IDE:大部分是在PyCharm上面写的
解释器装的多 → 环境错乱 → error:没有配置,no model
- 爬虫可以做什么?
下载数据【文本/二进制数据(视频、音频、图片)】、自动化脚本【自动抢票、答题、采数据、评论、点赞】
- 爬虫的原理?
通过模拟/控制浏览器(客户端)批量的向服务器请求数据
- 完成一个完整的爬虫需要的步骤?
获取资源 – 发送请求 – 数据解析 – 保存数据
- 开发者工具 抓包

Headers 头部信息、数据包请求地址、请求方法、响应头、请求头
| Cookie | 用户身份标识 |
| Host | 客户端指定想访问的域名地址 |
| Origin | 资源在服务器的起始位置 |
| Pragma | 请求地址的查看参数 |
| Referer | 防盗链告诉服务器我是从哪个网页跳转过来的 |
| User-agent | 浏览器身份标识 |
| Payload | 查看参数、请求参数 |
| Preview | 预览服务器数据 |
| Response | 响应/回答 |
有花括号{}的 半结构化数据 json数据 前后端数据交互常用
驼峰命名法 AaBb大驼峰 a_b小驼峰
以下是几个爬虫实例:
1. 豆瓣电影
BV1NY411b7PR
🥝 实现步骤
step: 明确需求 → 发送请求 → 获取数据 → 解析数据(re正则表达式、css选择器、xpath) → 保存数据
🥝 实现代码
实现代码:
import requests # 数据请求模块
import parsel # 数据解析模块
import csv # 保存表格数据# f=open('douban.csv',mode='w',encoding='utf-8',newline='') # 中文乱码
f=open('douban.csv',mode='w',encoding='utf-8-sig',newline='')csv_writer =csv.DictWriter(f,fieldnames=['电影名字','详情页',#'导演',#'主演','演员','年份','国家','电影类型','评分','评论人数','概述',
])
csv_writer.writeheader()
for page in range(0,250,25):# url = 'https://movie.douban.com/top250'url =f'https://movie.douban.com/top250?start={page}&filter='headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}response = requests.get(url=url, headers=headers)# print(response.text)selector = parsel.Selector(response.text)lis = selector.css('.grid_view li') # css选择器# selector.xpath('//*[@class="grid_view"]/li') # xpathfor li in lis:# span:nth-child(1) 组合选择器,选择第几个span标签# text 获取标签的文本数据title = li.css('.hd a span:nth-child(1)::text').get() # 标题href = li.css('.hd a::attr(href)').get() # 详情页# li.xpath('//*[@class="hd"]/a/span(1)/text()').get()info = li.css('.bd p::text').getall()actor = info[0].strip().split('主演:') # strip()去字符串两端的空格,split字符串分割# director=actor[0].replace('导演:','').strip()# performer=actor[0].replace('...','').replace('/','').strip()actors = actor[0].replace('...', '').replace('/', '').strip() # 演员,导演+主演others = info[1].strip().split('/')year = others[0].strip() # 年份country = others[1].strip() # 城市type = others[2].strip() # 类型scores = li.css('.star span:nth-child(2)::text').get() # 评分#comment = li.css('.star span:nth-child(4)::text').get() # 评价人数comment = li.css('.star span:nth-child(4)::text').get().replace('人评价', '') # 评价人数overview = li.css('.inq::text').get() # 概述# print(title,actor,others)# print(director,performer,year,country,type)dit={'电影名字':title,'详情页':href,'演员':actors,#'导演':director,#'主演':performer,'年份':year,'国家':country,'电影类型':type,'评分':scores,'评论人数':comment,'概述':overview,}csv_writer.writerow(dit)print(title, href, actors, year, country, type, scores, comment, overview, sep=' | ')
🥝 部分参数
部分参数来源:

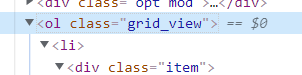
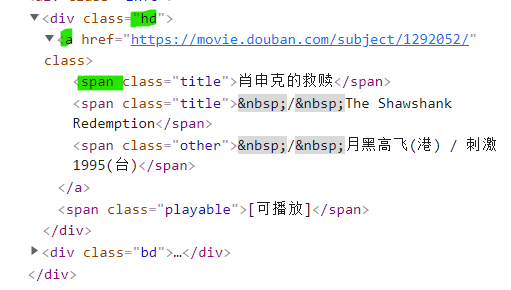

