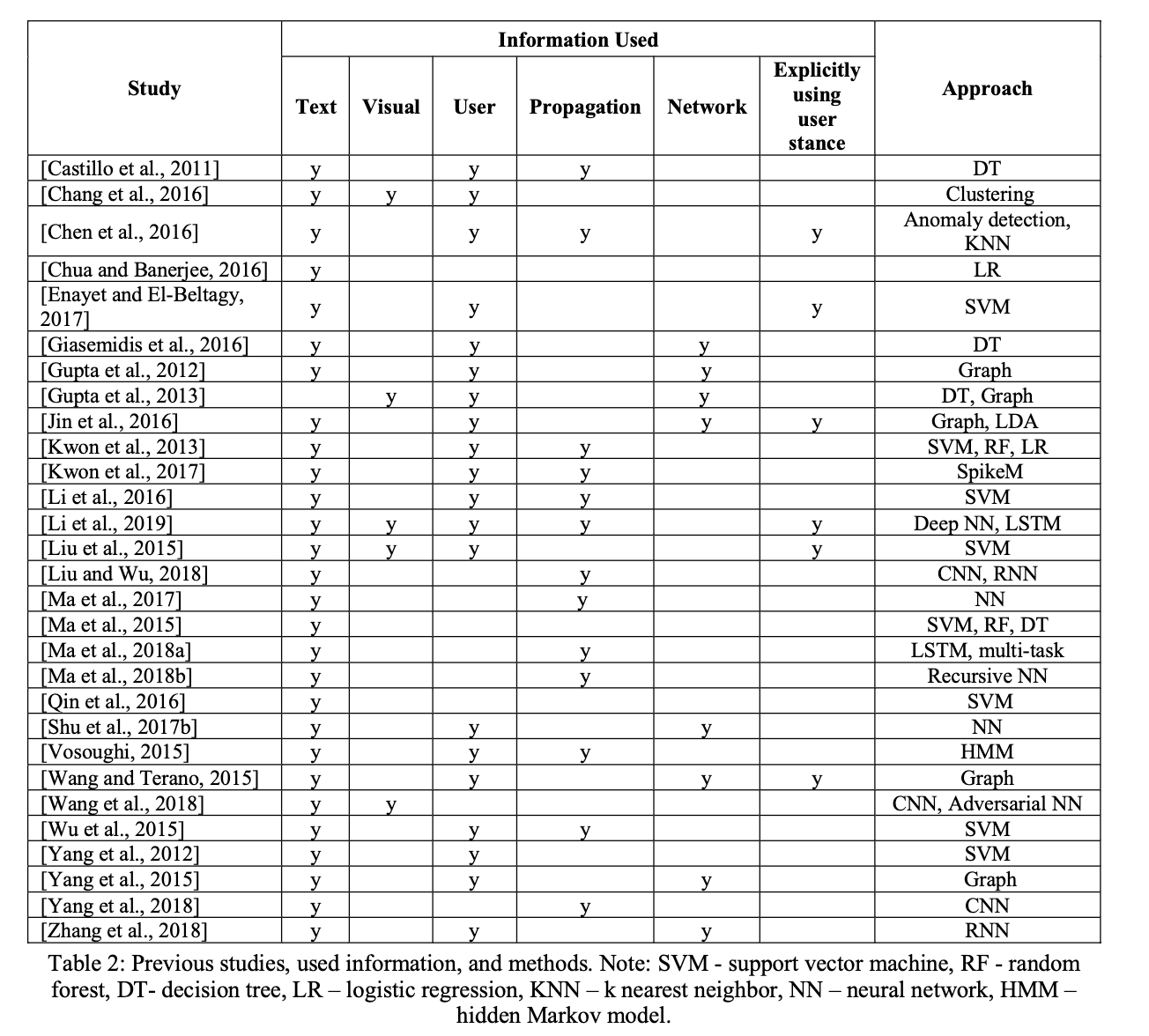
在本节中,我们根据他们在模型中利用的信息类型来回顾以前的研究。用于谣言检测的信息可以从几个信息维度进行分类: 内容,用户,传播路径和网络。我们还将简要概述采用多任务学习进行立场检测和谣言检测的研究,并介绍谣言检测的竞赛。表2介绍了这些研究及其相关信息。从这个表中我们可以看到,大多数研究都利用了文本内容、用户信息和传播路径。其中一些人还明确地将用户立场纳入他们的模型中。它还表明,几乎所有最近的研究都在他们的模型中使用了神经网络。由于篇幅所限,本文仅对具有代表性的研究进行介绍。
3.1使用内容信息的方法
文本内容。几乎所有以前关于谣言检测的研究都利用了文本内容。它包括来源帖子和所有用户回复。根据欺骗风格理论,旨在欺骗读者的欺骗信息的内容风格应该与真相的内容风格有所不同,例如,使用夸张的表达或强烈的情感。从用户响应文本中,我们还可以探索用户对谣言的立场和看法。
一般来说,文本特征可以分为基于属性的特征和基于结构的特征(周和扎法拉尼,2018)。基于属性的特征包括数量(词、名词、动词、短语等)、不确定性(问号、量词、试探性术语、情态术语的数量)、主观性(主观动词、命令式命令的百分比)、情感(肯定/否定词、感叹号)、多样性(唯一实词、唯一虚词)和可读性。基于结构的特征包括词汇、句法、语义和语篇信息,如词性标记、上下文无关语法和语言查询和单词统计(LIWC)。
来自 (Castillo等人,2011) 的早期研究在其模型中使用了许多文本特征,例如带有标签的推文的分数。这些特征和其他附加文本特征也用于其他研究 (Liu等人,2015; Enayet和El- Beltagy,2017; Li等人,2019a; 马等人,2017; Li等人,2019b)。Kwon等人 (2013) 也使用LIWC词典。Chua和Banerjee (2016) 分析了六类特征: 可理解性,情感,时间取向,定量细节,写作风格和主题。报告的一些重要特征是: 否定词,推文中的过去,现在,未来POS,差异,汗水和排除功能。文本内容在谣言检测中起着重要作用,但大多数研究表明,仅利用文本内容是不够的。
视觉内容: 视觉特征 (图像或视频) 已被证明是谣言检测的重要指标 (Jin等,2017a; Jin)谣言利用了个人的弱点,经常使用耸人听闻或虚假的图片来激发用户的情绪反应。视觉特征有两种类型:统计特征和内容特征。统计特征包括图像/视频计数、图像比例等(Gupta等人,2013年;金等人,2017a;金等人,2007b;Shu等人,2007a;Liu等人,2015;Li等人,2019a;Li等人,2019b;Shu等人,2017)。视觉内容特征包括清晰度分数、连贯性分数、多样性分数、相似性分布直方图等(Wang等人,2018年;Shu等人,2017年)。金等人(2017a;2017b)使用各种视觉内容和统计特征进行谣言检测。Wang等人(2018)采用多模态特征提取器从帖子中提取文字和视觉特征,然后将文字特征表示和视觉特征表示串联起来,形成多模态特征表示。
3.2 利用用户信息的方法