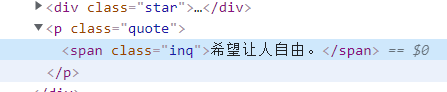
🥝 运行效果
部分效果:



🥝 乱码问题
中文乱码问题的解决:
乱码的效果就是它除了数字就全是问号???,哈哈哈哈。🤣
# f=open('douban.csv',mode='w',encoding='utf-8',newline='') # 中文乱码
f=open('douban.csv',mode='w',encoding='utf-8-sig',newline='')
2. 酷狗榜单
BV1ZU4y1B7yY
🥝 实现步骤
step: 发送请求 → 获取数据 → 解析数据
🥝 单个榜单
# pip Install requests
# 导入数据请求模块
import requests
# 导入正则模块,re是内置的,不需要安装
# 在Python中需要通过正则表达式对字符串进⾏匹配的时候,可以使⽤⼀个python自带的模块,名字为re。
import re
# 确定请求地址
url='https://www.kugou.com/yy/html/rank.html'
# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
# 发送请求
response = requests.get(url=url,headers=headers)
# print(response)
# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功
#(仅仅表示请求成功,不一定得到想要的数据)
# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据
# print(response.text)
# 解析数据
Hash_list = re.findall('"Hash":"(.*?)",', response.text)
album_id_list = re.findall('"album_id":(.*?),', response.text)
#print(Hash_list)
#print(album_id_list)
# for循环遍历 把列表里面元素一个一个提取出来
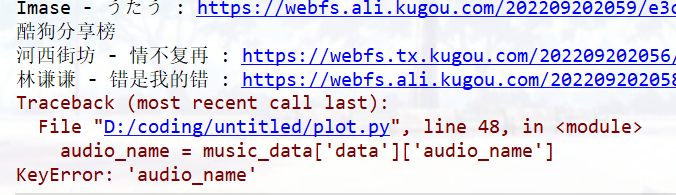
for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).textaudio_name=music_data['data']['audio_name']audio_url = music_data['data']['play_url']# print(music_data)print(audio_name,':',audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\'+audio_name+'.mp3',mode='wb') as f:f.write(audio_content)
获取请求地址:

请求头:
‘user-agent’: ’ Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36’ 表示浏览器基本身份标识
第九行代码要注意,如果引号写错了可能报错:
AttributeError: ‘set’ object has no attribute ‘items’
错误写法一:
headers={'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
headers是字典数据类型,不是集合set。{' '}是集合;{' ':' '}是字典
InvalidHeader: Invalid leading whitespace, reserved character(s), or returncharacter(s) in header value: ’ Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36’
错误写法二:
headers={'user-agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
多了个空格,小错误要注意。
re模块findall方法
re.findall() →找到所有我们想要的数据内容
解析的时候,hash、album
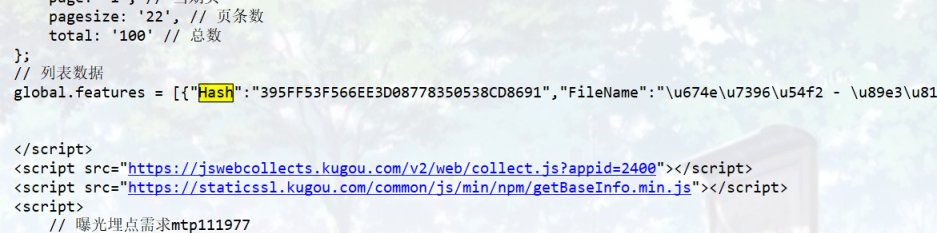
比较长,一次不好截,



错位❌写法:
music_data = requests.get(url=link, params=data, headers=headers).json()
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)