用户通过分享、点赞、转发、评论等多种方式从事谣言传播。之前的许多研究表明,用户可信度信息在谣言核实中非常重要(Castillo等人,2011;Yang等人,2012;Gupta等人,2012;Liu等人,2015;Vosoughi,2015;Shu等人,2017b;Zhang等人,2018;Liu and Wu,2018;Li等人,2019a;Li等人,2019b)。基于421条虚假谣言和147万条相关推文,李等人。(2016)研究虚假谣言的各种语义方面,分析其传播和用户特征。一些发现是:当人们对谣言的真实性不清楚时,他们通常只传播谣言而不加入自己的意见。可信用户不太可能支持谣言,而低可信度帐户提供最多支持; 在支持或揭穿谣言方面,可信用户要严格得多,因此比相应的用户更值得信赖。
在Castillo等人中,手工创建的用户特征,如用户的注册年龄、关注者数量、用户已创作的帖子数量等,与其他文本和传播特征一起被利用。(2011)和其他研究(Liu等人,2015;Enayet和El-Belagy,2017;Li等人,2019a;Li等人,2019b)。Liu和Wu(2018)使用社会网络图上的网络嵌入方法来构建用户表示。有证据表明,许多谣言要么来自假新闻网站,要么来自超党派网站(Silverman,2016;Li等人,2016;刘等人,2015)。
3.3 基于传播路径和网络的方法
谣言通过社交媒体以分享和重新分享来源帖子和分享帖子的形式传播,导致扩散级联或树。重新共享的路径和其他传播动态被用于谣言检测。我们将当前的研究分为 :( 1) 基于级联的谣言检测技术,该技术直接利用了谣言传播路径; (2) 基于网络的检测方法,该方法从级联构造了一个灵活的网络,从中间接检测到谣言。
基于传播的:当使用级联来检测谣言时,可以通过计算其级联与其他真假谣言的相似度来区分它们,或者通过生成便于区分虚假和真实谣言的级联表示来区分它们。Ma等人。(2018b)构建基于假新闻级联的树形结构神经网络用于谣言检测。Liu和Wu(2018)使用RNN的传播路径分类来进行早期谣言检测。Zubiaga等人。(2018b)提出了一种基于LSTM层和多个密集REU层的方法。其他利用传播路径的研究有(Kwan等人,2017;Wu等人,2015;Chen等人,2016;Yang等人,2018;Li等人,2019a;Li等人,2019b)。这些研究的实验表明,采用传播路径的模型比基于特征的算法表现更好。
但是我们应该记住,在谣言传播的早期,我们通常没有太多的传播信息,早期发现对于实时谣言检测系统尤其重要。来自 (vosoghi等人,2018) 的研究表明,未经证实的新闻往往会表现出多个且周期性的讨论尖峰,而经证实的新闻通常只有一个突出的尖峰,并且虚假谣言比真实新闻传播得更远,更快,更广泛。
基于网络: 基于网络的谣言检测构建灵活的网络来间接捕获谣言传播信息。构建的网络可以是同质的、异构的或分层的。Gupta等人 (2012) 构造了一个由用户、消息和事件组成的网络,使用类似PageRank的算法来计算事件可信度。Yang等人 (2015) 结合了从评论中获得的网络特征,他们说,当网络特征被添加到传统特征中时,结果大大改善。Wang和Terano (2015) 提出了社交图来模拟用户之间的互动并识别有影响力的谣言传播者。异构网络具有多种类型的节点或边。一个例子是新闻创作者、谣言和用户之间的三关系网络 (Shu et al.,2017b),它使用实体嵌入和关系建模来构建谣言检测的混合框架。在 (Zhang等人,2018) 中,RNN模型被设计用于通过探索创作者,内容,主题及其关系来检测谣言。
3.4 用户立场和谣言检测的联合学习
用户姿态在谣言检测中起着重要作用。最近的工作采用了多任务学习方法来共同学习立场检测和准确性预测,以便通过利用它们之间的相互依赖性来提高分类准确性。马等人 (2018a) 共同学习立场检测和准确性预测任务,其中每个任务都有一个特定于任务的GRU层,并且任务还共享一个GRU层。共享层是捕获这两个任务共有的模式,而任务特定层是捕获对该任务更重要的模式。在谣言检测任务中,最后一个时间步长的隐藏状态用于通过全连接的输出层进行预测。
Ma等人研究发现,联合学习提高了单个任务的性能,使用共享的和任务特定的参数比只使用共享的参数而没有任务特定的层更有利。Kochina等人(2018)提出了一种无任务特定层的多任务造谣方法。这两种方法都没有在他们的模型中使用注意力,也没有使用用户信息。Li等人。(2019b)在联合学习方法中利用用户可信度信息和注意力机制。
3.5 谣言辨别比赛
谣言检测有两个竞赛:
1.SemEval-2017任务 8: 确定谣言的准确性和对谣言的支持 (Derczynski等人,2017)。来自 (Enayet和El-Beltagy,2017) 的方法在谣言检测任务中排名第一。
2. SemEval-2019任务 7: 确定谣言的真实性和对谣言的支持 (Gorrell等,2019)。来自 (Li等人,2019a) 的方法在谣言检测任务中排名第一。表1列出了这两个任务中使用的数据集。(Enayet和El-Beltagy,2017) 和 (Li等人,2019a) 两者都利用了内容、用户和传播信息。他们还直接在模型中使用用户姿态。它们之间的主要区别在于Li等人 (2019a) 使用了神经网络,而Enayet和El- Beltagy (2017) 使用了SVM模型。
还有两个与假新闻有关的竞赛,但实际上这两个竞赛都是关于立场检测,而不是假新闻检测。它们是http://www.fakenewschallenge.org的假新闻挑战,也是WSDM 2019杯: 假新闻文章的分类: https://www.kaggle.com/c/假新闻对分类挑战
4 未来研究方向
尽管在揭穿社交媒体上的谣言方面取得了重大进展,但仍有许多挑战需要克服。在回顾前人研究的基础上,结合我们在谣言检测研究和实际系统实现方面的经验,本文提出了未来谣言检测研究的几个方向。
4.1知识库
知识库 (KB) 对于假新闻检测非常有帮助 (Hassan等人,2017)。已经有一些关于使用KB进行假新闻检测的研究,但是很少或没有关于社交媒体上的谣言检测的研究。原因之一是,对于社交媒体上的谣言,我们已经有很多信息,尤其是社交环境信息,可以利用和进行研究。另一个原因是,与主要处理新闻文章的假新闻检测相比,社交媒体上的谣言涉及各种主题,很难建立合适的KBs来覆盖它们。因此,以前大多数关于谣言检测的研究都没有关注利用KB来揭穿谣言。
自动事实检查过程旨在通过将从谣言文本中提取的知识与存储在构造的KB或知识图谱中的已知事实 (真实知识) 进行比较来评估索赔。利用KB在社交媒体上揭穿谣言的一个优点是,源帖子 (声明) 通常很短,与分析可能有多个声明的长新闻文章相比,从短文中提取主要声明更容易。来自 (Kwon等人,2017) 的研究表明,当我们想在谣言的早期阶段检测到谣言时,文本特征非常重要,因为当谣言刚刚出现时,没有传播信息或来自用户的很少反馈。通过从谣言文本中提取知识,我们假设基于KB的方法对谣言的早期发现特别有帮助。作为起点,最初的研究工作可以集中在流行谣言的主题领域,并且可以首先探索在假新闻检测中已经有效的方法。我们认为KBs如何有效地帮助谣言检测以及如何将其与其他社会背景信息集成将是一个有趣的研究主题。