不是json格式,多了一部分,把callback删掉可以,或者用text
response.json →获取json字典数据
取歌曲名字和url


with open('music\\'+audio_name+'.mp3') as f:
FileNotFoundError: [Errno 2] No such file or directory: ‘music\李玖哲 - 解脱.mp3’
文件夹不存在(music),即使music文件夹已在,仍报错,可以改成:
with open('music\\'+audio_name+'.mp3',mode='wb') as f:
效果
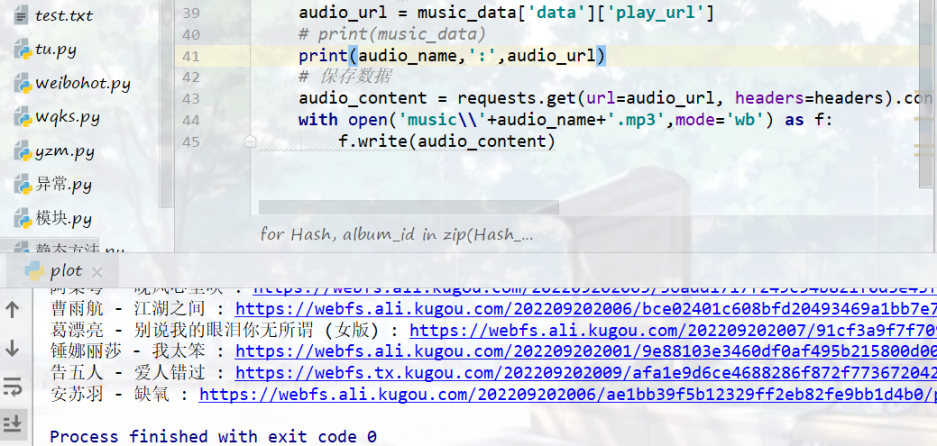

🥝 多个榜单
import requests
import reurl='https://www.kugou.com/yy/html/rank.html'
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
response = requests.get(url=url,headers=headers)
#print(response.text)
music_list = re.findall('<a title="(.*?)" .*? hidefocus="true" href="(.*?)">', response.text)[1:]# print(music_list)
# 从第几个开始爬,3(切片)
# for title,index in music_list[3:]:
for title,index in music_list:print(title)# url = 'https://www.kugou.com/yy/html/rank.html'# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}# 发送请求response = requests.get(url=index, headers=headers)# print(response)# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功# (仅仅表示请求成功,不一定得到想要的数据)# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据Hash_list = re.findall('"Hash":"(.*?)",', response.text)album_id_list = re.findall('"album_id":(.*?),', response.text)# print(Hash_list)# print(album_id_list)# for循环遍历 把列表里面元素一个一个提取出来for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).textaudio_name = music_data['data']['audio_name']audio_name = re.sub(r'[\/:*?"<>|]','',audio_name)audio_url = music_data['data']['play_url']if audio_url:# print(music_data)print(audio_name, ':', audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\' + audio_name + '.mp3', mode='wb') as f:f.write(audio_content)


第一个不要,做个切片
第一个网址打开是这样的
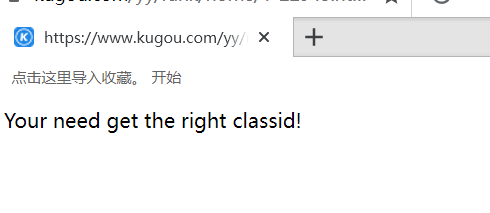
music_list = re.findall('<a title="(.*?)" hidefocus="true" href="(.*?)"', response.text)[1:]
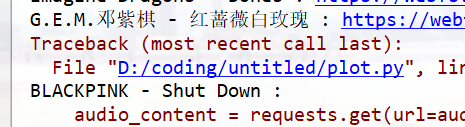
requests.exceptions.MissingSchema: Invalid URL ‘’: No scheme supplied. Perhaps you meant http://?
报错位置
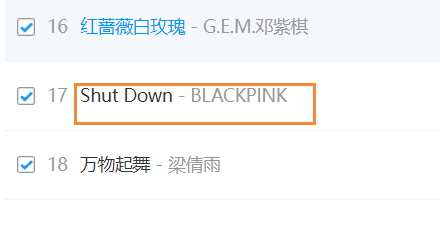
请求链接🔗不对,无法下载,改代码,让他直接跳过

OSError: [Errno 22] Invalid argument: ‘music\Stingray、Backstreet Boys - I Want It That Way (In the Style of Backstreet Boys|Karaoke Version).mp3’
特殊字符 → windows系统文件名不能包含

re.sub(r'[\/:*?"<>|]','',audio_name)
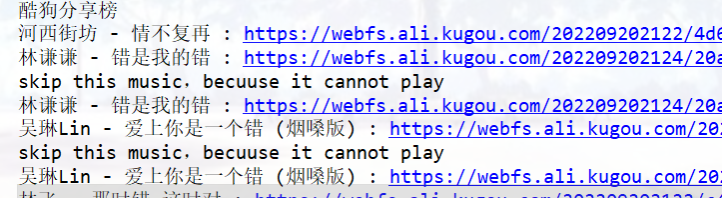
能跳过,但是有重复,就很怪
import requests
import reurl='https://www.kugou.com/yy/html/rank.html'
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
response = requests.get(url=url,headers=headers)
#print(response.text)
music_list = re.findall('<a title="(.*?)" .*? hidefocus="true" href="(.*?)">', response.text)[1:]# print(music_list)
# 从第4个开始爬,3(切片),0开始
# for title,index in music_list[3:]:
for title,index in music_list:print(title)# url = 'https://www.kugou.com/yy/html/rank.html'# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}# 发送请求response = requests.get(url=index, headers=headers)# print(response)# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功# (仅仅表示请求成功,不一定得到想要的数据)# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据Hash_list = re.findall('"Hash":"(.*?)",', response.text)album_id_list = re.findall('"album_id":(.*?),', response.text)# print(Hash_list)# print(album_id_list)# for循环遍历 把列表里面元素一个一个提取出来for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).texttry:audio_name = music_data['data']['audio_name']audio_name = re.sub(r'[\/:*?"<>|]', '', audio_name)audio_url = music_data['data']['play_url']except Exception as KeyError:print("skip this music,becuuse it cannot play")if audio_url:print(audio_name, ':', audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\' + audio_name + '.mp3', mode='wb') as f:f.write(audio_content)
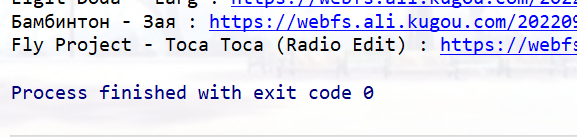
🥝 完善版本
import requests
import reurl='https://www.kugou.com/yy/html/rank.html'
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}
response = requests.get(url=url,headers=headers)
#print(response.text)
music_list = re.findall('<a title="(.*?)" .*? hidefocus="true" href="(.*?)">', response.text)[1:]# print(music_list)
# 从第4个开始爬,3(切片),0开始
# for title,index in music_list[3:]:
for title,index in music_list:print(title)# url = 'https://www.kugou.com/yy/html/rank.html'# 模拟伪装 headers 请求头 <-- 开发者工具里面进行复制粘贴headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.139 Safari/537.36'}# 发送请求response = requests.get(url=index, headers=headers)# print(response)# <Response [200]> //整体是一个响应对象,200 状态码表示请求成功# (仅仅表示请求成功,不一定得到想要的数据)# 获取数据,获取服务器返回响应数据 response.text 获取响应文本数据Hash_list = re.findall('"Hash":"(.*?)",', response.text)album_id_list = re.findall('"album_id":(.*?),', response.text)# print(Hash_list)# print(album_id_list)# for循环遍历 把列表里面元素一个一个提取出来for Hash, album_id in zip(Hash_list, album_id_list):# print(Hash,album_id)link = 'https://wwwapi.kugou.com/yy/index.php'# 请求参数data = {'r': 'play/getdata',# 'callback':'jQuery191022953264396493434_1663671714341','hash': Hash,'dfid': '4FII5w3ArJSc0dPjmR1DFIit','appid': '1014','mid': ' 8c6815fe99744abfea7f557377764693','platid': '4','album_id': album_id,# 'album_audio_id': '39933554','_': '1663671714343',}music_data = requests.get(url=link, params=data, headers=headers).json()# music_data = requests.get(url=link, params=data, headers=headers).texttry:audio_name = music_data['data']['audio_name']audio_name = re.sub(r'[\/:*?"<>|]', '', audio_name)audio_url = music_data['data']['play_url']if audio_url:print(audio_name, ':', audio_url)# 保存数据audio_content = requests.get(url=audio_url, headers=headers).contentwith open('music\\' + audio_name + '.mp3', mode='wb') as f:f.write(audio_content)except Exception as KeyError:pass
try-except的妙用,直接跳过一些错误/null的歌曲,比之前的多榜代码好一些。
3. 千千音乐
查单曲的params