4.2 用户响应的目标
用户响应对于谣言检测非常有用。通常,虚假谣言会收到更多的负面和质疑回应,可以利用这些回应进行谣言检测。每个来源消息 (谣言声称) 都有许多回复,它们要么是直接回复,要么是对转换线程中的其他消息的回复。转换线程的结构对于了解回复用户的真实立场很重要。
例如,给定一条消息 “这是假的” 和对它的回复 “我完全同意”,如果我们不认为该回复是针对 “这是假的”,那么我们将给这个回复一个错误的立场标签 “支持”。但实际上,这种回应否认了谣言的说法。尽管基于传播分析的神经网络模型可能会部分学习此信息,但我们认为明确处理这种情况将提高谣言检测性能。
用户响应目标的另一个问题是,有时用户的响应不是针对源消息的声明,而是针对谣言故事的某些方面。例如,这是SemEval19谣言侦测任务中的一个虚假谣言:“据报道,国家地理频道为这段大胆的视频支付了100万美元。Https://t.co/CDbjf65bKG.“对于这一谣言,许多人都在谈论这段视频有多棒,或者视频中的山羊有多勇敢。“坚持不懈,勇于拼搏!”和“好样的!”。对于立场检测算法,由于他们的积极情绪,很有可能将这种类型的响应预测为“支持”。这显然也会误导谣言检测算法。我们认为,研究用户回复的意图,以更好地理解用户评论的实际目标是值得的。
4.3跨域、跨语言
以前的大多数研究都强调通过实验环境区分虚假谣言和真相,这些实验环境通常限于特定的社交媒体平台或特定的话题领域,如政治。跨主题或跨平台分析谣言将让我们对谣言有更深入的了解,并发现它们的独特特征,从而进一步帮助跨域(话题和平台)揭穿谣言。
最近,我们看到了跨语言传播的谣言,尤其是涉及政治、投资、商业和金融等话题的谣言。通常,由于语言障碍和缺乏跨语言的谣言检测工具,谣言已经在一种语言中被揭穿,但仍在另一种语言中传播。对于类似Facebook的社交媒体平台微博和微信上的一些中文谣言来说,这是非常正确的。这些谣言通常是关于政治、世界事务、商业和健康/医学的话题。
例如,在微信中,有很多关于某些补品的谣言,声称它们对某些疾病有好处,并且还引用了一些外国研究来提供某些虚假证据。这种类型的谣言对于普通用户来说很难验证,尤其是对与医疗、医学、长寿相关的谣言感兴趣的主要群体的老年人。在过去的几年里,这种情况变得更加严重,因为越来越多的农村地区的人开始使用智能手机和社交媒体。如何处理这类跨语言跨平台的谣言检测问题也将是一个有趣的研究课题。
4.4解释性检测
大多数谣言检测方法只能预测谣言的真实性,很少透露为什么它是虚假谣言的信息。找到支持预测的证据并将其呈现给用户将是非常有益的,因为它可以帮助用户自行揭穿谣言。对结果进行解释已经引起了其他领域的研究,例如解释性推荐,但这仍然是谣言检测领域的一个新课题。随着当今越来越多的模型使用深度学习技术,这可能会变得更加困难。但是,随着AI技术在更多应用中使用,用户对结果解释的需求也在增加。例如,我们现在正在设计和实现一个阿里巴巴产品的谣言检测系统,产品设计者和用户需要的一个重要的产品特征是为准确性预测结果提供解释。
4.5将用户立场和用户可信度整合在一起
一些研究表明,用户立场和用户可信度信息都有助于提高谣言检测性能(Liu等人,2015;Enayet和El-Belagy,2017;Li等人,2019b)。然而,这些研究只涉及立场标签和反映用户可信度的特征,如no。关注者和用户账号年龄,作为整体预测模型中的单独特征。他们中没有一个人试图将这两种类型的信息系统地整合在一起,以获得一个统一的指标来反映回应对于确定谣言的真实性有多重要。