# 千千音乐
import requests
import time
import hashliburl='https://music.91q.com/v1/song/tracklink'# 要其他歌曲修改这个params就可以了
params={
'sign': 'aeb1fc52109d5dd518d02f4548936a0b',
'TSID': 'T10045980539',
'appid': 16073360,# 不变
'timestamp':1658711978,
}headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}response=requests.get(url=url,params=params,headers=headers)music_url=response.json()['data']['path']
music_title=response.json()['data']['title']
music_singer=response.json()['data']['artist'][0]['name']
print(music_title,music_singer,music_url)
4. 微博热搜
# pip install lxml
# 微博热搜
import requests
from lxml import etree
import time
url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr='
header={'cookie':"SINAGLOBAL=7254774839451.836.1628626364688; SUB=_2AkMWR_ROf8NxqwJRmf8cymjraIt-ygDEieKgGwWVJRMxHRl-yT9jqmUgtRB6PcfaoQpx1lJ1uirGAtLgm7UgNIYfEEnw; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WWEs5v92H1qMCCxQX.d-5iG; UOR=,,www.baidu.com; _s_tentry=-; Apache=1090953026415.7019.1632559647541; ULV=1632559647546:8:4:2:1090953026415.7019.1632559647541:1632110419050; WBtopGlobal_register_version=2021092517; WBStorage=6ff1c79b|undefined",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
resp = requests.get (url,headers=header)
resp1 = resp.content.decode(encoding='utf-8',errors='ignore')
resp2=etree.HTML(resp1)
title = resp2.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr/td/a/text()')
print(time.strftime("%F,%R")+'微博热搜:')
for i in range(51):print (f'{i} '+''.join([title[i]]))
time.sleep(1)

后面还有很多,截图未完,但效果大概就是这样子的
5. 当当榜单
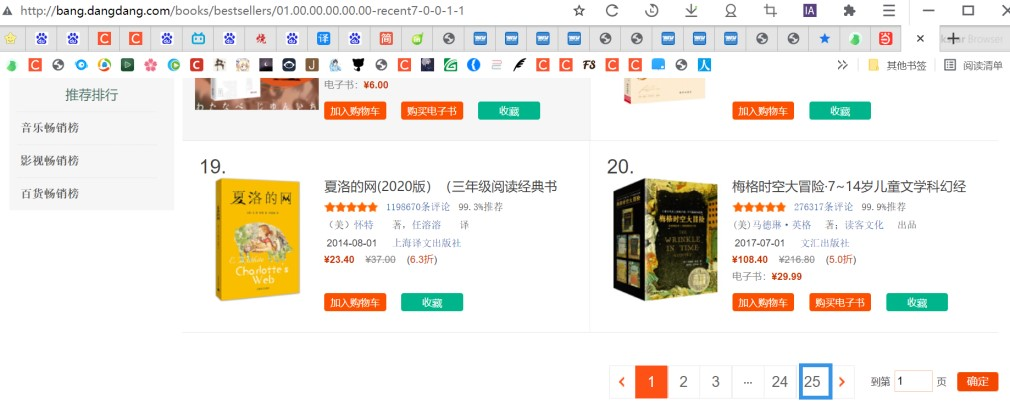
🥝 书籍数据
# 导入数据请求模块
import requests
# 导入数据解析模块
import parsel
# 导入csv模块 ---> 内置模块 不需要安装
import csv# 创建文件
f = open('书籍data25页.csv', mode='a', encoding='utf-8', newline='')
# f文件对象 fieldnames 字段名 ---> 表格第一行 作为表头
csv_writer = csv.DictWriter(f, fieldnames=['标题','评论','推荐',\'作者','日期','出版社','售价',\'原价','折扣','电子书','详情页',])
# 写入表头
csv_writer.writeheader()
"""
1. 发送请求, 模拟浏览器对于url发送请求- 等号左边是定义变量名- 模拟浏览器 ---> 请求头headers ---> 在开发者工具里面复制粘贴 字典数据类型一种简单反反爬手段, 防止被服务器识别出来是爬虫程序- 使用什么请求方式, 根据开发者工具来的
"""
for page in range(1, 26): # 1,26 是取1-25的数字, 不包含26# 确定请求网址url = f'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-{page}'# 模拟浏览器 ---> 请求头headers = {# User-Agent 用户代理 表示浏览器基本身份标识'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}# 发送请求 返回的响应对象 ---> <Response [200]>: <> 表示对象 response 响应回复 200状态码 表示请求成功response = requests.get(url=url, headers=headers)print(response)# 2. 获取数据, 获取服务器返回响应数据 ---> 开发者工具里面 response print(response.text)"""3. 解析数据, 提取我们想要数据内容, 书籍基本信息根据得到数据类型以及我们想要数据内容, 选择最适合解析方法:- re正则表达式- css选择器- xpathxpath ---> 根据标签节点提取数据css选择器 ---> 根据标签属性提取数据内容css语法匹配 不会 1 会的 2复制粘贴会不会 ---> ctrl + C ctrl + v"""# 转数据类型 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>selector = parsel.Selector(response.text)# 第一次提取 提取所有li标签 --> 返回列表, 元素Selector对象lis = selector.css('.bang_list_mode li')# for循环遍历 之后进行二次提取 我们想要内容for li in lis:"""attr() 属性选择器 a::attr(title) ---> 获取a标签里面title属性get() 获取一个 第一个 """title = li.css('.name a::attr(title)').get() # 标题star = li.css('.star a::text').get().replace('条评论', '') # 评论recommend = li.css('.tuijian::text').get().replace('推荐', '') # 推荐author = li.css('.publisher_info a::attr(title)').get() # 作者date = li.css('.publisher_info span::text').get() # 日期press = li.css('div:nth-child(6) a::text').get() # 出版社price_n = li.css('.price .price_n::text').get() # 售价price_r = li.css('.price .price_r::text').get() # 原价price_s = li.css('.price .price_s::text').get().replace('折', '') # 折扣price_e = li.css('.price .price_e .price_n::text').get() # 电子书href = li.css('.name a::attr(href)').get() # 详情页# 保存数据#源码、解答、教程加Q裙:261823976dit = {'标题': title,'评论': star,'推荐': recommend,'作者': author,\'日期': date,'出版社': press,'售价': price_n,'原价': price_r,\'折扣': price_s,'电子书': price_e,'详情页': href,}# 写入数据csv_writer.writerow(dit)print(title, star, recommend, author, date, press, price_n, price_r, price_s, price_e, href, sep=' | ')
🥝 获取评论
短评