例如,我们要明确区分这两种不同的情况:一个 权威的、可信的用户,如可靠的 新闻机构或政府机构,驳斥或支持一项主张。驳斥或支持一个说法,而一个低可信度的用户,例如一个 恶意账户,驳斥或支持一项主张。正如 “用户响应目标” 部分所解释的那样,在设计集成模型时,我们还需要考虑实际目标。
4.6 利用外部文本信息
除了前面提到的KBs之外,其他类型的外部信息也可能有助于谣言检测,例如来自可信的新机构网站的文章、政府和当局的公告或文件、相关方的官方公告、经过验证的过去谣言等。我们可以将当前的谣言与这些外部文本数据进行比较,以获得对谣言的更多见解。这听起来像是一个无聊的想法,也是一个旧的信息检索和文本匹配问题,但实际上它将对谣言检测产生非常实际的影响,特别是对于一个真正的谣言检测系统。许多谣言只是旧谣言或其变体的重新出现。而对于一个人来说,当我们核实一个谣言时,我们会做的一件事也是检查相关网站,看看是否有关于这个谣言的相关信息,比如官方公告。来自 (Qin等人2016) 的研究表明,这种方法在实时检测过去有变体的谣言时非常有效。系统实现的一个挑战是监视这些网站并抓取相关的文本信息。
4.7多任务学习
研究已经表明,立场检测和谣言检测的联合学习改进了谣言检测的性能马Kochkina等,2018; 马等,2018a)。在谣言检测工作流程中,根据算法的不同,可能涉及以下任务: 用户可信度评估,来源可信度评估,知识提取等。如果有针对这些数据类型的带有注释的适当数据集,除了用户立场和谣言检测任务之外,一个研究方向是探索针对这些任务的多任务学习。我们预计,至少这将有利于谣言真实性预测任务。
4.8 谣言早期发现
谣言早期发现是在谣言在社交媒体上广泛传播之前,在早期发现谣言,以便人们可以更早地采取适当的行动。早期检测对于实时系统尤其重要,因为谣言传播得越多,造成的损害就越多,人们就越有可能信任它。这是一项非常具有挑战性的任务,因为在其早期阶段,谣言几乎没有传播信息,用户响应也很少。该算法必须主要依赖于内容和外部知识,例如KB。一些研究已经在谣言的早期阶段测试了他们的算法 (Liu等人,2015马等人,2016; Kwon等人,2017; Liu和Wu,2018)。Kwon等人 (2017) 分析了随时间变化的特征稳定性,并报告用户和语言特征比结构化和传播特征更好,以确定谣言在其早期阶段的真实性。尽管已经有一些关于这个方向的研究,但由于它在实际系统中的重要性,仍然需要更多的研究努力。
4.9一个真实谣言检测系统的框架
尽管有许多关于谣言检测的研究,但大多数研究集中在仅利用部分可用信息的模型上,并在特定于平台或领域的数据集上进行测试。它们中很少有被设计用于实时系统 (Liu等人,2015; Liu等人,2016)。实用的谣言检测系统的框架应尝试利用所有可用信息,并将这些信息和模型适当地应用于可能涉及多种因素的不同情况,例如平台,谣言阶段,主题,语言和内容类型 (文本,视频或图像)。从利用信息的角度来看,我们认为以下信息或数据值得探索: 文本内容 (词汇,句法,语义,写作风格等),视觉内容 (视频,图像),谣言主题,知识库,外部文档,旧谣言,传播信息,用户特征、来源可信度、用户可信度、异质同质网络结构、跨平台信息、跨语言信息。