长评

一开始能用,后来报错,就用扣钉重新运行了一下,可以。
raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
requests.exceptions.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
# 导入数据请求模块
import time
import requests
import re
for page in range(1, 11): # 第1-第10页的评论time.sleep(1.5)# 确定网址url = 'http://product.dangdang.com/index.php'# 请求参数data = {'r': 'comment/list','productId': '27898031',#'productId': '25201859', # 《钝感力》'categoryPath': '01.43.77.07.00.00','mainProductId': '27898031',#'mainProductId': '25201859','mediumId': '0','pageIndex': page,'sortType': '1','filterType': '1','isSystem': '1','tagId': '0','tagFilterCount': '0','template': 'publish','long_or_short': 'short',# 短评}headers = {'Cookie': '__permanent_id=20220526142043051185927786403737954; dest_area=country_id%3D9000%26province_id%3D111%26city_id%20%3D0%26district_id%3D0%26town_id%3D0; ddscreen=2; secret_key=f4022441400c500aa79d59edd8918a6e; __visit_id=20220723213635653213297242210260506; __out_refer=; pos_6_start=1658583812022; pos_6_end=1658583812593; __trace_id=20220723214559176959858324136999851; __rpm=p_27898031.comment_body..1658583937494%7Cp_27898031.comment_body..1658583997600','Host': 'product.dangdang.com','Referer': 'http://product.dangdang.com/27898031.html',#'Referer': 'http://product.dangdang.com/25201859.html','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',}response = requests.get(url=url, params=data, headers=headers)html_data = response.json()['data']['list']['html']content_list = re.findall("<span><a href='.*?' target='_blank'>(.*?)</a></span>", html_data)for content in content_list:with open('评论.txt', mode='a', encoding='utf-8') as f:f.write(content)f.write('\n')print(content)
对一下最后一句评论,对的上。# 《钝感力》最后一句评论是质量挺好,印刷纸质都很好,内容上觉得有道理,又不是很能说服人,个人感受
🥝 词云显示

import jieba
import wordcloud
#import imageio
import imageio.v2 as imageio
# 读取图片
py = imageio.imread('python.gif')
# 打开文件
f = open('评论.txt', encoding='utf-8')
# 读取内容
txt = f.read()
# jieba模块进行分词 ---> 列表
txt_list = jieba.lcut(txt)
print(txt_list)
# join把列表合成字符串
string = ' '.join(txt_list)
# 使用词云库
wc = wordcloud.WordCloud(height=300, # 高度width=500, # 宽度background_color='white', # 背景颜色font_path='msyh.ttc', # 字体scale=15, # 轮廓stopwords={'的', '了', '很', '也'}, # 停用词mask=py # 自定义词云图样式
)
wc.generate(string) # 需要做词云数据传入进去
wc.to_file('1.png') # 输入图片
🥝 关于词云
词云:wordcloud
安装:
pip install wordcloud
实现步骤:
读取词云的文本文件 → WordCloud().generate(txt) → to_image()建立词云图像文件 → show()显示词云
用法:

# pip install wordcloud
# pip install jieba # 中文-jieba
import wordcloud
import jieba# 注意把字体导进去,如果用到要写中文要把能显示中文的字体(很多都行)导进去
wd = wordcloud.WordCloud(font_path="A73方正行黑简体.ttf") # 配置对象参数
txt=' '.join(jieba.cut("wordcloud python 猫咪 但是"))
wd.generate(txt) # 加载词云文本
wd.to_file("wd.png")

text.txt
text
dog dog dog
dog dog dog
fish
cat
cat
# pip install wordcloud
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
# 读取文本文件
with open('text.txt') as f:txt=f.read()
wd=wordcloud.WordCloud().generate(txt)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png")
或者,不从外面读,写成字符串
# pip install wordcloud
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
# 文本
txt="text dog dog dog dog dog dog fish cat cat"
wd=wordcloud.WordCloud().generate(txt)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png")
乱码问题
词云中文乱码问题
中文词云失败的解决方法jieba
文本文件中有中文,在扣钉中会变框框,在PyCharm中报错。

UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab in position 53: incomplete multibyte sequence
解决方法:

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf").generate(txt)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png") # 输出到文件

jieba模块
jieba模块
安装模块:
pip install jieba
分词模式:
jieba 是Python中的中文分词库,提供以下三种分词模式:
- 精确模式
jieba.lcut(str) - 全模式
jieba.lcut(str,cut_all=True) - 搜索引擎模式
jieba.lcut_for_search(str)
import jieba
s = "中国是一个伟大的国家"
print(jieba.lcut(s)) # 精准模式
# 输出结果: ['中国', '是', '一个', '伟大', '的', '国家']
print(jieba.lcut(s,cut_all=True)) # 全模式
# 输出结果:['中国', '国是', '一个', '伟大', '的', '国家']
s1 = "中华人民共和国是伟大的"
print(jieba.lcut_for_search(s1)) # 搜索引擎模式
# 输出结果 :
# ['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']
jieba模块的cut()方法
import jieba
txt="我的妹妹是一只猫"
words=jieba.cut(txt)
for word in words:print(word)
Building prefix dict from the default dictionary …
Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.952 seconds.
Prefix dict has been built succesfully.
我 的 妹妹 是 一只 猫
jieba猫猫Python猫猫jieba Matplotlib jieba,Python

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf").generate(cut_text)
wd.to_image().show() # 建立词云图像文件并显示
wd.to_file("wd.png") # 输出到文件
词云参数


与matplotlib联用

text
dog dog dog
dog dog dog
fish
cat
cat
狗
# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",background_color="lightblue",width=800,height=600).generate(txt)
plt.imshow(wd)
plt.savefig("wd.png") # 输出到文件
plt.show()
plt.axis("off") # 关闭轴线

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",background_color="lightblue",width=800,height=600).generate(txt)
plt.imshow(wd)
plt.axis("off") # 关闭轴线
plt.savefig("wd.png") # 输出到文件
plt.show()
词云形状
WordCloud(mask=)
一般的图片可能要先进行去底再使用
在线去底 https://www.aigei.com/bgremover/

# pip install wordcloud
# pip install jieba
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
bgimage=np.array(Image.open('python(已去底).gif'))
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",\background_color="white",mask=bgimage).generate(cut_text)
plt.imshow(wd)
plt.axis("off")
plt.savefig("wd.png") # 输出到文件
plt.show()
用 imageio 则不去底
# pip install wordcloud
# pip install jieba
# pip install imageio
# from wordcloud import WordCloud 后面就用WordCloud
import wordcloud
import jieba
import imageio
import matplotlib.pyplot as plt
# 读取文本文件
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
bgimage=imageio.imread('python.gif')
# generate(txt)根据文本生成词云
wd=wordcloud.WordCloud(font_path="A73方正行黑简体.ttf",\background_color="white",mask=bgimage).generate(cut_text)
plt.imshow(wd)
plt.axis("off")
plt.savefig("wd.png") # 输出到文件
plt.show()
可视化词云包-Stylecloud
https://github.com/minimaxir/stylecloud
https://fontawesome.com/
https://fontawesome.dashgame.com/
https://fa5.dashgame.com/#/

import pandas as pd
import jieba.analyse
from stylecloud import gen_stylecloud
with open('text.txt',encoding='utf-8') as f:txt=f.read()
cut_text=' '.join(jieba.cut(txt))
gen_stylecloud(text=cut_text,icon_name='fas fa-comment-dots',font_path="A73方正行黑简体.ttf",background_color='white',output_name='wd.jpg')
print('绘图成功!')



import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fas fa-dog',font_path="A73方正行黑简体.ttf",palette='colorbrewer.diverging.Spectral_11', background_color='black', gradient='horizontal')
# palette:调色板(通过 palettable 实现)[默认值:cartocolors.qualitative.Bold_5]
字体颜色color

import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fas fa-dog',font_path="A73方正行黑简体.ttf",palette='colorbrewer.diverging.Spectral_11', background_color='black', # 背景色colors='white',# 字体颜色gradient='horizontal'# 梯度)
反向遮罩invert_mask

import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fas fa-dog',font_path="A73方正行黑简体.ttf",palette='colorbrewer.diverging.Spectral_11', background_color='black', # 背景色colors='white',# 字体颜色invert_mask=True, # 反向遮罩gradient='horizontal')
调色板palette
palettable 网站: https://jiffyclub.github.io/palettable/

import stylecloud
stylecloud.gen_stylecloud(file_path='text.txt', icon_name= 'fab fa-twitter',font_path="A73方正行黑简体.ttf",palette='cartocolors.diverging.TealRose_7', background_color='white', # 背景色gradient='horizontal')

import stylecloud
stylecloud.gen_stylecloud(file_path='评论.txt', icon_name= 'fab fa-qq',font_path="A73方正行黑简体.ttf",palette='tableau.BlueRed_6', background_color='white', # 背景色gradient='horizontal',size=400,output_name='书评.png')
















![[书生大模型实战营][L0][Task2] Python 开发前置知识](https://i-blog.csdnimg.cn/direct/1bde2408daaa41c888065d06d9cccc70.png#pic_center)
